Recognition: unknown
Stratagem: Learning Transferable Reasoning via Trajectory-Modulated Game Self-Play
Pith reviewed 2026-05-10 05:22 UTC · model grok-4.3
The pith
Game self-play can produce reasoning that transfers across math, code, and general tasks when trajectories are scored for abstract patterns rather than just wins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
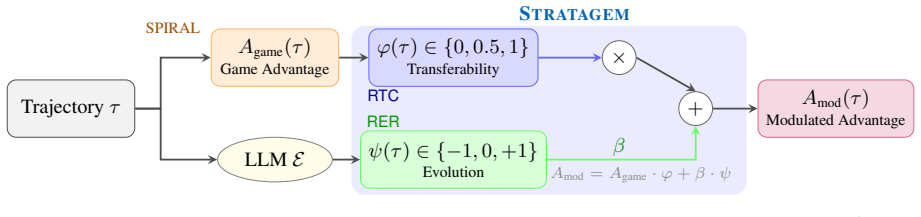
STRATAGEM modulates self-play trajectories so that only those exhibiting abstract, domain-agnostic reasoning receive extra reinforcement through a Reasoning Transferability Coefficient, while a Reasoning Evolution Reward pushes the model to develop progressively stronger reasoning across game iterations; the resulting policy yields measurable gains on out-of-domain benchmarks, most notably competition mathematics.
What carries the argument
The Reasoning Transferability Coefficient, a score that quantifies how little a reasoning trajectory depends on the current game's specific semantics, combined with the Reasoning Evolution Reward that tracks improvement in reasoning quality across successive self-play rounds.
If this is right
- Models exhibit stronger performance on competition-level mathematics that requires chaining many reasoning steps.
- Gains appear across mathematical reasoning, general reasoning, and code generation benchmarks rather than staying confined to the training games.
- Removing either the transferability coefficient or the evolution reward reduces the observed cross-domain improvements.
- Human judges rate the generated reasoning as more transferable when both components are active.
Where Pith is reading between the lines
- The same trajectory-scoring idea could be tested in non-game environments where the only feedback is correctness of the final answer.
- If the method works, it suggests a route to training reasoning systems that improve on entirely new task families without additional human demonstrations.
- The approach highlights a possible distinction between reasoning that optimizes for immediate success and reasoning that builds reusable structure.
Load-bearing premise
The new scores actually separate transferable reasoning patterns from game-specific shortcuts instead of simply favoring trajectories that happen to win more often.
What would settle it
Train two models on the same games, one with the new scores and one without; if the version without the scores matches or exceeds the version with them on out-of-domain math and code tasks, the claim that the scores isolate transferable reasoning does not hold.
Figures


















read the original abstract
Games offer a compelling paradigm for developing general reasoning capabilities in language models, as they naturally demand strategic planning, probabilistic inference, and adaptive decision-making. However, existing self-play approaches rely solely on terminal game outcomes, providing no mechanism to distinguish transferable reasoning patterns from game-specific heuristics. We present STRATAGEM, which addresses two fundamental barriers to reasoning transfer: domain specificity, where learned patterns remain anchored in game semantics, and contextual stasis, where static game contexts fail to cultivate progressive reasoning. STRATAGEM selectively reinforces trajectories exhibiting abstract, domain-agnostic reasoning through a Reasoning Transferability Coefficient, while incentivizing adaptive reasoning development via a Reasoning Evolution Reward. Experiments across mathematical reasoning, general reasoning, and code generation benchmarks demonstrate substantial improvements, with particularly strong gains on competition-level mathematics where multi-step reasoning is critical. Ablation studies and human evaluation confirm that both components contribute to transferable reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STRATAGEM, a self-play framework for language models that modulates game trajectories to learn transferable reasoning. It proposes a Reasoning Transferability Coefficient (RTC) to selectively reinforce trajectories exhibiting abstract, domain-agnostic patterns and a Reasoning Evolution Reward (RER) to incentivize progressive adaptive reasoning, addressing limitations of terminal-outcome-only self-play. Experiments on mathematical reasoning, general reasoning, and code generation benchmarks report substantial gains, especially on competition-level math, with ablations and human evaluations supporting the contributions of both components.
