Recognition: unknown
ARMove: Learning to Predict Human Mobility through Agentic Reasoning
Pith reviewed 2026-05-10 05:29 UTC · model grok-4.3
The pith
ARMove predicts human mobility by using LLMs to reason agentically over standardized features and user profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARMove treats mobility prediction as an agentic process in which a large language model iteratively adjusts weights across four feature pools and user-profile segments to maximize next-location accuracy, then distills the resulting strategy into a smaller model. The same agent produces an interpretable trace of which features drove each decision. On four worldwide datasets the method beats prior baselines on six of twelve metrics (gains from 0.78 percent to 10.47 percent) and retains performance when transferred across regions, user cohorts, and model scales.
What carries the argument
Agentic decision-making that dynamically re-weights standardized feature pools and user profiles while emitting an explicit reasoning trace for each prediction.
If this is right
- Mobility forecasts improve enough to support more efficient transit scheduling and emergency resource placement.
- Smaller, cheaper models can be used in production once strategies are distilled from larger ones.
- Planners gain inspectable explanations for why a model expects a person to travel to a given location.
- The same framework can ingest new observations over time without full retraining.
Where Pith is reading between the lines
- The iterative weighting step may reduce reliance on massive labeled trajectory datasets if the agent can bootstrap from sparse observations.
- Similar agentic loops could be tested on related sequential tasks such as next-app prediction or supply-chain routing.
- Real-time sensor streams could be folded into the feature pools to support live rerouting applications.
Load-bearing premise
The language-model agent genuinely discovers generalizable weighting rules rather than memorizing dataset-specific prompt patterns that fail on new cities or users.
What would settle it
A held-out city or user cohort where ARMove accuracy falls below the strongest non-LLM baseline or where the generated decision traces show no consistent link to actual movement patterns.
Figures





read the original abstract
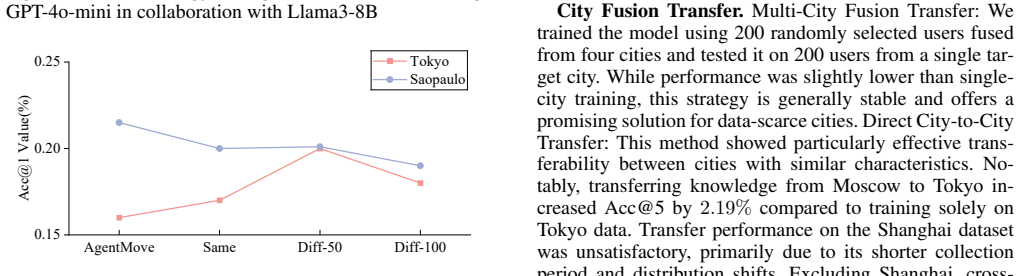
Human mobility prediction is a critical task but remains challenging due to its complexity and variability across populations and regions. Recently, large language models (LLMs) have made progress in zero-shot prediction, but existing methods suffer from limited interpretability (due to black-box reasoning), lack of iterative learning from new data, and poor transferability. In this paper, we introduce \textbf{ARMove}, a fully transferable framework for predicting human mobility through agentic reasoning. To address these limitations, ARMove employs standardized feature management with iterative optimization and user-specific customization: four major feature pools for foundational knowledge, user profiles for segmentation, and an automated generation mechanism integrating LLM knowledge. Robust generalization is achieved via agentic decision-making that adjusts feature weights to maximize accuracy while providing interpretable decision paths. Finally, large-small model synergy distills strategies from large LLMs (e.g., 72B) to smaller ones (e.g., 7B), reducing costs and enhancing performance ceilings. Extensive experiments on four global datasets show ARMove outperforms state-of-the-art baselines on 6 out of 12 metrics (gains of 0.78\% to 10.47\%), with transferability tests confirming robustness across regions, users, and scales. The other 4 items also achieved suboptimal results. Transferability tests confirm its 19 robustness across regions, user groups, and model scales, while interpretability 20 analysis highlights its transparency in decision-making. Our codes are available at: https://anonymous.4open.science/r/ARMove-F847.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ARMove, a fully transferable framework for human mobility prediction via agentic reasoning with LLMs. It uses four standardized feature pools, user profiles for segmentation, automated generation integrating LLM knowledge, iterative LLM-based optimization of feature weights to maximize accuracy while yielding interpretable decision paths, and distillation from large models (e.g., 72B) to smaller ones (e.g., 7B) for efficiency. Experiments on four global datasets claim outperformance over SOTA baselines on 6 of 12 metrics (gains 0.78%–10.47%), with transferability confirmed across regions, users, and scales plus interpretability analysis; code is linked anonymously.
