Recognition: unknown
The Multi-Block DC Function Class: Theory, Algorithms, and Applications
Pith reviewed 2026-05-10 05:35 UTC · model grok-4.3
The pith
The multi-block DC class allows polynomial-size decompositions for models that require exponential size under standard DC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the multi-block DC class strictly contains ordinary DC programming and is more powerful, because standard models such as polynomials and tensor factorizations admit only exponential-size DC decompositions while their multi-block versions remain polynomial, and because explicit multi-block formulations can be written for deep ReLU networks.
What carries the argument
The multi-block DC decomposition, which writes a function as a difference of two convex functions defined separately over each parameter block rather than a single global pair of convex functions.
If this is right
- Polynomials and tensor factorizations admit polynomial-size multi-block DC decompositions.
- Deep ReLU networks possess explicit multi-block DC formulations.
- Optimization algorithms for multi-block DC functions achieve non-asymptotic convergence in both batch and stochastic settings.
- The class applies directly to several modern nonconvex tasks in machine learning and optimization.
Where Pith is reading between the lines
- Practitioners could derive closed-form decompositions for additional structured nonconvex functions not covered in the paper.
- The block separation may combine with existing block-coordinate methods to produce hybrid solvers with improved scaling.
- Empirical timing comparisons on tensor completion or network training tasks would quantify whether the polynomial size translates to faster run times.
- Similar block-structured relaxations might apply to other difference-based function classes beyond DC.
Load-bearing premise
Explicit polynomial-size multi-block DC decompositions can be constructed for polynomials, tensor factorizations, and deep ReLU networks without hidden exponential cost in the construction itself.
What would settle it
A specific polynomial or ReLU network for which every multi-block DC decomposition requires exponential size in the number of variables or layers would falsify the separation and constructivity claims.
Figures

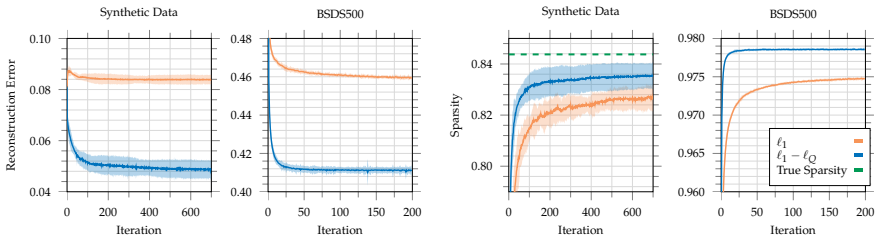
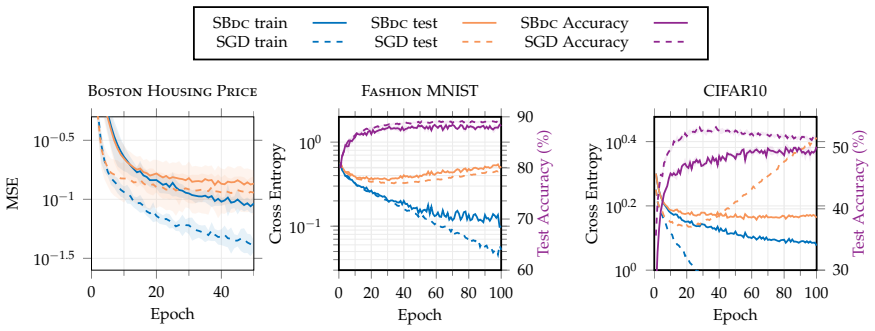

read the original abstract
We present the Multi-Block DC (BDC) class, a rich class of structured nonconvex functions that admit a DC ("difference-of-convex") decomposition across parameter blocks. This multi-block class not only subsumes the usual DC programming, but also turns out to be provably more powerful. Specifically, we demonstrate how standard models (e.g., polynomials and tensor factorization) must have DC decompositions of exponential size, while their BDC formulation is polynomial. This separation in complexity also underscores another key aspect: unlike DC formulations, obtaining BDC formulations for problems is vastly easier and constructive. We illustrate this aspect by presenting explicit BDC formulations for modern tasks such as deep ReLU networks, a result with no known equivalent in the DC class. Moreover, we complement the theory by developing algorithms with non-asymptotic convergence theory, including both batch and stochastic settings, and demonstrate the broad applicability of our method through several applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multi-Block DC (BDC) function class, a structured generalization of standard DC functions in which the difference-of-convex decomposition is performed across multiple parameter blocks. It claims to establish a complexity separation showing that standard models (polynomials, tensor factorization) require exponential-size DC decompositions under the paper's representation measure while admitting polynomial-size BDC formulations, supplies explicit constructive BDC decompositions for deep ReLU networks (with no known DC equivalent), and derives non-asymptotic convergence guarantees for both batch and stochastic algorithms together with illustrative applications.
