Recognition: unknown
Flint: Compiler Enabled Cluster-Free Design Space Exploration for Distributed ML
Pith reviewed 2026-05-10 05:18 UTC · model grok-4.3
The pith
Flint collects workload representations for distributed machine learning from compiler intermediates before any hardware execution occurs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flint is a framework that interfaces with ML compilers to obtain workload graphs from their intermediate representations, allowing design space exploration of distributed systems at any cluster size without requiring hardware execution or post-compilation traces. The compiler performs the work of understanding and preserving model behavior, enabling flexible analysis across the stack.
What carries the argument
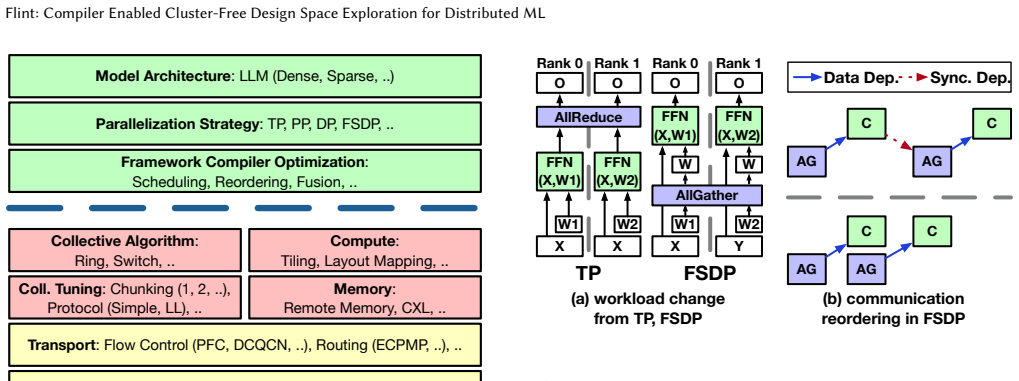
The intermediate representation (IR) from machine learning framework compilers, which encodes model computation while preserving semantics needed for distributed execution analysis.
If this is right
- Workload representations become available for any cluster size without access to matching hardware.
- Design space exploration can occur before hardware prototypes or full runs exist.
- Validation steps remain possible by comparing Flint graphs to selected hardware traces.
- Exploration can span more combinations of models, distributions, and system parameters.
Where Pith is reading between the lines
- The same compiler-IR approach could be tested on non-ML distributed workloads that have suitable compiler front ends.
- Flint-style extraction might reduce reliance on large shared test clusters for early-stage studies.
- Accuracy could be checked across multiple compilers to see how portable the representations are.
Load-bearing premise
The compiler intermediate representation must preserve all details of model behavior and performance that matter for distributed execution, so that graphs derived from it match what hardware traces would show.
What would settle it
A side-by-side comparison in which performance metrics such as communication volume, execution time, or scaling behavior predicted from a Flint workload graph differ substantially from measurements collected on real distributed hardware for the identical model and cluster configuration.
Figures







read the original abstract
Design space exploration for future distributed Machine Learning systems suffers from a lack of readily available workload representation that enables flexible exploration across the stack. We present Flint, a framework that bridges this gap by leveraging the Intermediate Representation of Machine Learning framework compilers. The compiler does the heavy weight lifting of understanding and preserving the behavior of the original model code. Flint can collect the workload representation of arbitrary cluster size because it interfaces with the compiler before hardware execution. We validate the workload graph against post-execution traces and show the flexibility of Flint through a design space exploration case study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Flint, a framework that extracts workload representations from the Intermediate Representation of ML framework compilers to enable design space exploration for distributed ML systems at arbitrary cluster sizes without requiring hardware execution. It claims that the compiler preserves original model behavior, validates the resulting graphs against post-execution traces, and demonstrates flexibility via a DSE case study.
