Recognition: unknown
Raven: Rethinking Automated Assessment for Scratch Programs via Video-Grounded Evaluation
Pith reviewed 2026-05-10 04:49 UTC · model grok-4.3
The pith
Raven assesses Scratch programs by having large language models analyze videos of their executions against shared task rules instead of writing per-program tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
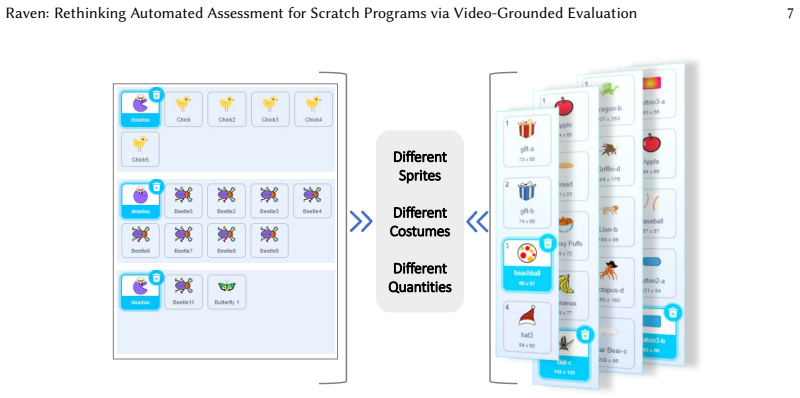
Raven replaces program-specific state assertions with instructor-specified, task-level video generation rules shared across all submissions. It integrates large language models with video analysis to evaluate whether a program's observed visual and interactive behaviors satisfy grading criteria without requiring explicit test cases or predefined outputs. This design enables consistent evaluation despite substantial diversity in implementation strategies and interaction sequences, as shown by higher accuracy and robustness on 13 real assignments with over 140 ground-truth labeled submissions plus positive results from a classroom study.
What carries the argument
Instructor-specified task-level video generation rules combined with large language model analysis of execution videos to check behavioral compliance.
Load-bearing premise
Large language models can watch videos of program runs and correctly decide whether they match the behavioral criteria without introducing systematic errors or biases across different student coding styles.
What would settle it
A collection of new Scratch submissions where Raven's grades differ from the consensus of several human graders on the same video-based criteria.
Figures









read the original abstract
Block-based programming environments such as Scratch are widely used in introductory computing education, yet scalable and reliable automated assessment remains elusive. Scratch programs are highly heterogeneous, event-driven, and visually grounded, which makes traditional assertion-based or test-based grading brittle and difficult to scale. As a result, assessment in real Scratch classrooms still relies heavily on manual inspection and delayed feedback, introducing inconsistency across instructors and limiting scalability. We present Raven, an automated assessment framework for Scratch that replaces program-specific state assertions with instructor-specified, task-level video generation rules shared across all student submissions. Raven integrates large language models with video analysis to evaluate whether a program's observed visual and interactive behaviors satisfy grading criteria, without requiring explicit test cases or predefined outputs. This design enables consistent evaluation despite substantial diversity in implementation strategies and interaction sequences. We evaluate Raven on 13 real Scratch assignments comprising over 140 student submissions with ground-truth labels from human graders. The results show that Raven significantly outperforms prior automated assessment tools in both grading accuracy and robustness across diverse programming styles. A classroom study with 30 students and 10 instructors further demonstrates strong user acceptance and practical applicability. Together, these findings highlight the effectiveness of task-level behavioral abstractions for scalable assessment of open-ended, event-driven programs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Raven, an automated assessment framework for Scratch programs that replaces program-specific assertions with instructor-specified task-level video generation rules. It integrates LLMs with video analysis to evaluate observed behaviors against grading criteria. Evaluation on 13 real assignments with over 140 student submissions (human ground-truth labels) claims significant outperformance over prior tools in accuracy and robustness across diverse styles; a classroom study with 30 students and 10 instructors reports strong user acceptance.