Significance. If the explicit constructions and separation results hold, the BDC class would provide a strictly more powerful yet tractable framework for nonconvex optimization than classical DC programming. The constructive polynomial-size formulations for modern models such as deep ReLU networks, combined with matching exponential lower bounds on ordinary DC size and non-asymptotic convergence theory for batch and stochastic variants, constitute a clear strength that could enable new algorithmic approaches in machine learning and tensor optimization.
minor comments (3)
- [Complexity analysis] The precise definition of the representation measure used for the DC versus BDC size comparison should be stated once in a dedicated subsection and cross-referenced in the complexity theorems to make the separation fully self-contained.
- [Algorithmic development] In the algorithmic sections, the dependence of the convergence rates on the number of blocks should be made explicit (e.g., in the statement of the main convergence theorem) so that readers can immediately see the scaling with respect to the multi-block structure.
- [Applications and examples] A short table summarizing the BDC decompositions for the running examples (polynomials, tensor factorization, ReLU networks) would improve readability and allow quick comparison of the polynomial versus exponential sizes.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report recognizes the key contributions of the Multi-Block DC class, including the complexity separation from standard DC programming, constructive polynomial-size formulations for deep ReLU networks, and non-asymptotic convergence results for batch and stochastic algorithms. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivations are constructive and independent
full rationale
The paper defines the BDC class and supplies explicit, polynomial-size BDC decompositions for polynomials, tensor factorizations, and deep ReLU networks, paired with separate exponential lower bounds on ordinary DC size under the stated representation measure. These constructions and bounds are presented as direct, verifiable results rather than reductions to fitted parameters or self-referential equations. Algorithmic convergence guarantees follow from the multi-block structure without invoking self-citations as load-bearing premises or smuggling ansatzes. The central separation claim therefore rests on independent proofs and explicit formulations, not on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of convex functions and DC decompositions from prior literature
invented entities (1)
-
Multi-Block DC (BDC) function class
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pacific Journal of Mathematics , volume=
On functions representable as a difference of convex functions , author=. Pacific Journal of Mathematics , volume=. 1959 , publisher=
1959
-
[2]
Convergence analysis of DC algorithm for DC programming with subanalytic data , author=. Ann. Oper. Res. Technical Report, LMI, INSA-Rouen , year=
-
[3]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms , author=. arXiv preprint arXiv:1708.07747 , year=
work page internal anchor Pith review arXiv
-
[4]
and Sra, Suvrit , booktitle =
Mariet, Zelda E. and Sra, Suvrit , booktitle =. Kronecker Determinantal Point Processes , url =
-
[5]
Journal of Multivariate Analysis , volume=
From moments of sum to moments of product , author=. Journal of Multivariate Analysis , volume=. 2008 , publisher=
2008
-
[6]
Journal of algebra , volume=
The solution to the Waring problem for monomials and the sum of coprime monomials , author=. Journal of algebra , volume=. 2012 , publisher=
2012
-
[7]
Mathematische Zeitschrift , volume=
On the real rank of monomials , author=. Mathematische Zeitschrift , volume=. 2017 , publisher=
2017
-
[8]
Revisiting
Maskan, Hoomaan and Hou, Yikun and Sra, Suvrit and Yurtsever, Alp , journal=. Revisiting
-
[9]
Proceedings of the American Mathematical Society , volume=
Monomials as sums of powers: the real binary case , author=. Proceedings of the American Mathematical Society , volume=
-
[10]
Annali di Matematica Pura ed Applicata (1923-) , volume=
