Recognition: unknown
Align Documents to Questions: Question-Oriented Document Rewriting for Retrieval-Augmented Generation
Pith reviewed 2026-05-10 06:38 UTC · model grok-4.3
The pith
Rewriting retrieved documents into a question-oriented style helps LLMs use factual evidence more effectively in RAG systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
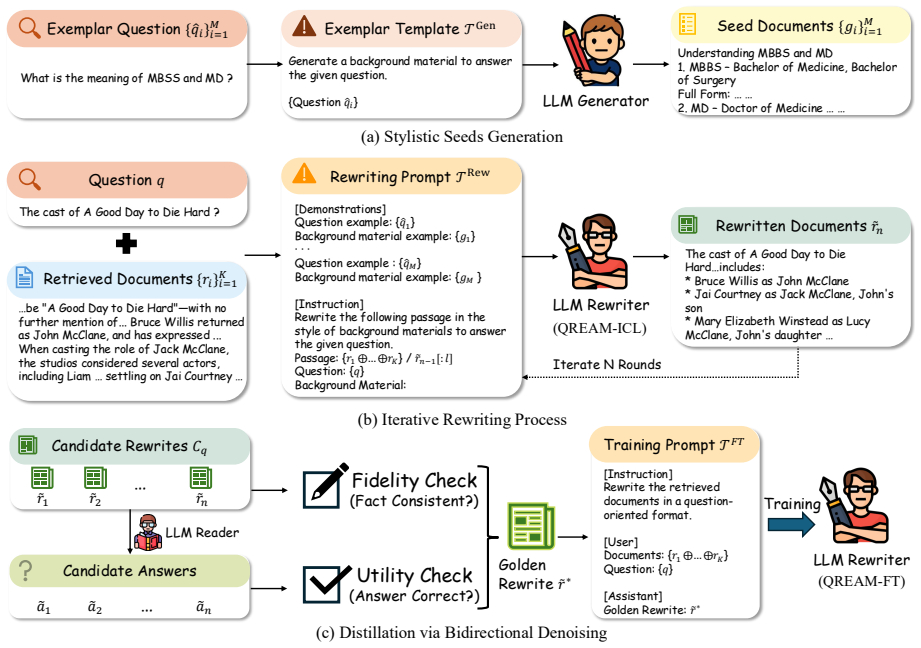
QREAM is a two-stage style-controlled rewriter: QREAM-ICL performs iterative rewriting of retrieved documents using stylistic seeds to explore question-oriented versions, while QREAM-FT distills this into a lightweight student model trained via dual-criteria rejection sampling on answer correctness and factual consistency, allowing seamless integration into RAG pipelines that improves LLM utilization of evidence.
What carries the argument
QREAM, the question-oriented document rewriter that converts retrieved passages to match query style while preserving facts through in-context exploration and filtered distillation.
If this is right
- QREAM can be added as a plug-and-play step before LLM generation in any retrieval-augmented pipeline.
- The dual filtering on correctness and consistency produces supervision data that maintains factual grounding.
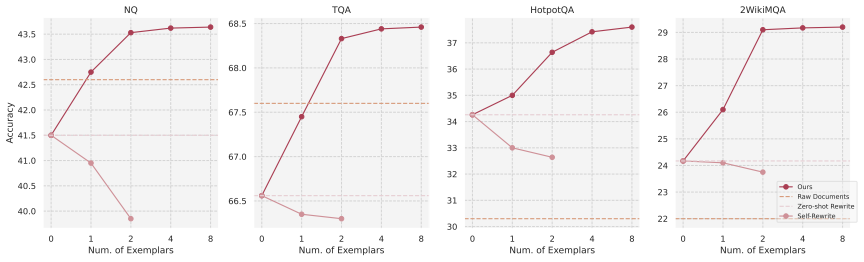
- Performance gains reach up to 8 percent relative improvement with negligible extra latency.
- The approach balances question relevance against preservation of original facts in the rewritten output.
Where Pith is reading between the lines
- Similar rewriting could be applied to other input formats such as tables or code snippets to reduce presentation barriers in retrieval systems.
- The distillation step might transfer to rewriting tasks outside RAG, such as summarization or dialogue adaptation.