Significance. If the empirical results hold, the shift to task-level behavioral abstractions via video-grounded LLM analysis addresses a core limitation of brittle, code-specific testing in heterogeneous, event-driven block-based environments. This could enable more scalable and consistent automated feedback in introductory computing education. The classroom study provides practical validation beyond lab metrics.
major comments (2)
- [Evaluation] Evaluation section: the claim that Raven 'significantly outperforms prior automated assessment tools' is central but unsupported by reported metrics, baseline details, error analysis, or statistical tests (e.g., no precision/recall/F1 breakdowns, no p-values, no confusion matrices). Without these, the strength of the outperformance and robustness claims cannot be verified from the given results.
- [Raven Framework] Raven Framework / Methods: the integration of LLMs for video analysis of compliance with behavioral rules lacks concrete details on prompting strategies, decision criteria for 'satisfaction,' handling of edge cases in event-driven executions, or validation of LLM outputs against human judgments. This is load-bearing for reproducibility and for ruling out systematic biases in the weakest assumption (reliable LLM video analysis across heterogeneous implementations).
minor comments (2)
- [Abstract] Abstract: specify the exact performance metrics (e.g., accuracy, F1) and the identities of the 'prior automated assessment tools' to strengthen the summary of results.
- [Classroom Study] The classroom study description would benefit from more detail on the protocol, survey instruments, and quantitative acceptance measures to allow readers to assess the strength of the 'strong user acceptance' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential significance of task-level video-grounded evaluation for Scratch assessment. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the claim that Raven 'significantly outperforms prior automated assessment tools' is central but unsupported by reported metrics, baseline details, error analysis, or statistical tests (e.g., no precision/recall/F1 breakdowns, no p-values, no confusion matrices). Without these, the strength of the outperformance and robustness claims cannot be verified from the given results.
Authors: We agree that the evaluation would be more convincing with additional granularity. The current manuscript reports overall accuracy gains and robustness across 13 assignments with human ground-truth labels, but does not include the requested breakdowns. In the revised version we will add per-assignment and aggregate precision/recall/F1 scores, confusion matrices, explicit baseline implementations and their results, a categorized error analysis of disagreements, and statistical significance tests (e.g., McNemar’s test with p-values) to substantiate the outperformance claims. revision: yes
-
Referee: [Raven Framework] Raven Framework / Methods: the integration of LLMs for video analysis of compliance with behavioral rules lacks concrete details on prompting strategies, decision criteria for 'satisfaction,' handling of edge cases in event-driven executions, or validation of LLM outputs against human judgments. This is load-bearing for reproducibility and for ruling out systematic biases in the weakest assumption (reliable LLM video analysis across heterogeneous implementations).
Authors: We concur that these details are essential for reproducibility. The revised Methods section will specify the prompting strategies (including chain-of-thought and few-shot examples), the precise decision criteria for rule satisfaction (e.g., LLM confidence thresholds or voting schemes), explicit handling of event-driven edge cases such as timing variability and multi-sprite interactions, and a validation experiment comparing LLM judgments to human annotations on a held-out video sample. We will also discuss observed biases and mitigation steps. revision: yes
Circularity Check
No significant circularity detected
full rationale
This is an empirical systems paper whose central claims rest on direct comparison of Raven's outputs against independent human ground-truth labels for 140 student submissions across 13 assignments, plus a separate classroom study. No mathematical derivations, parameter fittings, or self-referential predictions appear in the provided text; evaluation metrics are computed from external annotations rather than any internal construction that reduces to the paper's own inputs. The design choices (video-grounded task-level rules) are presented as engineering decisions validated by the external benchmark, with no load-bearing self-citations or ansatzes that collapse the result to a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dimah Al-Fraihat, Mike Joy, Ra’ed Masa’deh, and Jane Sinclair. 2020. Evaluating E-learning systems success: An empirical study.Computers in Human Behavior102 (2020), 67–86. doi:10.1016/j.chb.2019.08.004
-
[2]
Kirsti M Ala-Mutka. 2005. A Survey of Automated Assessment Approaches for Programming Assignments.Computer Science Education15, 2 (2005), 83–102. doi:10.1080/08993400500150747
-
[3]
Sinan Ariyurek, Aysu Betin-Can, and Elif Surer. 2021. Automated Video Game Testing Using Synthetic and Humanlike Agents.IEEE Transactions on Games13, 1 (2021), 50–67. doi:10.1109/TG.2019.2947597
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, et al . 2025. Qwen3-VL Technical Report. arXiv:2511.21631 [cs.CV] https: //arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, et al . 2025. Qwen2.5-VL Technical Report. arXiv:2502.13923 [cs.CV] https: //arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Mohammad Bajammal, Andrea Stocco, Davood Mazinanian, and Ali Mesbah. 2022. A Survey on the Use of Computer Vision to Improve Software Engineering Tasks.IEEE Transactions on Software Engineering48, 5 (2022), 1722–1742. doi:10.1109/TSE.2020.3032986
-
[7]
Ishan Banerjee, Bao Nguyen, Vahid Garousi, and Atif Memon. 2013. Graphical user interface (GUI) testing: Systematic mapping and repository.Information and Software Technology55, 10 (2013), 1679–1694. doi:10 .1016/j.infsof .2013.03.004
2013
-
[8]
Bryce Boe, Charlotte Hill, Michelle Len, Greg Dreschler, Phillip Conrad, and Diana Franklin. 2013. Hairball: lint- inspired static analysis of scratch projects. InProceeding of the 44th ACM Technical Symposium on Computer Science Education(Denver, Colorado, USA)(SIGCSE ’13). Association for Computing Machinery, New York, NY, USA, 215–220. doi:10.1145/2445...
