Recognition: unknown
Democratizing Tool Learning with Environments Fully Simulated by a Free 8B Language Model
Pith reviewed 2026-05-10 04:49 UTC · model grok-4.3
The pith
An 8B open-source language model can fully simulate dynamic environments for training tool-calling agents via reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
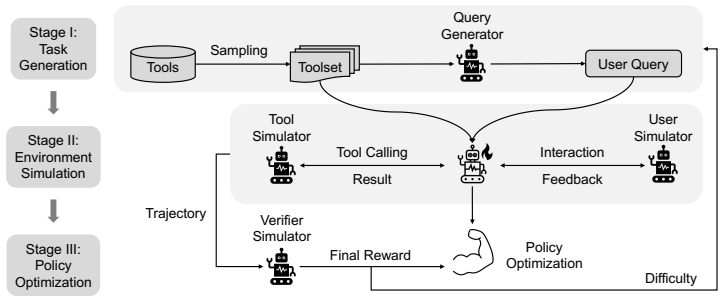
TRUSTEE shows that environments fully simulated by an 8B language model, covering task creation, user and tool simulation, and evaluation, paired with an adaptive curriculum learning mechanism, can train tool-calling agents that outperform baselines requiring extra external resources in most cases.
What carries the argument
TRUSTEE, the framework that directs an 8B language model to generate tasks, simulate users and tools, evaluate agent trajectories, and apply curriculum adjustments during reinforcement learning.
If this is right
- Tool-calling agents can be trained without paid APIs or ground-truth annotations.
- Small local models suffice as the sole source of interactive training environments for reinforcement learning.
- Adaptive curriculum learning can progressively increase task difficulty using only signals from the simulator.
- The resulting agents establish competitive baselines for tool learning under strict resource limits.
Where Pith is reading between the lines
- The same simulation pattern could apply to training agents in other interactive domains such as web browsing or code execution without external costs.
- Modest increases in simulator model size might yield further gains while still avoiding frontier-model dependence.
- Longer training runs or repeated environment resets could reveal whether simulation drift eventually limits agent performance.
Load-bearing premise
An 8B language model can produce sufficiently realistic, dynamic, and consistent simulations of tasks, user interactions, tool behaviors, and trajectory evaluations to support effective reinforcement learning of tool-calling agents.
What would settle it
Train agents inside the 8B-simulated environments and then measure their performance on real tool-use benchmarks; if the agents show no improvement over random behavior or over agents trained with human data and larger models, the simulation approach fails.
Figures







read the original abstract
Reinforcement learning (RL) has become a prevalent paradigm for training tool calling agents, which typically requires online interactive environments. Existing approaches either rely on training data with ground truth annotations or require advanced proprietary language models (LMs) to synthesize environments that keep fixed once created. In this work, we propose TRUSTEE, a cost-friendly method for training tool calling agents with dynamic environments fully simulated by free open-source LMs that can be as small as 8B, including task generation, user simulation, tool simulation and trajectory evaluation, paired with an adaptive curriculum learning mechanism that controls task difficulty during training. Our empirical results show that TRUSTEE outperforms baselines which require extra external resources in most cases. These confirm that, with a sufficiently sophisticated design, even simulated environments with a local 8B LM as the backbone could set a strong baseline for tool learning. We hope our proposed paradigm could democratize tool learning and inspire future research on environment scaling with limited resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRUSTEE, a framework for training tool-calling agents via reinforcement learning in environments fully simulated by a free 8B open-source language model. The simulation pipeline covers task generation, user simulation, tool simulation, and trajectory evaluation, paired with an adaptive curriculum learning mechanism to dynamically control task difficulty. The central empirical claim is that this cost-friendly setup outperforms baselines relying on extra external resources in most cases, demonstrating that sophisticated design enables strong tool-learning baselines even with limited local compute.
