Recognition: unknown
BioVLM: Routing Prompts, Not Parameters, for Cross-Modality Generalization in Biomedical VLMs
Pith reviewed 2026-05-10 05:26 UTC · model grok-4.3
The pith
BioVLM improves cross-modality generalization in biomedical vision-language models by dynamically routing each input to the most suitable prompts from a learned bank rather than fine-tuning the model parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BioVLM learns a diverse prompt bank and, at inference, selects the most discriminative prompts for each input by applying a low-entropy criterion to the model's predictive distribution; this selection couples few-shot evidence with LLM-derived semantic priors, which are further strengthened by distilling high-confidence attributes and enforcing augmentation consistency, allowing the model to generalize to unseen categories and domains while training remains lightweight and inference stays efficient.
What carries the argument
Dynamic low-entropy prompt selection from a learned prompt bank, which routes each input to modality-appropriate prompts without altering backbone parameters.
If this is right
- Achieves new state-of-the-art performance on 11 MedMNIST+ 2D datasets across three distinct generalization settings.
- Enables transfer to unseen categories and domains at test time by selecting modality-appropriate prompts.
- Keeps training lightweight and inference efficient by avoiding extensive backbone fine-tuning.
- Strengthens coupling between few-shot data and LLM priors through attribute distillation and augmentation consistency.
Where Pith is reading between the lines
- The same prompt-routing pattern could be tested on non-biomedical vision-language models that face domain shifts in natural images or video.
- If the selection step proves robust, it might reduce the computational cost of adapting large multimodal models in clinical settings where labeled data are scarce.
- A direct extension would be to apply the method to 3D volumetric medical scans or multi-modal inputs that combine imaging with clinical text.
Load-bearing premise
Low-entropy selection on the predictive distribution reliably identifies the most discriminative prompts and couples few-shot evidence with LLM priors without introducing selection bias or modality mismatch.
What would settle it
A result in which, on any of the eleven MedMNIST+ datasets under one of the three generalization settings, low-entropy prompt selection produces lower accuracy than a parameter-fine-tuning baseline or than random prompt choice.
Figures



read the original abstract
Pretrained biomedical vision-language models (VLMs) such as BioMedCLIP perform well on average but often degrade on challenging modalities where inter-class margins are small and acquisition-specific variations are pronounced, especially under few-shot supervision and when modality priors differ from pretraining corpora substantially. We propose BioVLM, a prompt-learning framework that improves cross-domain generalization without extensive backbone fine-tuning. BioVLM learns a diverse prompt bank and introduces dynamic prompt selection: for each input, it selects the most discriminative prompts via a low-entropy criterion on the predictive distribution, effectively coupling sparse few-shot evidence with rich LLM semantic priors. To strengthen this coupling, we distill high-confidence LLM-derived attributes and enforce robust knowledge transfer through strong/weak augmentation consistency. At test time, BioVLM adapts by choosing modality-appropriate prompts, enabling transfer to unseen categories and domains, while keeping training lightweight and inference efficient. On 11 MedMNIST+ 2D datasets, BioVLM achieves new state of the art across three distinct generalization settings. Codes are available at https://github.com/mainaksingha01/BioVLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BioVLM, a prompt-learning framework for biomedical VLMs. It learns a diverse prompt bank and performs dynamic prompt selection for each input using a low-entropy criterion on the predictive distribution. This is combined with distillation of high-confidence LLM-derived attributes and strong/weak augmentation consistency to enable cross-modality generalization without backbone fine-tuning. The paper reports new state-of-the-art results on 11 MedMNIST+ 2D datasets across three generalization settings, with code released.
Significance. Should the empirical findings prove robust upon detailed examination, the work offers a lightweight adaptation strategy for VLMs in data-scarce biomedical domains, potentially advancing applications in medical image analysis where modality shifts and limited annotations are prevalent. The open-sourcing of code is a notable strength for reproducibility.
major comments (2)
- The abstract claims state-of-the-art performance on 11 datasets but provides no information on experimental protocols, baseline methods, statistical significance, or ablation studies. This omission hinders evaluation of whether the reported improvements are reliable and generalizable.
