Recognition: unknown
Diverse Dictionary Learning
Pith reviewed 2026-05-10 06:36 UTC · model grok-4.3
The pith
Intersections, complements, and symmetric differences of latent variables linked to observations remain identifiable from data alone, even without strong assumptions on the model or data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the setting where data X is generated by an unknown function g from unknown latents Z, the intersections, complements, and symmetric differences of the latent variables associated with arbitrary observations, together with the latent-to-observed dependency structure, are identifiable up to appropriate indeterminacies without requiring strong assumptions like linearity. These set-theoretic objects can be composed via set algebra to yield structured views such as genus-differentia definitions of the hidden factors. Sufficient structural diversity in the setup further guarantees full identifiability of the latent variables. All these identifiability results stem from a simple inductive bias.
What carries the argument
Diverse dictionary learning, which formalizes the recovery of set operations (intersections, complements, symmetric differences) on latent variables linked to observations along with the latent-to-observed dependency structure.
If this is right
- Structured views of the hidden world such as genus-differentia definitions can be constructed by composing the identifiable set operations.
- Full identifiability of all latent variables follows automatically once sufficient structural diversity is present.
- The inductive bias can be added to most existing latent variable models to obtain the partial and full recoveries.
- The dependency structure between latents and observations becomes recoverable as part of the same process.
Where Pith is reading between the lines
- The framework could guide the design of new unsupervised models that prioritize set-based recoveries over attempting full disentanglement from the start.
- It offers a way to evaluate partial identifiability in practice on real data by checking consistency of recovered intersections and complements against domain knowledge.
- Extensions to dynamic or graph-structured data might allow tracking how set relations among hidden factors evolve over time.
Load-bearing premise
The setup must contain sufficient structural diversity in the latent-to-observation links for the set operations to compose into full identifiability of every latent variable.
What would settle it
A synthetic dataset with deliberately low structural diversity where the set operations on latents fail to be recovered accurately from observations despite using the proposed inductive bias.
Figures






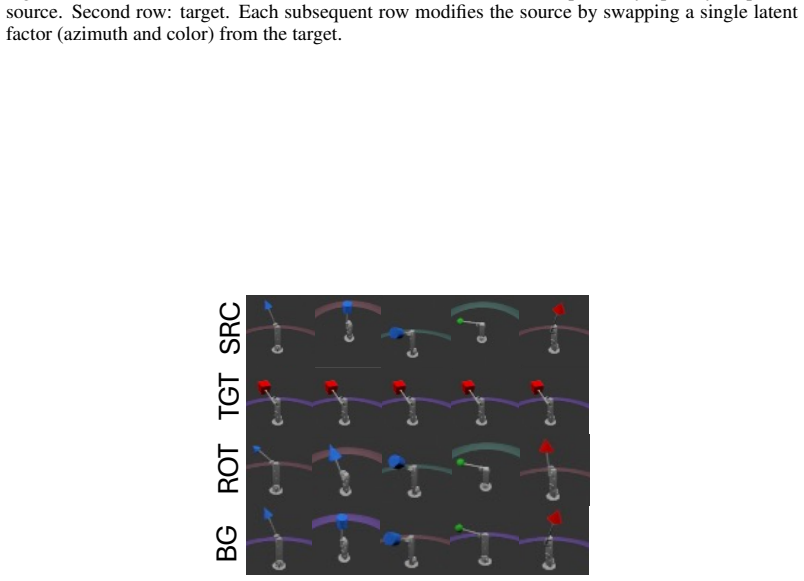
read the original abstract
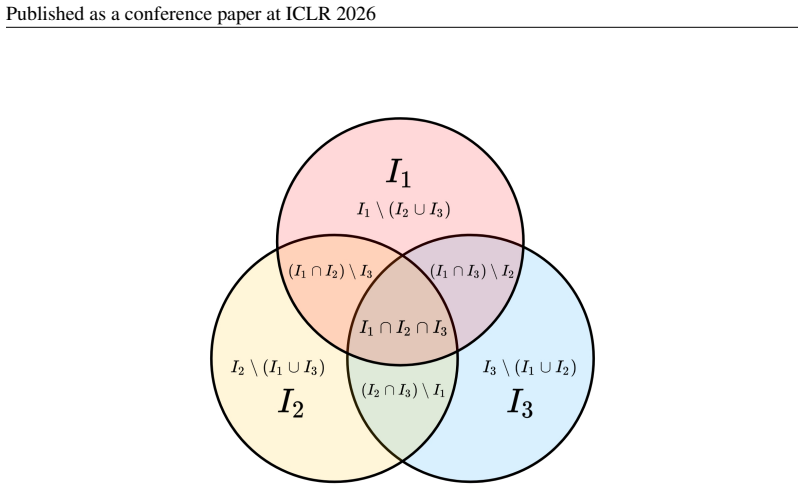
