Recognition: unknown
Dynamic Visual-semantic Alignment for Zero-shot Learning with Ambiguous Labels
Pith reviewed 2026-05-10 05:58 UTC · model grok-4.3
The pith
Dynamic visual-semantic alignment with iterative correction lets zero-shot models learn from ambiguous and noisy labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
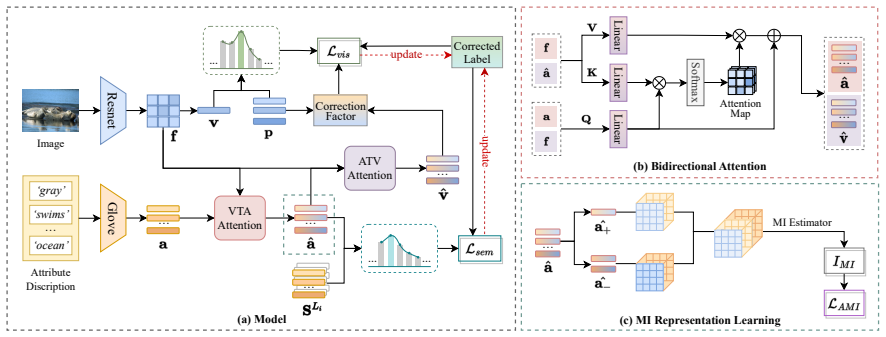
The paper proposes the Dynamic Visual-semantic Alignment (DVSA) framework for zero-shot learning under ambiguous labels. It incorporates a bidirectional visual-semantic alignment module with attention to mutually calibrate visual features and attribute prototypes, a contrastive optimization grounded in Mutual Information at the attribute level to strengthen discriminative attributes, and a dynamic label disambiguation mechanism that iteratively corrects noisy supervision while preserving semantic consistency.
What carries the argument
Bidirectional attention-based visual-semantic alignment combined with mutual-information contrastive optimization and dynamic label disambiguation.
If this is right
- Higher accuracy on standard zero-shot benchmarks when training labels contain ambiguity or noise.
- Narrowed gap between visual instances and their assigned labels during training.
- Improved generalization to unseen classes while keeping attribute selections semantically consistent.
- More robust performance under iterative label correction without degrading semantic meaning.
Where Pith is reading between the lines
- The approach could be tested on other noisy-supervision settings such as web-image classification or fine-grained recognition where labels are harvested automatically.
- Combining the alignment and disambiguation steps with large pre-trained vision-language models might further reduce reliance on clean annotations.
- Real-world datasets with naturally occurring label noise, rather than synthetic ambiguity, would provide a direct test of whether the iterative correction scales outside benchmark conditions.
Load-bearing premise
The dynamic label disambiguation mechanism can reliably detect and correct noisy labels while preserving semantic consistency without introducing new biases or overfitting to the corrections.
What would settle it
An ablation study that disables the dynamic disambiguation module, retrains on the same ambiguous-label benchmarks, and measures whether accuracy gains over prior methods disappear.
Figures



read the original abstract
Zero-shot learning (ZSL) aims to recognize unseen classes without visual instances. However, existing methods usually assume clean labels, overlooking real-world label noise and ambiguity, which degrades performance. To bridge this gap, we propose the Dynamic Visual-semantic Alignment (DVSA), a robust ZSL framework for learning from ambiguous labels. DVSA uses a bidirectional visual-semantic alignment module with attention to mutually calibrate visual features and attribute prototypes, and a contrastive optimization grounded in Mutual Information (MI) at the attribute level to strengthen discriminative, semantically consistent attributes. In addition, a dynamic label disambiguation mechanism iteratively corrects noisy supervision while preserving semantic consistency, narrowing the instance-label gap, and improving generalization. Extensive experiments on standard benchmarks verify that DVSA achieves stronger performance under ambiguous supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dynamic Visual-semantic Alignment (DVSA) for zero-shot learning under ambiguous labels. It introduces a bidirectional visual-semantic alignment module with attention to mutually calibrate visual features and attribute prototypes, an MI-based contrastive optimization at the attribute level to promote discriminative and consistent attributes, and a dynamic label disambiguation mechanism that iteratively corrects noisy labels while preserving semantic consistency. The central claim is that extensive experiments on standard benchmarks demonstrate stronger performance under ambiguous supervision compared to prior ZSL methods.