Significance. If the empirical results and transferability hold, ARMove could advance mobility prediction by providing an interpretable, agentic LLM-based alternative to black-box models, addressing limitations in zero-shot LLM methods through iterative learning and distillation. This has potential for practical, generalizable applications in urban analytics and related domains, with the code release supporting reproducibility efforts.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): The abstract reports metric gains (0.78% to 10.47% on 6/12 metrics) and robustness but supplies no details on experimental protocols, error bars, statistical significance, baseline implementations, or how post-hoc adjustments were avoided, leaving the central empirical claims unsupported by visible evidence.
- [§3 (Method)] §3 (Method): The agentic decision-making process (iterative feature weight adjustment by the LLM agent, automated generation from feature pools, and large-small distillation) is claimed to produce interpretable paths and robust generalization; however, the description provides no evidence that the prompting strategy or weight-adjustment mechanism is fixed and dataset-agnostic rather than relying on per-experiment customization, which directly bears on the transferability claims.
minor comments (2)
- [Abstract] Abstract: Apparent typographical artifacts such as 'confirm its 19 robustness' and 'interpretability 20 analysis' reduce readability and should be corrected.
- [Abstract] Abstract: The statement 'The other 4 items also achieved suboptimal results' is unclear in context of 12 metrics with 6 outperforming; the manuscript should specify what the remaining metrics achieved relative to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and proposed revisions to strengthen the presentation of our empirical results and methodological details.
read point-by-point responses
-
Referee: [§4 (Experiments)] The abstract reports metric gains (0.78% to 10.47% on 6/12 metrics) and robustness but supplies no details on experimental protocols, error bars, statistical significance, baseline implementations, or how post-hoc adjustments were avoided, leaving the central empirical claims unsupported by visible evidence.
Authors: We acknowledge that the abstract provides only a high-level summary. Section 4 of the manuscript details the four global datasets, baseline implementations (following original papers with fixed hyperparameters via cross-validation), and evaluation protocols. To make the evidence more explicit, the revised version will add error bars (standard deviation over 5 runs with different seeds), p-values from paired t-tests for significance, and a dedicated subsection explicitly describing the fixed experimental protocol with no post-hoc adjustments. This will directly support the reported gains and robustness claims. revision: yes
-
Referee: [§3 (Method)] The agentic decision-making process (iterative feature weight adjustment by the LLM agent, automated generation from feature pools, and large-small distillation) is claimed to produce interpretable paths and robust generalization; however, the description provides no evidence that the prompting strategy or weight-adjustment mechanism is fixed and dataset-agnostic rather than relying on per-experiment customization, which directly bears on the transferability claims.
Authors: The prompting strategy and weight-adjustment mechanism are fixed and dataset-agnostic by design: a single standardized prompt template (detailed in the supplementary material) instructs the LLM to iteratively adjust weights from the four fixed feature pools based solely on validation accuracy feedback, with no dataset-specific instructions. User profiles use the same generation prompt across all cases. We will revise Section 3 to explicitly include the prompt templates and Algorithm 1 pseudocode, and cross-reference the transferability results in Section 4.3 (which apply the identical mechanism without customization) to substantiate the generalization claims. revision: partial
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper presents an applied ML framework (ARMove) that integrates LLMs for feature weighting and distillation, then reports empirical results on four global datasets against baselines. No mathematical derivation chain, uniqueness theorem, or first-principles claim is made that reduces to its own inputs by construction. Performance gains (on 6/12 metrics) and transferability tests are presented as experimental outcomes, not as logically forced by internal fitting definitions. The method uses standard optimization and prompting techniques whose effectiveness is measured externally rather than defined into the result. No self-citation load-bearing steps or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- feature weights
axioms (2)
- domain assumption Large language models encode useful foundational knowledge for human mobility patterns
- domain assumption Agentic reasoning can produce interpretable and transferable decision paths
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
AAAI , year=
Predicting the next location: A recurrent model with spatial and temporal contexts , author=. AAAI , year=