Significance. If the IR-derived graphs accurately capture all distributed execution behaviors, Flint could meaningfully advance the field by enabling hardware-independent DSE early in the design process, lowering barriers for researchers without access to large clusters and accelerating iteration on distributed ML systems. The approach correctly credits the compiler for heavy lifting on behavior preservation and provides a concrete case study of flexibility.
major comments (2)
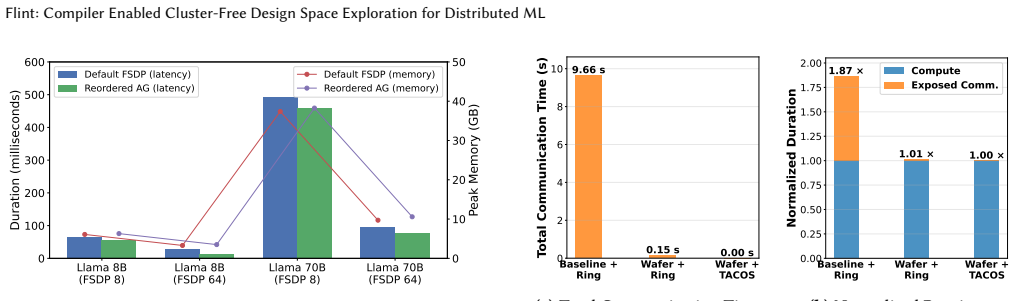
- [§4 (Validation)] §4 (Validation): The manuscript states that the workload graph is validated against post-execution traces but supplies no quantitative error metrics, fidelity statistics, or description of the IR-to-graph mapping procedure; without these, the central claim that compiler IR preserves all behavior relevant to distributed performance cannot be assessed.
- [§5 (Case Study)] §5 (Case Study): The DSE case study illustrates flexibility across cluster sizes but does not report baseline comparisons, speedup numbers, or error bounds relative to trace-based methods, leaving the practical advantage of the cluster-free approach unsubstantiated.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result from the validation (e.g., average trace mismatch).
- [§3] Notation for the extracted workload graph (nodes, edges, and attributes) should be formally defined early, perhaps with a small example table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important areas where additional detail will strengthen the presentation of Flint's validation and the substantiation of its practical advantages for cluster-free DSE.
read point-by-point responses
-
Referee: [§4 (Validation)] §4 (Validation): The manuscript states that the workload graph is validated against post-execution traces but supplies no quantitative error metrics, fidelity statistics, or description of the IR-to-graph mapping procedure; without these, the central claim that compiler IR preserves all behavior relevant to distributed performance cannot be assessed.
Authors: We agree that the current manuscript provides only a high-level statement of validation without the requested quantitative details. In the revised version we will expand §4 to include (1) a step-by-step description of the IR-to-workload-graph extraction procedure and (2) quantitative fidelity statistics, such as mean relative error and maximum deviation on communication volume, computation time, and total execution time when compared against post-execution traces. These additions will allow readers to directly assess how faithfully the compiler-derived graphs capture distributed execution behavior. revision: yes
-
Referee: [§5 (Case Study)] §5 (Case Study): The DSE case study illustrates flexibility across cluster sizes but does not report baseline comparisons, speedup numbers, or error bounds relative to trace-based methods, leaving the practical advantage of the cluster-free approach unsubstantiated.
Authors: We concur that baseline comparisons are needed to quantify the benefits of the cluster-free approach. The revised §5 will incorporate direct comparisons against trace-based DSE methods, reporting (1) wall-clock speedup of the exploration process itself and (2) error bounds (e.g., MAPE and maximum relative error) on the performance predictions produced by Flint relative to the same predictions obtained from hardware traces. This will provide concrete evidence of the practical advantage while preserving the flexibility demonstration already present. revision: yes
Circularity Check
No significant circularity
full rationale
The paper extracts a workload graph from compiler IR before hardware execution and explicitly validates this graph against post-execution traces, providing an external empirical check rather than deriving the result from its own inputs or self-citations. No equations, fitted parameters, self-definitional steps, or load-bearing self-citations appear in the abstract or description; the central claim that the IR preserves relevant distributed behavior is tested directly against real traces instead of being assumed by construction. This leaves the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MLCommons Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
Chakra introduces a portable, interoperable graph-based execution trace format for distributed ML workloads along with supporting tools to standardize performance benchmarking and software-hardware co-design.