Real rank geometry of ternary forms , author=. Annali di Matematica Pura ed Applicata (1923-) , volume=. 2017 , publisher=
1923
-
[11]
Alternating DC algorithm for partial DC programming problems , url =
Pham Dinh, Tao and Huynh, Van Ngai and Le Thi, Hoai An and Ho, Vinh Thanh , date =. Alternating DC algorithm for partial DC programming problems , url =. Journal of Global Optimization , number =. 2022 , bdsk-url-1 =. doi:10.1007/s10898-021-01043-w , id =
-
[12]
SIAM Journal on Optimization , volume=
Stochastic difference-of-convex-functions algorithms for nonconvex programming , author=. SIAM Journal on Optimization , volume=. 2022 , publisher=
2022
-
[13]
Stochastic difference of convex algorithm and its application to training deep
Nitanda, Atsushi and Suzuki, Taiji , booktitle=. Stochastic difference of convex algorithm and its application to training deep. 2017 , organization=
2017
-
[14]
Why gradient clipping accelerates training: A theoretical justification for adaptivity
Why gradient clipping accelerates training: A theoretical justification for adaptivity , author=. arXiv preprint arXiv:1905.11881 , year=
-
[15]
Neural Information Processing Systems , year=
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift) , author=. Neural Information Processing Systems , year=
-
[16]
Convex-Concave Programming: An Effective Alternative for Optimizing Shallow Neural Networks , year=
Askarizadeh, Mohammad and Morsali, Alireza and Tofigh, Sadegh and Nguyen, Kim Khoa , journal=. Convex-Concave Programming: An Effective Alternative for Optimizing Shallow Neural Networks , year=
-
[17]
2018 , publisher=
Lectures on convex optimization , author=. 2018 , publisher=
2018
-
[18]
Advances in Neural Information Processing Systems , volume=
Transformers learn to implement preconditioned gradient descent for in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Robustness to unbounded smoothness of generalized
Crawshaw, Michael and Liu, Mingrui and Orabona, Francesco and Zhang, Wei and Zhuang, Zhenxun , journal=. Robustness to unbounded smoothness of generalized
-
[20]
arXiv preprint arXiv:2502.03401 , year=
Revisiting Stochastic Proximal Point Methods: Generalized Smoothness and Similarity , author=. arXiv preprint arXiv:2502.03401 , year=
-
[21]
Mathematical Programming , volume=
Proximal alternating linearized minimization for nonconvex and nonsmooth problems , author=. Mathematical Programming , volume=. 2014 , publisher=
2014
-
[22]
International Conference on Machine Learning , pages=
Conditional gradient methods via stochastic path-integrated differential estimator , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[23]
Stochastic
Reddi, Sashank J and Sra, Suvrit and P. Stochastic. 2016 54th annual Allerton conference on communication, control, and computing (Allerton) , pages=. 2016 , organization=
2016
-
[24]
1998 , publisher=
Variational analysis , author=. 1998 , publisher=
1998
-
[25]
Libor Vesel. A non-. Journal of Mathematical Analysis and Applications , keywords =. doi:https://doi.org/10.1016/j.jmaa.2018.03.021 , issn =
-
[26]
Open issues and recent advances in DC programming and DCA , url =
Le Thi, Hoai An and Pham Dinh, Tao , date =. Open issues and recent advances in DC programming and DCA , url =. Journal of Global Optimization , number =. 2024 , bdsk-url-1 =. doi:10.1007/s10898-023-01272-1 , id =
-
[27]
Journal of Machine Learning Research , volume=
Multiplicative multitask feature learning , author=. Journal of Machine Learning Research , volume=
-
[28]
Advances in Neural Information Processing Systems , volume=
Multi-stage multi-task feature learning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
A proximal
Jiang, Zhuoxuan and Zhao, Xinyuan and Ding, Chao , journal=. A proximal. 2021 , publisher=
2021
-
[30]
Stochastic Optimization for
Xu, Yi and Qi, Qi and Lin, Qihang and Jin, Rong and Yang, Tianbao , booktitle =. Stochastic Optimization for. 2019 , editor =
2019
-
[31]
Advances in Neural Information Processing Systems , volume=
Nuclear norm regularization for deep learning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Partial matrix completion , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