- The core mechanism of low-entropy prompt selection assumes that the predictive distribution from few-shot examples reliably identifies discriminative prompts. However, as noted in the paper's own discussion of challenging regimes with small inter-class margins, few-shot predictive distributions are often high-entropy and miscalibrated, which could cause the selection to favor spurious patterns over modality-appropriate prompts, undermining the claimed coupling of few-shot evidence with LLM priors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point-by-point below, providing clarifications and indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: The abstract claims state-of-the-art performance on 11 datasets but provides no information on experimental protocols, baseline methods, statistical significance, or ablation studies. This omission hinders evaluation of whether the reported improvements are reliable and generalizable.
Authors: We agree that the abstract is concise and omits key details on protocols, baselines, significance, and ablations, which are instead provided in the full manuscript (Section 4 for protocols and baselines in Table 1, Section 4.3 for multi-seed statistics, and Section 5 for ablations). To address this, we have revised the abstract to briefly note the three generalization settings on MedMNIST+ datasets, comparison to strong baselines such as BioMedCLIP and CoOp, and that results are averaged over multiple runs with standard deviations reported. This change improves evaluability without exceeding length constraints. revision: yes
-
Referee: The core mechanism of low-entropy prompt selection assumes that the predictive distribution from few-shot examples reliably identifies discriminative prompts. However, as noted in the paper's own discussion of challenging regimes with small inter-class margins, few-shot predictive distributions are often high-entropy and miscalibrated, which could cause the selection to favor spurious patterns over modality-appropriate prompts, undermining the claimed coupling of few-shot evidence with LLM priors.
Authors: We acknowledge the referee's point and the paper's own discussion of high-entropy regimes in challenging modalities. However, low-entropy selection is not applied in isolation: it is explicitly combined with LLM attribute distillation and strong/weak augmentation consistency to regularize against spurious patterns and miscalibration. The LLM priors provide semantic guidance precisely when few-shot evidence is weak, and consistency enforces modality-appropriate behavior. We have added a new subsection with qualitative prompt visualizations and quantitative entropy analysis across datasets to demonstrate that selected prompts align with discriminative features rather than noise. This supports rather than undermines the coupling, as evidenced by the consistent SOTA gains. revision: partial
Circularity Check
No significant circularity in empirical prompt-learning framework
full rationale
The paper presents BioVLM as an empirical prompt-learning method that learns a prompt bank and applies dynamic selection via low-entropy criterion on the predictive distribution, plus LLM attribute distillation and augmentation consistency. No equations, derivations, or self-citations are provided that reduce the method or SOTA claims to fitted inputs by construction. The approach is self-contained, with code release and validation on external MedMNIST+ datasets across generalization settings, satisfying the criteria for an independent empirical framework without self-definitional loops or renamed fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling open-vocabulary image segmentation with image-level labels. InECCV. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Chuan Guo, Geoff Pleiss, Yu Sun, and Kili...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Baple: Backdoor attacks on medical foun- dational models using prompt learning. InInter- national Conference on Medical Image Computing and Computer-Assisted Intervention, pages 443–453. Springer. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Md Nazmul Islam, Mehedi Hasan, Md Kabir Hossain, Md Golam Rabiul Alam, Md Zia Uddin, and Ahmet Soylu
Quilt-1m: One million image-text pairs for histopathology.Advances in neural information pro- cessing systems, 36:37995–38017. Md Nazmul Islam, Mehedi Hasan, Md Kabir Hossain, Md Golam Rabiul Alam, Md Zia Uddin, and Ahmet Soylu. 2022. Vision transformer and explainable transfer learning models for auto detection of kidney cyst, stone and tumor from ct-rad...