Significance. If the RTC and RER mechanisms can be shown to isolate transferable reasoning rather than proxying raw performance, the work would meaningfully advance game-based self-play beyond outcome-driven RL by tackling domain specificity and contextual stasis. This could influence scalable training of general reasoning capabilities in LLMs, particularly where multi-step inference is required.
major comments (3)
- [§3] §3 (Method): The manuscript provides no explicit formula, pseudocode, or computation procedure for the Reasoning Transferability Coefficient, preventing verification that it is independent of terminal game rewards, trajectory length, or embedding similarity to successful outcomes as required to support the domain-agnostic transfer claim.
- [§4] §4 (Experiments): No quantitative baseline comparisons, effect sizes, statistical significance tests, or implementation details (e.g., how coefficients are applied during self-play) are reported, so it is impossible to determine whether observed gains on competition-level mathematics exceed what standard RL scaling would produce.
- [§4.3] §4.3 (Ablations): The ablation results are described only qualitatively; without reporting exact performance deltas when RTC or RER is removed, the claim that both components are necessary for transferable reasoning cannot be evaluated against the alternative that they simply amplify high-reward trajectories.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., absolute accuracy gains on a named benchmark) to convey the scale of improvement.
- [§3] Notation for RTC and RER should be introduced with a clear equation or algorithmic step in the main text rather than left at the conceptual level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving clarity and rigor in the presentation of STRATAGEM. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The manuscript provides no explicit formula, pseudocode, or computation procedure for the Reasoning Transferability Coefficient, preventing verification that it is independent of terminal game rewards, trajectory length, or embedding similarity to successful outcomes as required to support the domain-agnostic transfer claim.
Authors: We agree that the initial manuscript did not provide sufficient detail on the Reasoning Transferability Coefficient (RTC). The RTC is formulated as a normalized abstraction score based on the divergence between a trajectory's step-wise embedding and a reference set of domain-agnostic reasoning motifs, explicitly excluding terminal rewards and applying length normalization via padding and averaging. We will add the complete mathematical definition, pseudocode, and a step-by-step computation procedure to the revised Section 3, allowing direct verification of its independence from game-specific factors. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative baseline comparisons, effect sizes, statistical significance tests, or implementation details (e.g., how coefficients are applied during self-play) are reported, so it is impossible to determine whether observed gains on competition-level mathematics exceed what standard RL scaling would produce.
Authors: We acknowledge that the experimental section requires more quantitative rigor. In the revision, we will incorporate direct comparisons to standard RL baselines (including outcome-only self-play and PPO variants), report effect sizes, include statistical significance testing (e.g., paired t-tests with p-values), and specify implementation details such as the exact weighting and application schedule of RTC and RER within the self-play reward function. These additions will clarify that gains on competition-level mathematics go beyond what would be expected from RL scaling alone. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): The ablation results are described only qualitatively; without reporting exact performance deltas when RTC or RER is removed, the claim that both components are necessary for transferable reasoning cannot be evaluated against the alternative that they simply amplify high-reward trajectories.
Authors: The ablation results were presented qualitatively in the original submission to emphasize overall trends. We will revise Section 4.3 to include precise numerical performance deltas for each ablation condition (e.g., exact accuracy drops on MATH, GSM8K, and code benchmarks when RTC or RER is removed), accompanied by updated tables. This will enable quantitative evaluation of whether the components provide benefits beyond simple amplification of high-reward trajectories. revision: yes
Circularity Check
No circularity: conceptual method with no equations or self-referential reductions
full rationale
The paper introduces STRATAGEM via the Reasoning Transferability Coefficient and Reasoning Evolution Reward as mechanisms for selective reinforcement of transferable reasoning trajectories. However, the provided text contains no equations, derivations, fitted parameters, or self-citations that define these components in terms of themselves or reduce any claimed prediction to the input data by construction. The approach is presented at a high level with reference to experimental outcomes on external benchmarks, rendering the description self-contained without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- Reasoning Transferability Coefficient
- Reasoning Evolution Reward
axioms (1)
- domain assumption Games naturally demand strategic planning, probabilistic inference, and adaptive decision-making.
invented entities (2)
-
Reasoning Transferability Coefficient
no independent evidence
-
Reasoning Evolution Reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on large language model-based social agents in game-theoretic scenarios,
Reasoning does not necessarily improve role- playing ability. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10301– 10314. Xiachong Feng, Longxu Dou, Ella Li, Qinghao Wang, Haochuan Wang, Yu Guo, Chang Ma, and Ling- peng Kong. 2024. A survey on large language model-based social agents in game-theoretic scenar- ios.arXiv prepr...