Reference graph
Works this paper leans on
-
[1]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Ab- hinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Ra...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Na- talia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and Chauhan, Geeta and Chourdia, Anjali and Constable, Will and Desmaison, Al- ban and DeVito, Zachary and Ellison, Elias and Feng, Will and Gong, Jiong and Gschwind, Michael ...
- [3]
-
[4]
2025.https://github.com/astra-sim/symbolic%5Ftensor%5F graph
Changhai Man and Hanjiang Wu and Srinivas Sridharan and Tushar Krishna. 2025.https://github.com/astra-sim/symbolic%5Ftensor%5F graph
2025
-
[5]
Colin Unger and Zhihao Jia and Wei Wu and Sina Lin and Mandeep Baines and Carlos Efrain Quintero Narvaez and Vinay Ramakrishnaiah and Nirmal Prajapati and Pat McCormick and Jamaludin Mohd-Yusof and Xi Luo and Dheevatsa Mudigere and Jongsoo Park and Misha Smelyanskiy and Alex Aiken. 2022. Unity: Accelerating DNN Training Through Joint Optimization of Algeb...
2022
-
[6]
DeepSeek-AI and Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Ruoyu Zhang and Runxin Xu and Qihao Zhu and Shirong Ma and Peiyi Wang and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Che...
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Fan, Shiqing and Rong, Yi and Meng, Chen and Cao, Zongyan and Wang, Siyu and Zheng, Zhen and Wu, Chuan and Long, Guoping and Yang, Jun and Xia, Lixue and Diao, Lansong and Liu, Xiaoyong and Lin, Wei. 2021. DAPPLE: a pipelined data parallel approach for training large models. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Par...
-
[9]
Gangidi, Adithya and Miao, Rui and Zheng, Shengbao and Bondu, Sai Jayesh and Goes, Guilherme and Morsy, Hany and Puri, Rohit and Riftadi, Mohammad and Shetty, Ashmitha Jeevaraj and Yang, Jingyi and Zhang, Shuqiang and Fernandez, Mikel Jimenez and Gandham, Shashidhar and Zeng, Hongyi. 2024. RDMA over Ethernet for Dis- tributed Training at Meta Scale. InPro...
2024
-
[10]
Hoefler, Torsten and Siebert, Christian and Lumsdaine, Andrew. 2009. Group operation assembly language-a flexible way to express col- lective communication. In2009 International Conference on Parallel Processing. IEEE
2009
-
[11]
Isaev, Mikhail and McDonald, Nic and Dennison, Larry and Vuduc, Richard. 2023. Calculon: a methodology and tool for high-level co- design of systems and large language models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
2023
-
[12]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake VanderPlas and Skye Wanderman- Milne and Qiao Zhang. 2018. JAX: composable transformations of Python+NumPy programs.http://github.com/jax-ml/jax
2018
-
[13]
Reed and Zachary DeVito and Horace He and Ansley Ussery and Jason Ansel , title =
James K. Reed and Zachary DeVito and Horace He and Ansley Ussery and Jason Ansel. 2022. Torch.fx: Practical Program Capture and Trans- formation for Deep Learning in Python. arXiv:2112.08429 [cs.LG] https://arxiv.org/abs/2112.08429
-
[14]
Jang, Insu and Yang, Zhenning and Zhang, Zhen and Jin, Xin and Chowdhury, Mosharaf. 2023. Oobleck: Resilient Distributed Training 13 Jinsun Yoo, Meghan Cowan, Zheng Du, Changhai Man, Srinivas Sridharan, and Tushar Krishna of Large Models Using Pipeline Templates. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). Association f...
