Recognition: unknown
Robust Deep FOSLS for Transmission Problems
Pith reviewed 2026-05-10 05:40 UTC · model grok-4.3
The pith
A weighted FOSLS formulation lets neural networks solve transmission problems robustly by keeping the loss equivalent to the energy norm regardless of material parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The weighted FOSLS functional is equivalent to a natural energy norm of the transmission problem equations with constants independent of material parameters, and its integral-loss form exhibits passive variance reduction in which gradient variance decreases as the loss value decreases.
What carries the argument
Weighted first-order system least-squares (FOSLS) formulation incorporating an energy-norm Poincaré constant.
If this is right
- The optimization remains aligned with a meaningful error measure at arbitrary material contrast.
- The gradient estimates exhibit decreasing variance as training loss decreases, unlike VPINNs and Deep Ritz methods.
- ReQU activation allows approximation of discontinuous solutions without typical overshoots of smooth networks.
- The reduced-order neural network approach with least-squares coefficient computation produces accurate solutions in 1D and 2D interface problems.
Where Pith is reading between the lines
- If the equivalence holds in practice, the method could be applied to time-dependent or nonlinear transmission problems where parameter independence is critical.
- The passive variance reduction might improve training stability in other physics-informed neural network formulations.
- Extensions to three dimensions would require verifying that the neural network can still capture the interface behavior effectively.
Load-bearing premise
The neural network architecture and activation can represent the solution well enough for the theoretical equivalence to guide the actual optimization process without introducing new instabilities.
What would settle it
Numerical counterexample where, despite decreasing loss, the computed solution error in the energy norm does not decrease proportionally, or where gradient variance does not reduce with loss.
Figures







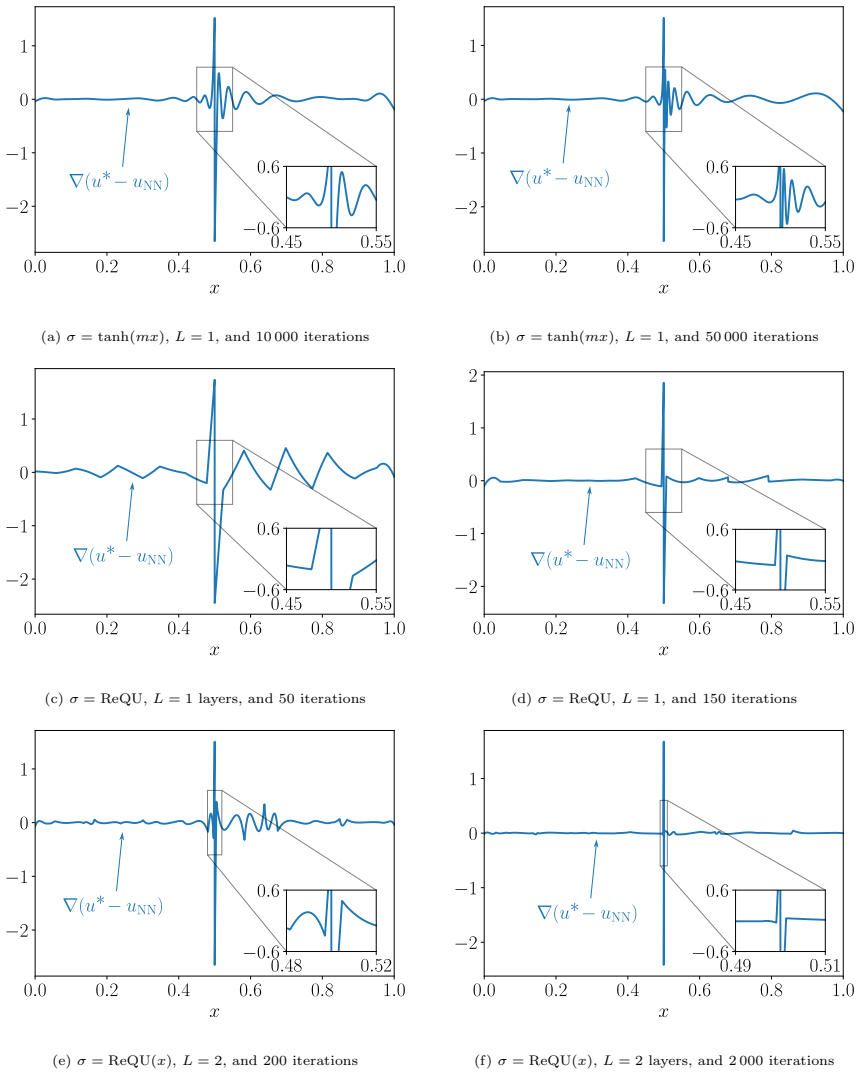

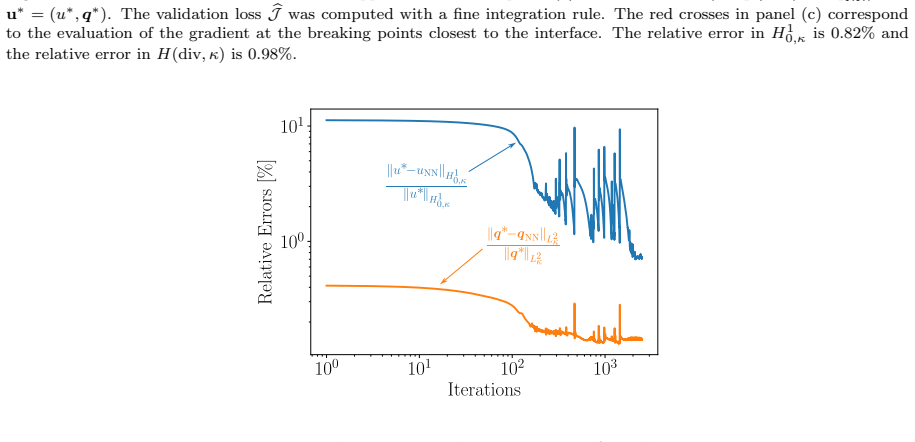
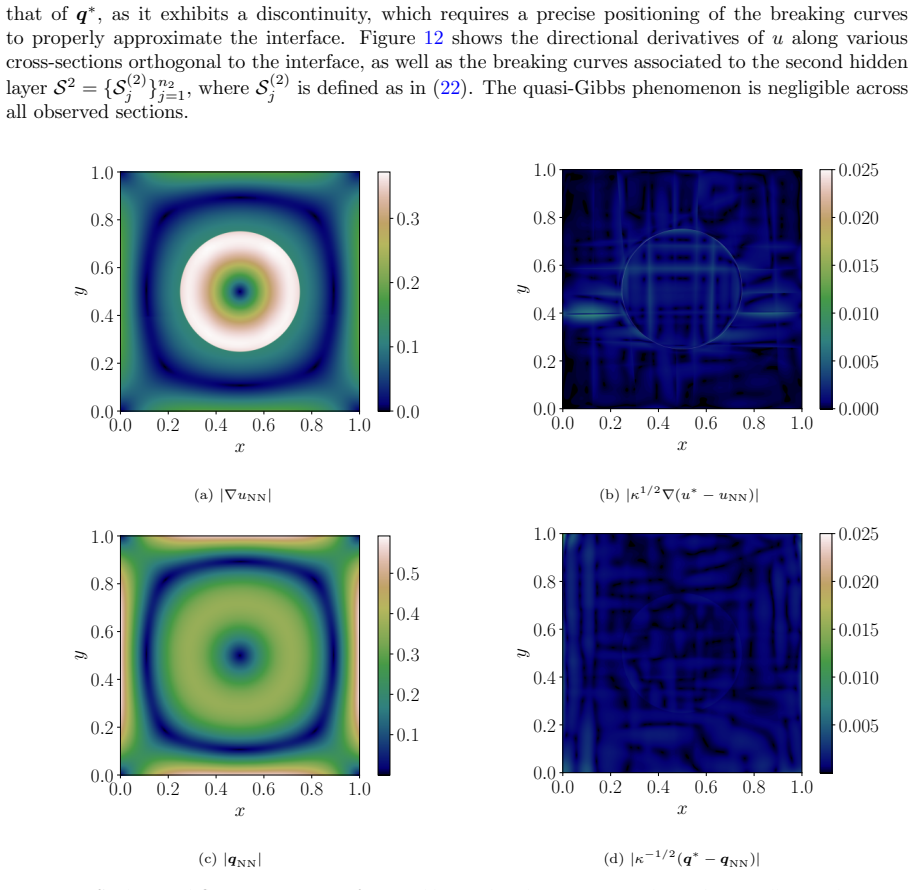

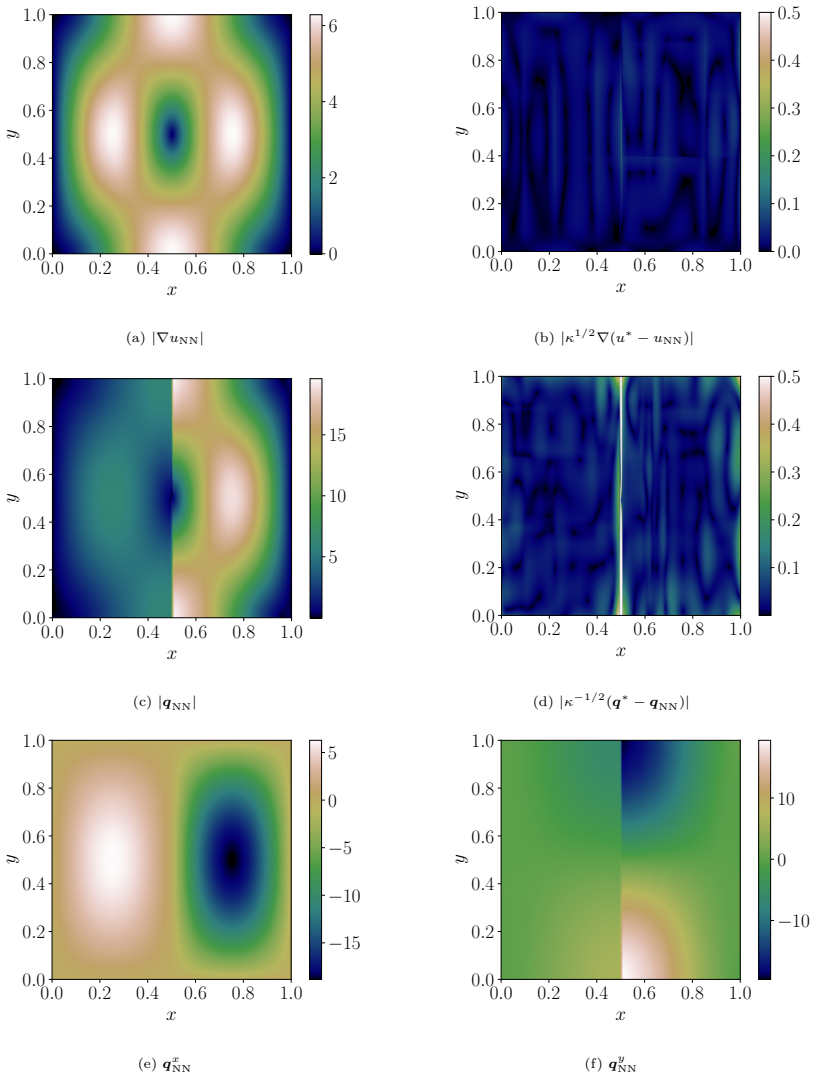

read the original abstract
This work presents a robust, energy-based deep learning framework for solving transmission problems in heterogeneous media, including cases with discontinuous material scenarios. We introduce a weighted First-Order System Least-Squares (FOSLS) formulation involving an energy-norm Poincar\'e constant and prove its equivalence to a natural energy norm of the underlying equations, with constants independent of material parameters. As a result, the optimization landscape remains aligned with a meaningful error approximation even under high material contrast, where standard neural network losses often deteriorate. We further prove that the FOSLS formulation, together with its integral-loss representation, exhibits a passive variance reduction property, whereby the gradient variance progressively decreases as the loss diminishes, in contrast to methods such as VPINNs and Deep Ritz. From a numerical standpoint, we adopt a reduced-order perspective by constructing a low-dimensional space described by a neural network. The optimal coefficients are computed via a least-squares solver, and the space is subsequently improved through gradient-based updates. By selecting the activation function ReQU, the method mitigates the spurious overshoots typically observed in smooth networks when approximating discontinuities. Numerical experiments in 1D and 2D interface settings corroborate these findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a weighted First-Order System Least-Squares (FOSLS) formulation for transmission problems in heterogeneous media with discontinuous coefficients. It proves equivalence of this weighted loss to a natural energy norm with constants independent of material parameters, establishes a passive variance-reduction property for the integral-loss representation, and proposes a reduced-order neural-network solver using ReQU activations in which optimal coefficients are obtained by least-squares and the network is refined by gradient updates. Numerical experiments in one and two dimensions are presented to support the claims.
