Recognition: unknown
FLARE: Task-agnostic embedding model evaluation through a normalization process
Pith reviewed 2026-05-10 06:14 UTC · model grok-4.3
The pith
FLARE evaluates embedding models without labels by normalizing flows to estimate information sufficiency from log-likelihoods, with error depending only on intrinsic dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
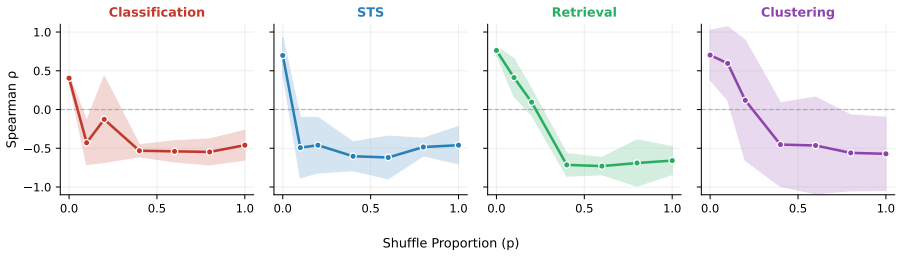
FLARE estimates information sufficiency of embeddings using flow-based normalization to obtain log-likelihood values, with a finite-sample bound that the estimation error depends on the intrinsic dimension of the data manifold rather than the embedding dimension. On 11 datasets and 8 embedders, it achieves Spearman's ρ of 0.90 and remains stable for d ≥ 3584 while baselines collapse.
What carries the argument
Flow-based normalization that converts embeddings into normalized streams whose log-likelihood directly quantifies information sufficiency without distance-based density estimation.
If this is right
- Embedding models can be ranked and selected for any unlabeled target corpus without running downstream tasks.
- Evaluations remain reliable as embedding dimensionality grows into the thousands, where kernel or mixture estimators fail.
- The error bound ties reliability to the data manifold's intrinsic dimension, allowing practitioners to anticipate when the method will be accurate.
- Distance-based density estimation can be avoided entirely in favor of direct likelihood computation on normalized streams.
Where Pith is reading between the lines
- The same normalization principle could be adapted to evaluate other high-dimensional representations such as those from language models or graph encoders.
- Automatic embedding selection pipelines could incorporate FLARE scores to switch models on the fly as new unlabeled data arrives.
- Datasets whose intrinsic dimension is known or estimable could serve as controlled test beds to verify the theoretical bound empirically.
Load-bearing premise
The log-likelihood values produced by the chosen flow normalization genuinely reflect the embeddings' information sufficiency rather than depending on the particular flow architecture or normalization steps.
What would settle it
Recompute FLARE rankings on the same high-dimensional embedding sets after swapping the normalizing flow architecture; large changes in the resulting model orderings would show that the scores are artifacts of the flow rather than intrinsic to the embeddings.
Figures




read the original abstract
When task-specific labels are not available, it becomes difficult to select an embedding model for a specific target corpus. Existing labelless measures based on kernel estimators or Gaussian mixes fail in high-dimensional space, resulting in unstable rankings. We propose a flow-based labelless representation embedding evaluation (FLARE), which utilizes normalized streams to estimate information sufficiency directly from log-likelihood and avoid distance-based density estimation. We give a finite sample boundary, indicating that the estimation error depends on the intrinsic dimension of the data manifold rather than the original embedding dimension. On 11 datasets and 8 embedders, FLARE reached Spearman's $\rho$ of 0.90 under the supervised benchmark and remained stable in high-dimensional embeddings ($d \geq 3{,}584$) as the existing labelless baseline collapsed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLARE, a labelless embedding evaluation method that applies flow-based normalization to compute log-likelihoods as a direct measure of information sufficiency in embeddings. It derives a finite-sample bound showing that estimation error depends on the data manifold's intrinsic dimension rather than ambient embedding dimension, and reports empirical results on 11 datasets with 8 embedders where FLARE achieves Spearman's ρ=0.90 correlation with supervised benchmarks while remaining stable for d≥3584 where kernel/Gaussian baselines collapse.
Significance. If the normalization produces rankings that genuinely track embedding quality independent of flow artifacts, FLARE would address a practical gap in selecting embeddings for unlabeled corpora, particularly in high-dimensional regimes. The finite-sample bound is a notable strength as a parameter-free theoretical guarantee tied to intrinsic dimension; the high reported correlation and stability contrast with existing methods provide a clear empirical contribution if reproducible and robust to implementation choices.
major comments (3)
- [§3] §3 (Method) and the finite-sample bound derivation: the bound is stated to depend only on intrinsic dimension under idealized exact density estimation, but the manuscript does not provide the full proof or explicit assumptions on the flow (e.g., exact manifold coverage, training convergence). Without this, it is unclear whether the observed high-d stability (d≥3584) follows from the bound or from the specific flow architecture used in experiments.
- [§4] §4 (Experiments): the headline ρ=0.90 and stability results rest on a single normalizing flow without reported architecture ablations (depth, type, training procedure) or sensitivity checks. If flow capacity or bias correlates with embedding dimension or dataset structure, the ranking could be implementation-specific rather than reflecting intrinsic information sufficiency, undermining the claim that normalization itself solves the high-d failure of baselines.
