Recognition: unknown
Semantic Entanglement in Vector-Based Retrieval: A Formal Framework and Context-Conditioned Disentanglement Pipeline for Agentic RAG Systems
Pith reviewed 2026-05-10 05:27 UTC · model grok-4.3
The pith
Documents with interleaved topics create overlapping embeddings that limit retrieval precision; a four-stage pipeline restructures them to lower the Entanglement Index and raise Top-K accuracy from 32 percent to 82 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
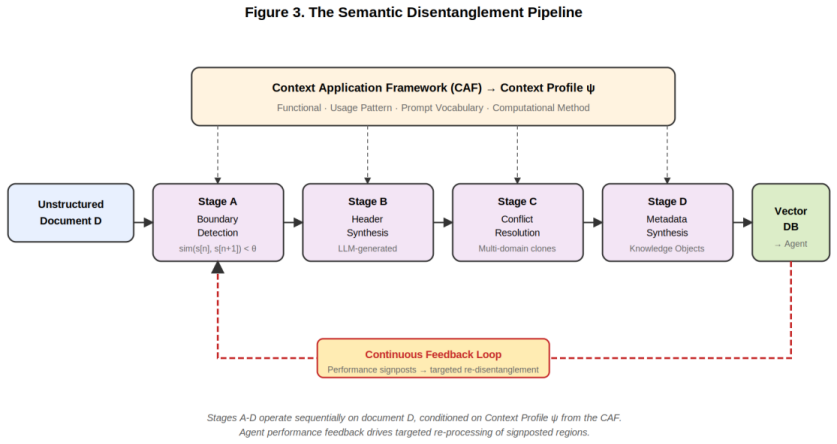
Source documents that interleave multiple topics within contiguous text produce embedding spaces in which semantically distinct content occupies overlapping neighborhoods; this condition, termed semantic entanglement and quantified by the Entanglement Index, constrains attainable Top-K retrieval precision under cosine similarity. The Semantic Disentanglement Pipeline counters it by applying four stages of context-conditioned restructuring prior to vectorization, with an additional continuous feedback loop that adapts document structure according to observed agent performance.
What carries the argument
The Entanglement Index (EI), a model-relative scalar that measures cross-topic overlap within the embedding neighborhoods of a document, serves as both diagnostic and target; the four-stage Semantic Disentanglement Pipeline then reduces this index by breaking and reassembling text according to patterns of operational use before any vector is computed.
If this is right
- Lower measured entanglement directly expands the region of embedding space from which correct evidence can be retrieved by simple cosine similarity.
- Context-conditioned preprocessing produces document structures that match the actual distribution of queries an agent will issue rather than a fixed token budget.
- The feedback loop allows document boundaries to evolve as agent behavior changes, keeping entanglement low without manual re-chunking.
- Once entanglement is reduced at the preprocessing stage, downstream components such as rerankers or prompt engineers no longer need to compensate for an irrecoverable overlap that was baked into the vectors.
Where Pith is reading between the lines
- The same restructuring logic could be tested on non-healthcare corpora that also mix regulatory, procedural, and explanatory content to check whether EI reduction remains the operative factor.
- Because the pipeline acts before any embedding model is applied, its gains should be largely independent of the choice of encoder, but this independence could be verified by repeating the evaluation across several embedding families.
- If EI can be monitored continuously in production, it supplies an early-warning signal that a knowledge base is drifting into higher entanglement and may need reprocessing.
- The approach leaves open whether certain topic mixtures are inherently harder to disentangle than others and therefore set a lower bound on achievable precision.
Load-bearing premise
The measured gains in retrieval precision are caused by the reduction in semantic entanglement rather than by other elements of the four-stage pipeline, by particular traits of the healthcare dataset, or by implementation choices not reported in the evaluation.
What would settle it
An ablation that applies the same four-stage restructuring steps but does not track or minimize the Entanglement Index and still records the full jump from 32 percent to 82 percent precision would show that EI reduction is not required for the observed improvement.
