Recognition: unknown
UniCSG: Unified High-Fidelity Content-Constrained Style-Driven Generation via Staged Semantic and Frequency Disentanglement
Pith reviewed 2026-05-10 05:12 UTC · model grok-4.3
The pith
UniCSG separates content semantics from style in latent space through staged low-frequency preprocessing and frequency-aware reconstruction to improve faithfulness in diffusion-based style transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniCSG is a unified framework for content-constrained style-driven generation that employs staged training consisting of a latent-space semantic disentanglement stage using low-frequency preprocessing and conditioning corruption to encourage separation, followed by a latent-space frequency-aware detail reconstruction stage with multi-scale frequency supervision, plus pixel-space reward learning to align with perceptual quality, yielding improved content faithfulness and style alignment.
What carries the argument
Staged latent-space training that first disentangles semantics via low-frequency preprocessing and conditioning corruption, then reconstructs details via multi-scale frequency supervision, augmented by pixel-space reward learning.
If this is right
- Greater content faithfulness because original semantics remain intact while style is applied.
- Reduced reference-content leakage through explicit separation before detail reconstruction.
- Robust performance across both text prompts and image references as style sources.
- Higher perceptual quality after decoding due to the reward alignment step.
- Unified handling of multiple guidance modes without separate models.
Where Pith is reading between the lines
- The frequency supervision step could be adapted to control detail levels at different scales in other generative tasks.
- If the separation holds, the same staged approach might reduce entanglement in conditional video generation.
- Reward learning in pixel space after latent training suggests a general way to bridge latent objectives with human preferences.
Load-bearing premise
That low-frequency preprocessing combined with conditioning corruption will produce reliable content-style separation in latent space without introducing new artifacts that the later frequency reconstruction stage cannot correct.
What would settle it
Measure content leakage on held-out reference images by comparing structural similarity or semantic consistency scores between outputs from the full UniCSG pipeline versus the same model trained without the low-frequency preprocessing and corruption steps.
Figures




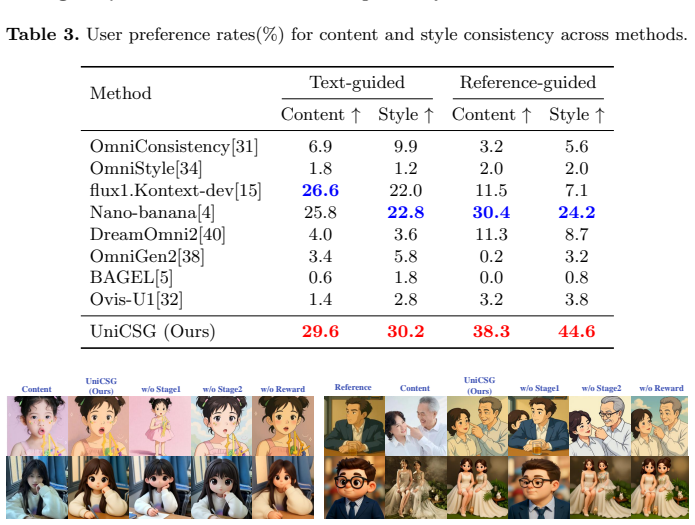
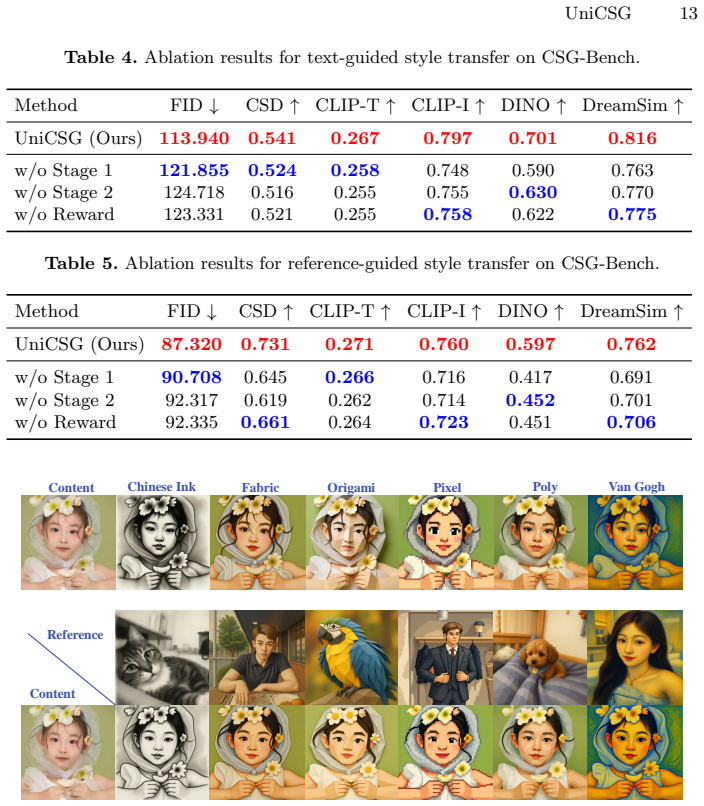







read the original abstract
Style transfer must match a target style while preserving content semantics. DiT-based diffusion models often suffer from content-style entanglement, leading to reference-content leakage and unstable generation. We present UniCSG, a unified framework for content-constrained, style-driven generation in both text-guided and reference-guided settings. UniCSG employs staged training: (i) a latent-space semantic disentanglement stage that combines low-frequency preprocessing with conditioning corruption to encourage content-style separation, and (ii) a latent-space frequency-aware detail reconstruction stage that refines details via multi-scale frequency supervision. We further incorporate pixel-space reward learning to align latent objectives with perceptual quality after decoding. Experiments demonstrate improved content faithfulness, style alignment, and robustness in both settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniCSG, a unified framework for content-constrained style-driven generation with DiT-based diffusion models. It uses staged latent-space training consisting of (i) semantic disentanglement via low-frequency preprocessing combined with conditioning corruption and (ii) frequency-aware detail reconstruction with multi-scale frequency supervision, plus pixel-space reward learning to align with perceptual quality. The approach targets both text-guided and reference-guided settings and claims improved content faithfulness, style alignment, and robustness.
Significance. If the staged disentanglement proves reliable, the work could meaningfully advance controllable style transfer by mitigating content-style entanglement and reference leakage in modern diffusion models. The combination of frequency preprocessing, corruption-based separation, and multi-scale supervision is a coherent technical choice, and the unified treatment of text and reference guidance is a practical strength. No machine-checked proofs or parameter-free derivations are present, but the pipeline is falsifiable via standard style-transfer metrics.
major comments (1)
- Abstract and experimental sections: the central claim that experiments demonstrate improved content faithfulness, style alignment, and robustness rests on assertions without any reported quantitative metrics, baselines, ablation studies, or error analysis. This is load-bearing because the value of the low-frequency preprocessing plus conditioning corruption step cannot be assessed without evidence that it produces usable separation that the reconstruction stage can reliably refine.
minor comments (2)
- The description of the conditioning corruption mechanism would benefit from an explicit equation or pseudocode showing how corruption is applied and annealed across training stages.
- Figure captions and method diagrams should explicitly label the low-frequency preprocessing block and the multi-scale frequency supervision losses to improve traceability from text to visuals.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation of major revision. We agree that the experimental claims require quantitative backing to be convincing and will substantially expand the experimental section with metrics, baselines, ablations, and analysis in the revised manuscript.
read point-by-point responses
-
Referee: Abstract and experimental sections: the central claim that experiments demonstrate improved content faithfulness, style alignment, and robustness rests on assertions without any reported quantitative metrics, baselines, ablation studies, or error analysis. This is load-bearing because the value of the low-frequency preprocessing plus conditioning corruption step cannot be assessed without evidence that it produces usable separation that the reconstruction stage can reliably refine.