-
[9]
Janet Carter, Kirsti Ala-Mutka, Ursula Fuller, Martin Dick, John English, William Fone, and Judy Sheard. 2003. How shall we assess this?. InWorking Group Reports from ITiCSE on Innovation and Technology in Computer Science Education(Thessaloniki, Greece)(ITiCSE-WGR ’03). Association for Computing Machinery, New York, NY, USA, 107–123. doi:10.1145/960875.960539
-
[10]
Cecilia Ka Yuk Chan and Wenjie Hu. 2023. Students’ voices on generative AI: perceptions, benefits, and challenges in higher education.International Journal of Educational Technology in Higher Education20, 1 (July 2023), 43. doi:10 .1186/ s41239-023-00411-8
2023
-
[11]
Li-Hsin Chang and Filip Ginter. 2024. Automatic Short Answer Grading for Finnish with ChatGPT.Proceedings of the AAAI Conference on Artificial Intelligence38, 21 (Mar. 2024), 23173–23181. doi:10.1609/aaai.v38i21.30363
-
[12]
Tsung-Hsiang Chang, Tom Yeh, and Robert C. Miller. 2010. GUI testing using computer vision. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Atlanta, Georgia, USA)(CHI ’10). Association for Computing Machinery, New York, NY, USA, 1535–1544. doi:10.1145/1753326.1753555
-
[13]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and et al. 2021. Evaluating Large Language Models Trained on Code. arXiv:2107.03374. https://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Fred D. Davis. 1989. Perceived usefulness, perceived ease of use, and user acceptance of information technology.MIS Q.13, 3 (Sept. 1989), 319–340. doi:10.2307/249008
-
[15]
Adina Deiner, Patric Feldmeier, Gordon Fraser, Sebastian Schweikl, and Wengran Wang. 2023. Automated Test Generation for Scratch Programs.Empirical Software Engineering28, 1 (2023), 79. doi:10.1007/s10664-022-10255-x
- [16]
-
[17]
Adina Deiner and Gordon Fraser. 2024. NuzzleBug: Debugging Block-Based Programs in Scratch. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE ’24). 1—2. doi:10.1145/3597503.3623331
-
[18]
Benedikt Fein, Florian Obermüller, and Gordon Fraser. 2022. CATNIP: An Automated Hint Generation Tool for Scratch. InProceedings of the 27th ACM Conference on on Innovation and Technology in Computer Science Education Vol. 1(Dublin, Ireland)(ITiCSE ’22). Association for Computing Machinery, New York, NY, USA, 124–130. doi:10.1145/3502718.3524820
-
[19]
Andrina Granić and Nikola Marangunić. 2019. Technology acceptance model in educational context: A systematic literature review.British Journal of Educational Technology50, 5 (2019), 2572–2593. doi:10.1111/bjet.12864
-
[20]
Christian Grévisse. 2024. LLM-based automatic short answer grading in undergraduate medical education.BMC Medical Education24, 1 (Sept. 2024), 1060. doi:10.1186/s12909-024-06026-5 , Vol. 1, No. 1, Article . Publication date: April 2026. 20 Donglin Li, Daming Li, Hanyuan Shi, and Jialu Zhang
-
[21]
Jialiang Gu, Keren Zhou, Daming Li, Hanyuan Shi, and Jialu Zhang. 2026. Context-Aware Feedback Compression in Online Judge Programming with LLMs. InProceedings of the 34th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (FSE Companion ’26)(Montreal, QC, Canada, 5–9 July 2026) (FSE Companion ’26)....