Significance. If the continuous-level equivalence and variance-reduction results hold and are shown to be inherited by the neural-network trial space, the work would supply a theoretically grounded, robust alternative to standard variational losses for high-contrast interface problems. The material-independent constants and the contrast with VPINNs/Deep Ritz on variance behavior are genuine strengths; the hybrid least-squares-plus-gradient reduced-order perspective is also a constructive contribution.
major comments (2)
- [Abstract and theoretical sections] Abstract and theoretical sections: the claimed equivalence of the weighted FOSLS to the energy norm with constants independent of the material jump is load-bearing for the robustness statement, yet the manuscript does not demonstrate that these constants remain uniform once the trial space is restricted to the finite-dimensional ReQU neural-network manifold; without this inheritance the optimization-landscape claim for extreme contrasts is not secured.
- [Numerical method description] Numerical method description: the passive variance-reduction property is proved at the continuous level, but it is not shown that the property survives the reduced-order optimization (least-squares coefficient solve followed by gradient steps on the network parameters) when the interface geometry is non-trivial or the contrast is large; this gap directly affects the practical reliability asserted in the abstract.
minor comments (2)
- [Theoretical formulation] The precise weighting that incorporates the energy-norm Poincaré constant should be written explicitly (including any dependence on the contrast) so that readers can verify independence.
- [Numerical experiments] Numerical experiments would be strengthened by reporting the network depth/width, the number of quadrature points, and the precise stopping criterion for the least-squares coefficient solve.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The points raised correctly identify that our theoretical results on equivalence and variance reduction are established at the continuous level, while the neural-network implementation is a reduced-order method. We respond point by point below, clarifying the scope of the analysis and outlining targeted revisions.
read point-by-point responses
-
Referee: [Abstract and theoretical sections] Abstract and theoretical sections: the claimed equivalence of the weighted FOSLS to the energy norm with constants independent of the material jump is load-bearing for the robustness statement, yet the manuscript does not demonstrate that these constants remain uniform once the trial space is restricted to the finite-dimensional ReQU neural-network manifold; without this inheritance the optimization-landscape claim for extreme contrasts is not secured.
Authors: We agree that the manuscript establishes the equivalence of the weighted FOSLS loss to the energy norm with material-independent constants only at the continuous level. The ReQU network defines a finite-dimensional trial space in the reduced-order solver, where coefficients are obtained by least-squares and parameters are updated by gradients. The paper does not contain a rigorous proof that the same uniform constants hold exactly on this manifold. By the universal approximation properties of ReQU networks in the relevant Sobolev spaces, the constants can be made arbitrarily close to the continuous-case values for sufficiently wide networks, but this is an approximation argument rather than a direct inheritance proof. In the revised manuscript we will add a dedicated remark in the theoretical section discussing the density of the ReQU trial space and its implications for the optimization landscape, together with additional numerical diagnostics (e.g., computed loss-to-energy-norm ratios across increasing network widths) for the highest-contrast test cases. revision: partial
-
Referee: [Numerical method description] Numerical method description: the passive variance-reduction property is proved at the continuous level, but it is not shown that the property survives the reduced-order optimization (least-squares coefficient solve followed by gradient steps on the network parameters) when the interface geometry is non-trivial or the contrast is large; this gap directly affects the practical reliability asserted in the abstract.
