Recognition: unknown
AutoSearch: Adaptive Search Depth for Efficient Agentic RAG via Reinforcement Learning
Pith reviewed 2026-05-10 06:42 UTC · model grok-4.3
The pith
AutoSearch trains an agent with reinforcement learning to halt retrieval at the shortest depth that still produces accurate answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
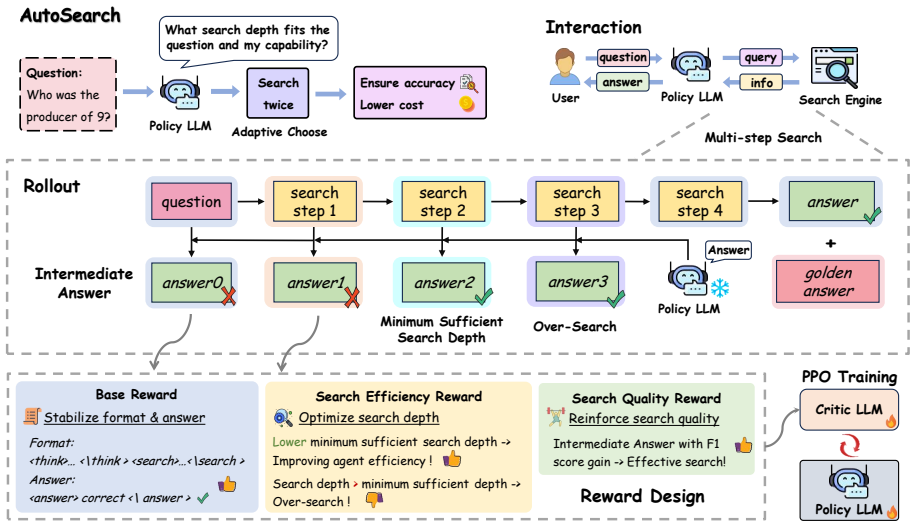
AutoSearch is a reinforcement learning framework that evaluates each search step via self-generated intermediate answers. It identifies the minimal sufficient search depth and promotes efficient search by rewarding its attainment while penalizing over-searching. Additional reward mechanisms stabilize search behavior and improve answer quality on complex questions. Experiments on multiple benchmarks show that AutoSearch achieves a superior accuracy-efficiency trade-off compared with fixed-depth baselines.
What carries the argument
The self-answering mechanism inside the RL policy that generates an intermediate answer after each retrieval step and uses it to decide whether the minimal sufficient depth has been reached.
If this is right
- On questions whose complexity matches the agent's capability the search stops early and saves compute.
- Continued over-searching is directly penalized, lowering latency and tool-call costs.
- Stabilizing rewards keep the agent from oscillating or under-exploring on hard questions.
- The same learned stopping rule applies across benchmarks without per-question hyper-parameters.
Where Pith is reading between the lines
- The same self-evaluation signal could be reused in other agent loops that repeat external tool calls until an internal check passes.
- Deployed RAG services could track cumulative token usage and automatically switch to shallower policies when budgets tighten.
- Measuring how the learned depth changes when the base model is swapped would show whether the minimal-depth signal is model-specific or more general.
Load-bearing premise
Self-generated intermediate answers can be trusted to indicate reliably whether further searches would still improve the final answer.
What would settle it
Run the method on a held-out set of questions and measure whether accuracy rises when forced to continue searching past the depth AutoSearch chose.
Figures















read the original abstract
Agentic retrieval-augmented generation (RAG) systems enable large language models (LLMs) to solve complex tasks through multi-step interaction with external retrieval tools. However, such multi-step interaction often involves redundant search steps, incurring substantial computational cost and latency. Prior work limits search depth (i.e., the number of search steps) to reduce cost, but this often leads to underexploration of complex questions. To address this, we first investigate how search depth affects accuracy and find a minimal sufficient search depth that defines an accuracy-efficiency trade-off, jointly determined by question complexity and the agent's capability. Furthermore, we propose AutoSearch, a reinforcement learning (RL) framework that evaluates each search step via self-generated intermediate answers. By a self-answering mechanism, AutoSearch identifies the minimal sufficient search depth and promotes efficient search by rewarding its attainment while penalizing over-searching. In addition, reward mechanisms are introduced to stabilize search behavior and improve answer quality on complex questions. Extensive experiments on multiple benchmarks show that AutoSearch achieves a superior accuracy-efficiency trade-off, alleviating over-searching while preserving search quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the impact of search depth on accuracy in agentic RAG systems, identifies a minimal sufficient search depth determined by question complexity and agent capability, and proposes AutoSearch, an RL framework that uses self-generated intermediate answers to detect this depth, reward its attainment, penalize over-searching, and stabilize behavior via additional reward mechanisms. Experiments on multiple benchmarks are reported to show superior accuracy-efficiency trade-offs compared to fixed-depth baselines.