Figures




read the original abstract
Retrieval-Augmented Generation (RAG) systems depend on the geometric properties of vector representations to retrieve contextually appropriate evidence. When source documents interleave multiple topics within contiguous text, standard vectorization produces embedding spaces in which semantically distinct content occupies overlapping neighborhoods. We term this condition semantic entanglement. We formalize entanglement as a model-relative measure of cross-topic overlap in embedding space and define an Entanglement Index (EI) as a quantitative proxy. We argue that higher EI constrains attainable Top-K retrieval precision under cosine similarity retrieval. To address this, we introduce the Semantic Disentanglement Pipeline (SDP), a four-stage preprocessing framework that restructures documents prior to embedding. We further propose context-conditioned preprocessing, in which document structure is shaped by patterns of operational use, and a continuous feedback mechanism that adapts document structure based on agent performance. We evaluate SDP on a real-world enterprise healthcare knowledge base comprising over 2,000 documents across approximately 25 sub-domains. Top-K retrieval precision improves from approximately 32% under fixed-token chunking to approximately 82% under SDP, while mean EI decreases from 0.71 to 0.14. We do not claim that entanglement fully explains RAG failure, but that it captures a distinct preprocessing failure mode that downstream optimization cannot reliably correct once encoded into the vector space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic entanglement arises when source documents interleave multiple topics, producing overlapping neighborhoods in embedding space that constrain Top-K retrieval precision under cosine similarity. It formalizes entanglement via a model-relative Entanglement Index (EI) as a quantitative proxy, argues that higher EI limits attainable precision, and introduces the Semantic Disentanglement Pipeline (SDP), a four-stage preprocessing framework that includes context-conditioned restructuring and a continuous feedback loop adapting document structure to agent performance. Evaluation on a real-world enterprise healthcare knowledge base (>2,000 documents, ~25 sub-domains) reports Top-K precision rising from ~32% (fixed-token chunking) to ~82% (SDP) with mean EI falling from 0.71 to 0.14.
Significance. If the attribution of precision gains specifically to EI reduction is established, the work would identify a distinct preprocessing failure mode in RAG that cannot be corrected downstream once encoded in vector space. The formalization of EI, the proposal of context-conditioned adaptation, and the use of a large real enterprise dataset with quantitative before/after metrics constitute concrete contributions that could guide further research on agentic RAG systems.
major comments (2)
- §5 (Evaluation): The central claim that precision improves because SDP reduces semantic entanglement (EI drop from 0.71 to 0.14) rests on a single baseline (fixed-token chunking) without stage-wise ablations of the four SDP components, comparisons to alternative non-entanglement-aware chunkers, or controls that vary only the overlap metric while holding document structure fixed. This leaves the operative mechanism unisolated.
- §3 (Formal framework) and §5: The Entanglement Index is defined as a model-relative proxy for cross-topic overlap, yet the manuscript provides insufficient detail on its exact computation, topic identification procedure, and SDP stage specifications. Because the evaluation demonstrates that SDP lowers EI and raises precision without independent grounding of EI outside the pipeline, the reported correlation risks circularity.
minor comments (3)
- Abstract and §5: Results are reported with approximate values (e.g., 'approximately 32%', 'approximately 82%') and lack error bars, confidence intervals, or statistical significance tests.
- §5: The single-dataset evaluation on a healthcare KB leaves open whether gains exploit domain-specific topic interleaving patterns independent of the EI definition; additional datasets or cross-domain tests would strengthen generalizability.
- Throughout: The continuous feedback mechanism is described conceptually but its concrete implementation and triggering conditions during the reported evaluation are not specified, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important gaps in the evaluation design and the formal presentation of the Entanglement Index. We address each point below and commit to revisions that strengthen the isolation of the claimed mechanism and the transparency of the formalization.
read point-by-point responses
-
Referee: §5 (Evaluation): The central claim that precision improves because SDP reduces semantic entanglement (EI drop from 0.71 to 0.14) rests on a single baseline (fixed-token chunking) without stage-wise ablations of the four SDP components, comparisons to alternative non-entanglement-aware chunkers, or controls that vary only the overlap metric while holding document structure fixed. This leaves the operative mechanism unisolated.
Authors: We agree that the current evaluation design does not fully isolate the contribution of EI reduction. In the revised manuscript we will add (i) stage-wise ablations that apply each of the four SDP stages in isolation and in combination, (ii) comparisons against two additional non-entanglement-aware chunkers (semantic similarity-based chunking and hierarchical chunking), and (iii) a controlled experiment that holds document structure fixed while varying only the overlap metric used to compute EI. These additions will be reported with the same healthcare knowledge base to demonstrate that the observed precision gains are attributable to the measured reduction in semantic entanglement rather than to other structural changes. revision: yes
-
Referee: §3 (Formal framework) and §5: The Entanglement Index is defined as a model-relative proxy for cross-topic overlap, yet the manuscript provides insufficient detail on its exact computation, topic identification procedure, and SDP stage specifications. Because the evaluation demonstrates that SDP lowers EI and raises precision without independent grounding of EI outside the pipeline, the reported correlation risks circularity.