2022
-
[4]
Jakob Nikolas Kather, Cleo-Aron Weis, Francesco Bian- coni, Susanne M Melchers, Lothar R Schad, Timo Gaiser, Alexander Marx, and Frank Gerrit Zöllner
Springer. Jakob Nikolas Kather, Cleo-Aron Weis, Francesco Bian- coni, Susanne M Melchers, Lothar R Schad, Timo Gaiser, Alexander Marx, and Frank Gerrit Zöllner
-
[5]
Multi-class texture analysis in colorectal can- cer histology.Scientific reports, 6(1):27988. Daniel S Kermany, Michael Goldbaum, Wenjia Cai, Car- olina CS Valentim, Huiying Liang, Sally L Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, and 1 others. 2018. Identifying medical diag- noses and treatable diseases by image-based deep learning.cell, ...
-
[6]
10 Julio Silva-Rodriguez, Hadi Chakor, Riadh Kobbi, Jose Dolz, and Ismail Ben Ayed
Test-time prompt tuning for zero-shot gener- alization in vision-language models.arXiv preprint arXiv:2209.07511. 10 Julio Silva-Rodriguez, Hadi Chakor, Riadh Kobbi, Jose Dolz, and Ismail Ben Ayed. 2025. A foundation language-image model of the retina (flair): Encoding expert knowledge in text supervision.Medical Image Analysis, 99:103357. Mainak Singha, ...
-
[7]
CLIPoint3D: Language-Grounded Few-Shot Unsupervised 3D Point Cloud Domain Adaptation
Clipoint3d: Language-grounded few-shot un- supervised 3d point cloud domain adaptation.arXiv preprint arXiv:2602.20409. Mainak Singha, Subhankar Roy, Sarthak Mehrotra, Ankit Jha, Moloud Abdar, Biplab Banerjee, and Elisa Ricci. 2025. Fedmvp: Federated multimodal visual prompt tuning for vision-language models. InPro- ceedings of the IEEE/CVF International ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler
Covid-19 infection localization and severity grading from chest x-ray images.Computers in biol- ogy and medicine, 139:105002. Philipp Tschandl, Cliff Rosendahl, and Harald Kittler
-
[9]
The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pig- mented skin lesions.Scientific data, 5(1):180161. Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Ji- meng Sun. 2022. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the Conference on Empirical Methods in Natu- ral Language Proc...
-
[10]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.Pro- ceedings of the 60th Annual Meeting of the Associa- tion for Computational Linguistics (Volume 2: Short Papers). Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023. Adalora: Adap- tive ...
work page internal anchor Pith review arXiv 2023
-
[11]
Overview of the MedMNIST+ datasets: In Table A3, we provide a detailed overview of the datasets included in MedMNIST+, high- lighting key attributes such as imaging modal- ity, number of classes, total samples, and the standardized training, validation, and test- ing splits. MedMNIST+ comprises 11 pub- licly available 2D medical image classifica- tion dat...
-
[12]
Overview of the 11 biomedical datasets: We also conduct experiments on 11 biomedical datasets spanning diverse imaging modalities, following the same train-validation-test splits as in (Koleilat et al., 2025). These datasets in- clude CTKidney (Islam et al., 2022) for com- puted tomography; DermaMNIST (Codella et al., 2019; Tschandl et al., 2018) for der-...
2025
-
[13]
and KneeXray (Chen, 2018) for X-ray imaging
2018
-
[14]
used by BioMedCoOp (Koleilat et al., 2025) under few-shot learning and base-to-new gen- eralization settings respectively
Few-shot learning and base-to-new gen- eralization on the biomedical benchmark datasets:Tables A4 and A5 present the com- parison of BioVLM with state-of-the-art base- line methods across the biomedical datasets (0.5,0.5,0.5) (0.5,0.5,1) (1,0.5,0.5) (1,0.5,1) (1,1,1) Lambda combinations ( , , ) 46 48 50 52 54 56 58 60Accuracy (%)49.19 50.92 51.24 51.77 50...
2025
-
[15]
using Expected Cali- bration Error (ECE) (Guo et al., 2017)
Model Calibration Performance:Beyond classification accuracy, we analyze model cal- ibration on the few-shot learning task across 11 biomedical datasets. using Expected Cali- bration Error (ECE) (Guo et al., 2017). As shown in Table A6, our BioVLM demon- strates consistently stronger calibration than the compared methods across diverse biomed- ical modali...