-
[2]
Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games
Nitrogen: A foundation model for generalist gaming agents. Dongmin Park, Minkyu Kim, Beongjun Choi, Junhyuck Kim, Keon Lee, Jonghyun Lee, Inkyu Park, Byeong- Uk Lee, Jaeyoung Hwang, Jaewoo Ahn, Ameya Ma- habaleshwarkar, Bilal Kartal, Pritam Biswas, Yoshi Suhara, Kangwook Lee, and Jaewoong Cho. 2025. Orak: A foundational benchmark for training and evaluati...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Credit assignment: Rewards are typically sparse (given only at episode end), making it difficult to attribute credit across thousands of tokens
-
[4]
Temporal abstraction: Meaningful reasoning units span multiple tokens, but token-level opti- mization lacks this structure
-
[5]
Computational cost: Optimizing at the token level requires gradient computation through en- tire sequences We address these challenges by formulating a turn-level MDP, where actions correspond to com- plete responses rather than individual tokens. In this formulation: • States st ∈ S represent complete interaction con- texts, including the problem specifi...
1994
-
[6]
Alternating Turn Structure.In our formulation, players take turns rather than acting simultaneously
is a Nash equilibrium if neither player can improve by unilaterally deviating. Alternating Turn Structure.In our formulation, players take turns rather than acting simultaneously. At turn t, only player p=tmod 2 acts, while the other player’s action is null. This simplifies the transition dynamics: st+1 =T(s t, a(p) t )wherep=tmod 2(8) The alternating str...
2015
-
[7]
Each full training run completes in approximately 30 hours
for efficient inference. Each full training run completes in approximately 30 hours. I Game Environment Details This section provides detailed descriptions of the three text-based zero-sum games used for training. Tic-Tac-Toe.A classic 3×3 grid game serv- ing as our testbed forspatial reasoning. Players alternate placing marks to form horizontal, verti- c...
-
[8]
The game uses only three cards (Jack, Queen, King), where each player receives one card and must de- cide whether to bet, call, or fold based on incom- plete information
emphasizingprobabilistic reasoning. The game uses only three cards (Jack, Queen, King), where each player receives one card and must de- cide whether to bet, call, or fold based on incom- plete information. Success demands probability estimation, opponent modeling, and expected value calculation under uncertainty. Simple Negotiation.A resource trading gam...
2025
-
[9]
Game Sampling: Sample a game G∼ G from the game distribution
-
[10]
Trajectory Generation: Two instances of the current policy πθ play against each other, gener- ating trajectoryτ={(s t, y(p) t )}T t=0
-
[11]
Outcome Determination: The game engine de- termines the winner, assigning rewardsRp(τ)∈ {−1,0,+1}
-
[12]
K.3 Role-Conditioned Advantage Estimation A critical challenge in two-player games is that the expected return differs by role
Policy Update: Update θ using policy gradient with role-conditioned advantages The self-play mechanism ensures automatic cur- riculum learning: as the policy improves, its oppo- nent (itself) also improves, maintaining a challeng- ing training distribution throughout learning. K.3 Role-Conditioned Advantage Estimation A critical challenge in two-player ga...
-
[13]
King beats Queen
Domain Specificity: SPIRAL optimizes for game outcomes without explicitly encouraging abstract reasoning patterns. Winning strate- gies often rely on game-specific heuristics (e.g., “King beats Queen”) rather than domain- agnostic patterns (e.g., “enumerate cases and compute expected value”)
-
[14]
Contextual Stasis: Games present static prob- lem contexts where rules and settings remain fixed throughout interaction. SPIRAL does not incentivize reasoning that adapts to evolving contexts, yet real-world problems (e.g., mathe- matical proofs, code debugging) require contin- uous adaptation as intermediate results reshape the solution space. These chal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.