International Conference on Machine Learning , pages=
Over-parametrization via lifting for low-rank matrix sensing: Conversion of spurious solutions to strict saddle points , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[34]
and Wu, Teresa and Yang, Yingzhen , booktitle =
Wang, Yancheng and Goel, Rajeev and Nath, Utkarsh and Silva, Alvin C. and Wu, Teresa and Yang, Yingzhen , booktitle =. Learning Low-Rank Feature for Thorax Disease Classification , volume =
-
[35]
Proceedings of the 40th International Conference on Machine Learning , pages =
Generalized-Smooth Nonconvex Optimization is As Efficient As Smooth Nonconvex Optimization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[36]
Variance-reduced Clipping for Non-convex Optimization , year=
Reisizadeh, Amirhossein and Li, Haochuan and Das, Subhro and Jadbabaie, Ali , booktitle=. Variance-reduced Clipping for Non-convex Optimization , year=
-
[37]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Efficiency of coordinate descent methods for structured nonconvex optimization , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2020 , organization=
2020
-
[38]
Randomized block coordinate
Maskan, Hoomaan and Halvachi, Paniz and Sra, Suvrit and Yurtsever, Alp , journal=. Randomized block coordinate. 2025 , publisher=
2025
-
[39]
Proceedings of the 26th annual international conference on machine learning , pages=
Online dictionary learning for sparse coding , author=. Proceedings of the 26th annual international conference on machine learning , pages=
-
[40]
Martin and C
D. Martin and C. Fowlkes and D. Tal and J. Malik , title =. Proc. 8th Int'l Conf. Computer Vision , year =
-
[41]
Mathematics of Operations Research , year=
The cost of nonconvexity in deterministic nonsmooth optimization , author=. Mathematics of Operations Research , year=
-
[42]
International Conference on Machine Learning , pages=
Complexity of finding stationary points of nonconvex nonsmooth functions , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[43]
Mathematical Programming , volume=
Gradient descent with random initialization: Fast global convergence for nonconvex phase retrieval , author=. Mathematical Programming , volume=. 2019 , publisher=
2019
-
[44]
Conference on learning theory , pages=
On the low-rank approach for semidefinite programs arising in synchronization and community detection , author=. Conference on learning theory , pages=. 2016 , organization=
2016
-
[45]
Advances in Neural Information Processing Systems , volume=
Convex and non-convex optimization under generalized smoothness , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Improved analysis of clipping algorithms for non-convex optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
International Conference on Machine Learning , pages=
Fixed-point algorithms for learning determinantal point processes , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[48]
A gradient sampling method with complexity guarantees for
Davis, Damek and Drusvyatskiy, Dmitriy and Lee, Yin Tat and Padmanabhan, Swati and Ye, Guanghao , journal=. A gradient sampling method with complexity guarantees for
-
[49]
Neural computation , volume=
The concave-convex procedure , author=. Neural computation , volume=. 2003 , publisher=
2003
-
[50]
The Iterates of the
J. The Iterates of the. 2022 , url=
2022
-
[51]
2016 IEEE 55th conference on decision and control (CDC) , pages=
Disciplined convex-concave programming , author=. 2016 IEEE 55th conference on decision and control (CDC) , pages=. 2016 , organization=
2016
-
[52]
Yurtsever, Alp and Sra, Suvrit , journal=
- [53]
-
[54]
29th Annual Conference on Learning Theory , pages =
Gradient Descent Only Converges to Minimizers , author =. 29th Annual Conference on Learning Theory , pages =. 2016 , editor =
2016
-
[55]
Le Thi, Hoai An and Huynh, Van Ngai and Pham Dinh, Tao , title =. J. Optim. Theory Appl. , month =. 2018 , issue_date =. doi:10.1007/s10957-018-1345-y , abstract =
-
[56]
Algorithms for solving a class of nonconvex optimization problems
Tao, Pham Dinh and Souad, El Bernoussi , booktitle=. Algorithms for solving a class of nonconvex optimization problems. 1986 , publisher=
