Recognition: unknown
Depth Adaptive Efficient Visual Autoregressive Modeling
Pith reviewed 2026-05-10 06:19 UTC · model grok-4.3
The pith
DepthVAR assigns variable computational depth to each token in visual autoregressive image models, cutting inference time 2.3 to 3.1 times with only small quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Visual autoregressive models possess significant depth redundancy. This redundancy can be exploited by a training-free adaptive allocation scheme that assigns per-token computational depth through a cyclic rotated scheduler and translates the assignments into layer-major masks that selectively run transformer blocks, followed by code blending that scales each token's contribution exactly to its received depth.
What carries the argument
The adaptive depth scheduler that cycles depth assignments across tokens together with the code-blending step that normalizes each token's output influence to its allocated depth.
If this is right
- Lower-depth tokens skip later transformer layers, directly reducing multiply-add operations per generation step.
- The cyclic schedule distributes refinement evenly so no single position is chronically under- or over-processed.
- Code blending ensures the final representation for each token reflects the precise fraction of computation it received.
- The resulting images maintain competitive quality at 2.3 to 3.1 times the baseline speed.
- The adaptive scheme yields a better quality-speed curve than binary token-pruning baselines that remove positions entirely.
Where Pith is reading between the lines
- The same per-token depth variation could be tested in autoregressive models for video or audio to see whether similar redundancy exists outside images.
- If the cyclic schedule proves robust, it might be replaced by a lightweight learned predictor without losing the training-free property.
- Hardware that supports dynamic layer skipping would amplify the reported speedups beyond what software masking alone achieves.
Load-bearing premise
VAR models contain enough distributed depth redundancy that cyclic adaptive allocation plus proportional code blending recovers nearly the original generation quality.
What would settle it
Running the full DepthVAR procedure on a standard VAR checkpoint at the claimed speedups and finding that FID or perceptual quality metrics degrade far more than the minimal loss reported in the paper's experiments.
Figures














read the original abstract
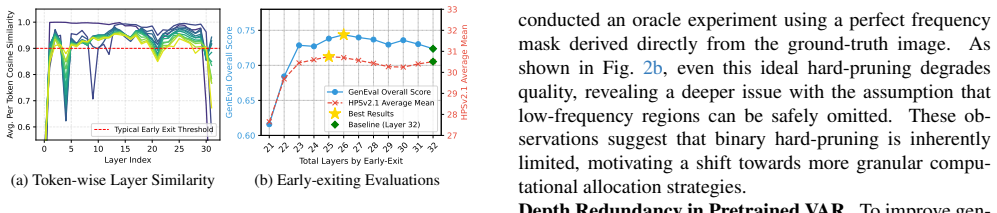
Visual Autoregressive (VAR) modeling inefficiently applies a fixed computational depth to each position when generating high-resolution images. While existing methods accelerate inference by pruning tokens using frequency maps, their binary hard-pruning approach is fundamentally limited and fails to improve quality even with better frequency estimation. Observing that VAR models possess significant depth redundancy, we propose a paradigm shift from pruning entire tokens to adaptively allocating per-token computational depth. To this end, we introduce DepthVAR, a training-free framework that dynamically allocates computation. It integrates an adaptive depth scheduler, which assigns computational depth via a cyclic rotated schedule for balanced, non-static refinement, with a dynamic inference process that translates these depths into layer-major masks, selectively applies transformer blocks, and blends the resulting codes to ensure each token's influence is proportional to its processing depth. Extensive experiments show that DepthVAR achieves 2.3$\times$-3.1$\times$ acceleration with minimal quality loss, offering a competitive compute-performance trade-off compared to existing hard-pruning approaches. Code is available at https://github.com/STOVAGtz/DepthVAR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DepthVAR, a training-free framework for Visual Autoregressive (VAR) models that exploits observed depth redundancy by adaptively allocating per-token computational depth. It uses a cyclic rotated scheduler for balanced refinement, translates depths into layer-major masks, selectively applies transformer blocks, and blends codes proportionally to depth. Experiments claim 2.3×-3.1× inference acceleration with minimal quality loss relative to hard-pruning baselines.
