Recognition: unknown
HiP-LoRA: Budgeted Spectral Plasticity for Robust Low-Rank Adaptation
Pith reviewed 2026-05-10 04:40 UTC · model grok-4.3
The pith
HiP-LoRA splits low-rank updates via cached SVD into a stability-budgeted principal channel and an unrestricted residual channel to limit interference with pretrained weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HiP-LoRA is a spectrum-aware adaptation framework that utilizes the cached singular value decomposition of pretrained layers to decompose updates into a principal channel within the dominant singular subspace and a residual low-rank channel in the orthogonal complement. A singular-value-weighted stability budget on the principal channel continuously balances pretrained behavior preservation with task-specific plasticity.
What carries the argument
Dual-channel decomposition of low-rank updates using cached SVD, with a singular-value-weighted stability budget applied only to the principal channel inside the dominant singular subspace.
If this is right
- Under identical parameter budgets, HiP-LoRA produces smaller shifts away from pretrained singular directions than standard LoRA.
- Multi-adapter merging failures decrease because updates avoid the same leading directions across adapters.
- Performance improves on continual tuning sequences and knowledge editing tasks that are sensitive to interference.
- The residual channel remains fully available for task plasticity while the principal channel is throttled by the singular-value-weighted budget.
Where Pith is reading between the lines
- The same SVD-based separation could be applied to other low-rank or modular adaptation methods that currently ignore spectral structure.
- If the budget can be set automatically from the singular-value spectrum, the method might remove the need for manual hyper-parameter search in sequential adaptation pipelines.
- The orthogonal residual channel might allow higher effective rank for task learning without increasing total parameter count.
Load-bearing premise
The cached SVD gives a stable separation between the dominant singular subspace and its orthogonal complement, and the chosen stability budget can protect general capabilities without blocking needed task plasticity.
What would settle it
If applying HiP-LoRA under its stated budget causes the leading singular directions of the adapted weights to shift as much as standard LoRA does when both are measured on a held-out general-capability benchmark, the separation-and-budget mechanism has not worked.
Figures





read the original abstract
Adapting foundation models under resource budgets relies heavily on Parameter-Efficient Fine-Tuning (PEFT), with LoRA being a standard modular solution. However, LoRA suffers from spectral interference. Low-rank updates often concentrate energy on the leading singular directions of pretrained weights, perturbing general capabilities and causing catastrophic forgetting and fragile multi-adapter merging. To resolve this, we propose HiP-LoRA, a spectrum-aware adaptation framework. Utilizing the cached singular value decomposition (SVD) of pretrained layers, HiP-LoRA decomposes updates into two channels: a principal channel within the dominant singular subspace, and a residual low-rank channel in the orthogonal complement. A singular-value-weighted stability budget on the principal channel continuously balances pretrained behavior preservation with task-specific plasticity. Experiments on Llama-3.1-8B demonstrate that under matched budgets, HiP-LoRA drastically reduces pretraining degradation and multi-adapter MergeFail, robustly outperforming baselines in interference-sensitive tasks like continual tuning and knowledge editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HiP-LoRA, a spectrum-aware extension of LoRA for parameter-efficient fine-tuning of foundation models. It caches the SVD of each pretrained weight matrix W0 = U Σ V^T and decomposes low-rank updates into a principal channel projected onto the dominant singular subspace and a residual channel in the orthogonal complement. A singular-value-weighted stability budget constrains the principal-channel magnitude to preserve general capabilities while allowing task plasticity. Experiments on Llama-3.1-8B are claimed to show reduced pretraining degradation and lower MergeFail rates versus baselines under matched budgets, with gains in continual tuning and knowledge editing.
Significance. If the empirical claims hold and the fixed-SVD separation remains valid, HiP-LoRA would offer a practical way to mitigate spectral interference in LoRA, improving robustness for multi-adapter and continual-learning settings without increasing parameter count. This addresses a recognized weakness in current PEFT methods and could influence subsequent work on budgeted or subspace-aware adaptation.
major comments (3)
- [Method (decomposition and budget definition)] The central mechanism relies on the cached SVD of W0 providing a stable partition between general (principal) and task-specific (residual) directions throughout optimization. Low-rank updates can rotate the singular vectors of the adapted matrix, so the fixed U and V matrices may no longer align with the current weight; the stability budget would then either over-constrain useful plasticity or fail to protect pretrained directions. This assumption is load-bearing for all claims of reduced degradation and MergeFail, yet the manuscript provides neither a theoretical bound on subspace drift nor an ablation measuring how much the singular vectors actually rotate under the proposed updates.