- [22]
-
[23]
Felienne Hermans and Efthimia Aivaloglou. 2016. Do code smells hamper novice programming? A controlled experiment on Scratch programs. In2016 IEEE 24th International Conference on Program Comprehension (ICPC). 1–10. doi:10.1109/ICPC.2016.7503706
-
[24]
Silas Hsu, Tiffany Wenting Li, Zhilin Zhang, Max Fowler, Craig Zilles, and Karrie Karahalios. 2021. Attitudes Surrounding an Imperfect AI Autograder(CHI ’21). Association for Computing Machinery, New York, NY, USA, Article 681, 15 pages. doi:10.1145/3411764.3445424
-
[25]
Majeed Kazemitabaar, Runlong Ye, Xiaoning Wang, et al. 2024. CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 6...
-
[26]
Hieke Keuning, Bastiaan Heeren, and Johan Jeuring. 2017. Code Quality Issues in Student Programs. InProceedings of the 2017 ACM Conference on Innovation and Technology in Computer Science Education (ITiCSE ’17). Association for Computing Machinery, New York, NY, USA, 110–115. doi:10.1145/3059009.3059061
-
[27]
Hieke Keuning, Johan Jeuring, and Bastiaan Heeren. 2019. A Systematic Literature Review of Automated Feedback Generation for Programming Exercises.ACM Transactions on Computing Education19, 1 (2019), 3:1–3:43. doi:10 .1145/ 3231711
2019
-
[28]
Juho Leinonen, Paul Denny, Stephen MacNeil, et al. 2023. Comparing Code Explanations Created by Students and Large Language Models. InProceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1 (ITiCSE 2023). Association for Computing Machinery, New York, NY, USA, 124–130. doi:10.1145/3587102.3588785
-
[29]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2017. DroidBot: a lightweight UI-Guided test input generator for android. In2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). 23–26. doi:10.1109/ICSE-C.2017.8
-
[30]
Xiaoyun Liang, Jiayi Qi, Yongqiang Gao, Chao Peng, and Ping Yang. 2023. AG3: Automated Game GUI Text Glitch Detection Based on Computer Vision. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(San Francisco, CA, USA)(ESEC/FSE 2023). Association for Computing Machinery, Ne...
-
[31]
2024.How to Teach Programming in the AI Era? Using LLMs as a Teachable Agent for Debugging
Qianou Ma, Hua Shen, Kenneth Koedinger, and Sherry Tongshuang Wu. 2024.How to Teach Programming in the AI Era? Using LLMs as a Teachable Agent for Debugging. Springer Nature Switzerland, 265–279. doi:10 .1007/978-3-031- 64302-6_19
2024
-
[32]
John Maloney, Mitchel Resnick, Natalie Rusk, Brian Silverman, and Evelyn Eastmond. 2010. The Scratch Programming Language and Environment. 10, 4, Article 16 (Nov. 2010), 15 pages. doi:10.1145/1868358.1868363
-
[33]
Marcus Messer, Neil C. C. Brown, Michael Kölling, and Miaojing Shi. 2024. Automated Grading and Feedback Tools for Programming Education: A Systematic Review. 24, 1, Article 10 (Feb. 2024), 43 pages. doi:10.1145/3636515
-
[34]
Jesús Moreno-León and Gregorio Robles. 2015. Dr. Scratch: a Web Tool to Automatically Evaluate Scratch Projects. In Proceedings of the Workshop in Primary and Secondary Computing Education(London, United Kingdom)(WiPSCE ’15). Association for Computing Machinery, New York, NY, USA, 132–133. doi:10.1145/2818314.2818338
-
[35]
Tushar Nagarajan and Kristen Grauman. 2021. Shaping embodied agent behavior with activity-context priors from egocentric video. InAdvances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (Eds.), Vol. 34. Curran Associates, Inc., 29794–29805. https://proceedings .neurips.cc/ paper_files/p...
