Recognition: unknown
BizCompass: Benchmarking the Reasoning Capabilities of LLMs in Business Knowledge and Applications
Pith reviewed 2026-05-10 05:48 UTC · model grok-4.3
The pith
BizCompass benchmark links theoretical business knowledge in four domains to practical tasks for analyst, trader, and consultant roles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BizCompass uses a dual-axis design that pairs knowledge-level coverage of finance, economics, statistics, and operations management with application-level tasks drawn from the roles of analyst, trader, and consultant. This structure exposes performance differences across realistic scenarios and diagnoses which foundational capabilities enable or constrain success, with results from evaluating multiple LLMs demonstrating how theoretical knowledge translates into practical business performance.
What carries the argument
The dual-axis design of BizCompass that pairs four theoretical knowledge domains with three representative business roles to structure evaluation tasks.
If this is right
- Model selection for business contexts can be guided by measured performance on specific knowledge-to-role mappings.
- Training can be optimized by targeting the foundational capabilities shown to constrain practical success.
- Performance variations across realistic business scenarios become measurable for targeted model improvements.
- Public release of the datasets supports reproducibility and further research on LLM use in business.
Where Pith is reading between the lines
- The dual-axis approach could be adapted to link theory and practice in other complex domains such as law or healthcare.
- Narrow single-task benchmarks may systematically miss integration failures that only appear in role-structured scenarios.
- Developers could prioritize strengthening identified weak domains to improve overall readiness for business applications.
Load-bearing premise
The selected tasks and domains accurately capture the rigorous reasoning and knowledge integration demanded by real business analysis without significant gaps or biases in coverage.
What would settle it
A finding that LLMs scoring well on the benchmark's knowledge and role tasks perform poorly when deployed in actual business settings, or that high-performing real-world models score poorly on the benchmark, would indicate the tasks do not properly reflect required capabilities.
Figures


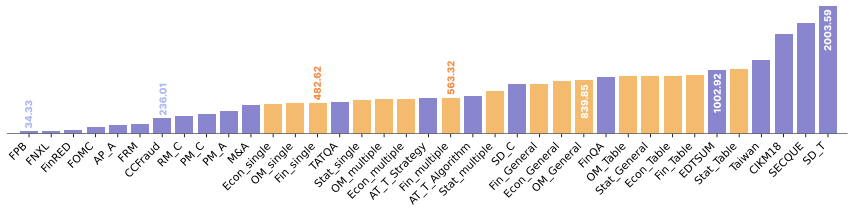



read the original abstract
Large language models (LLMs) hold great promise for business applications, yet business analysis remains inherently complex, demanding rigorous reasoning and the integration of diverse knowledge sources. Existing benchmarks typically target narrow tasks and thus leave a fundamental question unanswered: how can LLMs be reliably applied in business, and how are these applications grounded in underlying theoretical capabilities? To address this gap, we introduce BizCompass, a benchmark explicitly designed to connect theoretical foundations with practical business knowledge and applications. At the knowledge level, BizCompass covers four core domains--finance, economics, statistics, and operations management. At the application level, it structures tasks around three representative roles: the analyst, the trader, and the consultant. This dual-axis design not only exposes performance differences across realistic scenarios but also diagnoses which foundational capabilities enable or constrain success. We systematically evaluate both open-source and commercial LLMs, revealing how theoretical knowledge translates into practical performance in business. The results provide actionable insights for model selection and training optimization in real-world business contexts. All datasets and evaluation code are publicly released to support reproducibility and future research: https://bizcompass.dev.ypemc.com.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BizCompass, a benchmark for LLMs that uses a dual-axis structure: four knowledge domains (finance, economics, statistics, operations management) and three role-based application tasks (analyst, trader, consultant). It claims this design connects theoretical foundations to practical business scenarios, exposes performance differences across LLMs, diagnoses enabling or constraining capabilities, and yields actionable insights for model selection, with all datasets and code released publicly.
Significance. A well-validated benchmark spanning multiple business domains and roles could meaningfully advance evaluation of LLMs beyond narrow tasks, supporting better model selection and training for real applications. The public release aids reproducibility, but the diagnostic value depends on unshown linkages between tasks and capabilities.
major comments (2)
- [Abstract] Abstract: the claim that the dual-axis design 'diagnoses which foundational capabilities enable or constrain success' lacks any described mechanism (controlled mapping, error categorization, or ablation) to attribute outcomes to specific theoretical capabilities rather than prompt sensitivity or general instruction following.