Given only observational data $X = g(Z)$, where both the latent variables $Z$ and the generating process $g$ are unknown, recovering $Z$ is ill-posed without additional assumptions. Existing methods often assume linearity or rely on auxiliary supervision and functional constraints. However, such assumptions are rarely verifiable in practice, and most theoretical guarantees break down under even mild violations, leaving uncertainty about how to reliably understand the hidden world. To make identifiability actionable in the real-world scenarios, we take a complementary view: in the general settings where full identifiability is unattainable, what can still be recovered with guarantees, and what biases could be universally adopted? We introduce the problem of diverse dictionary learning to formalize this view. Specifically, we show that intersections, complements, and symmetric differences of latent variables linked to arbitrary observations, along with the latent-to-observed dependency structure, are still identifiable up to appropriate indeterminacies even without strong assumptions. These set-theoretic results can be composed using set algebra to construct structured and essential views of the hidden world, such as genus-differentia definitions. When sufficient structural diversity is present, they further imply full identifiability of all latent variables. Notably, all identifiability benefits follow from a simple inductive bias during estimation that can be readily integrated into most models. We validate the theory and demonstrate the benefits of the bias on both synthetic and real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the diverse dictionary learning framework for recovering aspects of unknown latent variables Z from observations X = g(Z). It claims that intersections, complements, and symmetric differences of latent variables linked to observations, along with the latent-to-observed dependency structure, remain identifiable up to appropriate indeterminacies without strong assumptions on g or Z. These set-algebraic results can be composed to form structured views (e.g., genus-differentia definitions), and under a sufficient structural diversity condition they imply full identifiability of all latents. All benefits derive from a simple, model-agnostic inductive bias that can be added to existing estimators. The claims are supported by theoretical arguments and empirical validation on synthetic and real-world data.
Significance. If the identifiability theorems hold, the work provides a practical route to guaranteed partial recovery of latent structure in settings where full identifiability is impossible, using only a lightweight bias rather than unverifiable functional or linearity assumptions. The set-algebra composition approach is a genuine strength and could influence representation learning by enabling interpretable, composable views of the hidden world. The model-agnostic character of the bias is also a positive feature for broad applicability.
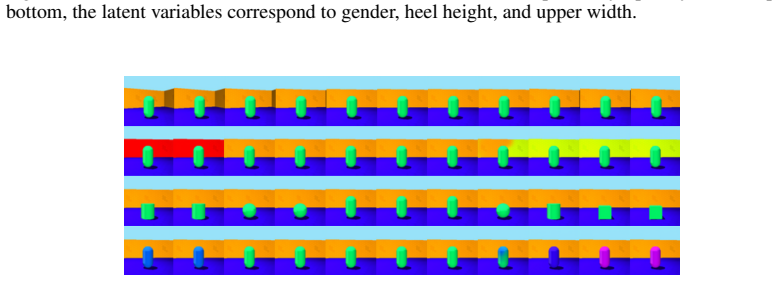
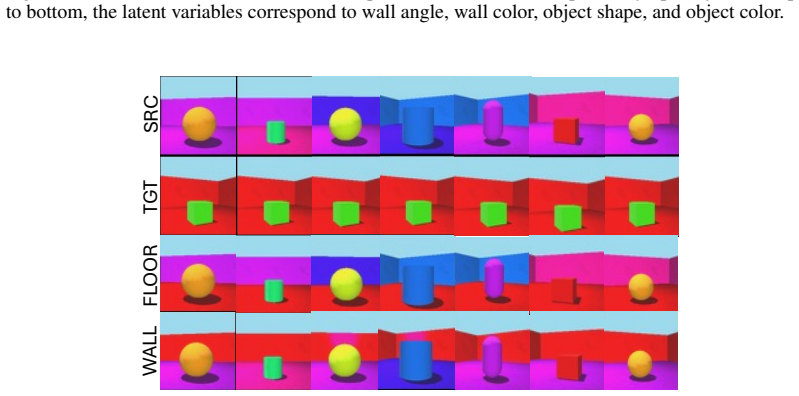
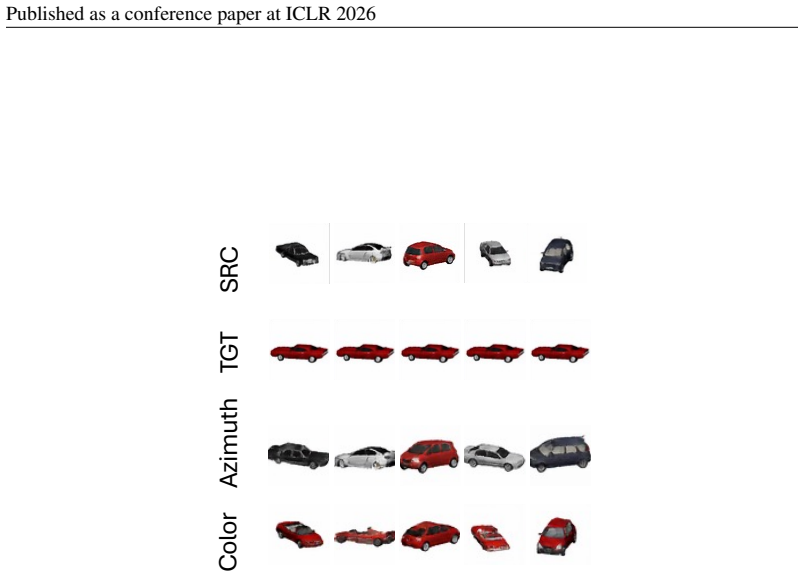
major comments (2)