Significance. If the central claims hold, AutoSearch provides a practical RL-driven method to reduce redundant retrieval steps and latency in multi-step agentic RAG without sacrificing answer quality on complex queries. The self-answering reward design and stabilization mechanisms represent a targeted contribution to efficient LLM agent design, with potential applicability to other tool-using agents if the stopping-signal reliability generalizes.
major comments (2)
- [Abstract and Proposed Method] The central claim that AutoSearch alleviates over-searching while preserving quality rests on the untested assumption that self-generated intermediate answers reliably signal when the minimal sufficient search depth has been reached. No direct measurement or ablation of stopping-signal fidelity (e.g., precision of self-assessed completeness versus ground-truth information sufficiency) is provided, particularly for complex multi-hop questions where LLMs are prone to overconfidence or hallucination. This is load-bearing for the accuracy-efficiency trade-off result.
- [Experiments] The experimental validation of the superior trade-off is difficult to assess without details on data splits, exact reward formulations (including the self-answering and stabilization terms), ablation studies isolating the RL components, and statistical significance of gains over baselines. The abstract reports benchmark improvements but does not address potential post-hoc tuning or sensitivity to the minimal-sufficient-depth definition.
minor comments (2)
- [Method] Notation for the RL state, action (search depth), and reward components should be formalized with equations early in the method section to improve clarity.
- [Discussion] The paper should include a limitations section discussing failure modes of the self-answering mechanism on out-of-distribution or highly ambiguous queries.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the identification of areas where additional validation and transparency would strengthen the presentation of our claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and Proposed Method] The central claim that AutoSearch alleviates over-searching while preserving quality rests on the untested assumption that self-generated intermediate answers reliably signal when the minimal sufficient search depth has been reached. No direct measurement or ablation of stopping-signal fidelity (e.g., precision of self-assessed completeness versus ground-truth information sufficiency) is provided, particularly for complex multi-hop questions where LLMs are prone to overconfidence or hallucination. This is load-bearing for the accuracy-efficiency trade-off result.
Authors: We acknowledge that a direct evaluation of the stopping-signal fidelity is necessary to fully substantiate the mechanism's reliability, especially given known LLM tendencies toward overconfidence on complex queries. The original manuscript focuses on end-to-end accuracy-efficiency results and the investigation of minimal sufficient depth via search depth sweeps, but does not include an explicit ablation measuring how well self-generated answers align with ground-truth information sufficiency. In the revision, we will add a dedicated analysis (new subsection in Experiments or Appendix) that quantifies stopping-signal precision and recall by comparing AutoSearch's self-assessed stopping decisions against an oracle based on ground-truth retrieval sufficiency. This will be performed on a subset of multi-hop questions from the benchmarks, with discussion of cases where hallucination or overconfidence may affect reliability. We believe this addition will directly address the load-bearing nature of the claim. revision: yes
-
Referee: [Experiments] The experimental validation of the superior trade-off is difficult to assess without details on data splits, exact reward formulations (including the self-answering and stabilization terms), ablation studies isolating the RL components, and statistical significance of gains over baselines. The abstract reports benchmark improvements but does not address potential post-hoc tuning or sensitivity to the minimal-sufficient-depth definition.
Authors: We agree that the current experimental section lacks sufficient detail for full reproducibility and assessment of robustness. The manuscript reports aggregate benchmark results but omits explicit data split descriptions, full reward equations, component ablations, and statistical testing. In the revised version, we will expand the Experiments section to include: (i) precise descriptions of train/validation/test splits for all datasets, (ii) the complete mathematical formulations of the self-answering reward, over-search penalty, and all stabilization terms, (iii) ablation studies that systematically isolate each RL component (e.g., variants without the self-answering reward or without stabilization), and (iv) statistical significance results (e.g., mean and standard deviation over 5 random seeds with paired t-test p-values) for all reported gains. We will also add a sensitivity analysis subsection examining performance under different definitions of minimal sufficient depth and clarify the hyperparameter selection protocol (including any tuning procedures) to rule out post-hoc concerns. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper first empirically investigates the relationship between search depth and accuracy to identify a minimal sufficient depth determined by question complexity and agent capability, then introduces an RL framework that rewards attainment of this depth via a self-answering mechanism. This structure does not reduce any claimed prediction or result to its inputs by construction, nor does it rely on self-citations, uniqueness theorems, or ansatzes smuggled from prior work. The self-answering reward is an explicit design choice in the RL objective rather than a tautological redefinition, and the abstract presents the method as a new training procedure without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-generated intermediate answers provide a reliable signal for whether sufficient information has been retrieved.