Authors: We accept this criticism. The current manuscript relies on qualitative results and the abstract's summary statement without supporting numbers. In the revision we will add: (1) quantitative tables reporting LPIPS, SSIM, and CLIP-based content similarity for faithfulness; style alignment via Gram-matrix or VGG feature distances; and robustness metrics under reference perturbation or text variation; (2) direct comparisons against DiT fine-tuning, IP-Adapter, and recent style-transfer baselines; (3) ablations that isolate the low-frequency preprocessing and conditioning-corruption components, measuring their effect on separation quality before and after the reconstruction stage; and (4) an error-analysis subsection with representative failure cases and quantitative breakdown. These additions will allow readers to evaluate whether the staged disentanglement produces the claimed separation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an empirical staged training pipeline (latent semantic disentanglement via low-frequency preprocessing and conditioning corruption, followed by frequency-aware reconstruction and pixel-space reward learning) for content-constrained style transfer in DiT diffusion models. No equations, derivations, uniqueness theorems, or self-citations that reduce any claimed result to its own inputs by construction appear in the abstract or method summary. Performance claims rest on experimental outcomes rather than closed-form reductions or fitted parameters renamed as predictions. The separation reliability is flagged as an unverified empirical link, but this is a standard assumption open to external falsification and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2503.10614 (2025)
Chen, B., Zhao, B., Xie, H., Cai, Y., Li, Q., Mao, X.: Consislora: Enhancing content and style consistency for lora-based style transfer. arXiv preprint arXiv:2503.10614 (2025)
- [3]
-
[4]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities (2025),https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., Fan, H.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review arXiv 2025
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Deng, Y., Tang, F., Dong, W., Ma, C., Pan, X., Wang, L., Xu, C.: Stytr2: Image style transfer with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11326–11336 (June 2022)
2022
-
[7]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021), https://arxiv.org/abs/2010.11929 16 Yang et al
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
In: Forty- first International Conference on Machine Learning (2024),https://openreview
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M¨ uller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., Rombach, R.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty- first International Conference on Machine Learning (2024),https://openreview. net/forum?id=FPnUhsQJ5B
2024
-
[9]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Fu, S., Tamir, N.Y., Sundaram, S., Chai, L., Zhang, R., Dekel, T., Isola, P.: Dream- sim: learning new dimensions of human visual similarity using synthetic data. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[10]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV)
Gao, Z., Song, J., Zhang, Z., Deng, J., Patras, I.: Frequency-guided diffusion for training-free text-driven image translation. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV). pp. 19195–19205 (October 2025)
2025
-
[11]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
2016
-
[12]
In: Proceed- ings of the 31st International Conference on Neural Information Processing Sys- tems
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. In: Proceed- ings of the 31st International Conference on Neural Information Processing Sys- tems. p. 6629–6640. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017)
2017
-
[13]
In: ICCV (2017)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: ICCV (2017)
2017
-
[14]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[15]
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., M¨ uller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://a...
work page internal anchor Pith review arXiv 2025
- [16]
- [17]
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Lei, M., Song, X., Zhu, B., Wang, H., Zhang, C.: Stylestudio: Text-driven style transfer with selective control of style elements. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 23443–23452 (June 2025)
2025
-
[19]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
Li, H., Fan, Z., Wen, Z., Zhu, Z., Li, Y.: Aicomposer: Any style and content image composition via feature integration. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 16840–16850 (October 2025)
2025
-
[20]
Li, T., He, K.: Back to basics: Let denoising generative models denoise (2026), https://arxiv.org/abs/2511.13720
work page internal anchor Pith review arXiv 2026
- [21]
-
[22]
Ma, Z., Wei, L., Wang, S., Zhang, S., Tian, Q.: Deco: Frequency-decoupled pixel diffusion for end-to-end image generation (2025),https://arxiv.org/abs/2511. 19365
2025
-
[23]
Transactions on Ma- chine Learning Research (2024),https://openreview.net/forum?id=a68SUt6zFt, featured Certification
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: UniCSG 17 DINOv2: Learning robust v...
