Recognition: unknown
Target Parameterization in Diffusion Models for Nonlinear Spatiotemporal System Identification
Pith reviewed 2026-05-10 05:30 UTC · model grok-4.3
The pith
Clean-state prediction in diffusion models improves long-term rollout stability for turbulent nonlinear systems over noise or velocity targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
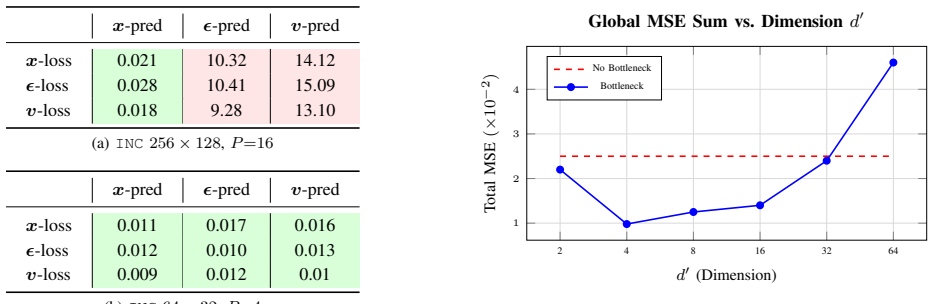
In diffusion-based identification of nonlinear spatiotemporal systems, clean-state prediction as the modeling target yields consistently better rollout stability and lower long-horizon error than velocity- or noise-based objectives, and the benefit grows with increasing per-token dimensionality.
What carries the argument
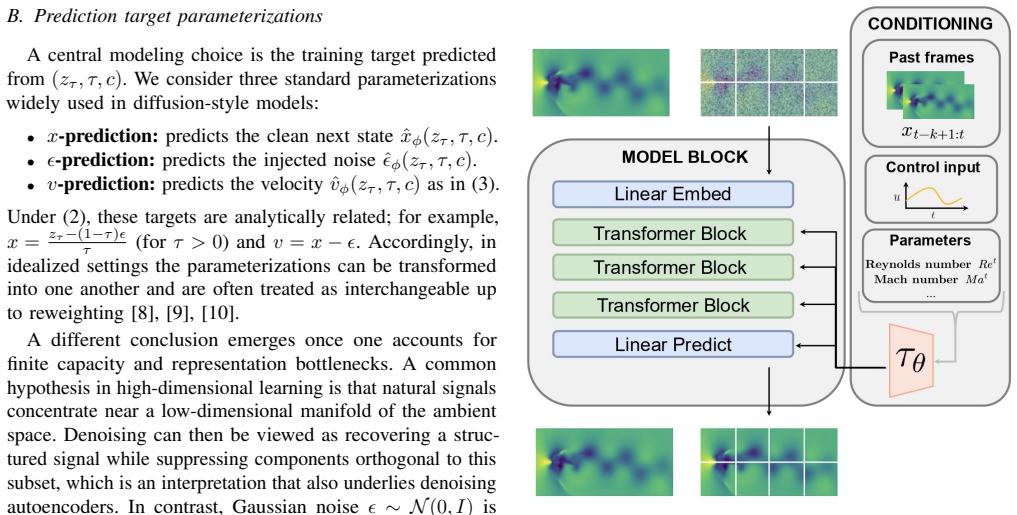
Target parameterization (clean-state versus noise or velocity prediction) inside the diffusion training objective, which directly shapes how the model learns to reverse the forward noise process and thereby controls error accumulation across iterative rollouts on high-dimensional spatial fields.
Load-bearing premise
That turbulent-flow simulation with a simple patch-based transformer isolates the effect of target choice without confounding influences from architecture details or data specifics.
What would settle it
Demonstrating on any other nonlinear spatiotemporal system that clean-state prediction produces equal or higher long-horizon error than noise or velocity prediction would falsify the reported advantage.
Figures


read the original abstract
Machine learning is becoming increasingly important for nonlinear system identification, including dynamical systems with spatially distributed outputs. However, classical identification and forecasting approaches become markedly less reliable in turbulent-flow regimes, where the dynamics are high-dimensional, strongly nonlinear, and highly sensitive to compounding rollout errors. Diffusion-based models have recently shown improved robustness in this setting and offer probabilistic inference capabilities, but many current implementations inherit target parameterizations from image generation, most commonly noise or velocity prediction. In this work, we revisit this design choice in the context of nonlinear spatiotemporal system identification. We consider a simple, self-contained patch-based transformer that operates directly on physical fields and use turbulent flow simulation as a representative testbed. Our results show that clean-state prediction consistently improves rollout stability and reduces long-horizon error relative to velocity- and noise-based objectives, with the advantage becoming more pronounced as the per-token dimensionality increases. These findings identify target parameterization as a key modeling choice in diffusion-based identification of nonlinear systems with spatial outputs in turbulent regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines target parameterization choices in diffusion models applied to nonlinear spatiotemporal system identification, focusing on turbulent flow regimes where classical methods struggle with high dimensionality and error accumulation. Using a patch-based transformer operating directly on physical fields as a testbed, the authors compare clean-state, velocity, and noise prediction objectives and report that clean-state prediction yields consistently better rollout stability and lower long-horizon errors, with the gap widening at higher per-token dimensionality.