- [Theory section (likely §3–4)] Theory section (likely §3–4): the central claim that intersections/complements/symmetric differences and the dependency structure are identifiable up to indeterminacies without strong assumptions is load-bearing; the manuscript must supply the key derivation steps or proof outline showing that the set-algebra operations do not introduce hidden functional assumptions or reduce to fitted parameters.
- [Diversity condition (abstract and corresponding theorem)] Diversity condition (abstract and corresponding theorem): the statement that 'sufficient structural diversity' yields full identifiability is load-bearing for the strongest claim; the paper needs an explicit, checkable criterion or bound for this condition so that readers can assess when the full-identifiability regime applies versus the partial-recovery regime.
minor comments (2)
- [Notation] Notation for the generating process g and the set operations on latents should be introduced with a single consistent diagram or table early in the paper to aid readability.
- [Experiments] The empirical section would benefit from an ablation that isolates the contribution of the diversity bias versus the base model on the reported metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential impact of the diverse dictionary learning framework. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theory section (likely §3–4)] Theory section (likely §3–4): the central claim that intersections/complements/symmetric differences and the dependency structure are identifiable up to indeterminacies without strong assumptions is load-bearing; the manuscript must supply the key derivation steps or proof outline showing that the set-algebra operations do not introduce hidden functional assumptions or reduce to fitted parameters.
Authors: We agree that the central identifiability claims require a clearer exposition of the derivation steps. The current manuscript presents the set-algebraic results in §3–4 with supporting arguments, but we will revise the theory section to include an explicit proof outline. This outline will step through the recovery of intersections, complements, symmetric differences, and the dependency structure directly from the observational distribution of X, demonstrating that these operations rely solely on the set-theoretic structure induced by the diverse dictionary learning bias and introduce no additional functional assumptions on g or Z. The outline will also clarify that the recovered quantities are not fitted parameters but are determined up to the stated indeterminacies by the support patterns in the data. revision: yes
-
Referee: [Diversity condition (abstract and corresponding theorem)] Diversity condition (abstract and corresponding theorem): the statement that 'sufficient structural diversity' yields full identifiability is load-bearing for the strongest claim; the paper needs an explicit, checkable criterion or bound for this condition so that readers can assess when the full-identifiability regime applies versus the partial-recovery regime.