- If the stylistic bias proves general, future retrieval methods could optimize jointly for content and presentation style rather than content alone.
Load-bearing premise
The main bottleneck in RAG is stylistic mismatch that makes retrieved evidence harder for LLMs to use than generated text, and that rewriting can correct the style without introducing new factual errors or biases.
What would settle it
A controlled test on a standard RAG benchmark in which applying the rewriter produces zero or negative change in accuracy or increases the rate of factual hallucinations.
Figures


read the original abstract
Retrieval-Augmented Generation (RAG) enhances the factuality of Large Language Models (LLMs) by incorporating retrieved documents and/or generated context. However, LLMs often exhibit a stylistic bias when presented with mixed contexts, favoring fluent but hallucinated generated content over factually grounded yet disorganized retrieved evidence. This phenomenon reveals that the utility of retrieved information is bottlenecked by its presentation. To bridge this gap, we propose QREAM, a style-controlled rewriter that aligns retrieved documents with a question-oriented style while preserving facts, better for LLM readers to utilize. Our framework consists of two stages: (1) QREAM-ICL, which uses stylistic seeds to guide iterative rewriting exploration; and (2) QREAM-FT, a lightweight student model distilled from denoised ICL outputs. QREAM-FT employs dual-criteria rejection sampling, filtering based on answer correctness and factual consistency to ensure high-quality supervision. QREAM seamlessly integrates into existing RAG pipelines as a plug-and-play module. Experiments demonstrate that QREAM consistently enhances advanced RAG pipelines, yielding up to 8% relative improvement with negligible latency overhead, effectively balancing question relevance with factual grounding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QREAM, a two-stage framework for rewriting retrieved documents in RAG pipelines to adopt a question-oriented style while preserving factual content. QREAM-ICL uses in-context learning with stylistic seeds for iterative rewriting, and QREAM-FT distills a lightweight model from denoised outputs selected via dual-criteria rejection sampling based on answer correctness and factual consistency. The method is claimed to integrate seamlessly into existing RAG systems, achieving up to 8% relative performance gains with negligible additional latency.
Significance. If the empirical gains are robust and the fact preservation mechanism is reliable, this work could have practical significance for improving the effectiveness of retrieved documents in RAG by mitigating stylistic biases in LLMs. It offers a plug-and-play solution that balances relevance and grounding without substantial computational overhead.
major comments (2)
- Abstract: The abstract claims performance improvements of up to 8% but does not provide any details on the experimental setup, including datasets, baselines, evaluation metrics, or the specific RAG pipelines tested. This lack of information makes it impossible to verify the central empirical claim from the provided text.
- Abstract: The dual-criteria rejection sampling in QREAM-FT relies on LLM-based assessment for factual consistency and answer correctness. No validation of these LLM judges (such as correlation with human judgments or use of automated metrics like entailment) is mentioned, which is critical because errors in the filter could lead to corrupted training data and artifactual gains rather than true improvements from style alignment.
minor comments (2)
- The abstract introduces several new terms (QREAM, QREAM-ICL, QREAM-FT) without defining them upfront, which may confuse readers unfamiliar with the framework.
- It would be helpful to clarify what 'stylistic seeds' refers to in the description of QREAM-ICL.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: Abstract: The abstract claims performance improvements of up to 8% but does not provide any details on the experimental setup, including datasets, baselines, evaluation metrics, or the specific RAG pipelines tested. This lack of information makes it impossible to verify the central empirical claim from the provided text.
Authors: We agree that the current abstract is concise and omits specific experimental details, which limits immediate verification of the reported gains. The full experimental setup—including the datasets, baselines, evaluation metrics, and RAG pipelines—is described in detail in Section 4 of the manuscript. To address this, we will revise the abstract to include a brief summary of the key experimental elements (e.g., the benchmarks used and the consistent relative improvements across pipelines) while preserving its length constraints. revision: yes
-
Referee: Abstract: The dual-criteria rejection sampling in QREAM-FT relies on LLM-based assessment for factual consistency and answer correctness. No validation of these LLM judges (such as correlation with human judgments or use of automated metrics like entailment) is mentioned, which is critical because errors in the filter could lead to corrupted training data and artifactual gains rather than true improvements from style alignment.