Authors: The passive variance-reduction result is proved for the continuous integral-loss representation. In the reduced-order procedure the least-squares coefficient solve is exact for any fixed network parameters, after which only the network parameters are updated by gradient descent. While we do not supply a theoretical proof that variance reduction is preserved exactly under this hybrid iteration for arbitrary interfaces and contrasts, the numerical experiments already include high-contrast 1-D and 2-D transmission problems with non-trivial interfaces, and the observed optimization trajectories remain stable. In the revision we will augment the numerical section with explicit plots of gradient variance versus iteration number for the 2-D high-contrast example, thereby supplying empirical confirmation that the practical behavior aligns with the continuous-level property. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core claims rest on explicit mathematical proofs that the weighted FOSLS formulation is equivalent to a natural energy norm (with material-independent constants) and that the integral-loss form yields passive variance reduction. These steps are derived at the continuous level from the underlying PDE system and are not obtained by fitting parameters to data, redefining quantities in terms of themselves, or importing uniqueness results solely via self-citation. The reduced-order NN discretization is presented as a numerical realization of the already-proven continuous properties rather than a redefinition of them. No load-bearing step reduces by construction to its own inputs, and the derivation remains self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of a Poincaré constant for the weighted first-order system that is independent of material jumps
- domain assumption The neural network with ReQU activation lies in a space dense enough to approximate discontinuous solutions
Reference graph
Works this paper leans on
-
[1]
A. Bonito, R. A. DeVore, R. H. Nochetto, Adaptive Finite Element Methods for Elliptic Problems with Discontinuous Coefficients, SIAM Journal on Numerical Analysis 51 (6) (2013) 3106–3134.doi:10.1137/130905757
-
[2]
On the Gibbs Phenomenon and Its Resolution,
D. Gottlieb, C.-W. Shu, On the Gibbs Phenomenon and Its Resolution, SIAM Review 39 (4) (1997) 644–668.doi: 10.1137/S0036144596301390
-
[3]
M. Raissi, P. Perdikaris, G. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707.doi:10.1016/j.jcp.2018.10.045
-
[4]
Y. Jiao, Y. Lai, D. Li, X. Lu, F. Wang, Y. Wang, J. Z. Yang, A Rate of Convergence of Physics Informed Neu- ral Networks for the Linear Second Order Elliptic PDEs, Communications in Computational Physics 31 (4) (2022) 1272–1295.doi:10.4208/cicp.oa-2021-0186
-
[5]
S. Cai, Z. Mao, Z. Wang, M. Yin, G. E. Karniadakis, Physics-informed neural networks (PINNs) for fluid mechanics: a review, Acta Mechanica Sinica 37 (12) (2021) 1727–1738.doi:10.1007/s10409-021-01148-1
-
[6]
J. M. Taylor, D. Pardo, I. Muga, A Deep Fourier Residual method for solving PDEs using Neural Networks, Computer Methods in Applied Mechanics and Engineering 405 (2023) 115850.doi:10.1016/j.cma.2022.115850
-
[7]
E. Kharazmi, Z. Zhang, G. E. Karniadakis, Variational Physics-Informed Neural Networks For Solving Partial Differ- ential Equations (2019).doi:10.48550/arXiv.1912.00873
-
[8]
S. Berrone, C. Canuto, M. Pintore, Variational Physics Informed Neural Networks: the Role of Quadratures and Test Functions, Journal of Scientific Computing 92 (3) (2022) 100.doi:10.1007/s10915-022-01950-4