Significance. If the central claim holds, the shift from binary token pruning to depth-adaptive allocation could improve efficiency-quality trade-offs in autoregressive image generation without retraining. The training-free design and public code release are clear strengths enabling reproducibility. However, the low soundness rating stems from missing details on ablations, baselines, and verification that blending preserves output distributions.
major comments (1)
- [Dynamic inference process description] The load-bearing assumption that cyclic scheduling plus proportional code blending produces hidden states whose statistics remain close to full-depth training (preventing drift in subsequent autoregressive predictions) is stated without derivation, ablation, or analysis of in-distribution properties for the blended codes.
minor comments (1)
- [Abstract] The abstract should explicitly state the VAR model variants, image resolutions, and quantitative metrics (FID, etc.) underlying the 2.3×-3.1× acceleration range and 'minimal quality loss' claim.
Simulated Author's Rebuttal
Thank you for your thorough review and valuable feedback on our paper 'Depth Adaptive Efficient Visual Autoregressive Modeling'. We address the major comment point-by-point below and commit to revisions that strengthen the presentation of our dynamic inference process.
read point-by-point responses
-
Referee: The load-bearing assumption that cyclic scheduling plus proportional code blending produces hidden states whose statistics remain close to full-depth training (preventing drift in subsequent autoregressive predictions) is stated without derivation, ablation, or analysis of in-distribution properties for the blended codes.
Authors: We agree that additional justification for the blending mechanism is warranted. Although our experiments demonstrate that DepthVAR maintains competitive image quality with significant speedups, indicating that any distributional drift is not detrimental to the autoregressive generation process, we will enhance the manuscript with: a more detailed description of the blending operation and its motivation; new ablations isolating the effect of proportional blending versus alternatives (e.g., no blending or hard selection); and quantitative analysis comparing the statistics of blended hidden states to full-depth ones, including cosine similarity and norm differences at various layers. These additions will be included in the revised version to better verify preservation of in-distribution properties. revision: yes
Circularity Check
No significant circularity; method is training-free and observation-driven
full rationale
The paper's derivation chain consists of an empirical observation of depth redundancy in VAR models followed by a proposed training-free framework (cyclic rotated scheduler, layer-major masks, and proportional code blending). No equations, fitted parameters, or self-citations are presented that reduce the central claims to inputs by construction. The approach is explicitly positioned as a paradigm shift grounded in observation and validated by experiments, with no load-bearing self-referential steps or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VAR models exhibit significant depth redundancy across tokens
Reference graph
Works this paper leans on
-
[1]
Binarybert: Pushing the limit of bert quantization
Haoli Bai, Wei Zhang, Lu Hou, Lifeng Shang, Jin Jin, Xin Jiang, Qun Liu, Michael Lyu, and Irwin King. Binarybert: Pushing the limit of bert quantization. InProceedings of the 59th Annual Meeting of the Association for Computa- tional Linguistics and the 11th International Joint Confer- ence on Natural Language Processing (Volume 1: Long Pa- pers), pages 4...
2021
-
[2]
Adaptive neural networks for efficient inference
Tolga Bolukbasi, Joseph Wang, Ofer Dekel, and Venkatesh Saligrama. Adaptive neural networks for efficient inference. InInternational conference on machine learning, pages 527–
-
[3]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. InInternational Conference on Learning Representations, 2023. 5, 6
2023
-
[4]
Tts-var: A test- time scaling framework for visual auto-regressive genera- tion
Zhekai Chen, Ruihang Chu, Yukang Chen, Shiwei Zhang, Yujie Wei, Yingya Zhang, and Xihui Liu. Tts-var: A test- time scaling framework for visual auto-regressive genera- tion. InThe Thirty-ninth Annual Conference on Neural In- formation Processing Systems. 2
-
[5]
Frequency-aware autoregressive modeling for efficient high-resolution image synthesis
Zhuokun Chen, Jugang Fan, Zhuowei Yu, Bohan Zhuang, and Mingkui Tan. Frequency-aware autoregressive modeling for efficient high-resolution image synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 17140–17149, 2025. 1, 3, 4, 5, 6, 7
2025
-
[6]
Collaborative decoding makes visual auto-regressive modeling efficient
Zigeng Chen, Xinyin Ma, Gongfan Fang, and Xinchao Wang. Collaborative decoding makes visual auto-regressive modeling efficient. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23334–23344,
-
[7]
A survey of techniques for optimizing transformer inference.Journal of Systems Architecture, 144:102990, 2023
Krishna Teja Chitty-Venkata, Sparsh Mittal, Murali Emani, Venkatram Vishwanath, and Arun K Somani. A survey of techniques for optimizing transformer inference.Journal of Systems Architecture, 144:102990, 2023. 2
2023
-
[8]
An algorithm for the machine calculation of complex fourier series.Mathematics of computation, 19(90):297–301, 1965
James W Cooley and John W Tukey. An algorithm for the machine calculation of complex fourier series.Mathematics of computation, 19(90):297–301, 1965. 4
1965
-
[9]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christo- pher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 6
2022
-
[10]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers.arXiv preprint arXiv:1807.03819, 2018. 2
work page internal anchor Pith review arXiv 2018
-
[11]
Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference,
Luciano Del Corro, Allie Del Giorno, Sahaj Agarwal, Bin Yu, Ahmed Awadallah, and Subhabrata Mukherjee. Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference.arXiv preprint arXiv:2307.02628, 2023. 2
-
[12]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 2
2019
-
[13]
Depth-adaptive transformer
Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer. InICLR 2020-Eighth Interna- tional Conference on Learning Representations, pages 1–14,
2020
-
[14]
Layer- skip: Enabling early exit inference and self-speculative de- coding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, et al. Layer- skip: Enabling early exit inference and self-speculative de- coding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1...
