Recognition: unknown
ThreadSumm: Summarization of Nested Discourse Threads Using Tree of Thoughts
Pith reviewed 2026-05-10 05:28 UTC · model grok-4.3
The pith
ThreadSumm extracts discourse aspects and atomic units then searches multiple summary candidates with Tree of Thoughts to handle nested discussion threads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
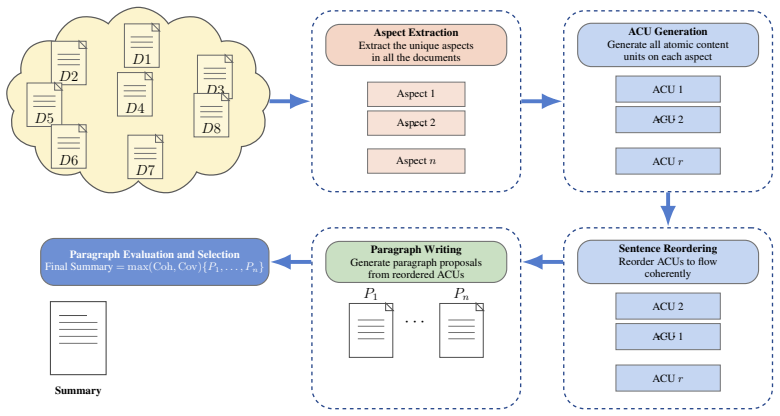
ThreadSumm first extracts discourse aspects and Atomic Content Units from the nested thread, applies sentence ordering to build thread-aware sequences, and then runs Tree of Thoughts to generate and score multiple paragraph candidates that jointly optimize coherence and coverage, yielding summaries with improved logical structure, higher aspect retention, and greater opinion coverage than existing baselines.
What carries the argument
Tree of Thoughts search over paragraph candidates generated from explicit aspect and Atomic Content Unit representations, used to jointly optimize coherence and coverage.
If this is right
- Summaries surface multiple viewpoints instead of collapsing to one linear strand.
- Explicit aspect and content unit representations make the generated summaries more interpretable.
- Iterative refinement within a single search space improves both logical flow and completeness.
- The approach generalizes to any nested discourse where replies and quotes overlap.
Where Pith is reading between the lines
- The same extraction-plus-search pattern could be tested on other hierarchically structured texts such as email chains or comment sections in news articles.
- Grounding summaries in atomic units extracted upfront may reduce the risk of missing minority opinions that linear prompts often overlook.
- If the ordering step proves robust, it might serve as a lightweight pre-processing stage for other discourse-level tasks.
Load-bearing premise
That large language models can extract discourse aspects and atomic content units accurately enough to capture interleaved replies and overlapping topics without introducing major errors or biases.
What would settle it
Running the method and standard LLM baselines on a held-out set of deeply nested threads and checking whether the new summaries show statistically higher scores on aspect retention and opinion coverage metrics.
Figures








read the original abstract
Summarizing deeply nested discussion threads requires handling interleaved replies, quotes, and overlapping topics, which standard LLM summarizers struggle to capture reliably. We introduce ThreadSumm, a multi-stage LLM framework that treats thread summarization as a hierarchical reasoning problem over explicit aspect and content unit representations. Our method first performs content planning via LLM-based extraction of discourse aspects and Atomic Content Units, then applies sentence ordering to construct thread-aware sequences that surface multiple viewpoints rather than a single linear strand. On top of these interpretable units, ThreadSumm employs a Tree of Thoughts search that generates and scores multiple paragraph candidates, jointly optimizing coherence and coverage within a unified search space. With this multi-proposal and iterative refinement design, we show improved performance in generating logically structured summaries compared to existing baselines, while achieving higher aspect retention and opinion coverage in nested discussions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ThreadSumm, a multi-stage LLM framework for summarizing deeply nested discussion threads. It performs LLM-based extraction of discourse aspects and Atomic Content Units, applies sentence ordering to build thread-aware sequences, and employs Tree of Thoughts search to generate and iteratively refine multiple paragraph candidates, jointly optimizing for coherence and coverage. The authors claim this yields improved logical structure, higher aspect retention, and better opinion coverage compared to existing baselines.