-
[15]
Lebeck and Danyang Zhuo
Jianxing Qin and Jingrong Chen and Xinhao Kong and Yongji Wu and Tianjun Yuan and Liang Luo and Zhaodong Wang and Ying Zhang and Tingjun Chen and Alvin R. Lebeck and Danyang Zhuo
-
[16]
arXiv:2505.01616 [cs.DC] https://arxiv.org/abs/2505.01616
Phantora: Maximizing Code Reuse in Simulation-based Machine Learning System Performance Estimation. arXiv:2505.01616 [cs.DC] https://arxiv.org/abs/2505.01616
- [17]
-
[18]
Keysight Technologies. 2026. Keysight AI (KAI) Data Center Builder. https://www.keysight.com/us/en/products/ethernet-traffic-emul ation/protocol-and-load-test-l2-3-emulation-software/kai-data- center-builder.html. Accessed: 2026-04-16
2026
-
[19]
Xing and Joseph E
Lianmin Zheng and Zhuohan Li and Hao Zhang and Yonghao Zhuang and Zhifeng Chen and Yanping Huang and Yida Wang and Yuanzhong Xu and Danyang Zhuo and Eric P. Xing and Joseph E. Gonzalez and Ion Stoica. 2022. Alpa: Automating Inter- and Intra-Operator Par- allelism for Distributed Deep Learning. In16th USENIX Symposium on Operating Systems Design and Implem...
2022
-
[20]
Louis Feng and Shengbao Zheng and Zhaodong Wang and Wenyin Fu and James Hongyi Zeng. 2023. Using Chakra execution traces for benchmarking and network performance optimization.https: //engineering.fb.com/2023/09/07/networking-traffic/chakra-exec ution-traces-benchmarking-network-performance-optimization/. Engineering at Meta blog, accessed April 7, 2026
2023
-
[21]
Mingyu Liang and Wenyin Fu and Louis Feng and Zhongyi Lin and Pavani Panakanti and Shengbao Zheng and Srinivas Sridharan and Christina Delimitrou. 2023. Mystique: Enabling Accurate and Scalable Generation of Production AI Benchmarks. InProceedings of the 50th Annual International Symposium on Computer Architecture (ISCA)
2023
-
[22]
Narayanan, Deepak and Harlap, Aaron and Phanishayee, Amar and Seshadri, Vivek and Devanur, Nikhil R. and Ganger, Gregory R. and Gibbons, Phillip B. and Zaharia, Matei. 2019. PipeDream: generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19). Association for Computing Machinery, ...
-
[23]
OpenAI. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Saeed Rashidi, William Won, Sudarshan Srinivasan, Puneet Gupta, and Tushar Krishna. 2025. FRED: A Wafer-scale Fabric for 3D Parallel DNN Training. InProceedings of the 52nd Annual International Sympo- sium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, NY, USA, 34–48. doi:10.1145/3695053.3731055
- [25]
- [26]
-
[27]
Sridharan, Srinivas and Heo, Taekyung and Feng, Louis and Wang, Zhaodong and Bergeron, Matt and Fu, Wenyin and Zheng, Shengbao and Coutinho, Brian and Rashidi, Saeed and Man, Changhai and others
- [28]
-
[29]
Srihas Yarlagadda and Amey Agrawal and Elton Pinto and Hakesh Darapaneni and Mitali Meratwal and Shivam Mittal and Pranavi Ba- jjuri and Srinivas Sridharan and Alexey Tumanov. 2025. Maya: Opti- mizing Deep Learning Training Workloads using Emulated Virtual Ac- celerators. arXiv:2503.20191 [cs.LG]https://arxiv.org/abs/2503.20191
-
[30]
Wanchao Liang and Tianyu Liu and Less Wright and Will Consta- ble and Andrew Gu and Chien-Chin Huang and Iris Zhang and Wei Feng and Howard Huang and Junjie Wang and Sanket Purandare and Gokul Nadathur and Stratos Idreos. 2025. TorchTitan: One- stop PyTorch native solution for production ready LLM pre-training. arXiv:2410.06511 [cs.CL]https://arxiv.org/ab...