2024
-
[15]
Fast bit-reversal algorithms
Anne C Elster. Fast bit-reversal algorithms. InInternational Conference on Acoustics, Speech, and Signal Processing, pages 1099–1102. IEEE, 1989. 4
1989
-
[16]
arXiv preprint arXiv:1909.11556 , year=
Angela Fan, Edouard Grave, and Armand Joulin. Reducing transformer depth on demand with structured dropout.arXiv preprint arXiv:1909.11556, 2019. 2, 3
-
[17]
Siqi Fan, Xuezhi Fang, Xingrun Xing, Peng Han, Shuo Shang, and Yequan Wang. Position-aware depth decay de- coding (d 3): Boosting large language model inference effi- ciency.arXiv preprint arXiv:2503.08524, 2025. 2
-
[18]
Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 23(120):1–39, 2022. 2
2022
-
[19]
Deecap: Dynamic early exiting for efficient image captioning
Zhengcong Fei, Xu Yan, Shuhui Wang, and Qi Tian. Deecap: Dynamic early exiting for efficient image captioning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12216–12226, 2022. 2
2022
-
[20]
Geneval: An object-focused framework for evaluating text- to-image alignment.Advances in Neural Information Pro- cessing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text- to-image alignment.Advances in Neural Information Pro- cessing Systems, 36:52132–52152, 2023. 6, 1, 2
2023
-
[21]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016. 2, 5
work page internal anchor Pith review arXiv 2016
-
[22]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InFirst conference on lan- guage modeling, 2024. 3
2024
-
[23]
MiniLLM: On-Policy Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models.arXiv preprint arXiv:2306.08543, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[24]
Fastvar: Linear vi- sual autoregressive modeling via cached token pruning
Hang Guo, Yawei Li, Taolin Zhang, Jiangshan Wang, Tao Dai, Shu-Tao Xia, and Luca Benini. Fastvar: Linear vi- sual autoregressive modeling via cached token pruning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19011–19021, 2025. 1, 3, 5, 6, 7, 2
2025
-
[25]
Infinity: Scaling bit- 9 wise autoregressive modeling for high-resolution image syn- thesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bit- 9 wise autoregressive modeling for high-resolution image syn- thesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15733–15744, 2025. 1, 2, 3, 4, 5, 6, 7
2025
-
[26]
Router-tuning: A simple and effec- tive approach for dynamic depth
Shwai He, Tao Ge, Guoheng Sun, Bowei Tian, Xiaoyang Wang, and Dong Yu. Router-tuning: A simple and effec- tive approach for dynamic depth. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Pro- cessing, pages 1925–1938, 2025. 2
2025
-
[27]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. In European Conference on Computer Vision, pages 289–305. Springer, 2024. 4
2024
-
[28]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
Dynabert: Dynamic bert with adaptive width and depth.Advances in Neural Information Processing Sys- tems, 33:9782–9793, 2020
Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, and Qun Liu. Dynabert: Dynamic bert with adaptive width and depth.Advances in Neural Information Processing Sys- tems, 33:9782–9793, 2020. 2
2020
-
[30]
arXiv preprint arXiv:1703.09844 (2017)
Gao Huang, Danlu Chen, Tianhong Li, Felix Wu, Laurens Van Der Maaten, and Kilian Q Weinberger. Multi-scale dense networks for resource efficient image classification. arXiv preprint arXiv:1703.09844, 2017. 2
-
[31]
Yekun Ke, Xiaoyu Li, Yingyu Liang, Zhizhou Sha, Zhen- mei Shi, and Zhao Song. On computational limits and provably efficient criteria of visual autoregressive mod- els: A fine-grained complexity analysis.arXiv preprint arXiv:2501.04377, 2025. 3
-
[32]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. 1
2009
-
[33]
Hmar: Efficient hierarchical masked auto- regressive image generation
Hermann Kumbong, Xian Liu, Tsung-Yi Lin, Ming-Yu Liu, Xihui Liu, Ziwei Liu, Daniel Y Fu, Christopher Re, and David W Romero. Hmar: Efficient hierarchical masked auto- regressive image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2535– 2544, 2025. 3
2025
-
[34]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020. 2
work page internal anchor Pith review arXiv 2006
-
[35]