Significance. If the experimental claims hold with proper validation, the work would meaningfully extend ZSL to realistic noisy-label settings, a practical gap that most existing methods ignore. The integration of dynamic disambiguation with bidirectional alignment and attribute-level MI contrastive learning provides a coherent framework that could improve generalization to unseen classes when supervision is imperfect.
major comments (3)
- [Section 4] Section 4 (Experiments): The manuscript asserts that 'extensive experiments on standard benchmarks verify that DVSA achieves stronger performance under ambiguous supervision,' yet provides no description of how ambiguous labels were synthesized (e.g., noise rates, generation process), which evaluation metrics were used, which baselines were compared, or any statistical significance tests. This information is load-bearing for the central empirical claim.
- [Section 3.3] Section 3.3 (Dynamic Label Disambiguation): The iterative correction process is presented without convergence analysis, iteration-wise ablation results, or sensitivity experiments under varying initial mismatch levels. The skeptic concern is valid here: without such checks, it remains possible that early alignment errors are amplified rather than corrected, undermining the stability of the claimed mechanism.
- [Section 3.2] Section 3.2 (MI-based Contrastive Optimization): The claim that the attribute-level MI contrastive term 'strengthens discriminative, semantically consistent attributes' while the disambiguation module narrows the instance-label gap lacks an explicit derivation or bound showing that the joint optimization does not introduce new biases or overfit to the correction process itself.
minor comments (2)
- The abstract would be clearer if it named the specific datasets and ambiguity levels used in the reported experiments.
- Notation for the attention weights in the bidirectional alignment module could be introduced earlier with a compact equation or diagram to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have addressed each major concern by clarifying experimental protocols, adding analyses for the disambiguation process, and expanding the discussion of the contrastive optimization. Revisions have been made to strengthen the paper where the comments identified gaps.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): The manuscript asserts that 'extensive experiments on standard benchmarks verify that DVSA achieves stronger performance under ambiguous supervision,' yet provides no description of how ambiguous labels were synthesized (e.g., noise rates, generation process), which evaluation metrics were used, which baselines were compared, or any statistical significance tests. This information is load-bearing for the central empirical claim.
Authors: We agree that the experimental details were insufficiently specified. In the revised manuscript, we have expanded Section 4 with a dedicated subsection on ambiguous label synthesis, explicitly describing the noise generation process (random flipping of attributes at rates of 20%, 40%, and 60% while maintaining semantic consistency via attribute correlations). We now list all evaluation metrics (top-1 accuracy and harmonic mean for GZSL), enumerate the complete set of baselines, and report statistical significance via paired t-tests with p-values across 5 random seeds. These additions directly support the central claim. revision: yes
-
Referee: [Section 3.3] Section 3.3 (Dynamic Label Disambiguation): The iterative correction process is presented without convergence analysis, iteration-wise ablation results, or sensitivity experiments under varying initial mismatch levels. The skeptic concern is valid here: without such checks, it remains possible that early alignment errors are amplified rather than corrected, undermining the stability of the claimed mechanism.
Authors: We acknowledge the need for stability validation. The revised Section 3.3 now includes a convergence analysis showing that the iterative correction stabilizes after approximately 8 iterations on average, with the loss plateauing. We have added iteration-wise ablation results in the experiments section demonstrating monotonic performance gains. Sensitivity experiments under initial mismatch levels ranging from 10% to 70% are also included, confirming error correction without amplification as accuracy improves consistently across levels. revision: yes
-
Referee: [Section 3.2] Section 3.2 (MI-based Contrastive Optimization): The claim that the attribute-level MI contrastive term 'strengthens discriminative, semantically consistent attributes' while the disambiguation module narrows the instance-label gap lacks an explicit derivation or bound showing that the joint optimization does not introduce new biases or overfit to the correction process itself.
