Recognition: unknown
MemSearch-o1: Empowering Large Language Models with Reasoning-Aligned Memory Growth in Agentic Search
Pith reviewed 2026-05-13 07:22 UTC · model grok-4.3
The pith
MemSearch-o1 grows fine-grained memory fragments from query seed tokens and retraces them into connected paths to reduce dilution in agentic search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
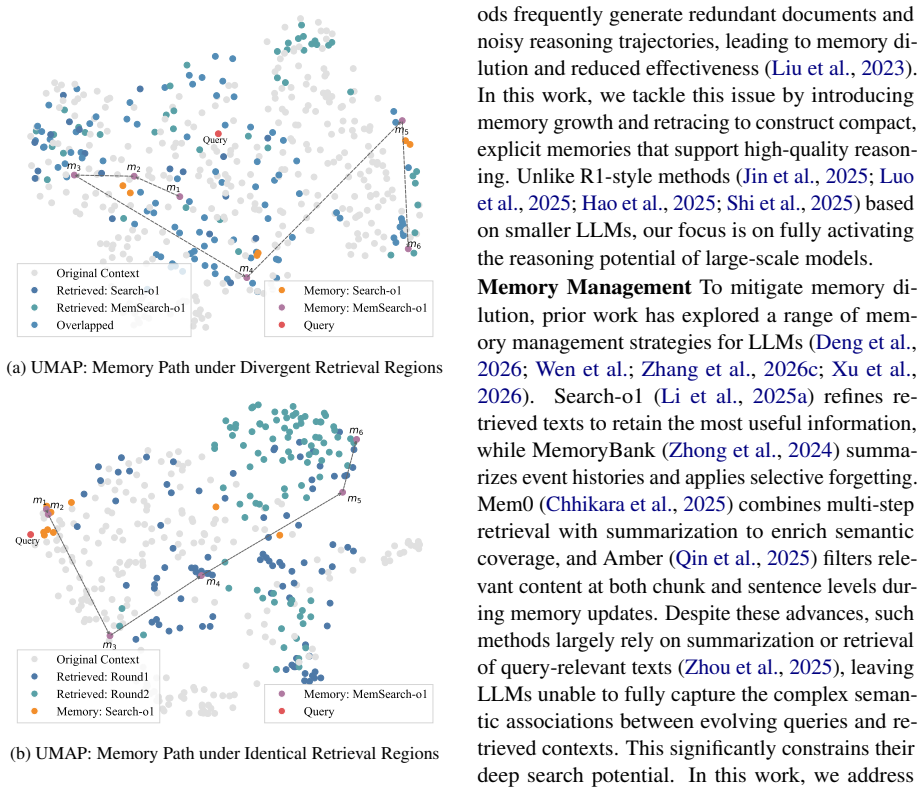
MemSearch-o1 shifts memory management from stream-like concatenation to structured, token-level growth with path-based reasoning: it dynamically grows fine-grained memory fragments from memory seed tokens drawn from the queries, retraces and refines those fragments via a contribution function, and finally reorganizes them into a globally connected memory path.
What carries the argument
Reasoning-aligned memory growth that builds and retraces fine-grained fragments from query seed tokens using a contribution function to form connected paths.
If this is right
- Agentic search loops can run for more iterations while preserving query-document relations.
- Diverse LLMs gain better access to their own reasoning capacity once memory stays structured rather than diluted.
- Memory handling moves from linear appending to path reorganization that supports global coherence.
- The framework supplies a concrete base for building memory-aware agentic systems.
- Fine-grained token-level growth reduces the information loss that occurs in long iterative retrieval sequences.
Where Pith is reading between the lines
- The same growth-and-retrace pattern could be applied to multi-turn conversational agents to keep context coherent without repeated full-context resets.
- Integration with graph databases might let the reorganized paths serve as explicit knowledge graphs for downstream verification.
- Longer-horizon tasks such as multi-step planning or tool use would become more reliable if the contribution function can be tuned to prioritize causal links over simple relevance.