Fast in- ference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast in- ference from transformers via speculative decoding. InIn- ternational Conference on Machine Learning, pages 19274– 19286. PMLR, 2023. 3
2023
-
[36]
arXiv preprint arXiv:2506.08908 , year=
Jiajun Li, Yue Ma, Xinyu Zhang, Qingyan Wei, Songhua Liu, and Linfeng Zhang. Skipvar: Accelerating visual au- toregressive modeling via adaptive frequency-aware skip- ping.arXiv preprint arXiv:2506.08908, 2025. 3, 5, 6, 7
-
[37]
Memory-efficient visual autoregressive modeling with scale-aware kv cache compression
Kunjun Li, Zigeng Chen, Cheng-Yen Yang, and Jenq-Neng Hwang. Memory-efficient visual autoregressive modeling with scale-aware kv cache compression. InThe Thirty-ninth Annual Conference on Neural Information Processing Sys- tems. 3
-
[38]
Freqexit: En- abling early-exit inference for visual autoregressive models via frequency-aware guidance
Ying Li, Chengfei Lv, and Huan Wang. Freqexit: En- abling early-exit inference for visual autoregressive models via frequency-aware guidance. InNeurIPS, 2025. 1, 2, 3
2025
-
[39]
Spin- quant: Llm quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge So- ran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spin- quant: Llm quantization with learned rotations. InThe Thirteenth International Conference on Learning Represen- tations. 2
-
[40]
Sentence- t5: Scalable sentence encoders from pre-trained text-to-text models
Jianmo Ni, Gustavo Hernandez Abrego, Noah Constant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang. Sentence- t5: Scalable sentence encoders from pre-trained text-to-text models. InFindings of the association for computational linguistics: ACL 2022, pages 1864–1874, 2022. 3
2022
-
[41]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. 1
2025
-
[42]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949,
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949,
-
[43]
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam San- toro. Mixture-of-depths: Dynamically allocating com- pute in transformer-based language models.arXiv preprint arXiv:2404.02258, 2024. 2
-
[44]
M-var: Decoupled scale-wise autoregressive modeling for high-quality image generation
Sucheng Ren, Yaodong Yu, Nataniel Ruiz, Feng Wang, Alan Yuille, and Cihang Xie. M-var: Decoupled scale-wise autoregressive modeling for high-quality image generation. arXiv preprint arXiv:2411.10433, 2024. 3
-
[45]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
work page internal anchor Pith review arXiv 1910
-
[46]
Tal Schuster, Adam Fisch, Tommi Jaakkola, and Regina Barzilay. Consistent accelerated inference via confident adaptive transformers.arXiv preprint arXiv:2104.08803,
-
[47]
Con- fident adaptive language modeling.Advances in Neural In- formation Processing Systems, 35:17456–17472, 2022
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. Con- fident adaptive language modeling.Advances in Neural In- formation Processing Systems, 35:17456–17472, 2022. 2, 3, 5
2022
-
[48]
Roy Schwartz, Gabriel Stanovsky, Swabha Swayamdipta, Jesse Dodge, and Noah A Smith. The right tool for the job: Matching model and instance complexities.arXiv preprint arXiv:2004.07453, 2020. 2
-
[49]
Weiqiao Shan, Long Meng, Tong Zheng, Yingfeng Luo, Bei Li, Tong Xiao, Jingbo Zhu, et al. Early exit is a nat- ural capability in transformer-based models: An empirical study on early exit without joint optimization.arXiv preprint arXiv:2412.01455, 2024. 2
-
[50]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer.arXiv preprint arXiv:1701.06538, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
Q- bert: Hessian based ultra low precision quantization of bert
Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Q- bert: Hessian based ultra low precision quantization of bert. 10 InProceedings of the AAAI conference on artificial intelli- gence, pages 8815–8821, 2020. 2
2020
-
[52]
Block- wise parallel decoding for deep autoregressive models.Ad- vances in Neural Information Processing Systems, 31, 2018
Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Block- wise parallel decoding for deep autoregressive models.Ad- vances in Neural Information Processing Systems, 31, 2018. 3
2018
-
[53]
arXiv preprint arXiv:2004.02984 , year=
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yim- ing Yang, and Denny Zhou. Mobilebert: a compact task- agnostic bert for resource-limited devices.arXiv preprint arXiv:2004.02984, 2020. 2