1986
-
[57]
Deep neural network training with
Pokutta, Sebastian and Spiegel, Christoph and Zimmer, Max , journal=. Deep neural network training with
-
[58]
Computational optimization and applications , volume=
Auction algorithms for network flow problems: A tutorial introduction , author=. Computational optimization and applications , volume=. 1992 , publisher=
1992
-
[59]
Proceedings of the 35th International Conference on Machine Learning , pages =
Convergence guarantees for a class of non-convex and non-smooth optimization problems , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[60]
A new efficient algorithm based on
An, Le Thi Hoai and Belghiti, M Tayeb and Tao, Pham Dinh , journal=. A new efficient algorithm based on. 2007 , publisher=
2007
-
[61]
2016 , publisher=
Pham Dinh, Tao and Le Thi, Hoai An and Pham, Viet Nga and Niu, Yi-Shuai , journal=. 2016 , publisher=
2016
-
[62]
Mathematical Programming , year=
An efficient cost scaling algorithm for the assignment problem , author=. Mathematical Programming , year=
-
[63]
, booktitle=
Ramshaw, Lyle and Tarjan, Robert E. , booktitle=. A Weight-Scaling Algorithm for Min-Cost Imperfect Matchings in Bipartite Graphs , year=
-
[64]
Symposium on the Theory of Computing , year=
Integer priority queues with decrease key in constant time and the single source shortest paths problem , author=. Symposium on the Theory of Computing , year=
-
[65]
Alfaro, Carlos A. and Perez, Sergio L. and Valencia, Carlos E. and Vargas, Marcos C. , date =. The assignment problem revisited , url =. Optimization Letters , number =. 2022 , bdsk-url-1 =. doi:10.1007/s11590-021-01791-4 , id =
-
[66]
International Conference on Artificial Intelligence and Statistics , year=
Kernel Methods for Missing Variables , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[67]
International Conference on Machine Learning , year=
Three Operator Splitting with a Nonconvex Loss Function , author=. International Conference on Machine Learning , year=
-
[68]
SIAM Journal on Optimization , volume=
Conditional gradient sliding for convex optimization , author=. SIAM Journal on Optimization , volume=. 2016 , publisher=
2016
-
[69]
Mathematical Programming , year=
Performance of first-order methods for smooth convex minimization: a novel approach , author=. Mathematical Programming , year=
-
[70]
On the rate of convergence of the difference-of-convex algorithm (
Abbaszadehpeivasti, Hadi and de Klerk, Etienne and Zamani, Moslem , journal=. On the rate of convergence of the difference-of-convex algorithm (. 2023 , publisher=
2023
-
[71]
Alternating
Pham Dinh, Tao and Huynh, Van Ngai and Le Thi, Hoai An and Ho, Vinh Thanh , journal=. Alternating. 2022 , publisher=
2022
-
[72]
Parallel
Niu, Yi-Shuai and You, Yu and Liu, Wen-Zhuo , booktitle=. Parallel. 2019 , organization=
2019
-
[73]
Optimization Letters , pages=
A difference-of-convex programming approach with parallel branch-and-bound for sentence compression via a hybrid extractive model , author=. Optimization Letters , pages=. 2021 , publisher=
2021
-
[74]
Tao, Pham Dinh and An, Le Thi Hoai , journal=. A. 1998 , publisher=
1998
-
[75]
PLOS one , volume=
Fast approximate quadratic programming for graph matching , author=. PLOS one , volume=. 2015 , publisher=
2015
-
[76]
SIAM Journal on Scientific Computing , volume=
Minimization of 1-2 for compressed sensing , author=. SIAM Journal on Scientific Computing , volume=. 2015 , publisher=
2015
-
[77]
Kuhn, Harold W , journal=. The. 1955 , publisher=
1955
-
[78]
Journal of the society for industrial and applied mathematics , volume=
Algorithms for the assignment and transportation problems , author=. Journal of the society for industrial and applied mathematics , volume=. 1957 , publisher=
1957
-
[79]
Computing , volume=
A shortest augmenting path algorithm for dense and sparse linear assignment problems , author=. Computing , volume=. 1987 , publisher=
1987
-
[80]
Regularized optimal transport and the
Dessein, Arnaud and Papadakis, Nicolas and Rouas, Jean-Luc , journal=. Regularized optimal transport and the
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.