- [Benchmark design] Benchmark design section: no evidence is supplied of task construction details, reliability validation, or checks for coverage gaps/biases, which is load-bearing for the central claim that the tasks accurately capture rigorous business reasoning and allow diagnosis of constraints.
minor comments (1)
- [Abstract] Abstract: states that systematic evaluation was performed and results provide insights, yet supplies no performance numbers, key findings, or error analysis to ground those claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing to strengthen the paper where the concerns are valid and providing clarification on our design choices without overstating the current content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the dual-axis design 'diagnoses which foundational capabilities enable or constrain success' lacks any described mechanism (controlled mapping, error categorization, or ablation) to attribute outcomes to specific theoretical capabilities rather than prompt sensitivity or general instruction following.
Authors: We agree the abstract phrasing is ambitious and could imply a more formal diagnostic mechanism than is explicitly detailed. The intended diagnosis arises from systematic cross-axis comparisons: performance patterns across the four knowledge domains and three role tasks are analyzed to identify correlations (e.g., strong statistics knowledge enabling analyst tasks but not necessarily trader ones). However, we acknowledge this is observational rather than controlled via ablations or error categorization. We will revise the abstract to use more precise language (e.g., 'facilitates diagnosis through structured comparisons') and add a short subsection in the Evaluation or Results section describing the comparative analysis method used. This addresses the concern directly. revision: yes
-
Referee: [Benchmark design] Benchmark design section: no evidence is supplied of task construction details, reliability validation, or checks for coverage gaps/biases, which is load-bearing for the central claim that the tasks accurately capture rigorous business reasoning and allow diagnosis of constraints.
Authors: The Benchmark Design section outlines task sourcing from established public datasets in each domain, mapping to role-specific scenarios, and basic expert review for relevance. We recognize, however, that explicit details on construction process, inter-annotator reliability, and formal bias/gap analysis are not sufficiently elaborated. We will expand this section to include: (1) step-by-step task construction methodology, (2) any validation steps performed (e.g., domain expert review), and (3) a limitations subsection discussing potential coverage gaps or biases with how the dual-axis structure helps mitigate them. This will better ground the central claims. revision: yes
Circularity Check
No circularity: benchmark construction with no derivation chain
full rationale
The paper presents BizCompass as a new benchmark structured around four knowledge domains and three role-based tasks. No equations, parameter fitting, or self-referential derivations appear in the provided text. The dual-axis design is introduced as an explicit structuring choice to connect knowledge and applications, not derived from or reduced to prior inputs by construction. Claims about diagnosis of capabilities are descriptive assertions about the benchmark's intended use rather than a closed logical loop. Per guidelines, this is self-contained benchmark work with no load-bearing self-citation or fitted predictions, warranting a non-finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Business analysis requires rigorous reasoning and integration of knowledge from finance, economics, statistics, and operations management.
- domain assumption Tasks for analyst, trader, and consultant roles represent practical business applications.
Reference graph
Works this paper leans on
-
[1]
Where should i publish to get promoted? a finance journal ranking based on business-school promotions.Journal of Banking & Finance, 114:105780. Deborah L Bandalos. 2018.Measurement Theory and Applications for the Social Sciences. Guilford Publi- cations. Noga BenYoash, Menachem Brief, Oded Ovadia, Gil Shenderovitz, Moshik Mishaeli, Rachel Lemberg, and Eit...
-
[2]
DeepSeek-R1 incentivizes reasoning in llms through reinforcement learning.Nature, 645:633 – 638. Yu Ding. 2023. Editorial: Perspectives of ISE/OR re- searchers.IISE Transactions, 55(1):1–1. Forty-ninth Edition. 2000. Journal Quality List. Kathleen M Eisenhardt and Mark J Zbaracki. 1992. Strategic decision making.Strategic management journal, 13(S2):17–37....
-
[3]
Developing, Analyzing, and Using Distractors for Multiple-Choice Tests in Education: A Compre- hensive Review.Review of educational research, 87(6):1082–1116. Xin Guo, Haotian Xia, Zhaowei Liu, Hanyang Cao, Zhi Yang, Zhiqiang Liu, Sizhe Wang, Jinyi Niu, Chuqi Wang, Yanhui Wang, and 1 others. 2025. FinEval: A Chinese financial domain knowledge evaluation b...