-
[54]
Hart: Efficient visual generation with hybrid autoregressive transformer
Haotian Tang, Yecheng Wu, Shang Yang, Enze Xie, Jun- song Chen, Junyu Chen, Zhuoyang Zhang, Han Cai, Yao Lu, and Song Han. Hart: Efficient visual generation with hybrid autoregressive transformer. InThe Thirteenth International Conference on Learning Representations. 1, 2, 3, 5, 6, 7
-
[55]
You need multiple exiting: Dynamic early exiting for accelerating unified vision language model
Shengkun Tang, Yaqing Wang, Zhenglun Kong, Tianchi Zhang, Yao Li, Caiwen Ding, Yanzhi Wang, Yi Liang, and Dongkuan Xu. You need multiple exiting: Dynamic early exiting for accelerating unified vision language model. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 10781–10791, 2023. 2
2023
-
[56]
A survey on transformer compression,
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, and Dacheng Tao. A survey on transformer compression.arXiv preprint arXiv:2402.05964, 2024. 2
-
[57]
Branchynet: Fast inference via early exiting from deep neural networks
Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In2016 23rd international con- ference on pattern recognition (ICPR), pages 2464–2469. IEEE, 2016. 2
2016
-
[58]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural in- formation processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Li- wei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural in- formation processing systems, 37:84839–84865, 2024. 1, 2, 3
2024
-
[59]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 3
2017
-
[60]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review arXiv
-
[61]
Litevar: Compressing visual autoregressive modelling with efficient attention and quantization
Rui Xie, Tianchen Zhao, Zhihang Yuan, Rui Wan, Wenxi Gao, Zhenhua Zhu, Xuefei Ning, and Yu Wang. Litevar: Compressing visual autoregressive modelling with efficient attention and quantization. InWorkshop on Machine Learn- ing and Compression, NeurIPS 2024. 3
2024
-
[62]
Berxit: Early exiting for bert with better fine-tuning and extension to regression
Ji Xin, Raphael Tang, Yaoliang Yu, and Jimmy Lin. Berxit: Early exiting for bert with better fine-tuning and extension to regression. InProceedings of the 16th conference of the European chapter of the association for computational lin- guistics: Main Volume, pages 91–104, 2021. 2
2021
-
[63]
Imagereward: learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: learning and evaluating human preferences for text-to-image generation. InProceedings of the 37th International Con- ference on Neural Information Processing Systems, pages 15903–15935, 2023. 6, 7, 1, 3
2023
-
[64]
Bert loses patience: Fast and robust inference with early exit.Advances in Neural Information Processing Systems, 33:18330–18341, 2020
Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. Bert loses patience: Fast and robust inference with early exit.Advances in Neural Information Processing Systems, 33:18330–18341, 2020. 2
2020
-
[65]
Leebert: Learned early exit for bert with cross- level optimization
Wei Zhu. Leebert: Learned early exit for bert with cross- level optimization. InProceedings of the 59th Annual Meet- ing of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2968–2980,
-
[66]
Ablation on Different Reference Metrics The reference metricEand its layer range[ℓ begin, ℓend]de- termine the base decision rank map that guides depth allo- cation
2 11 Depth Adaptive Efficient Visual Autoregressive Modeling Supplementary Material A. Ablation on Different Reference Metrics The reference metricEand its layer range[ℓ begin, ℓend]de- termine the base decision rank map that guides depth allo- cation. We ablate these choices in Table 6, including met- rics analogous to those in SparseV AR [5] (EMSE on Bl...
-
[67]
and FastV AR (ESUB), under different reference scalesr R. R Reference Metric GenEval ImageReward E[ℓ begin, ℓend]Score↑ Avg Latency (ms)↓Score↑ Avg Latency (ms)↓ 7 EMAE [3,19]0.7256 1168 0.9088 1174 EMAE [0,31]0.7216 1228 0.9081 1253 EMSE [3,19]0.7219 1217 0.9094 1214 EMSE [0,31]0.7304 1270 0.8948 1295 EMSE Block 3 0.7198 1164 0.9078 1184 ESUB −0.7210 124...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.