-
[9]
Gradient-annihilated pinns for solving riemannproblems:Applicationtorelativistichydrodynamics
S. Rojas, P. Maczuga, J. Mu˜ noz-Matute, D. Pardo, M. Paszy´ nski, Robust Variational Physics-Informed Neural Net- works, Computer Methods in Applied Mechanics and Engineering 425 (2024) 116904.doi:10.1016/j.cma.2024. 116904
-
[10]
W. E, B. Yu, The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving Variational Problems, Communications in Mathematics and Statistics 6 (1) (2018) 1–12.doi:10.1007/s40304-018-0127-z
-
[11]
C. Uriarte, D. Pardo, I. Muga, J. Mu˜ noz-Matute, A Deep Double Ritz Method (D2RM) for solving Partial Differential Equations using Neural Networks, Computer Methods in Applied Mechanics and Engineering 405 (2023) 115892. doi:10.1016/j.cma.2023.115892
-
[12]
Z. Cai, R. Lazarov, T. A. Manteuffel, S. F. McCormick, First-Order System Least Squares for Second-Order Partial Differential Equations: Part I, SIAM Journal on Numerical Analysis 31 (6) (1994) 1785–1799.doi:10.1137/0731091
-
[13]
P. B. Bochev, M. D. Gunzburger, Least-squares finite element methods, Vol. 166 of Applied Mathematical Sciences, Springer, New York, 2009.doi:10.1007/b13382
-
[14]
S. M¨ unzenmaier, G. Starke, First-Order System Least Squares for Coupled Stokes–Darcy Flow, SIAM Journal on Numerical Analysis 49 (1) (2011) 387–404.doi:10.1137/100805108
-
[15]
T. F¨ uhrer, M. Karkulik, Space–time least-squares finite elements for parabolic equations, Computers & Mathematics with Applications 92 (2021) 27–36.doi:10.1016/j.camwa.2021.03.004
-
[16]
P. B. Bochev, M. D. Gunzburger, A locally conservative least-squares method for Darcy flows, Communications in Numerical Methods in Engineering 24 (2) (2008) 97–110.doi:10.1002/cnm.957
-
[17]
M. Berndt, T. A. Manteuffel, S. F. McCormick, G. Starke, Analysis of First-Order System Least Squares (FOSLS) for Elliptic Problems with Discontinuous Coefficients: Part I, SIAM Journal on Numerical Analysis 43 (1) (2005) 386–408.doi:10.1137/S0036142903427688
-
[18]
M. Berndt, T. A. Manteuffel, S. F. McCormick, Analysis of First-Order System Least Squares (FOSLS) for Elliptic Problems with Discontinuous Coefficients: Part II, SIAM Journal on Numerical Analysis 43 (1) (2005) 409–436. doi:10.1137/S003614290342769X
-
[19]
Z. Cai, J. Chen, M. Liu, X. Liu, Deep least-squares methods: An unsupervised learning-based numerical method for solving elliptic PDEs, Journal of Computational Physics 420 (2020) 109707.doi:10.1016/j.jcp.2020.109707
-
[20]
F. M. Bersetche, J. P. Borthagaray, A deep First-Order System Least Squares method for solving elliptic PDEs, Computers & Mathematics with Applications 129 (2023) 136–150.doi:10.1016/j.camwa.2022.11.014
-
[21]
T. Meissner, E. Huynh, P. Kuberry, P. Bochev, A deep least-squares method for the Stokes equations, Computers & Mathematics with Applications 196 (2025) 1–12.doi:10.1016/j.camwa.2025.07.004
-
[22]
Y. Qiu, W. Dahmen, P. Chen, Variationally correct operator learning: Reduced basis neural operator with a posteriori error estimation (2025).doi:10.48550/arXiv.2512.21319
-
[23]
M. Bachmayr, W. Dahmen, M. Oster, Variationally correct neural residual regression for parametric PDEs: on the viability of controlled accuracy, IMA Journal of Numerical Analysis (10 2025).doi:10.1093/imanum/draf073
-
[24]
P. C. Castillo, W. Dahmen, J. Gopalakrishnan, DPG loss functions for learning parameter-to-solution maps by neural networks (2025).doi:10.48550/arXiv.2506.18773
