Recognition: 2 theorem links
· Lean TheoremRankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems
Pith reviewed 2026-05-13 07:10 UTC · model grok-4.3
The pith
RankUp mitigates representation collapse in deep recommender models by increasing the effective rank of token representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that randomized permutation splitting over sparse features combined with a multi-embedding paradigm, global token integration, and crossed pretrained embedding tokens prevents representation collapse, enabling the effective rank of representations to increase more consistently with model depth in large-scale advertising recommender systems, as demonstrated by production deployments yielding GMV improvements.
What carries the argument
Randomized permutation splitting over sparse features together with the multi-embedding paradigm, global token integration, and crossed pretrained embedding tokens, which collectively maintain higher effective rank across layers.
If this is right
- Effective rank of token representations increases consistently rather than oscillating and degrading.
- Expressive capacity of the model improves, supporting better performance in advertising recommendations.
- Production systems see GMV gains of 3.41% in Video Accounts, 4.81% in Official Accounts, and 2.12% in Moments.
- Scaling laws for depth and dimensionality translate more directly into representation quality.
Where Pith is reading between the lines
- Similar splitting techniques could address rank issues in other deep learning domains like transformers for language or vision.
- Models might be able to go deeper without hitting rank collapse limits if this method is generalized.
- The focus on rank as a diagnostic could lead to new monitoring tools for model health in recommenders.
- Crossed pretrained embeddings might transfer benefits from pretraining more effectively in sparse settings.
Load-bearing premise
That the observed GMV improvements are attributable to the increase in effective rank rather than other unmentioned changes during deployment or the choice of comparison baselines.
What would settle it
Measuring the effective rank trajectory in RankUp models when depth is increased further and checking if rank continues to rise without degradation, or if performance gains disappear when rank is artificially capped.
Figures



read the original abstract
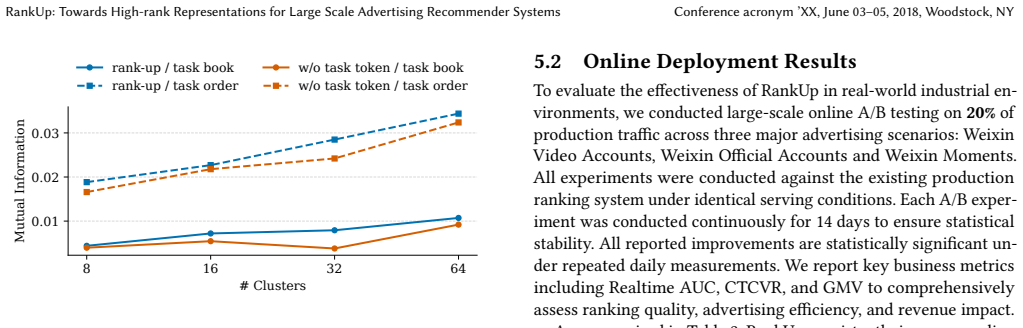
The scaling laws for recommender systems have been increasingly validated, where MetaFormer-based architectures consistently benefit from increased model depth, hidden dimensionality, and user behavior sequence length. However, whether representation capacity scales proportionally with parameter growth remains unexplored. Prior studies on RankMixer reveal that the effective rank of token representations exhibits a damped oscillatory trajectory across layers, failing to increase consistently with depth and even degrading in deeper layers. Motivated by this observation, we propose RankUp, an architecture designed to mitigate representation collapse and enhance expressive capacity through randomized permutation splitting over sparse features, a multi-embedding paradigm, global token integration and crossed pretrained embedding tokens. RankUp has been fully deployed in large-scale production across Weixin Video Accounts, Official Accounts and Moments, yielding GMV improvements of 3.41%, 4.81% and 2.12%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RankUp, an architecture to mitigate representation collapse and increase effective rank in large-scale recommender systems. It uses randomized permutation splitting over sparse features, a multi-embedding paradigm, global token integration, and crossed pretrained embedding tokens. Motivated by damped rank trajectories observed in RankMixer, the work reports full production deployment in Weixin Video Accounts, Official Accounts, and Moments, with associated GMV improvements of 3.41%, 4.81%, and 2.12%.
Significance. If the causal link between the proposed components, measured rank increases, and the reported GMV lifts can be established, the result would be significant for industrial recommender systems. It would provide concrete evidence that preserving high effective rank yields measurable business impact at scale, extending scaling-law observations to representation capacity in advertising recommenders.
major comments (2)
- [Abstract] Abstract: The central claim that RankUp's techniques produce the stated GMV lifts via increased effective rank is unsupported by any reported rank measurements (pre/post-deployment), ablation studies isolating each component (permutation splitting, multi-embedding, global tokens, crossed embeddings), statistical tests, or baseline comparisons. Without these, the causal path from architecture change to business metric cannot be verified.
- [Abstract] Abstract (results paragraph): No description is given of the deployment protocol, including whether changes were evaluated via A/B test versus full rollout, whether other system modifications occurred simultaneously, or how the baseline model was defined and held constant. This leaves open the possibility that observed GMV gains arise from uncontrolled factors rather than rank improvement.
minor comments (2)
- [Abstract] The abstract references 'Prior studies on RankMixer' but does not provide a citation; adding the specific reference would improve traceability of the motivating observation.