Authors: This is a fair and important point. The manuscript describes the dual-criteria rejection sampling procedure in Section 3.2 but does not include explicit validation of the LLM judges. We will add validation results in the revised version, such as agreement statistics with human annotations on sampled data and comparisons against automated metrics like textual entailment, to demonstrate the reliability of the filtering step and rule out potential artifacts. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper describes a two-stage empirical framework (QREAM-ICL for iterative rewriting and QREAM-FT for distillation via rejection sampling) and reports experimental gains on RAG pipelines. No equations, parameters fitted to target metrics, or theoretical derivations appear in the provided text. Claims rest on observed performance improvements rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not invoked to establish uniqueness theorems or load-bearing premises. The rejection sampling step is a procedural filter and does not create self-definition or fitted-input-as-prediction circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs exhibit a stylistic bias favoring fluent generated content over factually grounded but disorganized retrieved evidence
invented entities (1)
-
QREAM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Patricia S. Abril and Robert Plant. The patent holder's dilemma: Buy, sell, or troll?. Communications of the ACM. doi:10.1145/1188913.1188915
-
[2]
Deciding equivalances among conjunctive aggregate queries
Sarah Cohen and Werner Nutt and Yehoshua Sagic. Deciding equivalances among conjunctive aggregate queries. doi:10.1145/1219092.1219093
-
[3]
Special issue: Digital Libraries. 1996
1996
-
[4]
Understanding Policy-Based Networking
David Kosiur. Understanding Policy-Based Networking
-
[7]
Editor (Ed.), title The title of book two , The name of the series two, edition 2nd
The title of book two. doi:10.1007/3-540-09237-4
-
[8]
Asad Z. Spector. Achieving application requirements. Distributed Systems. doi:10.1145/90417.90738
-
[9]
Douglass and David Harel and Mark B
Bruce P. Douglass and David Harel and Mark B. Trakhtenbrot. Statecarts in use: structured analysis and object-orientation. Lectures on Embedded Systems. doi:10.1007/3-540-65193-4_29
-
[10]
Donald E. Knuth. The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd. ed.)
-
[11]
Donald E. Knuth. The Art of Computer Programming
-
[12]
Structured Variational Inference Procedures and their Realizations (as incol)
Dan Geiger and Christopher Meek. Structured Variational Inference Procedures and their Realizations (as incol). Proceedings of Tenth International Workshop on Artificial Intelligence and Statistics, The Barbados
-
[13]
Stan W. Smith. An experiment in bibliographic mark-up: Parsing metadata for XML export. Proceedings of the 3rd. annual workshop on Librarians and Computers
-
[14]
Catch me, if you can: Evading network signatures with web-based polymorphic worms
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna. Catch me, if you can: Evading network signatures with web-based polymorphic worms. Proceedings of the first USENIX workshop on Offensive Technologies
-
[15]
Sten Andler. Predicate Path expressions. Proceedings of the 6th. ACM SIGACT-SIGPLAN symposium on Principles of Programming Languages. doi:10.1145/567752.567774
-
[16]
LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER
David Harel. LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER
-
[17]
Anisi , title =
David A. Anisi , title =
-
[18]
Clarkson
Kenneth L. Clarkson. Algorithms for Closest-Point Problems (Computational Geometry)
-
[19]
Introduction to Bayesian Statistics
Harry Thornburg. Introduction to Bayesian Statistics. 2001
2001
-
[20]
CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11
Rafal Ablamowicz and Bertfried Fauser. CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11. 2007