- The approach suggests that memory dilution is partly an artifact of concatenation order rather than an inevitable limit of context windows.
Load-bearing premise
Dynamically growing and retracing fine-grained memory fragments from query seed tokens will capture semantic relations and lose less information than prior stream-like concatenation methods.
What would settle it
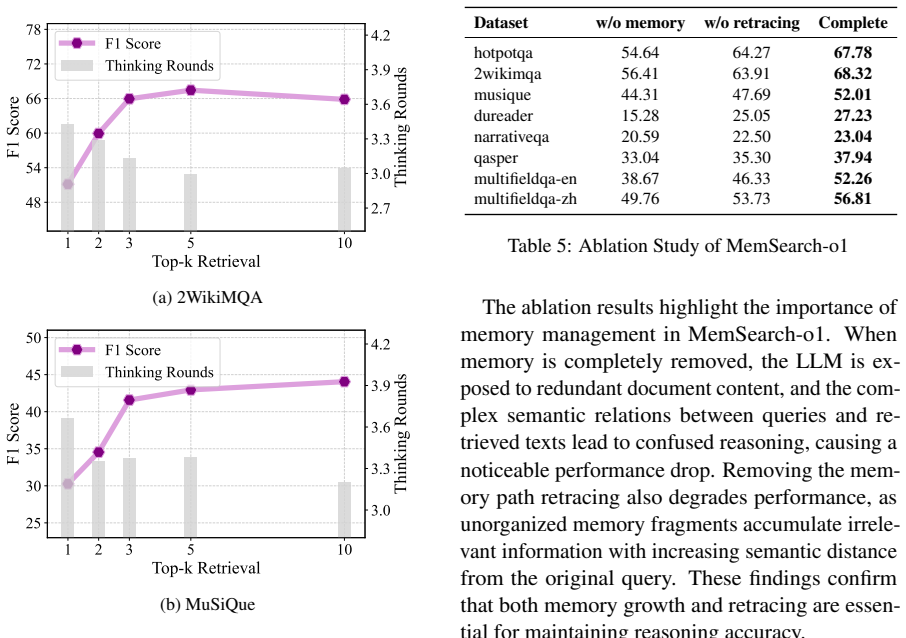
If side-by-side runs on the same eight benchmarks show no measurable drop in memory dilution or no rise in reasoning accuracy compared with standard stream-based memory, the central claim would be falsified.
Figures



read the original abstract
Recent advances in large language models (LLMs) have scaled the potential for reasoning and agentic search, wherein models autonomously plan, retrieve, and reason over external knowledge to answer complex queries. However, the iterative think-search loop accumulates long system memories, leading to memory dilution problem. In addition, existing memory management methods struggle to capture fine-grained semantic relations between queries and documents and often lose substantial information. Therefore, we propose MemSearch-o1, an agentic search framework built on reasoning-aligned memory growth and retracing. MemSearch-o1 dynamically grows fine-grained memory fragments from memory seed tokens from the queries, then retraces and deeply refines the memory via a contribution function, and finally reorganizes a globally connected memory path. This shifts memory management from stream-like concatenation to structured, token-level growth with path-based reasoning. Experiments on eight benchmark datasets show that MemSearch-o1 substantially mitigates memory dilution, and more effectively activates the reasoning potential of diverse LLMs, establishing a solid foundation for memory-aware agentic intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MemSearch-o1, an agentic search framework for LLMs that addresses memory dilution in iterative think-search processes. It introduces reasoning-aligned memory growth, where fine-grained memory fragments are dynamically grown from query seed tokens, followed by retracing using a contribution function and reorganization into a globally connected memory path. This approach is positioned as superior to stream-like concatenation for capturing fine-grained semantic relations. The paper claims that experiments on eight benchmark datasets demonstrate substantial mitigation of memory dilution and more effective activation of reasoning potential in diverse LLMs.