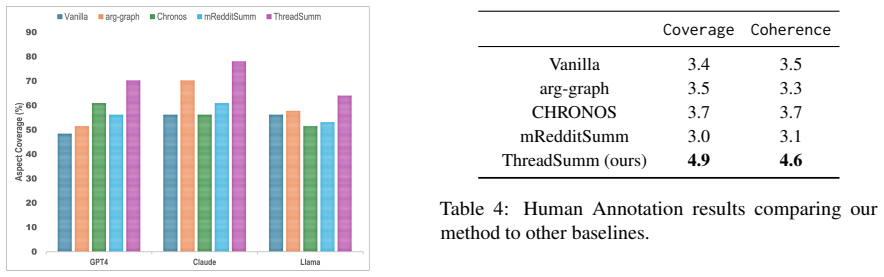
Significance. If the empirical results hold, the work provides a structured, interpretable alternative to direct LLM summarization for complex online discourse, addressing challenges like interleaved replies and multi-viewpoint coverage through explicit content planning and search-based refinement. This could be relevant for applications in forum and social media analysis, though the lack of visible experimental details limits its assessed contribution to the field.
major comments (3)
- [Abstract] Abstract: The central claim of 'improved performance in generating logically structured summaries' and 'higher aspect retention and opinion coverage' is presented without any quantitative metrics (e.g., ROUGE, human evaluation scores), baseline descriptions, dataset details, or experimental setup, leaving the primary contribution unsupported by evidence.
- [Framework description] Framework description (content planning stage): The LLM-based extraction of discourse aspects and Atomic Content Units, followed by sentence ordering, is described at a high level but provides no information on prompt design, few-shot examples, or validation (e.g., inter-annotator agreement or error analysis). Since errors in this foundational step would directly propagate into the Tree of Thoughts search space and undermine later refinement, this is load-bearing for the reliability claims.
- [Tree of Thoughts component] Tree of Thoughts component: The scoring mechanism for evaluating paragraph candidates (jointly optimizing coherence and coverage) is not specified, including any details on the search algorithm, heuristics, or how multiple proposals are compared, making it impossible to assess whether the multi-proposal design actually delivers the claimed improvements.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly define 'Atomic Content Units' and 'thread-aware sequences' on first use to improve readability for readers unfamiliar with the specific terminology.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the paper to incorporate additional details and quantitative support as outlined.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'improved performance in generating logically structured summaries' and 'higher aspect retention and opinion coverage' is presented without any quantitative metrics (e.g., ROUGE, human evaluation scores), baseline descriptions, dataset details, or experimental setup, leaving the primary contribution unsupported by evidence.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports experimental comparisons against baselines on nested discussion datasets, with metrics including ROUGE scores for coherence and human evaluations for aspect retention and opinion coverage. In the revised version, we will update the abstract to concisely report these specific improvements and experimental details. revision: yes
-
Referee: [Framework description] Framework description (content planning stage): The LLM-based extraction of discourse aspects and Atomic Content Units, followed by sentence ordering, is described at a high level but provides no information on prompt design, few-shot examples, or validation (e.g., inter-annotator agreement or error analysis). Since errors in this foundational step would directly propagate into the Tree of Thoughts search space and undermine later refinement, this is load-bearing for the reliability claims.
Authors: We acknowledge that the content planning stage requires more implementation details to support reproducibility and address potential error propagation. We will expand this section (and add an appendix if needed) with the exact prompt templates, few-shot examples, and validation steps such as manual error analysis or agreement metrics used for aspect and Atomic Content Unit extraction. revision: yes
-
Referee: [Tree of Thoughts component] Tree of Thoughts component: The scoring mechanism for evaluating paragraph candidates (jointly optimizing coherence and coverage) is not specified, including any details on the search algorithm, heuristics, or how multiple proposals are compared, making it impossible to assess whether the multi-proposal design actually delivers the claimed improvements.