Authors: We acknowledge that the sufficient structural diversity condition, while stated in the abstract and formalized in the corresponding theorem, would benefit from a more explicit and checkable characterization. In the revision we will augment the theorem statement with a quantitative criterion expressed in terms of the minimal number and overlap pattern of observed supports required to guarantee that the set-algebraic operations span the full latent space. This criterion will allow readers to determine, for a given dataset, whether the full-identifiability regime or only the partial-recovery regime applies, without altering the qualitative nature of the original condition. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core claims rest on set-algebraic identifiability results for intersections, complements, symmetric differences, and latent-to-observed dependencies (up to indeterminacies) that hold without strong assumptions, with full identifiability only under an explicitly stated sufficient structural diversity condition. These follow from the introduced diverse dictionary learning formulation and a simple inductive bias during estimation. No equations or steps in the provided text reduce the claimed results to fitted parameters, self-citations, or definitional tautologies; the derivation is presented as following directly from the diversity bias and set operations. Validation on synthetic and real data is separate from the theoretical chain. The results are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Set algebra operations (intersection, complement, symmetric difference) can be composed to construct structured views of latent variables.
- domain assumption A simple inductive bias toward diversity during estimation is sufficient to achieve the identifiability guarantees.
invented entities (1)
-
Diverse dictionary learning framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Simon Buchholz, Michel Besserve, and Bernhard Sch ¨olkopf. Function classes for identifiable non- linear independent component analysis.arXiv preprint arXiv:2208.06406,
-
[2]
Batchtopk sparse autoencoders
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning. Guangyi Chen, Yifan Shen, Zhenhao Chen, Xiangchen Song, Yuewen Sun, Weiran Yao, Xiao Liu, and Kun Zhang. Caring: Learning temporal causal representation under non-invertible generation process. InInter...
2024
-
[3]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
doi: 10.1353/hph.1984.0001. 10 Published as a conference paper at ICLR 2026 Hermanni H¨alv¨a, Sylvain Le Corff, Luc Leh´ericy, Jonathan So, Yongjie Zhu, Elisabeth Gassiat, and Aapo Hyv ¨arinen. Disentangling identifiable features from noisy data with structured nonlinear ICA.Advances in Neural Information Processing Systems, 34,
-
[5]
Jikai Jin and Vasilis Syrgkanis. Learning causal representations from general environments: Identi- fiability and intrinsic ambiguity.arXiv preprint arXiv:2311.12267,
-
[6]
Identification of nonlinear latent hierarchical models.Advances in Neural Information Processing Systems, 36: 2010–2032,
Lingjing Kong, Biwei Huang, Feng Xie, Eric Xing, Yuejie Chi, and Kun Zhang. Identification of nonlinear latent hierarchical models.Advances in Neural Information Processing Systems, 36: 2010–2032,
2010
-
[7]
Biscuit: Causal representation learning from binary interactions
11 Published as a conference paper at ICLR 2026 Phillip Lippe, Sara Magliacane, Sindy L ¨owe, Yuki M Asano, Taco Cohen, and Efstratios Gavves. Biscuit: Causal representation learning from binary interactions. InUncertainty in Artificial Intelligence, pp. 1263–1273. PMLR,
2026
-
[8]
Gemma E Moran and Bryon Aragam. Towards interpretable deep generative models via causal representation learning.arXiv preprint arXiv:2504.11609,
-
[9]
Nanda, N., Lee, A., and Wattenberg, M
Gemma E Moran, Dhanya Sridhar, Yixin Wang, and David M Blei. Identifiable variational autoen- coders via sparse decoding.arXiv preprint arXiv:2110.10804,
-
[10]
Xuanchi Ren, Tao Yang, Yuwang Wang, and Wenjun Zeng. Learning disentangled representa- tion by exploiting pretrained generative models: A contrastive learning view.arXiv preprint arXiv:2102.10543,
-
[11]
Open Problems in Mechanistic Interpretability
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability.arXiv preprint arXiv:2501.16496,
work page internal anchor Pith review arXiv
-
[12]
Peter Sorrenson, Carsten Rother, and Ullrich K¨othe. Disentanglement by nonlinear ICA with general incompressible-flow networks (GIN).arXiv preprint arXiv:2001.04872,
-
[13]
Julius von K ¨ugelgen, Yash Sharma, Luigi Gresele, Wieland Brendel, Bernhard Sch ¨olkopf, Michel Besserve, and Francesco Locatello. Self-supervised learning with data augmentations provably isolates content from style.arXiv preprint arXiv:2106.04619,
-
[14]
Nonparametric identifiability of causal represen- tations from unknown interventions.Advances in Neural Information Processing Systems, 36: 48603–48638,
12 Published as a conference paper at ICLR 2026 Julius von K¨ugelgen, Michel Besserve, Liang Wendong, Luigi Gresele, Armin Keki´c, Elias Barein- boim, David Blei, and Bernhard Sch ¨olkopf. Nonparametric identifiability of causal represen- tations from unknown interventions.Advances in Neural Information Processing Systems, 36: 48603–48638,
2026
-
[15]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmark- ing machine learning algorithms.arXiv preprint arXiv:1708.07747,
work page internal anchor Pith review arXiv
-
[16]
arXiv preprint arXiv:2110.05428 , year=
Dingling Yao, Caroline Muller, and Francesco Locatello. Marrying causal representation learning with dynamical systems for science.Advances in Neural Information Processing Systems, 37: 71705–71736, 2024a. Dingling Yao, Danru Xu, S´ebastien Lachapelle, Sara Magliacane, Perouz Taslakian, Georg Martius, Julius von K ¨ugelgen, and Francesco Locatello. Multi-...