2021
-
[36]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to Help With Code Understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 97, 13 pages. doi:10 .1145/ 3597503.3639187
-
[37]
Seong-Guk Nam and Yeong-Seok Seo. 2023. GUI Component Detection-Based Automated Software Crash Diagnosis. Electronics12, 11 (2023). doi:10.3390/electronics12112382
-
[38]
Nguyen, Bryan Robbins, Ishan Banerjee, and Atif Memon
Bao N. Nguyen, Bryan Robbins, Ishan Banerjee, and Atif Memon. 2014. GUITAR: an innovative tool for automated testing of GUI-driven software.Automated Software Engineering21, 1 (March 2014), 65–105. doi:10 .1007/s10515-013- 0128-9
2014
-
[39]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, et al. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774 , Vol. 1, No. 1, Article . Publication date: April 2026. Raven: Rethinking Automated Assessment for Scratch Programs via Video-Grounded Evaluation 21
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Carlos Pacheco, Shuvendu K. Lahiri, Michael D. Ernst, and Thomas Ball. 2007. Feedback-Directed Random Test Generation. In29th International Conference on Software Engineering (ICSE’07). 75–84. doi:10.1109/ICSE.2007.37
-
[41]
José Carlos Paiva, José Paulo Leal, and Álvaro Figueira. 2022. Automated Assessment in Computer Science Education: A State-of-the-Art Review.ACM Trans. Comput. Educ.22, 3, Article 34 (June 2022), 40 pages. doi:10.1145/3513140
-
[42]
Raphael Pham, Helge Holzmann, Kurt Schneider, and Christian Brüggemann. 2014. Tailoring video recording to support efficient GUI testing and debugging.Software Quality Journal22, 2 (June 2014), 273–292. doi:10 .1007/s11219-013-9206-2
2014
-
[43]
Tung Phung, José Cambronero, Sumit Gulwani, Tobias Kohn, Rupak Majumdar, Adish Singla, and Gustavo Soares. 2023. Generating High-Precision Feedback for Programming Syntax Errors using Large Language Models.Proceedings of the 16th International Conference on Educational Data Mining (EDM 2023)(2023), 370–377. doi:10.5281/zenodo.8115653
-
[44]
Price, Yihuan Dong, and Dragan Lipovac
Thomas W. Price, Yihuan Dong, and Dragan Lipovac. 2017. iSnap: Towards Intelligent Tutoring in Novice Programming Environments. InSIGCSE. 483–488. doi:10.1145/3017680.3017762
-
[45]
MIT Press, Cambridge, MA (2021), https://mitpress.mit.edu/9780262044776
Mitchel Resnick. 2017.Lifelong Kindergarten: Cultivating Creativity through Projects, Passion, Peers, and Play. MIT Press, Cambridge, MA. https://mitpress.mit.edu/9780262037297/lifelong-kindergarten/
-
[46]
Mitchel Resnick, John Maloney, Andrés Monroy-Hernández, Natalie Rusk, Evelyn Eastmond, Karen Brennan, Amon Millner, Eric Rosenbaum, Jay Silver, Brian Silverman, and Yasmin Kafai. 2009. Scratch: programming for all.Commun. ACM52, 11 (Nov. 2009), 60–67. doi:10.1145/1592761.1592779
-
[47]
Zachary P. Reynolds, Abhinandan B. Jayanth, Ugur Koc, et al . 2017. Identifying and Documenting False Positive Patterns Generated by Static Code Analysis Tools. In2017 IEEE/ACM 4th International Workshop on Software Engineering Research and Industrial Practice (SER&IP). 55–61. doi:10.1109/SER-IP.2017..20
-
[48]
Koedinger
Kelly Rivers and Kenneth R. Koedinger. 2017. Data-Driven Hint Generation in Vast Solution Spaces: A Self-Improving Python Programming Tutor.International Journal of Artificial Intelligence in Education27, 1 (2017), 37–64. doi:10 .1007/ s40593-015-0070-z
2017
-
[49]
Marcos Román-González, Jesús Moreno-León, and Gregorio Robles. 2017. Complementary Tools for Computational Thinking Assessment. https://www .researchgate.net/publication/ 318469859_Complementary_Tools_for_Computational_Thinking_Assessment
2017
-
[50]