Authors: We will revise the Tree of Thoughts section to fully specify the scoring mechanism, including how coherence and coverage are jointly evaluated (via LLM-based judges or defined heuristics), the search algorithm (e.g., branching factor, depth limits, and selection criteria), and the comparison process among paragraph candidates. This will allow readers to assess the multi-proposal refinement approach. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents a descriptive multi-stage LLM engineering framework for thread summarization with no mathematical derivations, equations, fitted parameters, or self-referential predictions. Content planning via aspect/ACU extraction and sentence ordering, followed by Tree of Thoughts search, relies on external LLM capabilities rather than any internal derivation that reduces to its own inputs by construction. Claims of improved performance are supported by empirical comparisons to baselines, with no load-bearing steps equivalent to the inputs. This is the expected honest non-finding for an applied NLP system description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BooookScore : A systematic exploration of book-length summarization in the era of LLMs
Booookscore: A systematic exploration of book-length summarization in the era of llms.arXiv preprint arXiv:2310.00785. Alexander Richard Fabbri, Faiaz Rahman, Imad Rizvi, Borui Wang, Haoran Li, Yashar Mehdad, and Dragomir Radev. 2021. Convosumm: Conversation summarization benchmark and improved abstractive summarization with argument mining. InProceed- in...
-
[2]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Using bert encoding and sentence-level lan- guage model for sentence ordering. InInternational Conference on Text, Speech, and Dialogue, pages 318–330. Springer. Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xi- angliang Zhang. 2024. Large language model based multi-agents: A survey of progress and chall...
work page internal anchor Pith review arXiv 2024
-
[3]
Amy Zhang, Bryan Culbertson, and Praveen Paritosh
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Amy Zhang, Bryan Culbertson, and Praveen Paritosh
-
[4]
Characterizing online discussion using coarse discourse sequences. Inproceedings of the interna- tional AAAI conference on web and social media, volume 11, pages 357–366. Shiyue Zhang, Asli Celikyilmaz, Jianfeng Gao, and Mohit Bansal. 2021. Emailsum: Abstractive email thread summarization.arXiv preprint arXiv:2107.14691. Yusen Zhang, Ruoxi Sun, Yanfei Che...
-
[5]
Read the document carefully
-
[6]
Read the Aspect list carefully
-
[7]
For each aspect, identify all distinct fac- tual claims, propositions, or ideas
-
[8]
Each ACU should express only one idea
-
[9]
Each ACU should be independent of surrounding text
-
[10]
Each ACU should be written in clear and concise language
-
[11]
Rewrite each idea as a minimal, stan- dalone statement
-
[12]
Do not include reasoning steps or expla- nations, only the extracted statements
-
[13]
Output the ACUs in a list, where each item is one ACU string
-
[14]
Figure 6: ACU Generation Prompt A.3 Sentence Ordering We use the prompt in Figure 7 to reorder the ACUs generated in the previous sentence to form a coher- ent flow
Return only the file as output. Figure 6: ACU Generation Prompt A.3 Sentence Ordering We use the prompt in Figure 7 to reorder the ACUs generated in the previous sentence to form a coher- ent flow. Sentence Ordering Prompt You are an expert at reordering documents for them to follow a logical and coherent flow. Ensure every sentence appears ex- actly once...
-
[15]
Coherence (logical flow, readability, and overall structure, ranging from 0.0 to 1.0)
-
[16]
Coverage (how completely it includes all key ideas/sentences from the original text, ranging from 0.0 to 1.0) Return the two scores as two numbers separated by a space (e.g., ’0.9 1.0’). If the paragraph con- tains significantly fewer or more sentences than the original text, or if it changes the core meaning, score coverage lower. Do not provide any othe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.