Significance. If the results are substantiated, this work could have notable significance in the field of agentic AI and LLM-based search systems. By shifting memory management to a structured, token-level growth and path-based reasoning paradigm, it offers a potential solution to a key limitation in long-context agentic interactions. The framework establishes a foundation for memory-aware agentic intelligence, which may influence future designs of autonomous reasoning agents.
major comments (2)
- [Abstract] Abstract: The central empirical claim that MemSearch-o1 'substantially mitigates memory dilution' and 'more effectively activates the reasoning potential' on eight benchmark datasets is presented without any quantitative results, specific metrics, baselines, error bars, or ablation details. This absence is load-bearing for the paper's contribution, as the soundness of the method rests entirely on these unverified assertions.
- [Method] Method: The 'contribution function' for retracing memory fragments and the 'path reorganization' step are described only at a conceptual level with no formal definition, pseudocode, or mathematical formulation. This makes it impossible to verify how the approach captures fine-grained semantic relations better than stream-like methods or to assess its parameter-free status.
minor comments (1)
- [Abstract] Abstract: The invented term 'reasoning-aligned memory growth' is used without an immediate definition or citation to related memory management literature.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and agree that revisions are needed to strengthen the presentation of our empirical claims and methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that MemSearch-o1 'substantially mitigates memory dilution' and 'more effectively activates the reasoning potential' on eight benchmark datasets is presented without any quantitative results, specific metrics, baselines, error bars, or ablation details. This absence is load-bearing for the paper's contribution, as the soundness of the method rests entirely on these unverified assertions.
Authors: We agree that the abstract would benefit from concrete quantitative highlights to support the claims. In the revised version, we will incorporate key results such as average performance gains across the eight benchmarks (e.g., accuracy improvements over baselines like standard RAG and stream-concatenation methods), specific metrics used, and a brief mention of ablations demonstrating the contribution of each component. This will make the abstract self-contained while remaining within length limits. revision: yes
-
Referee: [Method] Method: The 'contribution function' for retracing memory fragments and the 'path reorganization' step are described only at a conceptual level with no formal definition, pseudocode, or mathematical formulation. This makes it impossible to verify how the approach captures fine-grained semantic relations better than stream-like methods or to assess its parameter-free status.
Authors: We acknowledge that the current description of the contribution function and path reorganization remains at a high level. We will revise the Method section to include a precise mathematical formulation of the contribution function (including how it scores token-level fragments based on reasoning alignment), pseudocode for the full retracing and reorganization pipeline, and an explicit statement confirming the parameter-free nature with justification. These additions will clarify the advantages over stream-like concatenation in capturing semantic relations. revision: yes
Circularity Check
No significant circularity; framework is an independent design proposal
full rationale
The paper introduces MemSearch-o1 as a new agentic search framework that grows fine-grained memory fragments from query seed tokens, applies a contribution function for retracing, and reorganizes paths. No equations, fitted parameters, or self-referential derivations appear in the provided abstract or implied full text. The central claims rest on experimental results across eight benchmarks rather than any mathematical chain that reduces to its own inputs by construction. This matches the reader's assessment of an independent design without reduction to self-defined quantities, yielding a score of 0 with no load-bearing self-citations or ansatzes identified.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Iterative think-search loops in agentic systems accumulate long memories that suffer dilution.
- domain assumption Existing memory management methods fail to capture fine-grained semantic relations between queries and documents.
invented entities (2)
-
reasoning-aligned memory growth
no independent evidence
-
contribution function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How lan- guage models use long contexts.arXiv preprint arXiv:2307.03172. Qidong Liu, Xian Wu, Wanyu Wang, Yejing Wang, Yuanshao Zhu, Xiangyu Zhao, Feng Tian, a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Jun- feng Fang, Hengxing Cai, An Zhang, and Xiang Wang
Compressing long context for enhancing rag with amr-based concept distillation.arXiv preprint arXiv:2405.03085. Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Jun- feng Fang, Hengxing Cai, An Zhang, and Xiang Wang. 2025. Search and refine during think: Au- tonomous retrieval-augmented reasoning of llms. arXiv preprint arXiv:2505.11277. Zoltán Gendler Szabó...
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jian- hong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, and 22 oth- ers. 2024. Qwen2.5 technical report.arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.