Mark Santolucito, Jialu Zhang, Ennan Zhai, Jürgen Cito, and Ruzica Piskac. 2022. Learning CI Configuration Correctness for Early Build Feedback. In2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). 1006–1017. doi:10.1109/SANER53432.2022.00118
-
[51]
Ronny Scherer, Fazilat Siddiq, and Jo Tondeur. 2019. The technology acceptance model (TAM): A meta-analytic structural equation modeling approach to explaining teachers’ adoption of digital technology in education.Computers & Education128 (2019), 13–35. doi:10.1016/j.compedu.2018.09.009
-
[52]
Sebastian Schweikl and Gordon Fraser. 2025. RePurr: Automated Repair of Block-Based Learners’ Programs.Proc. ACM Softw. Eng.2, FSE, Article FSE067 (June 2025), 24 pages. doi:10.1145/3715786
-
[53]
Scratch Foundation. 2026. Scratch Statistics - Scratch Imagine, Program, Share. https://scratch .mit.edu/statistics/. Accessed: 2026-01-29
2026
- [54]
- [55]
- [56]
- [57]
-
[58]
Andreas Stahlbauer, Marvin Kreis, and Gordon Fraser. 2019. Testing scratch programs automatically. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Tallinn, Estonia)(ESEC/FSE 2019). Association for Computing Machinery, New York, NY, USA, 165–175. doi:10.11...
-
[59]
Niko Strijbol, Robbe De Proft, Klaas Goethals, Bart Mesuere, Peter Dawyndt, and Christophe Scholliers. 2024. Blink: An educational software debugger for Scratch.SoftwareX25 (2024), 101617. doi:10.1016/j.softx.2023.101617
-
[60]
Shao-Hua Sun, Hyeonwoo Noh, Sriram Somasundaram, and Joseph Lim. 2018. Neural Program Synthesis from Diverse Demonstration Videos. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, 4790–4799. https://proceedings .mlr.press/ v80/sun18a.html
2018
- [61]
-
[62]
Peng Wang, Shuai Bai, Sinan Tan, et al. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv:2409.12191 [cs.CV] https://arxiv.org/abs/2409.12191 , Vol. 1, No. 1, Article . Publication date: April 2026. 22 Donglin Li, Daming Li, Hanyuan Shi, and Jialu Zhang
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [63]
-
[64]
An Yang, Anfeng Li, Baosong Yang, et al. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https://arxiv .org/ abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [65]
-
[66]
Tom Yeh, Tsung-Hsiang Chang, and Robert C. Miller. 2009. Sikuli: using GUI screenshots for search and automation. InProceedings of the 22nd Annual ACM Symposium on User Interface Software and Technology(Victoria, BC, Canada) (UIST ’09). Association for Computing Machinery, New York, NY, USA, 183–192. doi:10.1145/1622176.1622213
-
[67]
Jialu Zhang, José Pablo Cambronero, Sumit Gulwani, Vu Le, Ruzica Piskac, Gustavo Soares, and Gust Verbruggen
-
[68]
PyDex: Repairing Bugs in Introductory Python Assignments using LLMs.Proc. ACM Program. Lang.8, OOPSLA1 (2024), 1100–1124. doi:10.1145/3649850
- [69]
-
[70]
Jialu Zhang, De Li, John Charles Kolesar, Hanyuan Shi, and Ruzica Piskac. 2023. Automated Feedback Generation for Competition-Level Code. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering(Rochester, MI, USA)(ASE ’22). Association for Computing Machinery, New York, NY, USA, Article 13, 13 pages. doi:10.1145/35513...
-
[71]
Jialu Zhang, Todd Mytkowicz, Mike Kaufman, Ruzica Piskac, and Shuvendu K. Lahiri. 2022. Using pre-trained language models to resolve textual and semantic merge conflicts (experience paper). InISSTA ’22: 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event, South Korea, July 18 - 22, 2022, Sukyoung Ryu and Yannis Smaragd...
-
[72]
Yan Zheng, Xiaofei Xie, Ting Su, Lei Ma, et al. 2019. Wuji: Automatic Online Combat Game Testing Using Evolutionary Deep Reinforcement Learning. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). 772–784. doi:10.1109/ASE.2019.00077 , Vol. 1, No. 1, Article . Publication date: April 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.