2024
-
[24]
Pan, Y., Feng, R., Dai, Q., Wang, Y., Lin, W., Guo, M., Luo, C., Zheng, N.: Seman- tics lead the way: Harmonizing semantic and texture modeling with asynchronous latent diffusion. arXiv preprint arXiv:2512.04926 (2025)
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4195– 4205 (October 2023)
2023
-
[26]
In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M¨ uller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution im- age synthesis. In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on Learning Representations. vol. 2024, pp. 1862–1874 (2024),https://pr...
2024
-
[27]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceed- ings of Machine Learning Res...
2021
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Shang, C., Wang, Z., Wang, H., Meng, X.: Scsa: A plug-and-play semantic continuous-sparse attention for arbitrary semantic style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13051–13060 (June 2025)
2025
-
[29]
Measuring style similarity in diffusion models
Somepalli, G., Gupta, A., Gupta, K., Palta, S., Goldblum, M., Geiping, J., Shri- vastava, A., Goldstein, T.: Measuring style similarity in diffusion models. arXiv preprint arXiv:2404.01292 (2024)
- [30]
-
[31]
Song, Y., Liu, C., Shou, M.Z.: Omniconsistency: Learning style-agnostic consis- tency from paired stylization data (2025),https://api.semanticscholar.org/ CorpusID:278905729
2025
-
[32]
Wang, G.H., Zhao, S., Zhang, X., Cao, L., Zhan, P., Duan, L., Lu, S., Fu, M., Zhao, J., Li, Y., Chen, Q.G.: Ovis-u1 technical report. arXiv preprint arXiv:2506.23044 (2025)
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang, X., Xu, W., Zhang, Q., Zheng, W.S.: Domain generalizable portrait style transfer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 15802–15811 (October 2025)
2025
-
[34]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Wang, Y., Liu, R., Lin, J., Liu, F., Yi, Z., Wang, Y., Ma, R.: Omnistyle: Filtering high quality style transfer data at scale. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 7847–7856 (June 2025)
2025
-
[35]
ArXivabs/2509.05970(2025),https://api.semanticscholar
Wang, Y., Yi, Z., Zhang, Y., Zheng, P., Xie, X., Lin, J., Wang, Y., Ma, R.: Omnistyle2: Scalable and high quality artistic style transfer data generation via destylization. ArXivabs/2509.05970(2025),https://api.semanticscholar. org/CorpusID:286975228
-
[36]
International Journal 18 Yang et al
Wang, Z., Wang, X., Xie, L., Qi, Z., Shan, Y., Wang, W., Luo, P.: StyleAdapter: A Unified Stylized Image Generation Model. International Journal 18 Yang et al. of Computer Vision133(4), 1894–1911 (Apr 2025).https://doi.org/10.1007/ s11263-024-02253-x,https://doi.org/10.1007/s11263-024-02253-x
-
[37]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review arXiv 2025