- [Method and Experiments] The stability budget is introduced as a free hyperparameter (singular-value-weighted) rather than being derived from the data or reduced to a parameter-free quantity. Experiments must therefore demonstrate that performance is robust across reasonable choices of this budget and that the reported gains are not an artifact of favorable tuning on the specific tasks.
- [Experiments] The abstract asserts “drastic” outperformance on Llama-3.1-8B in interference-sensitive tasks, but the provided text supplies no quantitative tables, exact baseline configurations, or controls for total parameter budget. Full results (including pretraining-perplexity deltas, MergeFail rates, and statistical significance) are required to substantiate the central claim.
minor comments (2)
- [Method] Notation for the principal and residual channels should be introduced with explicit matrix expressions (e.g., the projection onto the top-k right singular vectors) rather than descriptive prose only.
- [Method] Clarify whether the SVD is computed once per layer at initialization or recomputed periodically; the current wording leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while noting where revisions are needed to improve clarity and completeness.
read point-by-point responses
-
Referee: [Method (decomposition and budget definition)] The central mechanism relies on the cached SVD of W0 providing a stable partition between general (principal) and task-specific (residual) directions throughout optimization. Low-rank updates can rotate the singular vectors of the adapted matrix, so the fixed U and V matrices may no longer align with the current weight; the stability budget would then either over-constrain useful plasticity or fail to protect pretrained directions. This assumption is load-bearing for all claims of reduced degradation and MergeFail, yet the manuscript provides neither a theoretical bound on subspace drift nor an ablation measuring how much the singular vectors actually rotate under the proposed updates.
Authors: We agree the fixed SVD partition is a central modeling choice and that low-rank updates can induce some rotation of the singular vectors. The manuscript does not derive a theoretical bound on subspace drift, as obtaining a tight, non-vacuous bound for this setting appears non-trivial. However, we will add a new empirical ablation that tracks the principal angles between the original and adapted singular subspaces (for both HiP-LoRA and standard LoRA) across training steps on the Llama-3.1-8B experiments. This will quantify the actual drift observed under the proposed updates and support the practical validity of the cached decomposition. revision: partial
-
Referee: [Method and Experiments] The stability budget is introduced as a free hyperparameter (singular-value-weighted) rather than being derived from the data or reduced to a parameter-free quantity. Experiments must therefore demonstrate that performance is robust across reasonable choices of this budget and that the reported gains are not an artifact of favorable tuning on the specific tasks.
Authors: The singular-value-weighted budget is indeed a hyperparameter that trades off preservation versus plasticity. In the revised manuscript we will add a sensitivity plot and table showing performance on the continual-tuning and knowledge-editing benchmarks for a range of budget values (e.g., 0.2, 0.5, 0.8, 1.0). These results will confirm that the reported gains relative to baselines remain consistent across the tested range and are not an artifact of a single favorable setting. revision: yes
-
Referee: [Experiments] The abstract asserts “drastic” outperformance on Llama-3.1-8B in interference-sensitive tasks, but the provided text supplies no quantitative tables, exact baseline configurations, or controls for total parameter budget. Full results (including pretraining-perplexity deltas, MergeFail rates, and statistical significance) are required to substantiate the central claim.
Authors: The full manuscript contains the requested quantitative tables (pretraining-perplexity deltas, MergeFail rates, and matched-budget comparisons). We will revise the submission to ensure all tables appear in the main body with explicit baseline configurations (LoRA rank, scaling factor, optimizer settings) and report means plus standard deviations over three random seeds to establish statistical significance. revision: yes
- A theoretical bound on subspace drift under the low-rank updates.
Circularity Check
No circularity: method introduces cached-SVD decomposition and budget parameter without reducing claims to inputs by construction
full rationale
The paper presents HiP-LoRA as a new PEFT framework that caches the SVD of pretrained weights W0 once, routes low-rank updates into a principal channel (within the dominant singular subspace) and a residual channel (orthogonal complement), and applies a singular-value-weighted stability budget to the principal channel. No equations, derivations, or self-citations are shown that define the output in terms of the input or rename a fitted quantity as a prediction. The central claims about reduced degradation and MergeFail rest on experimental comparisons under matched budgets rather than on any self-referential reduction. The cached-SVD assumption and budget choice are design decisions whose validity is tested externally, not presupposed by the method's own definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- stability budget
axioms (1)
- domain assumption Cached SVD of pretrained weights accurately identifies dominant singular directions for update routing.
invented entities (2)
-
principal channel
no independent evidence
-
residual low-rank channel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
[Aghajanyanet al., 2021 ] Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InPro- ceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pag...