-
[13]
2017 , organization=
Modeling trajectories with recurrent neural networks , author=. 2017 , organization=
2017
-
[14]
Proceedings of the 2017 ACM on Conference on Information and Knowledge Management , pages=
Serm: A recurrent model for next location prediction in semantic trajectories , author=. Proceedings of the 2017 ACM on Conference on Information and Knowledge Management , pages=. 2017 , organization=
2017
-
[15]
Proceedings of the 2018 World Wide Web Conference , year=
DeepMove: Predicting Human Mobility with Attentional Recurrent Networks , author=. Proceedings of the 2018 World Wide Web Conference , year=
2018
-
[16]
The World Wide Web Conference , pages=
Predicting human mobility via variational attention , author=. The World Wide Web Conference , pages=. 2019 , organization=
2019
-
[17]
Proceedings of the AAAI conference on artificial intelligence , volume=
Where to go next: Modeling long-and short-term user preferences for point-of-interest recommendation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[18]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Geography-aware sequential location recommendation , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[19]
Proceedings of the web conference 2021 , pages=
Stan: Spatio-temporal attention network for next location recommendation , author=. Proceedings of the web conference 2021 , pages=
2021
-
[20]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Graph-flashback network for next location recommendation , author=. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[21]
2012 , publisher=
Supervised sequence labelling , author=. 2012 , publisher=
2012
-
[22]
and Le, Quoc and Zhou, Denny , title =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Chi, Ed H. and Le, Quoc and Zhou, Denny , title =. CoRR , volume =
-
[23]
ArXiv , year=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. ArXiv , year=
-
[24]
Proceedings of the National Academy of Sciences , volume=
The TimeGeo modeling framework for urban mobility without travel surveys , author=. Proceedings of the National Academy of Sciences , volume=. 2016 , publisher=
2016
-
[25]
Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages=
I know where you live: Inferring details of people's lives by visualizing publicly shared location data , author=. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages=
2016
-
[26]
International Journal of Geographical Information Science , volume=
Identifying home locations in human mobility data: an open-source R package for comparison and reproducibility , author=. International Journal of Geographical Information Science , volume=. 2021 , publisher=
2021
-
[27]
IEEE Transactions on Intelligent Transportation Systems , volume=
Visualizing the relationship between human mobility and points of interest , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2017 , publisher=
2017
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review arXiv
-
[30]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[31]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Lim, Nicholas and Hooi, Bryan and Ng, See-Kiong and Wang, Xueou and Goh, Yong Liang and Weng, Renrong and Varadarajan, Jagannadan , booktitle=
-
[34]
SIGIR'23 , pages=
Spatio-temporal hypergraph learning for next POI recommendation , author=. SIGIR'23 , pages=
-
[35]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Adaptive Graph Representation Learning for Next POI Recommendation , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Next POI recommendation with dynamic graph and explicit dependency , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
Proceedings of the 19th international conference on World wide web , pages=
Factorizing personalized markov chains for next-basket recommendation , author=. Proceedings of the 19th international conference on World wide web , pages=
-
[38]
Twenty-Third international joint conference on Artificial Intelligence , year=
Where you like to go next: Successive point-of-interest recommendation , author=. Twenty-Third international joint conference on Artificial Intelligence , year=
-
[39]
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct , author=. arXiv preprint arXiv:2308.09583 , year=
-
[40]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review arXiv
-
[41]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[42]
The Rise and Potential of Large Language Model Based Agents: A Survey
The rise and potential of large language model based agents: A survey , author=. arXiv preprint arXiv:2309.07864 , year=
work page internal anchor Pith review arXiv
-
[43]
ChatDev: Communicative Agents for Software Development
Communicative agents for software development , author=. arXiv preprint arXiv:2307.07924 , volume=
work page internal anchor Pith review arXiv
-
[44]
A real-world webagent with planning, long context understanding, and program synthesis , author=. arXiv preprint arXiv:2307.12856 , year=
-
[45]
Where would i go next? large language models as human mobility predictors , author=. arXiv preprint arXiv:2308.15197 , year=
-
[46]
arXiv preprint arXiv:2405.20962 , year=