2017
-
[16]
The results show that variations in the choice of LLM have minimal effect on our proposed method, with BioVLM consistently outperforming all base- lines across both tasks
Effect of different LLMs:In Table A2, we present the impact of different LLMs includ- ing Llama-3.2-3B (Grattafiori et al., 2024), Qwen2.5-14B (Yang et al., 2024), Phi-4 (Ab- din et al., 2024) and GPT-4o (Hurst et al., 2024), on the Base-to-New Generalization and Few-shot learning tasks. The results show that variations in the choice of LLM have minimal e...
2024
-
[17]
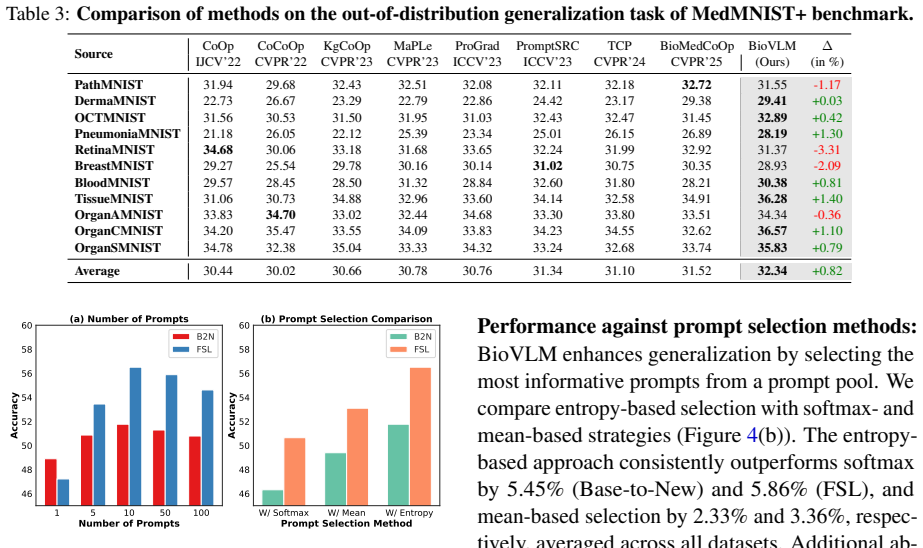
Ablation with additional prompt-selection methods:Table A1 compares different strate- gies for selecting or aggregating prompts from the prompt bank. In our method, each class is represented by multiple LLM-guided learnable prompts, and each prompt pro- duces image-text similarity scores through the frozen encoders.Softmaxdirectly uses prob- ability score...
-
[18]
As shown in Table A7,BioVLMconsistently outper- forms all PEFT baselines, demonstrating stronger adaptation under limited supervi- sion
Comparison with PEFT methods.We compare BioVLM with representative PEFT methods on the few-shot learning task of the MedMNIST+ benchmark. As shown in Table A7,BioVLMconsistently outper- forms all PEFT baselines, demonstrating stronger adaptation under limited supervi- sion. Compared with LoRA (Hu et al., 2022), AdaLoRA (Zhang et al., 2023), Lay- erNorm (K...
2022
-
[19]
The plot clearly shows that BioVLM achieves better class separation compared to BioMedCoOp
Qualitative results:Figure A2 presents the t-SNE visualization of the logits from BioMedCoOp and BioVLM on the PathM- NIST dataset in the few-shot setting. The plot clearly shows that BioVLM achieves better class separation compared to BioMedCoOp
-
[20]
small round cell with the nucleus making up most of the cell volume
Details results on Out-of-Domain gener- alization task:In Tables A8 - A18, we showcase the performance of Out-of-Domain (OOD) generalization task on 11 datasets, where our proposed BioVLM outperforms the state-of-the-art prompt learning methods by significant margin. Table A1:Ablation of prompt selection methods in BioVLM on Base-to-New Generalization and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.