2021
-
[2]
K., Hayase, J., and Srinivasa, S
[Ainsworthet al., 2022 ] Samuel K Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permutation symmetries.arXiv preprint arXiv:2209.04836,
-
[3]
Lensnet: An end-to-end learning framework for empirical point spread function modeling and lensless imaging reconstruc- tion
[Baiet al., 2025 ] Jiesong Bai, Yuhao Yin, Yihang Dong, Xi- aofeng Zhang, Chi-Man Pun, and Xuhang Chen. Lensnet: An end-to-end learning framework for empirical point spread function modeling and lensless imaging reconstruc- tion. InIJCAI, pages 684–692,
2025
-
[4]
Revisiting model stitching to compare neural representations.Advances in neural information process- ing systems, 34:225–236,
[Bansalet al., 2021 ] Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting model stitching to compare neural representations.Advances in neural information process- ing systems, 34:225–236,
2021
-
[5]
Code alpaca: An instruction-following llama model for code generation,
[Chaudhary, 2023] Sahil Chaudhary. Code alpaca: An instruction-following llama model for code generation,
2023
-
[6]
Evaluating Large Language Models Trained on Code
[Chen, 2021] Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Training Verifiers to Solve Math Word Problems
[Cobbeet al., 2021 ] Karl Cobbe, Vineet Kosaraju, Moham- mad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Qlora: Efficient fine- tuning of quantized llms.Advances in neural information processing systems, 36:10088–10115,
[Dettmerset al., 2023 ] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient fine- tuning of quantized llms.Advances in neural information processing systems, 36:10088–10115,
2023
-
[9]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135,
[French, 1999] Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135,
1999
-
[10]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
[Hanet al., 2024 ] Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine- tuning for large models: A comprehensive survey.arXiv preprint arXiv:2403.14608,
work page internal anchor Pith review arXiv 2024
-
[11]
Measuring Massive Multitask Language Understanding
[Hendryckset al., 2020 ] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask lan- guage understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review arXiv 2020
-
[12]
Parameter-efficient transfer learning for nlp
[Houlsbyet al., 2019 ] Neil Houlsby, Andrei Giurgiu, Stanis- law Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInterna- tional conference on machine learning, pages 2790–2799. PMLR,
2019
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
[Huet al., 2022 ] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
2022
-
[14]
Editing Models with Task Arithmetic
[Ilharcoet al., 2022 ] Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review arXiv 2022
-
[15]
Overcom- ing catastrophic forgetting in neural networks.Proceed- ings of the national academy of sciences, 114(13):3521– 3526,
[Kirkpatricket al., 2017 ] James Kirkpatrick, Razvan Pas- canu, Neil Rabinowitz, Joel Veness, Guillaume Des- jardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcom- ing catastrophic forgetting in neural networks.Proceed- ings of the national academy of sciences, 114(13):3521– 3526,
2017
-
[16]
What learning systems do intelligent agents need? complementary learning systems theory updated.Trends in cognitive sciences, 20(7):512– 534,
[Kumaranet al., 2016 ] Dharshan Kumaran, Demis Hass- abis, and James L McClelland. What learning systems do intelligent agents need? complementary learning systems theory updated.Trends in cognitive sciences, 20(7):512– 534,
2016
-
[17]
Fs-rwkv: Leveraging fre- quency spatial-aware rwkv for 3t-to-7t mri translation
[Leiet al., 2025 ] Yingtie Lei, Zimeng Li, Chi-Man Pun, Yu- peng Liu, and Xuhang Chen. Fs-rwkv: Leveraging fre- quency spatial-aware rwkv for 3t-to-7t mri translation. In BIBM, pages 1–6,
2025
-
[18]
The Power of Scale for Parameter-Efficient Prompt Tuning
[Lesteret al., 2021 ] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691,
work page internal anchor Pith review arXiv 2021
-
[19]
[Linet al., 2024 ] Zheng Lin, Xuanjie Hu, Yuxin Zhang, Zhe Chen, Zihan Fang, Xianhao Chen, Ang Li, Praneeth Vepakomma, and Yue Gao. Splitlora: A split parameter- efficient fine-tuning framework for large language models. arXiv preprint arXiv:2407.00952,
-
[20]
Dora: Weight- decomposed low-rank adaptation
[Liuet al., 2024 ] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang- Ting Cheng, and Min-Hung Chen. Dora: Weight- decomposed low-rank adaptation. InForty-first Interna- tional Conference on Machine Learning,
2024
-
[21]