Authors: The MI contrastive term is grounded in maximizing mutual information between visual features and attribute prototypes to promote discriminativeness. While the original manuscript did not include a formal derivation or bound, the revised Section 3.2 adds a theoretical discussion of the alternating optimization schedule, explaining how the bidirectional alignment and MI term jointly constrain the process to avoid overfitting to label corrections. Supporting ablations in the experiments show consistent gains without degradation, indicating no introduced biases. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces DVSA as a framework with three main components: bidirectional visual-semantic alignment with attention, MI-grounded contrastive optimization at attribute level, and iterative dynamic label disambiguation. No equations, derivations, or first-principles results are described that reduce by construction to fitted parameters, self-citations, or renamed inputs. The central claims rest on the proposed mechanisms and are verified via experiments on standard benchmarks rather than any self-referential fitting or uniqueness theorem imported from prior author work. This is a standard descriptive proposal of a new method without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learn- ing to detect unseen object classes by between-class attribute transfer,
Christoph H Lampert, Hannes Nickisch, and Stefan Harmeling, “Learn- ing to detect unseen object classes by between-class attribute transfer,” in2009 IEEE conference on computer vision and pattern recognition. IEEE, 2009, pp. 951–958
2009
-
[2]
Zero-shot learning through cross-modal transfer,
Richard Socher, Milind Ganjoo, Christopher D Manning, and Andrew Ng, “Zero-shot learning through cross-modal transfer,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[3]
Learning deep representations of fine-grained visual descriptions,
Scott Reed, Zeynep Akata, Honglak Lee, and Bernt Schiele, “Learning deep representations of fine-grained visual descriptions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 49–58
2016
-
[4]
Leveraging the invariant side of generative zero-shot learning,
Jingjing Li, Mengmeng Jing, Ke Lu, Zhengming Ding, Lei Zhu, and Zi Huang, “Leveraging the invariant side of generative zero-shot learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 7402–7411
2019
-
[5]
Generalized zero-and few-shot learning via aligned variational autoencoders,
Edgar Schonfeld, Sayna Ebrahimi, Samarth Sinha, Trevor Darrell, and Zeynep Akata, “Generalized zero-and few-shot learning via aligned variational autoencoders,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8247–8255
2019
-
[6]
Zerodiff: Solidified visual-semantic correlation in zero-shot learning,
Zihan Ye, Shreyank N Gowda, Shiming Chen, et al., “Zerodiff: Solidified visual-semantic correlation in zero-shot learning,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
Devise: A deep visual-semantic embedding model,
Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, et al., “Devise: A deep visual-semantic embedding model,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[8]
An embarrassingly simple approach to zero-shot learning,
Bernardino Romera-Paredes and Philip Torr, “An embarrassingly simple approach to zero-shot learning,” inInternational conference on machine learning. PMLR, 2015, pp. 2152–2161
2015
-
[9]
Goal-oriented gaze estimation for zero-shot learning,
Yang Liu, Lei Zhou, Xiao Bai, Yifei Huang, Lin Gu, Jun Zhou, and Tatsuya Harada, “Goal-oriented gaze estimation for zero-shot learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3794–3803
2021
-
[10]
In- complete data classification via distribution alignment with evidence combination,
Linqing Huang, Jinfu Fan, Shilin Wang, Gongshen Liu, et al., “In- complete data classification via distribution alignment with evidence combination,”Machine Intelligence Research, pp. 1–23, 2026
2026
-
[11]
Solving the partial label learning problem: An instance-based approach.,