Significance. If the results hold, this work is significant for lowering barriers to tool-learning research by eliminating dependence on proprietary models or large-scale external resources. It provides a concrete, reproducible paradigm using only an open-source 8B LM for the entire environment, with the adaptive curriculum explicitly addressing issues of dynamism and consistency. This could serve as a strong, accessible baseline and inspire future work on environment scaling under resource constraints.
minor comments (3)
- Abstract: the claim of outperformance is stated without any quantitative metrics, baseline names, or task counts; adding at least one key result (e.g., success rate delta) would immediately strengthen the summary.
- Experimental section: ensure all baselines are described with their exact resource requirements and implementation details so readers can verify the fairness of the comparison.
- Consider adding a table that reports mean performance, standard deviation, and number of runs across tasks to allow direct assessment of statistical reliability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and for recommending minor revision. We appreciate the recognition that our framework provides a reproducible, resource-efficient approach to tool-learning research using only an open-source 8B LM.
Circularity Check
No significant circularity detected
full rationale
The paper introduces TRUSTEE, an empirical system that uses a free 8B open-source LM to fully simulate dynamic environments (task generation, user simulation, tool simulation, trajectory evaluation) for RL-based training of tool-calling agents, augmented by adaptive curriculum learning. All load-bearing claims rest on reported empirical outperformance versus external baselines that require proprietary models or annotated data. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation; the simulation quality assumption is tested directly through the training outcomes rather than assumed by construction. The method is therefore self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An 8B language model can produce sufficiently high-quality simulations of tasks, users, tools, and trajectory evaluations for effective RL training of tool-calling agents
Reference graph
Works this paper leans on
-
[1]
ToolQA: A dataset for LLM question answering with external tools
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. ToolQA: A dataset for LLM question answering with external tools. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[2]
Gonzalez
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[3]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[4]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[5]
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.arXiv preprint arXiv:2306.05301, 2023
-
[6]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InThe Twelfth International Conference on Learning...
2024
-
[7]
ToolRL: Reward is all tool learning needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru WANG, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[8]
Nemotron-research-tool-n1: Exploring tool-using language models with reinforced reasoning
Shaokun Zhang, Yi Dong, Jieyu Zhang, Jan Kautz, Bryan Catanzaro, Andrew Tao, Qingyun Wu, Zhiding Yu, and Guilin Liu. Nemotron-research-tool-n1: Exploring tool-using language models with reinforced reasoning.arXiv preprint arXiv:2505.00024, 2025
-
[9]
Tool zero: Training tool-augmented LLMs via pure RL from scratch
Yirong Zeng, Xiao Ding, Yutai Hou, Yuxian Wang, Li Du, Juyi Dai, Qiuyang Ding, Duyu Tang, Dandan Tu, Weiwen Liu, Bing Qin, and Ting Liu. Tool zero: Training tool-augmented LLMs via pure RL from scratch. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[10]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025. 10
2025
-
[11]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
StableToolBench: Towards stable large-scale benchmarking on tool learning of large language models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. StableToolBench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the Association for Computational Linguistics: ACL 2024, 2024
2024
-
[13]
Towards general agentic intelligence via environment scaling
Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xiaobin Wang, Liangcai Su, Zhen Zhang, Shibin Wu, Zhengwei Tao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Towards general agentic intelligence via environment scaling. arXiv preprint arXiv:2509.13311, 2025
-
[14]
Facilitating multi-turn function calling for LLMs via compositional instruction tuning
Mingyang Chen, sunhaoze, Tianpeng Li, Fan Yang, Hao Liang, KeerLu, Bin CUI, Wentao Zhang, Zenan Zhou, and weipeng chen. Facilitating multi-turn function calling for LLMs via compositional instruction tuning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
ToolACE: Winning the points of LLM function calling
Weiwen Liu, Xu Huang, Xingshan Zeng, xinlong hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong W ANG, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Wang Xinzhi, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, and Enhong Chen. ToolACE: Winning the points of ...