-
[17]
15 A.2 Proof of Theorem 1
13 Published as a conference paper at ICLR 2026 Diverse Dictionary Learning Supplementary Material Table of Contents A Proofs 15 A.1 Proof of Proposition 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.2 Proof of Theorem 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.3 Proof of Theorem 2 . . . . . . . . . . . ....
2026
-
[18]
1 holds and: i
Suppose Assum. 1 holds and: i. The probability density ofZis positive inR dz; ii. (Sparsity regularization 6)∥D ˆZˆg∥0 ≤ ∥D Zg∥0. Then ifθ∼ obs ˆθ, we have generalized identifiability (Defn. 6), i.e.,θ∼ set ˆθ. Proof.Sinceθ∼ obs ˆθ, by the change-of-variable formula there must be ˆZ= ˆg−1 ◦g(Z) =ϕ(Z),(4) whereϕ= ˆg −1 ◦gis an invertible function and thusϕ...
2026
-
[19]
This matching corresponds to a permutationπ∈S n such that (D ˆZϕ−1)j,π(j) ̸= 0,∀j∈ {1,2,
SinceD ˆZϕ−1 is invertible, its rows are linearly independent, so for every subsetS⊆R, the corre- sponding rows have a nonzero determinant, implying that |{k∈C| ∃j∈S, D ˆZϕ−1 j,k ̸= 0}| ≥ |S|.(14) By Hall’s marriage theorem, there exists a perfect matching betweenRandC. This matching corresponds to a permutationπ∈S n such that (D ˆZϕ−1)j,π(j) ̸= 0,∀j∈ {1,...
2026
-
[20]
Suppose assumptions in Thm. 1 hold. Ifθ∼ obs ˆθ, the support of the Jacobian matrixD ˆzˆgis identical to that ofDzg, up to a permutation of column indices. Proof.Sinceθ∼ obs ˆθ, by consideringϕ= ˆg −1 ◦gand the change-of-variable formula, we have ˆZ=ϕ(Z),(46) whereϕis an invertible function and thusϕ −1 exists. Therefore, according to the chain rule, we h...
2026
-
[21]
This matching corresponds to a permutationπ∈S n such that (D ˆZϕ−1)j,π(j) ̸= 0,∀j∈ {1,2,
SinceD ˆZϕ−1 is invertible, its rows are linearly independent, so for every subsetS⊆R, the corre- sponding rows have a nonzero determinant, implying that |{k∈C| ∃j∈S, D ˆZϕ−1 j,k ̸= 0}| ≥ |S|.(56) By Hall’s marriage theorem, there exists a perfect matching betweenRandC. This matching corresponds to a permutationπ∈S n such that (D ˆZϕ−1)j,π(j) ̸= 0,∀j∈ {1,...
2026
-
[22]
Supposer∈( S Xj ∈A\{Xk} Ij)\I k
We begin with the first condition: there exists a set of observed variablesAand an elementX k ∈Asuch that [ Xj ∈A Ij = [dz],andI k \ [ Xj ∈A\{Xk} Ij ={i}.(66) Our want to show that, for any otherr̸=i, we have ∂Zi ∂ ˆZπ(r) = 0.(67) We consider two cases: •r∈( S Xj ∈A\{Xk} Ij)\I k; •r∈( S Xj ∈A\{Xk} Ij)∩I k. Supposer∈( S Xj ∈A\{Xk} Ij)\I k. Let us denoteJ A...