2007
-
[21]
Stats and Analysis
Poker-Edge.Com. Stats and Analysis. 2006
2006
-
[22]
A more perfect union
Barack Obama. A more perfect union
-
[23]
The fountain of youth
Joseph Scientist. The fountain of youth
-
[24]
Solder man
Dave Novak. Solder man. ACM SIGGRAPH 2003 Video Review on Animation theater Program: Part I - Vol. 145 (July 27--27, 2003). doi:10.945/woot07-S422
2003
-
[25]
Interview with Bill Kinder: January 13, 2005
Newton Lee. Interview with Bill Kinder: January 13, 2005. Comput. Entertain. doi:10.1145/1057270.1057278
-
[26]
The Enabling of Digital Libraries
Bernard Rous. The Enabling of Digital Libraries. Digital Libraries
-
[28]
(new) Finding minimum congestion spanning trees , journal =
Werneck, Renato and Setubal, Jo\. (new) Finding minimum congestion spanning trees , journal =. doi:10.1145/351827.384253 , acmid = 384253, publisher =
-
[30]
Conti, Mauro and Di Pietro, Roberto and Mancini, Luigi V. and Mei, Alessandro , title =. Inf. Fusion , volume =. 2009 , issn =. doi:10.1016/j.inffus.2009.01.002 , acmid =
-
[31]
Li, Cheng-Lun and Buyuktur, Ayse G. and Hutchful, David K. and Sant, Natasha B. and Nainwal, Satyendra K. , title =. CHI '08 extended abstracts on Human factors in computing systems , year =. doi:10.1145/1358628.1358946 , acmid =
-
[32]
, title =
Hollis, Billy S. , title =. 1999 , isbn =
1999
-
[33]
Goossens, Michel and Rahtz, S. P. and Moore, Ross and Sutor, Robert S. , title =. 1999 , isbn =
1999
-
[34]
and Rosenberg, Arnold L
Buss, Jonathan F. and Rosenberg, Arnold L. and Knott, Judson D. , title =. 1987 , source =
1987
-
[35]
CHI '08: CHI '08 extended abstracts on Human factors in computing systems , year =
, note =. CHI '08: CHI '08 extended abstracts on Human factors in computing systems , year =
-
[36]
Algorithms for Closest-Point Problems (Computational Geometry) , year =
Clarkson, Kenneth Lee , advisor =. Algorithms for Closest-Point Problems (Computational Geometry) , year =
-
[37]
SIGCOMM Comput. Commun. Rev. , year =
-
[38]
IEEE TCSC Executive Committee , booktitle =. 2004 , isbn =. doi:http://dx.doi.org/10.1109/ICWS.2004.64 , acmid =
-
[39]
Distributed systems (2nd Ed.) , year =
-
[40]
, title =
Petrie, Charles J. , title =. 1986 , source =
1986
-
[41]
Donald E. Knuth. Seminumerical Algorithms. 1981
1981
-
[42]
E-commerce and cultural values , year =
Kong, Wei-Chang , Title =. E-commerce and cultural values , year =
-
[43]
E-commerce and cultural values , year =
Kong, Wei-Chang , type =. E-commerce and cultural values , year =
-
[44]
Chapter 9 , booktitle =
Kong, Wei-Chang , editor =. Chapter 9 , booktitle =
-
[45]
E-commerce and cultural values , editor =
Kong, Wei-Chang , title =. E-commerce and cultural values , editor =. 2003 , isbn =
2003
-
[46]
E-commerce and cultural values - (InBook-num-in-chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values - (InBook-num-in-chap) , chapter =. 2004 , address =
2004
-
[47]
E-commerce and cultural values (Inbook-text-in-chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values (Inbook-text-in-chap) , chapter =. 2005 , address =
2005
-
[48]
E-commerce and cultural values (Inbook-num chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values (Inbook-num chap) , chapter =. 2006 , address =
2006
-
[49]
Microelectron
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi , title =. Microelectron. J. , volume =. 2010 , pages =
2010
-
[50]
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi and Zahra Sasanian , title =. J. Emerg. Technol. Comput. Syst. , volume =
-
[51]
Kirschmer, Markus and Voight, John , title =. SIAM J. Comput. , issue_date =. 2010 , issn =. doi:https://doi.org/10.1137/080734467 , acmid =
-
[52]
Hoare, C. A. R. , title =. Structured programming (incoll) , editor =. 1972 , isbn =
1972
-
[53]
History of programming languages I (incoll) , editor =
Lee, Jan , title =. History of programming languages I (incoll) , editor =. 1981 , isbn =. doi:http://doi.acm.org/10.1145/800025.1198348 , acmid =