2025
-
[16]
Procedural environment generation for tool-use agents
Michael Sullivan, Mareike Hartmann, and Alexander Koller. Procedural environment generation for tool-use agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[17]
Tommaso Castellani, Naimeng Ye, Daksh Mittal, Thomson Yen, and Hongseok Namkoong. Synthtools: A framework for scaling synthetic tools for agent development.arXiv preprint arXiv:2511.09572, 2025
-
[18]
From word to world: Can large language models be implicit text-based world models? InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026
Yixia Li, Hongru W ANG, Jiahao Qiu, Zhenfei Yin, Dongdong Zhang, Cheng Qian, Zeping Li, Xiaoteng Ma, Guanhua Chen, Heng Ji, and Mengdi Wang. From word to world: Can large language models be implicit text-based world models? InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026
2026
-
[19]
Cheng Qian, Zuxin Liu, Akshara Prabhakar, Jielin Qiu, Zhiwei Liu, Haolin Chen, Shirley Kokane, Heng Ji, Weiran Yao, Shelby Heinecke, Silvio Savarese, Caiming Xiong, and Huan Wang. Userrl: Training interactive user-centric agent via reinforcement learning.arXiv preprint arXiv:2509.19736, 2025
-
[20]
Simulating environments with reasoning models for agent training.arXiv preprint arXiv:2511.01824,
Yuetai Li, Huseyin A Inan, Xiang Yue, Wei-Ning Chen, Lukas Wutschitz, Janardhan Kulka- rni, Radha Poovendran, Robert Sim, and Saravan Rajmohan. Simulating environments with reasoning models for agent training.arXiv preprint arXiv:2511.01824, 2025
-
[21]
τ-bench: A bench- mark for tool-agent-user interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. τ-bench: A bench- mark for tool-agent-user interaction in real-world domains. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[22]
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis
Xiaoshuai Song, Haofei Chang, Guanting Dong, Yutao Zhu, Zhicheng Dou, and Ji-Rong Wen. Envscaler: Scaling tool-interactive environments for llm agent via programmatic synthesis. arXiv preprint arXiv:2601.05808, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Zhaoyang Wang, Canwen Xu, Boyi Liu, Yite Wang, Siwei Han, Zhewei Yao, Huaxiu Yao, and Yuxiong He. Agent world model: Infinity synthetic environments for agentic reinforcement learning.arXiv preprint arXiv:2602.10090, 2026. 11
-
[24]
The landscape of agentic reinforcement learning for LLMs: A survey.Transactions on Machine Learning Research,
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhong-Zhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Francisco Piedrahita Velez, Yue Liao, Hongru Wang, Mengyue Yang, Heng Ji, Jun Wang, Shuicheng Yan, Philip Torr, and Lei Bai. The landscape of agentic reinfo...
-
[25]
Survey Certification
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InF orty-second International Conference on Machine Learning, 2025
2025
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
xLAM: A family of large action models to empower AI agent systems
Jianguo Zhang, Tian Lan, Ming Zhu, Zuxin Liu, Thai Hoang, Shirley Kokane, Weiran Yao, Juntao Tan, Zhiwei Liu, Yihao Feng, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Silvio Savarese, and Caiming Xiong. xLAM: A family of large action models to empower AI agent systems. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the ...