Gradient episodic memory for continual learning.Advances in neural information processing systems, 30,
[Lopez-Paz and Ranzato, 2017] David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30,
2017
-
[22]
Learn to ex- plain: Multimodal reasoning via thought chains for sci- ence question answering.Advances in Neural Information Processing Systems, 35:2507–2521,
[Luet al., 2022 ] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to ex- plain: Multimodal reasoning via thought chains for sci- ence question answering.Advances in Neural Information Processing Systems, 35:2507–2521,
2022
-
[23]
Riemannian liquid spatio- temporal graph network
[Luet al., 2026 ] Liangsi Lu, Jingchao Wang, Zhaorong Dai, Hanqian Liu, and Yang Shi. Riemannian liquid spatio- temporal graph network. InProceedings of the ACM Web Conference 2026, WWW ’26, page 463–474, New York, NY , USA,
2026
-
[24]
[McClellandet al., 1995 ] James L McClelland, Bruce L Mc- Naughton, and Randall C O’Reilly
Association for Computing Machinery. [McClellandet al., 1995 ] James L McClelland, Bruce L Mc- Naughton, and Randall C O’Reilly. Why there are comple- mentary learning systems in the hippocampus and neocor- tex: insights from the successes and failures of connection- ist models of learning and memory.Psychological review, 102(3):419,
1995
-
[25]
Pissa: Principal singular values and singu- lar vectors adaptation of large language models.Advances in Neural Information Processing Systems, 37:121038– 121072,
[Menget al., 2024 ] Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singu- lar vectors adaptation of large language models.Advances in Neural Information Processing Systems, 37:121038– 121072,
2024
-
[26]
[Mitchellet al., 2021 ] Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale.arXiv preprint arXiv:2110.11309,
-
[27]
Adapterfusion: Non-destructive task composition for transfer learning
[Pfeifferet al., 2021 ] Jonas Pfeiffer, Aishwarya Kamath, Andreas R ¨uckl´e, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. InProceedings of the 16th conference of the European chapter of the association for computa- tional linguistics: main volume, pages 487–503,
2021
-
[28]
MMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
[Shiet al., 2026 ] Yang Shi, Yifeng Xie, Minzhe Guo, Liangsi Lu, Mingxuan Huang, Jingchao Wang, Zhihong Zhu, Boyan Xu, and Zhiqi Huang. Mmerror: A bench- mark for erroneous reasoning in vision-language models. arXiv preprint arXiv:2601.03331,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Orthogonal subspace learning for lan- guage model continual learning
[Wanget al., 2023 ] Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for lan- guage model continual learning. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2023, pages 10658–10671,
2023
-
[30]
Model soups: av- eraging weights of multiple fine-tuned models improves accuracy without increasing inference time
[Wortsmanet al., 2022 ] Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo- Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: av- eraging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInter- national conference on machine l...
2022
-
[31]
Eems: Edge-prompt enhanced medical image segmenta- tion based on learnable gating mechanism
[Xiaet al., 2025 ] Han Xia, Quanjun Li, Qian Li, Zimeng Li, Hongbin Ye, Yupeng Liu, Haolun Li, and Xuhang Chen. Eems: Edge-prompt enhanced medical image segmenta- tion based on learnable gating mechanism. InBIBM, pages 3006–3011,
2025
-
[32]
Ties- merging: Resolving interference when merging mod- els.Advances in Neural Information Processing Systems, 36:7093–7115,
[Yadavet al., 2023 ] Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties- merging: Resolving interference when merging mod- els.Advances in Neural Information Processing Systems, 36:7093–7115,
2023
-
[33]
Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models
[Zakenet al., 2022 ] Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1–9,
2022
-
[34]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
[Zhanget al., 2023 ] Qingru Zhang, Minshuo Chen, Alexan- der Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adap- tive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512,
work page internal anchor Pith review arXiv 2023
-
[35]
1:For each adapted matrix, precompute and cache top-k SVD triplets(U k, Vk, σ)of the frozen backbone weight W
(9) Algorithm 1HiP-LoRA (recap). 1:For each adapted matrix, precompute and cache top-k SVD triplets(U k, Vk, σ)of the frozen backbone weight W. 2:Initializeϕ←0,A←0,B←0, and fW←W− Uk diag(σ)V ⊤ k . 3:fortraining stepsdo 4:Project factors: eB←(I−P U)B, eA←A(I−P V ). 5:Form the update ∆W=U k diag(ϕ)V ⊤ k +s eB eA, with the standard LoRA scalings=α/rapplied o...