2026
-
[23]
Suppose for each row inM ϕ, there are more than one non-zero element
That part of proof directly follows from (Lachapelle et al., 2022; Zheng et al., 2022). Suppose for each row inM ϕ, there are more than one non-zero element. Then ∃j1 ̸=j 2, Mϕj1,· ∩M ϕj2,· ̸=∅.(106) Then considerj 3 ∈[d z]such that π(j3)∈M ϕj1,· ∩M ϕj2,·.(107) Sincej 1 ̸=j 3, it is eitherj 3 ̸=j 1 orj 3 ̸=j
2022
-
[24]
Since we have \ Xj ∈Aj1 Ij =j 1,(108) there must existsX i3 ∈A j1 such thatj 3 ̸=I i3. Becausej 1 ∈I i3, we have (i3, j1)∈supp(D Zg),(109) which further implies Mϕj1,· ∈span{e ′ k :k ′ ∈supp((D ˆZˆg)i3,·)}.(110) 23 Published as a conference paper at ICLR 2026 Given Eq. (107), it implies π(j3)∈supp(D ˆZˆg)i3,·.(111) This, again, implies j3 ∈supp(D Zg)i3,·,...
2026
-
[25]
All indices outsideAbelong toI 2 orI 3 (or both), soAis disentangled
Nowi∈I K \I V and every j∈I 3 is inI V \I K, again case (iii). All indices outsideAbelong toI 2 orI 3 (or both), soAis disentangled. (ii)I 2 \(I 1 ∪I 3)Symmetric to (i) with the roles of(1,2)and(2,1)swapped: use(X K, XV ) = (X2, X1)and(X 2, X3). (iii)I 3 \(I 1 ∪I 2)Symmetric to (i): use(X K, XV ) = (X3, X1)and(X 3, X2). (iv)(I 1 ∩I 2)\I 3 This is the work...
2026
-
[26]
These results, together with the comprehensive experiments in (Farnik et al., 2025), further sup- port the advantages of dependency sparsity, demonstrating that it not only yields more interpretable representations but also preserves active and meaningful latent features more effectively. B.4 FURTHER DISCUSSION ON SUFFICIENT NONLIENARITY The sufficient no...
2025
-
[27]
shows that dependency sparsity regularization remains practical even at scale up to common LLMs when combined with two standard strategies. 27 Published as a conference paper at ICLR 2026 •Apply latent sparsity first.Large models often have high dimensional latent spaces, but for any given input, many latent coordinates are inactive or irrelevant. A commo...
2026
-
[28]
The main difficulty is separating noise from latent variables, since in the general form they can be entangled in complex ways
and recent nonparametric work (Hyv ¨arinen et al., 2024). The main difficulty is separating noise from latent variables, since in the general form they can be entangled in complex ways. Recent work (Zheng et al., 2025), based on the Hu-Schennach theorem (Hu & Schennach, 2008), shows that general noise can be separated under additional assumptions on the g...
2024
-
[29]
Of course, the list is non-exclusive, and will only grow faster given the development of large-scale models
and genomics (Morioka & Hyvarinen, 2024). Of course, the list is non-exclusive, and will only grow faster given the development of large-scale models. The reason is simple: even with infinite data and computation, without identifiability, mod- els may achieve perfect predictions but cannot be guaranteed to recover the underlying truth. Thus, the closer we...
2024
-
[30]
Neither provides identifiability guarantees in the non- parametric setting
and the Hessian Penalty (Peebles et al., 2020). Neither provides identifiability guarantees in the non- parametric setting. Empirically, both underperform our method, with a widening gap asdincreases. This indicates that penalizing the dependency map in a structural way improves recovery of the true latent factors. Noise robustness.Remark 1 states that ou...
2020
-
[31]
Individual latent coordinates correspond cleanly to gender, heel height, and upper width, with minimal interference across factors
with Flow. Individual latent coordinates correspond cleanly to gender, heel height, and upper width, with minimal interference across factors. The Shapes3D traversals in Figure 8 (EncDiff) show similarly sharp control, disentangling wall angle, wall color, object shape, and object color. These traversals illustrate that dependency sparsity yields latent a...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.