-
[54]
, title =
Dijkstra, E. , title =. Classics in software engineering (incoll) , year =
-
[55]
Wenzel, Elizabeth M. , title =. Multimedia interface design (incoll) , year =. doi:10.1145/146022.146089 , acmid =
-
[56]
, title =
Mumford, E. , title =. Critical issues in information systems research (incoll) , year =
-
[57]
and Golden, Donald G
McCracken, Daniel D. and Golden, Donald G. , title =. 1990 , isbn =
1990
-
[58]
The analysis of linear partial differential operators
H. The analysis of linear partial differential operators. 1985 , PAGES =
1985
-
[59]
IEEE", address =
A. Adya and P. Bahl and J. Padhye and A.Wolman and L. Zhou , title =. Proceedings of the IEEE 1st International Conference on Broadnets Networks (BroadNets'04) , publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[60]
I. F. Akyildiz and W. Su and Y. Sankarasubramaniam and E. Cayirci , title =. Comm. ACM , volume = 38, number = "4", year =
-
[61]
I. F. Akyildiz and T. Melodia and K. R. Chowdhury , title =. Computer Netw. , volume = 51, number = "4", year =
-
[62]
ACM", address =
P. Bahl and R. Chancre and J. Dungeon , title =. Proceeding of the 10th International Conference on Mobile Computing and Networking (MobiCom'04) , publisher = "ACM", address = "New York, NY", year =
-
[63]
8 (Special Issue on Sensor Networks)
D. Culler and D. Estrin and M. Srivastava , title =. IEEE Comput. , volume = 37, number = "8 (Special Issue on Sensor Networks)", publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[64]
Natarajan and M
A. Natarajan and M. Motani and B. de Silva and K. Yap and K. C. Chua , title =. Network Architectures , editor =. 960935712
-
[65]
Tzamaloukas and J
A. Tzamaloukas and J. J. Garcia-Luna-Aceves , title =
-
[66]
Zhou and J
G. Zhou and J. Lu and C.-Y. Wan and M. D. Yarvis and J. A. Stankovic , title =
-
[67]
Mapping Powerlists onto Hypercubes
Jacob Kornerup. Mapping Powerlists onto Hypercubes. 1994
1994
-
[68]
Automatic Parallelization for Distributed-Memory Multiprocessing Systems
Michael Gerndt. Automatic Parallelization for Distributed-Memory Multiprocessing Systems
-
[69]
J. E. Archer, Jr. and R. Conway and F. B. Schneider. User recovery and reversal in interactive systems. ACM Trans. Program. Lang. Syst
-
[70]
D. D. Dunlop and V. R. Basili. Generalizing specifications for uniformly implemented loops. ACM Trans. Program. Lang. Syst
-
[71]
Heering and P
J. Heering and P. Klint. Towards monolingual programming environments. ACM Trans. Program. Lang. Syst
-
[72]
Donald E. Knuth. The book
-
[73]
Korach and D
E. Korach and D. Rotem and N. Santoro. Distributed algorithms for finding centers and medians in networks. ACM Trans. Program. Lang. Syst
-
[74]
: A Document Preparation System
Leslie Lamport. : A Document Preparation System
-
[75]
F. Nielson. Program transformations in a denotational setting. ACM Trans. Program. Lang. Syst
-
[76]
Brian K. Reid. A high-level approach to computer document formatting. Proceedings of the 7th Annual Symposium on Principles of Programming Languages
-
[77]
Zhou, Gang and Wu, Yafeng and Yan, Ting and He, Tian and Huang, Chengdu and Stankovic, John A. and Abdelzaher, Tarek F. , title =. ACM Trans. Embed. Comput. Syst. , issue_date =. doi:10.1145/1721695.1721705 , acmid = 1721705, publisher =
-
[78]
Institutional members of the Users Group
-
[79]
Boris Veytsman , title =
-
[80]
Robin Schneider , title =
-
[81]
and Peterson, Larry L
Bowman, Mic and Debray, Saumya K. and Peterson, Larry L. , title =. ACM Trans. Program. Lang. Syst. , volume =. 1993 , doi =
1993
-
[82]
TUGboat , volume =
Braams, Johannes , title =. TUGboat , volume =
-
[83]
Post Congress Tristesse
Malcolm Clark. Post Congress Tristesse. TeX90 Conference Proceedings
-
[84]
ACM Trans
Herlihy, Maurice , title =. ACM Trans. Program. Lang. Syst. , volume =. 1993 , doi =
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.