Authors: We acknowledge that the current manuscript does not supply sufficient implementation-level detail. In the revision we will expand Section 3 with (a) the precise mathematical definition and algorithmic steps for computing the model-relative Entanglement Index, (b) the topic identification procedure (domain-expert-guided clustering followed by manual validation on the 25-sub-domain healthcare corpus), and (c) explicit pseudocode and parameter settings for each of the four SDP stages. To address the circularity concern we will also include an independent validation: EI will be computed on a held-out subset of documents that were never processed by SDP, and its correlation with retrieval precision will be reported separately from the main SDP experiments. revision: yes
Circularity Check
No significant circularity in derivation or evaluation
full rationale
The paper defines semantic entanglement and EI as a model-relative measure of cross-topic overlap in embedding space, argues it constrains retrieval precision, introduces the SDP four-stage pipeline to restructure documents, and reports empirical results on a 2,000-document healthcare KB (precision 32% to 82%, EI 0.71 to 0.14 vs. fixed-token baseline). No equations, definitions, or steps reduce a claimed result to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked. The evaluation is a direct before/after comparison on external data rather than a fitted prediction or renamed known result. Absence of stage-wise ablations is a methodological limitation for causal claims but does not create circularity in the formal framework or reported chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cosine similarity in embedding space reflects semantic relatedness for retrieval purposes
invented entities (2)
-
Entanglement Index (EI)
no independent evidence
-
Semantic Disentanglement Pipeline (SDP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
(2024, September 19)
Anthropic. (2024, September 19). Introducing contextual retrieval. Anthropic. https://www.anthropic.com/news/contextual-retrieval Barnett, S., Kurniawan, S., Thudumu, S., Brannelly, Z., & Abdelrazek, M. (2024). Seven failure points when engineering a retrieval augmented generation system. In Proceedings of the IEEE/ACM 3rd International Conference on AI E...
2024
-
[2]
(pp. 194–199). Association for Computing Machinery. https://doi.org/10.1145/3644815.3644945 Beeferman, D., Berger, A., & Lafferty, J. (1999). Statistical models for text segmentation. Machine Learning, 34(1–3), 177–210. https://doi.org/10.1023/A:1007506220214 Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine L...
-
[3]
(pp. 26–33). Association for Computational Linguistics. Ethayarajh, K. (2019). How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processin...
2019
-
[4]
(pp. 55–65). Association for Computational Linguistics. https://doi.org/10.18653/v1/D19- 1006 Galley, M., McKeown, K. R., Fosler-Lussier, E., & Jing, H. (2003). Discourse segmentation of multi-party conversation. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics (ACL
-
[5]
(pp. 562–569). Association for Computational Linguistics. https://doi.org/10.3115/1075096.1075167 Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Guo, Q., Wang, M., & Wang, H. (2024). Retrieval-augmented generation for large language models: A survey (arXiv:2312.10997). arXiv. https://arxiv.org/abs/2312.10997 33 Ghinassi, I., Cata...
-
[6]
https://doi.org/10.3390/bioengineering12111194 Günther, M., Mohr, I., Williams, D. J., Wang, B., & Xiao, H. (2024). Late chunking: Contextual chunk embeddings using long-context embedding models (arXiv:2409.04701). arXiv. https://arxiv.org/abs/2409.04701 Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M. (2020). Retrieval augmented language model pre-tr...
-
[7]
3929–3938)
(pp. 3929–3938). PMLR. Hearst, M. A. (1997). TextTiling: Segmenting text into multi-paragraph subtopic passages. Computational Linguistics, 23(1), 33–64. Hutchins, E. (1995). Cognition in the wild. MIT Press. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (...
1997
-
[8]
9459–9474)
(pp. 9459–9474). Curran Associates. Loghmani, N. M. (2025). Operational context's impact on cockpit behavior: Case studies in aviation [Doctoral dissertation, Syracuse University]. SURFACE Dissertations – ALL,
2025
-
[9]
https://surface.syr.edu/etd/2255/ Pevzner, L., & Hearst, M. A. (2002). A critique and improvement of an evaluation metric for text segmentation. Computational Linguistics, 28(1), 19–36. https://doi.org/10.1162/089120102317341756 Radovanović, M., Nanopoulos, A., & Ivanović, M. (2010). Hubs in space: Popular nearest neighbors in high-dimensional data. Journ...
-
[10]
Rajaee, S., & Pilehvar, M. T. (2021). A cluster-based approach for improving isotropy in contextual embedding space. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on 34 Natural Language Processing (Volume 2: Short Papers) (pp. 575–584). Association for Computational L...
-
[11]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
(pp. 3982–3992). Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1410 Riedl, M., & Biemann, C. (2012). TopicTiling: A text segmentation algorithm based on LDA. In Proceedings of ACL 2012 Student Research Workshop (pp. 37–42). Association for Computational Linguistics. Singh, A., Ehtesham, A., Mahmud, S., & Kim, J.-H. (2025). Age...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.