Reference graph
Works this paper leans on
-
[1]
Your group-relative advantage is biased.arXiv preprint arXiv:2601.08521, 2026
Your Group-Relative Advantage Is Biased , author=. arXiv preprint arXiv:2601.08521 , year=
-
[2]
Advances in Neural Information Processing Systems , year=
Equilibrium Policy Generalization: A Reinforcement Learning Framework for Cross-Graph Zero-Shot Generalization in Pursuit-Evasion Games , author=. Advances in Neural Information Processing Systems , year=
-
[3]
Advances in Neural Information Processing Systems , year=
Videos are Sample-Efficient Supervisions: Behavior Cloning from Videos via Latent Representations , author=. Advances in Neural Information Processing Systems , year=
-
[4]
The Thirteenth International Conference on Learning Representations , year=
Unsupervised zero-shot reinforcement learning via dual-value forward-backward representation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Saliency-Guided Representation with Consistency Policy Learning for Visual Unsupervised Reinforcement Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[6]
Chao Wang, Hehe Fan, Huichen Yang, Zhengdong Hu, Sarvnaz Karimi, Lina Yao, and Yi Yang
Perception-Consistency Multimodal Large Language Models Reasoning via Caption-Regularized Policy Optimization , author=. arXiv preprint arXiv:2509.21854 , year=
-
[7]
The Fourteenth International Conference on Learning Representations , year=
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Rlae: Reinforcement learning-assisted ensemble for llms , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Promoting efficient reasoning with verifiable stepwise reward , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[10]
Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning (LAW) , year=
Acting Less is Reasoning More! Teaching Model to Act Efficiently , author=. Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning (LAW) , year=
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
A survey on rag meeting llms: Towards retrieval-augmented large language models , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , year=
Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL , author=. Advances in Neural Information Processing Systems , year=
-
[15]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the Second Conference on Language Modeling (COLM) , year=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. Proceedings of the Second Conference on Language Modeling (COLM) , year=
-
[18]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
R1-searcher: Incentivizing the search capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2503.05592 , year=
work page internal anchor Pith review arXiv
-
[19]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
StepSearch: Igniting LLMs search ability via step-wise proximal policy optimization , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[20]
arXiv preprint arXiv:2508.12800 , year=
Atom-searcher: Enhancing agentic deep research via fine-grained atomic thought reward , author=. arXiv preprint arXiv:2508.12800 , year=
-
[21]
R1-searcher++: Incentivizing the dynamic knowledge acquisition of llms via reinforcement learning , author=. arXiv preprint arXiv:2505.17005 , year=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
The Fourteenth International Conference on Learning Representations , year=
HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[24]
Proceedings of the 61st annual meeting of the association for computational linguistics (ACL) , pages=
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (ACL) , pages=
-
[25]
The Eleventh International Conference on Learning Representations , year=
Generate rather than retrieve: Large language models are strong context generators , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Replug: Retrieval-augmented black-box language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[27]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Rearter: Retrieval-augmented reasoning with trustworthy process rewarding , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[28]
ToolRL: Reward is All Tool Learning Needs
Toolrl: Reward is all tool learning needs , author=. arXiv preprint arXiv:2504.13958 , year=
work page internal anchor Pith review arXiv
-
[29]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Smartcal: An approach to self-aware tool-use evaluation and calibration , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2024
-
[30]
The Fourteenth International Conference on Learning Representations , year=
Unlocking Long-Horizon Agentic Search with Large-Scale End-to-End RL , author=. The Fourteenth International Conference on Learning Representations , year=
-
[31]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[32]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
When Not to Trust Language Models: Investigating Effectiveness and Limitations of Parametric and Non-Parametric Memories , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[34]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[35]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[36]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=
-
[37]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[38]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[39]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.