-
[4]
Financebench: A new benchmark for financial question answering.arXiv preprint arXiv:2311.11944, 2023
FinanceBench: A New Benchmark for Financial Question Answering.arXiv preprint arXiv:2311.11944. Junzhe Jiang, Chang Yang, Aixin Cui, Sihan Jin, Ruiyu Wang, Bo Li, Xiao Huang, Dongning Sun, and Xin- run Wang. 2025. FinMaster: A Holistic Bench- mark for Mastering Full-Pipeline Financial Work- flows with LLMs.arXiv preprint arXiv:2505.13533. Carlos E Jimenez...
-
[5]
FinanceQA: A Benchmark for Evaluating Financial Analysis Capabilities of Large Language Models.arXiv preprint arXiv:2501.18062. Samuel Messick. 1995. V ALIDITY OF PSYCHO- LOGICAL ASSESSMENT: V ALIDATION OF IN- FERENCES FROM PERSONS’ RESPONSES AND PERFORMANCES AS SCIENTIFIC INQUIRY INTO SCORE MEANING.American psychologist, 50(9):741. Margaret Mitchell, Sim...
-
[6]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning
The impact of item-writing flaws and item complexity on examination item difficulty and discrimination value.BMC medical education, 16(1):250. Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning
-
[7]
InThe Twelfth Inter- national Conference on Learning Representations
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InThe Twelfth Inter- national Conference on Learning Representations. Agam Shah, Suvan Paturi, and Sudheer Chava. 2023. Trillion Dollar Words: A New Financial Dataset, Task & Market Analysis. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Vol...
2023
-
[8]
Raj Sanjay Shah, Kunal Chawla, Dheeraj Eidnani, Agam Shah, Wendi Du, Sudheer Chava, Natraj Ra- man, Charese Smiley, Jiaao Chen, and Diyi Yang
Association for Computational Linguistics. Raj Sanjay Shah, Kunal Chawla, Dheeraj Eidnani, Agam Shah, Wendi Du, Sudheer Chava, Natraj Ra- man, Charese Smiley, Jiaao Chen, and Diyi Yang
-
[9]
InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)
When FLUE Meets FLANG: Benchmarks and Large Pretrained Language Model for Financial Domain. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguis- tics. James Shanteau. 1992. Competence in experts: The role of task characteristics.Organizational behavior and human decision p...
-
[10]
InProceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM), pages 1627–
Hybrid Deep Sequential Modeling for Social Text-Driven Stock Prediction. InProceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM), pages 1627–
-
[11]
Yuhe Wu, Yuran Chen, Zhuang Liu, and Wayne Lin
ACM. Yuhe Wu, Yuran Chen, Zhuang Liu, and Wayne Lin
-
[12]
Enhancing Financial Decision-making under Cyber Threats: a Dual-branch Framework Integrating Bayesian Deep Learning and Explainable AI.Annals of Operations Research, pages 1–33. xAI. 2025. Models. Accessed:2025-07-09. Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, and 1 others. 2...
-
[13]
Judging LLM-as-a-judge with MT-bench and Chatbot Arena. InAdvances in neural information processing systems, volume 36, pages 46595–46623. Yaxian Zhou, Yufei Yuan, Kai Huang, and Xiangpei Hu. 2024. Can ChatGPT Perform a Grounded The- ory Approach to Do Risk Analysis? An Empirical Study.Journal of Management Information Systems, 41(4):982–1015. Zhihan Zhou...
-
[14]
score":<arithmetic mean score>, “scores_per_question
‘scores_per_question‘: An object con- taining the independent score for each sub- question. The format must be exactly as follows: { “score":<arithmetic mean score>, “scores_per_question": { “<question_number_1>": <integer from 0 to 5>, “<question_number_2>": <integer from 0 to 5>} } J More Results J.1 Statistical Analysis of Business Scenarioss To explor...