2024
-
[36]
Reported MergeFail is the fraction of failed instances
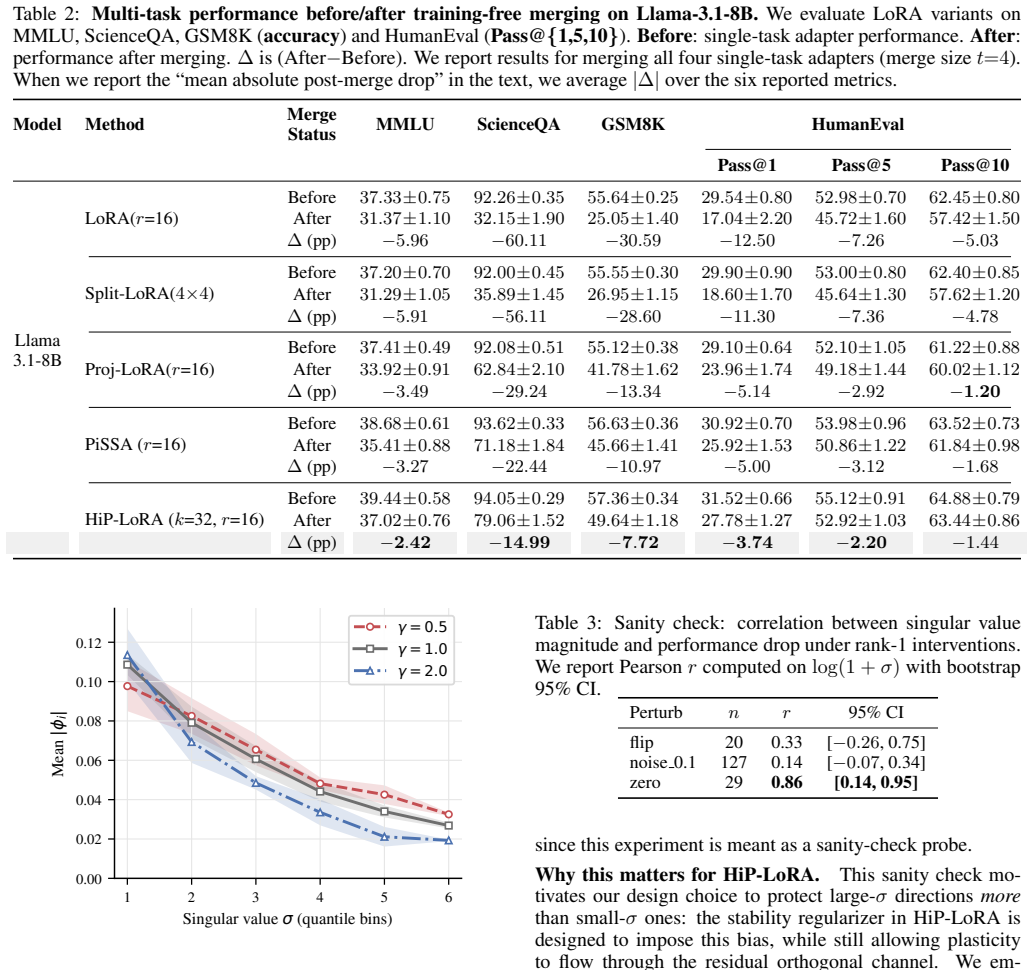
We useτ= 0.9. Reported MergeFail is the fraction of failed instances. Sampling policy and CIs.For each merge sizet, we train all single-task adapters with 3 random seeds ([42, 100, 2024]). We sampleN merge = 20merge instances per seed by (i) drawing a task subset of sizetuniformly with- out replacement from the task pool, and (ii) for each selected task, ...
2024
-
[37]
task vector
D Additional Results D.1 Supplementary diagnostics Table 6: Full correlation statistics for the spectral sanity check, including significance tests. Pearsonris computed onlog(1 +σ); Spearmanρis computed onσ. PerturbnPearsonr(p) Spearmanρ(p) flip 20 0.327 (0.159) 0.282 (0.229) noise 0.1 127 0.142 (0.111) 0.100 (0.265) zero 290.856(3.09e-9)0.412(0.026) Figu...
2024
-
[38]
What this tests.Table 13 tests whether HiP-LoRA’s merg- ing robustness is an artifact of using a weak merge rule (sim- ple addition)
1 We reuse the same merge instance sampling and paired bootstrap protocol as Appendix C.3 so comparisons remain paired. What this tests.Table 13 tests whether HiP-LoRA’s merg- ing robustness is an artifact of using a weak merge rule (sim- ple addition). If HiP-LoRA remains more robust under TIES- Merging (and ideally composes with it), it strengthens the ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.