Large Language Models are Zero-Shot Next Location Predictors , author=. arXiv preprint arXiv:2405.20962 , year=
-
[47]
Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies , volume=
Sume: Semantic-enhanced urban mobility network embedding for user demographic inference , author=. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies , volume=. 2020 , publisher=
2020
-
[48]
DefInt: A Default-interventionist Framework for Efficient Reasoning with Hybrid Large Language Models , author=. arXiv preprint arXiv:2402.02563 , year=
-
[49]
Chenyang Shao, Fengli Xu, Bingbing Fan, Jingtao Ding, Yuan Yuan, Meng Wang, and Yong Li
Beyond imitation: Generating human mobility from context-aware reasoning with large language models , author=. arXiv preprint arXiv:2402.09836 , year=
-
[50]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Large Language Model-driven Meta-structure Discovery in Heterogeneous Information Network , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[51]
arXiv preprint arXiv:2402.14744 , year=
Large language models as urban residents: An llm agent framework for personal mobility generation , author=. arXiv preprint arXiv:2402.14744 , year=
-
[52]
Time2Vec: Learning a Vector Representation of Time
Time2vec: Learning a vector representation of time , author=. arXiv preprint arXiv:1907.05321 , year=
work page Pith review arXiv 1907
-
[53]
arXiv preprint arXiv:2410.14970 , year=
Taming the long tail in human mobility prediction , author=. arXiv preprint arXiv:2410.14970 , year=
-
[54]
Scientific Data , volume=
YJMob100K: City-scale and longitudinal dataset of anonymized human mobility trajectories , author=. Scientific Data , volume=. 2024 , publisher=
2024
-
[55]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[56]
Lee, JungMi and Seel, Norbert M. Schema-Based Learning. Encyclopedia of the Sciences of Learning. 2012. doi:10.1007/978-1-4419-1428-6_1663
-
[57]
arXiv preprint arXiv:2410.08164 , year =
Agent s: An open agentic framework that uses computers like a human , author=. arXiv preprint arXiv:2410.08164 , year=
-
[58]
LLMLight: Large Language Models as Traffic Signal Control Agents , author=. arXiv preprint arXiv:2312.16044 , year=
-
[59]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 , year=
A Universal Model for Human Mobility Prediction , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 , year=
-
[60]
2025 , eprint=
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows , author=. 2025 , eprint=
2025
-
[61]
2025 , eprint=
Do as We Do, Not as You Think: the Conformity of Large Language Models , author=. 2025 , eprint=
2025
-
[62]
2025 , eprint=
AFlow: Automating Agentic Workflow Generation , author=. 2025 , eprint=
2025
-
[63]
2025 , eprint=
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models , author=. 2025 , eprint=
2025
-
[64]
2025 , eprint=
REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context in New Environments , author=. 2025 , eprint=
2025
-
[65]
2025 , eprint=
Active Task Disambiguation with LLMs , author=. 2025 , eprint=
2025
-
[66]
2024 , eprint=
Internet of Agents: Weaving a Web of Heterogeneous Agents for Collaborative Intelligence , author=. 2024 , eprint=
2024
-
[67]
2025 , eprint=
SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation , author=. 2025 , eprint=
2025
-
[68]
2025 , eprint=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
Synergistic Multi-Agent Framework with Trajectory Learning for Knowledge-Intensive Tasks , author=. 2025 , eprint=
2025
-
[70]
2025 , eprint=
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks , author=. 2025 , eprint=
2025
-
[71]
2025 , eprint=
Agent models: Internalizing Chain-of-Action Generation into Reasoning models , author=. 2025 , eprint=
2025
-
[72]
2025 , eprint=
Agentic Reasoning: A Streamlined Framework for Enhancing LLM Reasoning with Agentic Tools , author=. 2025 , eprint=
2025
-
[73]
2025 , eprint=
CAMS: A CityGPT-Powered Agentic Framework for Urban Human Mobility Simulation , author=. 2025 , eprint=
2025
-
[74]
2025 , eprint=
MINTQA: A Multi-Hop Question Answering Benchmark for Evaluating LLMs on New and Tail Knowledge , author=. 2025 , eprint=
2025
-
[75]
2025 , eprint=
UrbanLLaVA: A Multi-modal Large Language Model for Urban Intelligence with Spatial Reasoning and Understanding , author=. 2025 , eprint=
2025
-
[76]
2025 , eprint=
Mitigating Geospatial Knowledge Hallucination in Large Language Models: Benchmarking and Dynamic Factuality Aligning , author=. 2025 , eprint=
2025
-
[77]
2025 , eprint=
CityGPT: Empowering Urban Spatial Cognition of Large Language Models , author=. 2025 , eprint=
2025
-
[78]
2025 , eprint=
TrajAgent: An LLM-Agent Framework for Trajectory Modeling via Large-and-Small Model Collaboration , author=. 2025 , eprint=
2025
-
[79]
GETNext: Trajectory Flow Map Enhanced Transformer for Next POI Recommendation , url=
Yang, Song and Liu, Jiamou and Zhao, Kaiqi , year=. GETNext: Trajectory Flow Map Enhanced Transformer for Next POI Recommendation , url=. doi:10.1145/3477495.3531983 , booktitle=
-
[80]
2025 , eprint=
AgentMove: A Large Language Model based Agentic Framework for Zero-shot Next Location Prediction , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.