2010
-
[15]
Derive the simplified variance under (F3) and show it implies conditionally uncorrelated random effects
-
[16]
Critique (F3) with a clinical trial example where it fails, and discuss consequences for inference if violated but the simplified model is used. OUTPUT:
-
[17]
Since unconditional orthogonality implies E(aG1aG2) = 0 , the constant must be 0, so conditional covariances vanish
Under (F3), E(a2 G|J) =σ 2 G (constant) for random G, and E(aG1aG2|J) = constant for G1̸=G2 . Since unconditional orthogonality implies E(aG1aG2) = 0 , the constant must be 0, so conditional covariances vanish. Thus, var(y|J) = P G /∈Jσ2 G, with effects conditionally uncorrelated
-
[18]
A,B"). OUTPUT FORMAT: Return ONLY the answer as a string containing the chosen letters separated by commas (e.g., “A,B
In a trial with fixed factor Treatment (Placebo, Low Dose, High Dose) and random factor Patient, high-dose responses may vary more due to side effects, violating constant σ2 R across treatments. If violated but simplified model used, variance estimates are wrong, leading to invalid p-values, confidence intervals, and hypothesis tests for treatment effects...
-
[19]
(1), calculate the Economic Order Quantity Q ˆ for component XJ-100
Using the data from Table 1 and eq. (1), calculate the Economic Order Quantity Q ˆ for component XJ-100
-
[20]
Using eq
The current policy is to order 1,000 units at a time. Using eq. (2), calculate the total annual cost for the current policy (Q= 1000 ) and for the optimal EOQ policy (Q=Qˆ ) you found in part 1. How much money does the company save annually by switching to the EOQ model? OUTPUT:
-
[21]
(1): Annual Demand,D= 10,000units
To calculate the Economic Order Quantity (Qˆ), we substitute the parameter values from Table 1 into eq. (1): Annual Demand,D= 10,000units. Ordering Cost,S= $50per order. Holding Cost,H= $4per unit per year. Using eq. (1): Qˆ = r 2×10000×50 4 = r 1,000,000 4 = p 250,000 = 500 The Economic Order Quantity is 500 units
-
[22]
(2) and the data from Table 1
To find the cost savings, we first calculate the total annual cost for both policies using eq. (2) and the data from Table 1. Cost of Current Policy (Q = 1,000): T C(1000) = 10000 1000 (50) + 1000 2 (4) = 10(50) + 500(4) = 500 + 2000 = $2,500 Cost of EOQ Policy (Q = 500): T C(500) = 10000 500 (50) + 500 2 (4) = 20(50) + 250(4) = 1000 + 1000 = $2,000 The t...
2000
-
[23]
Establish Price Channel: Continuously calculate the 20-day simple moving average and the upper/lower Bollinger Bands for the target asset
-
[24]
A sell (short) signal is generated when the price closes above the upper Bollinger Band
Generate Entry Signals: A buy signal is generated when the asset’s price closes below the lower Bollinger Band. A sell (short) signal is generated when the price closes above the upper Bollinger Band
-
[25]
according to Table 1
Define Exit Rule: The position is closed (exited) when the asset’s price reverts and crosses back over the 20-day moving average. Describe a complete, three-step strategy for a mean-reversion trading system based on the provided framework. OUTPUT: The strategy for this mean-reversion system is a three-step process designed to capitalize on temporary price...
-
[26]
Identify the single most critical risk to Innovate Inc.’s valuation based on the report
-
[27]
Propose a key metric to monitor this risk
-
[28]
Define a specific, quantitative trigger for this metric that would require a mandatory portfolio action, and state what that action should be. OUTPUT:
-
[29]
The threat comes from a new competitor offering a significantly lower-priced alternative
The most critical risk is the severe margin and market share compression for its ’Pro-Suite’ software, which is the company’s primary profit driver, accounting for an estimated ‘80% of operating profit’. The threat comes from a new competitor offering a significantly lower-priced alternative
-
[30]
The key metric to monitor this risk will be a combination of Pro-Suite’s Average Selling Price (ASP) and its quarterly market share, as reported in the company’s financial statements and industry analysis reports
-
[31]
If this trigger is activated, the mandatory action is an immediate 25% reduction of our position in Innovate Inc
A mandatory portfolio action will be triggered if either of the following conditions is met in a single quarter: a) Pro-Suite’s reported market share drops by more than 5% sequentially, or b) its reported ASP decreases by more than 7% sequentially. If this trigger is activated, the mandatory action is an immediate 25% reduction of our position in Innovate...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.