Min-Ling Zhang and Fei Yu, “Solving the partial label learning problem: An instance-based approach.,” inIJCAI, 2015, pp. 4048–4054
2015
-
[12]
Kmt-pll: K-means cross-attention transformer for partial label learning,
Jinfu Fan, Linqing Huang, Chaoyu Gong, et al., “Kmt-pll: K-means cross-attention transformer for partial label learning,”IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[13]
Attribute propagation network for graph zero-shot learning,
Lu Liu, Tianyi Zhou, Guodong Long, et al., “Attribute propagation network for graph zero-shot learning,” inProceedings of the AAAI conference on artificial intelligence, 2020, vol. 34, pp. 4868–4875
2020
-
[14]
Transzero: Attribute- guided transformer for zero-shot learning,
Shiming Chen, Ziming Hong, Yang Liu, et al., “Transzero: Attribute- guided transformer for zero-shot learning,” inProceedings of the AAAI conference on artificial intelligence, 2022, vol. 36, pp. 330–338
2022
-
[15]
Partial label learning via gaussian processes,
Yu Zhou, Jianjun He, and Hong Gu, “Partial label learning via gaussian processes,”IEEE transactions on cybernetics, vol. 47, no. 12, pp. 4443– 4450, 2016
2016
-
[16]
Pico+: Contrastive label disambiguation for robust partial label learning,
Haobo Wang, Ruixuan Xiao, Yixuan Li, Lei Feng, Gang Niu, Gang Chen, and Junbo Zhao, “Pico+: Contrastive label disambiguation for robust partial label learning,”arXiv preprint arXiv:2201.08984, 2022
-
[17]
Large margin partial label machine,
Jing Chai, Ivor W Tsang, and Weijie Chen, “Large margin partial label machine,”IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 7, pp. 2594–2608, 2019
2019
-
[18]
Leveraged weighted loss for partial label learning,
Hongwei Wen, Jingyi Cui, Hanyuan Hang, Jiabin Liu, et al., “Leveraged weighted loss for partial label learning,” inInternational conference on machine learning. PMLR, 2021, pp. 11091–11100
2021
-
[19]
Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeswar, Sherjil Ozair, et al., “Mine: mutual information neural estimation,”arXiv preprint arXiv:1801.04062, 2018
-
[20]
Learning deep representations by mutual information estimation and maximization
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, et al., “Learning deep representations by mutual information estimation and maximization,”arXiv preprint arXiv:1808.06670, 2018
work page Pith review arXiv 2018
-
[21]
Graphdpi: Partial label disambiguation by graph representation learning via mutual information maximization,
Jinfu Fan, Yang Yu, Linqing Huang, et al., “Graphdpi: Partial label disambiguation by graph representation learning via mutual information maximization,”Pattern Recognition, vol. 134, pp. 109133, 2023
2023
-
[22]
On variational bounds of mutual information,
Ben Poole, Sherjil Ozair, Aaron Van Den Oord, Alex Alemi, and George Tucker, “On variational bounds of mutual information,” inInternational conference on machine learning. PMLR, 2019, pp. 5171–5180
2019
-
[23]
Msdn: Mutually semantic distillation network for zero-shot learning,
Shiming Chen, Ziming Hong, Guo-Sen Xie, Wenhan Yang, et al., “Msdn: Mutually semantic distillation network for zero-shot learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 7612–7621
2022
-
[24]
Boosting zero-shot learning via contrastive optimization of attribute representations,
Yu Du, Miaojing Shi, Fangyun Wei, and Guoqi Li, “Boosting zero-shot learning via contrastive optimization of attribute representations,”IEEE Transactions on Neural Networks and Learning Systems, 2023
2023
-
[25]
Causal visual-semantic correlation for zero-shot learning,
Shuhuang Chen, Dingjie Fu, Shiming Chen, Shuo Ye, Wenjin Hou, and Xinge You, “Causal visual-semantic correlation for zero-shot learning,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4246–4255
2024
-
[26]
Hsva: Hierarchical semantic-visual adaptation for zero-shot learning,
Shiming Chen, Guosen Xie, Yang Liu, et al., “Hsva: Hierarchical semantic-visual adaptation for zero-shot learning,”Advances in Neural Information Processing Systems, vol. 34, pp. 16622–16634, 2021