Significance. If the empirical isolation holds, the result identifies target parameterization as a practically important modeling decision for diffusion-based identification of nonlinear systems with spatial structure. It supplies a concrete, reproducible comparison on a challenging testbed and could inform more robust probabilistic forecasting architectures in control and dynamical systems applications.
major comments (1)
- [Experimental Results / Setup] The central claim requires that only the prediction target varies while loss scaling, gradient magnitudes, normalization, conditioning, and optimization trajectories remain equivalent across the three objectives. The manuscript employs a single patch-based transformer on one turbulent-flow dataset; without explicit ablations or controls demonstrating invariance to architecture-data interactions (e.g., patch embedding sensitivity to dimensionality), the observed advantage cannot be confidently attributed to parameterization alone.
minor comments (2)
- [Abstract] The abstract states that clean-state prediction improves rollout stability but supplies no quantitative metrics, error bars, or statistical tests; these details should appear in the main text and figures for verifiability.
- [Methods] Notation for the three target parameterizations (clean state, velocity, noise) should be introduced with explicit equations early in the methods section to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comment emphasizing the need for rigorous isolation of the target parameterization effect. We address the concern in detail below and will incorporate clarifications and discussion in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Results / Setup] The central claim requires that only the prediction target varies while loss scaling, gradient magnitudes, normalization, conditioning, and optimization trajectories remain equivalent across the three objectives. The manuscript employs a single patch-based transformer on one turbulent-flow dataset; without explicit ablations or controls demonstrating invariance to architecture-data interactions (e.g., patch embedding sensitivity to dimensionality), the observed advantage cannot be confidently attributed to parameterization alone.
Authors: We agree that the central claim requires careful controls to ensure differences arise from the prediction target. In our setup the patch-based transformer architecture, patch embedding, positional encodings, number of layers, attention heads, conditioning (timestep embedding), optimizer, learning-rate schedule, and batch size were held fixed; the sole change was the network regression target (clean state, velocity, or noise). Targets were normalized to comparable variance and we monitored gradient norms to confirm similar optimization behavior. We acknowledge, however, that the single-architecture, single-dataset design limits claims of invariance to architecture-data interactions. We will revise the manuscript to add an explicit subsection detailing these controls and a limitations paragraph discussing potential sensitivity of patch embeddings to per-token dimensionality. revision: partial
Circularity Check
No circularity in empirical comparison of diffusion target parameterizations
full rationale
The paper presents an empirical study comparing clean-state, velocity, and noise prediction objectives within a fixed patch-based transformer architecture on turbulent flow simulation data. All central claims rest on observed rollout stability and long-horizon error metrics obtained from independent simulation runs; no mathematical derivation, first-principles result, or uniqueness theorem is asserted that reduces by construction to its own inputs or to a fitted parameter renamed as a prediction. No self-citations are invoked as load-bearing justification for the target-parameterization choice, and the methodology does not involve ansatz smuggling, renaming of known empirical patterns, or self-definitional loops. The reported advantage of clean-state prediction is therefore an experimental outcome rather than a tautological restatement of the modeling assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Networks for System Identification: A Survey,
G. Pillonetto, A. Aravkin, D. Gedon, L. Ljung, A. H. Ribeiro, and T. B. Sch ¨on, “Deep Networks for System Identification: A Survey,” Automatica, vol. 171, p. 111907, 2025
2025
-
[2]
From System Models to Class Models: An In-Context Learning Paradigm,
M. Forgione, F. Pura, and D. Piga, “From System Models to Class Models: An In-Context Learning Paradigm,”IEEE Control Systems Letters, vol. 7, pp. 3513–3518, 2023
2023
-
[3]
Enhanced Trans- former Architecture for In-Context Learning of Dynamical Systems,
M. Rufolo, D. Piga, G. Maroni, and M. Forgione, “Enhanced Trans- former Architecture for In-Context Learning of Dynamical Systems,” inEuropean Control Conference (ECC), pp. 819–824, 2025
2025
-
[4]
Can Transformers Learn Optimal Filtering for Unknown Systems?
Z. Du, H. Balim, S. Oymak, and N. Ozay, “Can Transformers Learn Optimal Filtering for Unknown Systems?”IEEE Control Systems Letters, vol. 7, pp. 3525–3530, 2023
2023
-
[5]
S. Sun, L. Feng, and P. Benner, “Interpretable Spatial-Temporal Fusion Transformers: Multi-Output Prediction for Parametric Dynamical Systems with Time-Varying Inputs,”arXiv preprint arXiv:2505.00473, 2025
-
[6]
G. I. Beintema,Modeling and Identification of Nonlinear Dynamical Systems Using Deep Neural Network Architectures, Ph.D. dissertation, Eindhoven University of Technology, 2024
2024
-
[7]
Benchmarking autoregressive conditional diffusion models for turbulent flow simulation,
G. Kohl, L.-W. Chen, and N. Thuerey, “Benchmarking autoregressive conditional diffusion models for turbulent flow simulation,”Neural Networks, vol. 199, art. 108641, July 2026
2026
-
[8]
Denoising Diffusion Probabilistic Models,
J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” inAdvances in Neural Information Processing Systems, 2020
2020
-
[9]
Improved Denoising Diffusion Probabilistic Models,
A. Nichol and P. Dhariwal, “Improved Denoising Diffusion Probabilistic Models,” inProceedings of the 38th International Conference on Machine Learning, 2021
2021
-
[10]
Elucidating the Design Space of Diffusion-Based Generative Models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the Design Space of Diffusion-Based Generative Models,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[11]
Scalable Diffusion Models with Transformers
W. Peebles and S. Xie, “Scalable Diffusion Models with Transformers,” arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review arXiv 2022
-
[12]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He, “Back to Basics: Let Denoising Generative Models Denoise,”arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.