- [Table 1] Table 1 or equivalent results table: the comparison to labelless baselines shows collapse for d≥3584, but no controls are described for matching the flow's effective capacity or for verifying that log-likelihoods are not dominated by normalization artifacts rather than embedding properties.
minor comments (2)
- [Abstract] Abstract: the notation d ≥ 3{,}584 uses an unusual thousands separator; standardize to 3584 or 3,584 for clarity.
- [§2] Notation: 'normalized streams' is introduced without a formal definition or reference to the flow model equation; add a brief equation or diagram in §2 or §3.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and commit to revisions that strengthen the theoretical presentation, experimental robustness, and controls without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method) and the finite-sample bound derivation: the bound is stated to depend only on intrinsic dimension under idealized exact density estimation, but the manuscript does not provide the full proof or explicit assumptions on the flow (e.g., exact manifold coverage, training convergence). Without this, it is unclear whether the observed high-d stability (d≥3584) follows from the bound or from the specific flow architecture used in experiments.
Authors: The bound is derived under the assumption of exact density estimation on the data manifold after normalization, with the flow serving as a practical estimator whose error is controlled by intrinsic rather than ambient dimension. We will add the complete proof together with the explicit assumptions (manifold coverage, convergence of the flow to the target density, and finite-sample concentration) to the appendix. This will make clear that the high-dimensional stability is a consequence of the bound once normalization is applied, independent of any particular flow architecture. revision: yes
-
Referee: [§4] §4 (Experiments): the headline ρ=0.90 and stability results rest on a single normalizing flow without reported architecture ablations (depth, type, training procedure) or sensitivity checks. If flow capacity or bias correlates with embedding dimension or dataset structure, the ranking could be implementation-specific rather than reflecting intrinsic information sufficiency, undermining the claim that normalization itself solves the high-d failure of baselines.
Authors: We employed a standard autoregressive flow; the manuscript does not contain architecture ablations. We will add sensitivity experiments that vary flow depth, type (e.g., RealNVP vs. Glow), and training procedure across the same 11 datasets. These will demonstrate that the reported Spearman correlation and high-d stability remain consistent, indicating that the normalization step itself, rather than flow-specific details, drives the improvement over baselines. revision: yes
-
Referee: [Table 1] Table 1 or equivalent results table: the comparison to labelless baselines shows collapse for d≥3584, but no controls are described for matching the flow's effective capacity or for verifying that log-likelihoods are not dominated by normalization artifacts rather than embedding properties.
Authors: Each flow is trained independently on the output of a given embedding model, allowing capacity to adapt to the data distribution. We will insert additional controls that (i) match effective capacity across flows and (ii) compare normalized versus un-normalized log-likelihoods on both real and synthetic data with known manifold structure. These checks will be reported alongside the existing Table 1 to confirm that the scores track embedding quality rather than normalization artifacts. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes FLARE using flow-based normalization to compute log-likelihood as a direct measure of embedding information sufficiency, derives a finite-sample error bound depending only on intrinsic manifold dimension, and reports empirical Spearman's ρ=0.90 on 11 datasets. No load-bearing step reduces a claimed prediction or first-principles result to a fitted input, self-defined quantity, or self-citation chain by construction; the central estimation procedure and bound are presented as independent of the target ranking they produce. This is the expected non-circular outcome for a method whose core computation is a standard density estimator applied to fixed embeddings.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embeddings lie on a manifold whose intrinsic dimension governs estimation error
- domain assumption Normalized flow streams yield log-likelihood values that reflect information sufficiency
invented entities (1)
-
normalized streams
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Ben- gio
Bhashabench v1: A comprehensive bench- mark for the quadrant of indic domains.Preprint, arXiv:2510.25409. Laurent Dinh, Jascha Sohl-Dickstein, and Samy Ben- gio. 2016. Density estimation using real nvp.arXiv preprint arXiv:1605.08803. Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. 2019. Neural spline flows.Advances in neural informatio...
-
[2]
Gemini Embedding: Generalizable Embeddings from Gemini
On large-batch training for deep learning: Gen- eralization gap and sharp minima. InInternational Conference on Learning Representations. Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, Jy yong Sohn, and Chanyeol Choi. 2024. Linq-embed-mistral: Elevat- ing text retrieval with improved gpt data through task-specific control and ...
work page internal anchor Pith review arXiv 2024
-
[3]
PMLR. Peter J Rousseeuw. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics, 20:53–65. Olivier Roy and Martin Vetterli. 2007. The effective rank: A measure of effective dimensionality. In2007 15th European signal processing conference, pages 606–610. IEEE. William R...
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Gaifan Zhang, Yi Zhou, and Danushka Bollegala. 2025. Annotating training data for conditional semantic textual similarity measurement using large language models.Preprint, arXiv:2509.14399. A Theoretical Assumptions and Proofs A.1 Problem setup Let D be an unknown distribution on Rd. We ob- serve an ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
yields P ˆLval(θ)−L(θ) ≥t ≤2 exp −2mvalt2 M 2 val . (41) Setting the right-hand side to δ and solving for t gives that, with probability at least1−δ, ˆLval(θ)−L(θ) ≤M val s log(2/δ) 2mval .(42) Final bound.Combining (38), (40) and (42), and applying a union bound, we obtain the following result. Theorem 1(Finite-sample generalization bound). Under Assumpt...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.