2025
-
[31]
Robust function-calling for on-device language model via function masking
Qiqiang Lin, Muning Wen, Qiuying Peng, Guanyu Nie, Junwei Liao, Jun Wang, Xiaoyun Mo, Jiamu Zhou, Cheng Cheng, Yin Zhao, Jun Wang, and Weinan Zhang. Robust function-calling for on-device language model via function masking. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, 2025
2025
-
[33]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[34]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023
work page internal anchor Pith review arXiv 2023
-
[35]
Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang, Yong Jiang, Liangcai Su, Liwen Zhang, Wenbiao Yin, Zhen Zhang, Fuli Feng, Pengjun Xie, and Xiaobin Wang. Aut- oforge: Automated environment synthesis for agentic reinforcement learning.arXiv preprint arXiv:2512.22857, 2025
-
[36]
Zerosearch: Incentivize the search capability of llms without searching, 2025
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588, 2025. 12
-
[37]
Zhenzhen Ren, Xinpeng Zhang, Zhenxing Qian, Yan Gao, Yu Shi, Shuxin Zheng, and Jiyan He. Gtm: Simulating the world of tools for ai agents.arXiv preprint arXiv:2512.04535, 2025
-
[38]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Expected turns: The task as a whole should match expected turns: {number of turns} Design the goal and first message so the conversation length fits this
-
[40]
Length approximately {number of expected calls}
expected tool calls: A list of tool names (from the available tools above) that the agent is expected to use, in a plausible order. Length approximately {number of expected calls}
-
[41]
This may be richer or more specific than what the user says in the first message
user intent: A clear description of what the user ultimately wants to achieve (the ground truth goal for evaluation). This may be richer or more specific than what the user says in the first message
-
[42]
Do NOT tie this to query clarity
user persona: A short description of the user’s expertise level, matching: {persona}. Do NOT tie this to query clarity
-
[43]
I’m trying to figure out
first user query: The user’s first message only—how a real user would actually open the conversation. Keep it natural: - It need not state the full intent directly; the user might hint, ask a partial question, or express a vague need that the agent must clarify. - Match the query ambiguity level: {ambiguity} - Do not name tools; the message should lead na...
-
[44]
Tool Result: The simulated execution output (or an error message if the call is invalid)
-
[45]
Error: Tool call must be properly formatted in the expected structure
Tool Reward: An integer reward in {-1, 0, 1} evaluating how well this tool call serves the user’s intent ## Tool Result Guidelines ### Validation First, validate the tool call: - Parseable: Is the tool call properly formatted and parseable? If the tool call is null or malformed, return an error like "Error: Tool call must be properly formatted in the expe...
2024
-
[46]
Think: Recall relevant context and analyze the current user goal
-
[47]
Decide on Tool Usage: If a tool is needed, specify the tool and its parameters
-
[48]
Respond Appropriately: If a response is needed, generate one while maintaining consistency across user queries. # Output Format If you need to call tools, use the following format: <think> Your thoughts and reasoning </think> <tool_call> Tool call JSON object(s) </tool_call> If you need to respond to the user, use the following format: <think> Your though...
-
[51]
Figure 6: Detailed system prompt
Refer to the previous dialogue records in the history, including the user’s queries, previous tool calls, tool feedback, and your responses. Figure 6: Detailed system prompt. 19 Concise System Prompt You are a helpful multi-turn dialogue assistant capable of leveraging tool calls to solve user tasks. # Important Notes
-
[52]
Provide either calling tools or responding to the user
You must always include the <think> field to outline your reasoning. Provide either calling tools or responding to the user. The former leads to an interaction with the tool environment, while the latter switches back to the user interface
-
[53]
You will get the tool feedback after calling the tools
You may invoke multiple tool calls simultaneously in the <tool_call> field. You will get the tool feedback after calling the tools. You may call tools for multiple turns if needed
-
[54]
Figure 7: Concise system prompt
Refer to the previous dialogue records in the history, including the user’s queries, previous tool calls, tool feedback, and your responses. Figure 7: Concise system prompt. Prompt Template for Verifier Simulation You are a tool quality evaluator. Determine if this tool should be kept based on: ## Evaluation Criteria
-
[55]
Tool Name: Must be meaningful (not generic like "api", "hello", "test") 2. Description: Must be informative (not just repeating the name or single letters) 3. Parameters: Must have reasonable descriptions (not just "Parameter: {name}") 4. Overall Quality: Tool should be useful and clear ## Tool to Evaluate {tool} ## Response Format Respond ONLY with "KEEP...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.