-
[25]
A. Quarteroni, A. Manzoni, F. Negri, Reduced Basis Methods for Partial Differential Equations, UNITEXT, Springer, 2015.doi:10.1007/978-3-319-15431-2
-
[26]
Z. Cai, J. Chen, M. Liu, Least-squares ReLU neural network (LSNN) method for linear advection-reaction equation, Journal of Computational Physics 443 (2021) 110514.doi:10.1016/j.jcp.2021.110514
-
[27]
Z. Gao, L. Yan, T. Zhou, Failure-Informed Adaptive Sampling for PINNs, SIAM Journal on Scientific Computing 45 (4) (2023) A1971–A1994.doi:10.1137/22M1527763
-
[28]
J. M. Taylor, M. Bastidas, V. M. Calo, D. Pardo, Adaptive Deep Fourier Residual method via overlapping domain decomposition, Computer Methods in Applied Mechanics and Engineering 427 (2024) 116997.doi:10.1016/j.cma. 2024.116997
-
[29]
S. Badia, W. Li, A. F. Mart´ ın, Adaptive finite element interpolated neural networks, Computer Methods in Applied Mechanics and Engineering 437 (2025) 117806.doi:10.1016/j.cma.2025.117806
-
[30]
A. K. Sarma, S. Roy, C. Annavarapu, P. Roy, S. Jagannathan, Interface PINNs (I-PINNs): A physics-informed neural networks framework for interface problems, Computer Methods in Applied Mechanics and Engineering 429 (2024) 117135.doi:10.1016/j.cma.2024.117135
-
[31]
Z. Cai, J. Choi, M. Liu, Least-Squares Neural Network (LSNN) Method for Linear Advection-Reaction Equation: Discontinuity Interface, SIAM Journal on Scientific Computing 46 (4) (2024) C448–C478.doi:10.1137/23M1568107
-
[32]
Ern, J.-L
A. Ern, J.-L. Guermond, Advection-diffusion, Springer International Publishing, Cham, 2021, pp. 69–84.doi:10. 1007/978-3-030-57348-5_61. 25
2021
-
[33]
D. Aballay, F. Fuentes, V. Iligaray, ´Angel J. Omella, D. Pardo, M. A. S´ anchez, I. Tapia, C. Uriarte, Anr-adaptive finite element method using neural networks for parametric self-adjoint elliptic problems, Journal of Computational Physics 545 (2026) 114447.doi:10.1016/j.jcp.2025.114447
-
[34]
J. M. Taylor, D. Pardo, J. Mu˜ noz-Matute, Regularity-conforming neural networks (ReCoNNs) for solving partial differential equations, Journal of Computational Physics 532 (2025) 113954.doi:10.1016/j.jcp.2025.113954
-
[35]
A sample implementation for parallelizing divide-and-conquer algorithms on the GPU,
S. Berrone, C. Canuto, M. Pintore, N. Sukumar, Enforcing Dirichlet boundary conditions in physics-informed neural networks and variational physics-informed neural networks, Heliyon 9 (8) (2023) e18820.doi:10.1016/j.heliyon. 2023.e18820
- [36]
-
[37]
Haber, A Modified Monte-Carlo Quadrature
S. Haber, A Modified Monte-Carlo Quadrature. II, Mathematics of Computation 21 (99) (1967) 388–397.doi: 10.1090/S0025-5718-1967-0234606-9
-
[38]
J. M. Taylor, D. Pardo, Stochastic quadrature rules for solving PDEs using neural networks, Computers & Mathematics with Applications 214 (2026) 1–26.doi:10.1016/j.camwa.2026.04.002
-
[39]
C. Uriarte, M. Bastidas, D. Pardo, J. M. Taylor, S. Rojas, Optimizing Variational Physics-Informed Neural Networks Using Least Squares, Computers & Mathematics with Applications 185 (2025) 76–93.doi:10.1016/j.camwa.2025. 02.022
-
[40]
D. P. Kingma, J. Ba, Adam: A Method for Stochastic Optimization (2017).doi:10.48550/arXiv.1412.6980. Appendix A. Derivation of first eigenvalue constant for planar geometries We consider the one-dimensional problem with Ω = (0,1),x 0 ∈Ω, and homogeneous Dirichlet boundary conditions, where κ(x) = κ1,0≤x≤x 0, κ2, x 0 ≤x≤1, withκ 1, κ2 >0. Sinceκis constant...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.