-
[38]
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., Liu, Z., Xia, Z., Li, C., Deng, H., Wang, J., Luo, K., Zhang, B., Lian, D., Wang, X., Wang, Z., Huang, T., Liu, Z.: Omnigen2: Exploration to advanced multimodal generation (2025),https://arxiv.org/abs/2506.18871
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Wu, S., Huang, M., Cheng, Y., Wu, W., Tian, J., Luo, Y., Ding, F., He, Q.: Uso: Unified style and subject-driven generation via disentangled and reward learning (2025)
2025
- [40]
- [41]
-
[42]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=n4nmiIq3qj
Xing, P., Wang, H., Sun, Y., wangqixun, Baixu, Ai, H., Huang, J.Y., Li, Z.: CSGO: Content-style composition in text-to-image generation. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=n4nmiIq3qj
2025
-
[43]
Towards scalable pre-training of visual tokenizers for generation
Yao, J., Song, Y., Zhou, Y., Wang, X.: Towards scalable pre-training of visual tokenizers for generation. arXiv preprint arXiv:2512.13687 (2025)
-
[44]
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models (2023)
2023
- [45]
-
[46]
Yu, Y., Xiong, W., Nie, W., Sheng, Y., Liu, S., Luo, J.: Pixeldit: Pixel diffusion transformers for image generation (2025),https://arxiv.org/abs/2511.20645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 3836–3847 (October 2023)
2023
-
[48]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric (2018),https://arxiv.org/ abs/1801.03924
work page Pith review arXiv 2018
-
[49]
In: Fumero, M., Domine, C., L¨ ahner, Z., Crisostomi, D., Moschella, L., Stachen- feld, K
Zhang, S.: Fast imagic: Solving overfitting in text-guided image editing via disen- tangled UNet with forgetting mechanism and unified vision-language optimization. In: Fumero, M., Domine, C., L¨ ahner, Z., Crisostomi, D., Moschella, L., Stachen- feld, K. (eds.) Proceedings of UniReps: the Second Edition of the Workshop on Unifying Representations in Neur...
2024
-
[50]
13770 UniCSG 19
Zhang, S., Chen, Z., Chen, L., Wu, Y.: Cdst: Color disentangled style transfer for universal style reference customization (2025),https://arxiv.org/abs/2506. 13770 UniCSG 19
2025
- [51]
-
[52]
Zhang, S., Xiao, S., Huang, W.: Forgedit: Text guided image editing via learning and forgetting (2024),https://openreview.net/forum?id=nh4vQ1tGCt
2024
-
[53]
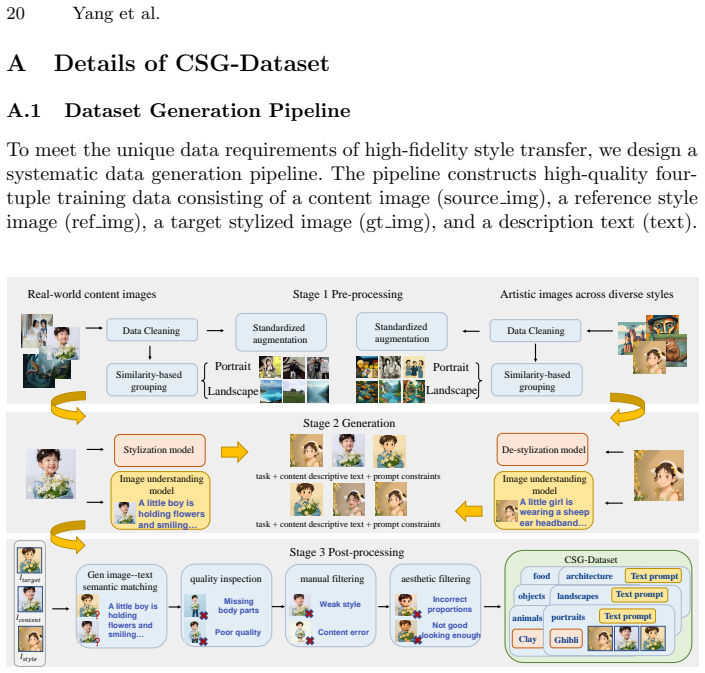
Zhang, Z., Ma, A., Cao, K., Wang, J., Liu, S., Ma, Y., Cheng, B., Leng, D., Yin, Y.: U-stydit: Ultra-high quality artistic style transfer using diffusion transformers (2025),https://arxiv.org/abs/2503.08157 20 Yang et al. A Details of CSG-Dataset A.1 Dataset Generation Pipeline To meet the unique data requirements of high-fidelity style transfer, we desig...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.