2021
-
[27]
Contrastive embedding for generalized zero-shot learning,
Zongyan Han, Zhenyong Fu, Shuo Chen, and Jian Yang, “Contrastive embedding for generalized zero-shot learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 2371–2381
2021
-
[28]
En-compactness: Self- distillation embedding & contrastive generation for generalized zero- shot learning,
Xia Kong, Zuodong Gao, Xiaofan Li, et al., “En-compactness: Self- distillation embedding & contrastive generation for generalized zero- shot learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 9306–9315
2022
-
[29]
Leveraging balanced semantic embedding for generative zero-shot learning,
Guo-Sen Xie, Xu-Yao Zhang, Tian-Zhu Xiang, Fang Zhao, et al., “Leveraging balanced semantic embedding for generative zero-shot learning,”IEEE Transactions on Neural Networks and Learning Sys- tems, vol. 34, no. 11, pp. 9575–9582, 2022
2022
-
[30]
Zero-shot learning with attentive region embedding and enhanced semantics,
Yang Liu, Yuhao Dang, Xinbo Gao, Jungong Han, and Ling Shao, “Zero-shot learning with attentive region embedding and enhanced semantics,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 3, pp. 4220–4231, 2022
2022
-
[31]
Dual-uncertainty guided cycle-consistent network for zero-shot learning,
Yilei Zhang, Yi Tian, Sihui Zhang, and Yaping Huang, “Dual-uncertainty guided cycle-consistent network for zero-shot learning,”IEEE Transac- tions on Circuits and Systems for Video Technology, vol. 33, no. 11, pp. 6872–6886, 2023
2023
-
[32]
Data distribution distilled generative model for generalized zero-shot recogni- tion,
Yijie Wang, Mingjian Hong, Luwen Huangfu, and Sheng Huang, “Data distribution distilled generative model for generalized zero-shot recogni- tion,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024, vol. 38, pp. 5695–5703
2024
-
[33]
Visual feature disentanglement for zero-shot learning,
Qingzhi He, Rong Quan, Weifeng Yang, and Jie Qin, “Visual feature disentanglement for zero-shot learning,” in2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6
2024
-
[34]
Attribute prototype network for zero-shot learning,
Wenjia Xu, Yongqin Xian, Jiuniu Wang, et al., “Attribute prototype network for zero-shot learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 21969–21980, 2020
2020
-
[35]
Re- think, revisit, revise: A spiral reinforced self-revised network for zero- shot learning,
Zhe Liu, Yun Li, Lina Yao, Julian McAuley, and Sam Dixon, “Re- think, revisit, revise: A spiral reinforced self-revised network for zero- shot learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 1, pp. 657–669, 2022
2022
-
[36]
Diversity-boosted generalization-specialization balancing for zero-shot learning,
Yun Li, Zhe Liu, Xiaojun Chang, et al., “Diversity-boosted generalization-specialization balancing for zero-shot learning,”IEEE Transactions on Multimedia, vol. 25, pp. 8372–8382, 2023
2023
-
[37]
Zs-vat: Learning unbiased attribute knowledge for zero-shot recognition through visual attribute transformer,
Zongyan Han, Zhenyong Fu, Shuo Chen, et al., “Zs-vat: Learning unbiased attribute knowledge for zero-shot recognition through visual attribute transformer,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 4, pp. 7025–7036, 2024
2024
-
[38]
Caltech-ucsd birds 200,
Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, et al., “Caltech-ucsd birds 200,” 2010
2010
-
[39]
The sun attribute database: Beyond categories for deeper scene understanding,
Genevieve Patterson, Chen Xu, Hang Su, and James Hays, “The sun attribute database: Beyond categories for deeper scene understanding,” International Journal of Computer Vision, vol. 108, pp. 59–81, 2014
2014
-
[40]
Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly,
Yongqin Xian, Christoph H Lampert, Bernt Schiele, and Zeynep Akata, “Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 9, pp. 2251–2265, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.