-
[31]
Won, William and Elavazhagan, Midhilesh and Srinivasan, Sudarshan and Gupta, Swati and Krishna, Tushar. 2024. TACOS: Topology-Aware Collective Algorithm Synthesizer for Distributed Machine Learning. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). doi:10.1109/MICRO61859.2024.00068
-
[32]
Won, William and Heo, Taekyung and Rashidi, Saeed and Sridha- ran, Srinivas and Srinivasan, Sudarshan and Krishna, Tushar. 2023. ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). doi:10.1109/ISPASS57527.2023.00035
-
[33]
Xianyan Jia and Le Jiang and Ang Wang and Wencong Xiao and Ziji Shi and Jie Zhang and Xinyuan Li and Langshi Chen and Yong Li and Zhen Zheng and Xiaoyong Liu and Wei Lin. 2022. Whale: Efficient Giant Model Training over Heterogeneous GPUs. In2022 USENIX Annual Technical Conference (USENIX ATC 22). USENIX Association, Carlsbad, CA.https://www.usenix.org/co...
2022
-
[34]
Xizheng Wang and Qingxu Li and Yichi Xu and Gang Lu and Dan Li and Li Chen and Heyang Zhou and Linkang Zheng and Sen Zhang and Yikai Zhu and Yang Liu and Pengcheng Zhang and Kun Qian and Kun- ling He and Jiaqi Gao and Ennan Zhai and Dennis Cai and Binzhang Fu
-
[35]
In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25)
SimAI: Unifying Architecture Design and Performance Tuning for Large-Scale Large Language Model Training with Scalability and Precision. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). USENIX Association, Philadelphia, PA. https://www.usenix.org/conference/nsdi25/presentation/wang- xizheng-simai
-
[36]
Yoo, Jinsun and Won, William and Cowan, Meghan and Jiang, Nan and Klenk, Benjamin and Sridharan, Srinivas and Krishna, Tushar
-
[37]
In2024 IEEE Symposium on High-Performance Interconnects (HOTI)
Towards a Standardized Representation for Deep Learning Collective Algorithms. In2024 IEEE Symposium on High-Performance Interconnects (HOTI). doi:10.1109/HOTI63208.2024.00017
-
[38]
Yuanzhong Xu and HyoukJoong Lee and Dehao Chen and Blake Hecht- man and Yanping Huang and Rahul Joshi and Maxim Krikun and Dmitry Lepikhin and Andy Ly and Marcello Maggioni and Ruom- ing Pang and Noam Shazeer and Shibo Wang and Tao Wang and Yonghui Wu and Zhifeng Chen. 2021. GSPMD: General and Scalable Parallelization for ML Computation Graphs. arXiv:2105...
-
[39]
Zhu, Zhanda and Giannoula, Christina and Andoorveedu, Muralidhar and Su, Qidong and Mangalam, Karttikeya and Zheng, Bojian and Pekhimenko, Gennady. 2025. Mist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization. In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys ’25). Association fo...
-
[40]
Ziheng Jiang and Haibin Lin and Yinmin Zhong and Qi Huang and Yangrui Chen and Zhi Zhang and Yanghua Peng and Xiang Li and Cong Xie and Shibiao Nong and Yulu Jia and Sun He and Hongmin Chen and Zhihao Bai and Qi Hou and Shipeng Yan and Ding Zhou 14 Flint: Compiler Enabled Cluster-Free Design Space Exploration for Distributed ML and Yiyao Sheng and Zhuo Ji...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.