- [Abstract] Terminology such as 'randomized permutation splitting' and 'crossed pretrained embedding tokens' is introduced without a brief operational definition or diagram; a short methods paragraph or figure would aid clarity for readers unfamiliar with the prior RankMixer work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, clarifying the evidence in the manuscript and committing to revisions where the causal claims or deployment details require additional support. The production GMV results remain the primary validation, but we agree that more explicit connections to rank metrics and experimental controls will strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that RankUp's techniques produce the stated GMV lifts via increased effective rank is unsupported by any reported rank measurements (pre/post-deployment), ablation studies isolating each component (permutation splitting, multi-embedding, global tokens, crossed embeddings), statistical tests, or baseline comparisons. Without these, the causal path from architecture change to business metric cannot be verified.
Authors: We agree that the current manuscript does not report explicit pre/post-deployment effective rank measurements or full component-wise ablations with statistical tests. The work is motivated by the damped rank trajectories documented in RankMixer, and the architectural choices (randomized permutation splitting, multi-embeddings, global tokens, crossed pretrained embeddings) are designed to counteract representation collapse. The GMV lifts are observed in live production deployments, which constitute the strongest real-world test. To address the gap, we will add an appendix with offline ablation results on rank metrics (e.g., effective rank before/after each component) and a table isolating contributions, along with baseline comparisons against the prior MetaFormer model. This revision will make the causal pathway more transparent. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): No description is given of the deployment protocol, including whether changes were evaluated via A/B test versus full rollout, whether other system modifications occurred simultaneously, or how the baseline model was defined and held constant. This leaves open the possibility that observed GMV gains arise from uncontrolled factors rather than rank improvement.
Authors: The reported GMV improvements (3.41%, 4.81%, 2.12%) come from full production rollouts in Weixin Video Accounts, Official Accounts, and Moments after internal offline validation. The baseline is the immediately preceding production model without RankUp components; no concurrent major system changes were introduced during the measurement windows. While full A/B tests are not always feasible at this scale due to traffic and engineering constraints, the deployments followed standard controlled rollout procedures with monitoring for external factors. We will revise the abstract and add a dedicated paragraph in the experiments section explicitly describing the deployment protocol, baseline definition, and confirmation that other variables were held constant. This directly mitigates concerns about uncontrolled factors. revision: yes
Circularity Check
Minor self-citation on RankMixer rank trajectory; central claims remain empirical deployment metrics
full rationale
The paper proposes RankUp to address damped rank in representations, motivated by a citation to prior RankMixer observations. However, the load-bearing results are production GMV lifts (3.41%, 4.81%, 2.12%) from full deployment, not a mathematical derivation or fitted prediction that reduces to inputs by construction. No equations, uniqueness theorems, or ansatzes are shown to be self-referential. The RankMixer reference adds a minor dependency on prior work but does not force the reported gains or make the architecture tautological. This is a standard empirical architecture paper with self-contained claims against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Effective rank of token representations exhibits a damped oscillatory trajectory across layers and can degrade in deeper layers
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclearthe effective rank of token representations exhibits a damped oscillatory trajectory across layers... token mixers can only provide bounded rank expansion... per-token FFNs exhibit rank-contractive behavior
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclearRandomized Permutation Splitting reduces correlation and collinearity... Multi-embedding Representation Paradigm expands the foundational degrees of freedom
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
- [3]
- [4]
-
[5]
Miaomiao Cai, Lei Chen, Yifan Wang, Haoyue Bai, Peijie Sun, Le Wu, Min Zhang, and Meng Wang. 2024. Popularity-aware alignment and contrast for mitigating popularity bias. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 187–198
work page 2024
-
[6]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[7]
InProceedings of the 1st workshop on deep learning for recommender systems
Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
-
[8]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Se- bastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of machine learning research24, 240 (2023), 1–113
work page 2023
-
[9]
1999.Elements of information theory
Thomas M Cover. 1999.Elements of information theory. John Wiley & Sons
work page 1999
-
[10]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
work page 2016
- [11]
- [12]
- [13]
-
[14]
Tianyu Hua, Wenxiao Wang, Zihui Xue, Sucheng Ren, Yue Wang, and Hang Zhao. 2021. On feature decorrelation in self-supervised learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9598–9608
work page 2021
- [15]
- [16]
-
[17]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. 2021. Understanding Dimensional Collapse in Contrastive Self-supervised Learning. InICLR
work page 2021
-
[18]
Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Field- aware factorization machines for CTR prediction. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys). 43–50
work page 2016
-
[19]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
work page 2009
-
[20]
Guoming Li, Shangyu Zhang, Junwei Pan, Wentao Ning, Jin Chen, Gengsheng Xue, Chao Zhou, Shudong Huang, Haijie Gu, and Mengling Yang. 2026. Ex- pand More, Shrink Less: Shaping Effective-Rank Dynamics for Dense Scaling in Recommendation. InUnder Review
work page 2026
-
[21]
Donald Loveland, Xinyi Wu, Tong Zhao, Danai Koutra, Neil Shah, and Mingxuan Ju. 2025. Understanding and scaling collaborative filtering optimization from the perspective of matrix rank. InProceedings of the ACM on Web Conference 2025. 436–449
work page 2025
-
[22]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. 2018. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of- Experts. InKDD. ACM, 1930–1939
work page 2018
-
[23]
Junwei Pan, Jian Xu, Alfonso Lobos Ruiz, Wenliang Zhao, Shengjun Pan, Yu Sun, and Quan Lu. 2018. Field-weighted factorization machines for click-through rate prediction in display advertising. InProceedings of the 2018 World Wide Web Conference (WWW). 1349–1357
work page 2018
-
[24]
Junwei Pan, Wei Xue, Ximei Wang, Haibin Yu, Xun Liu, Shijie Quan, Xueming Qiu, Dapeng Liu, Lei Xiao, and Jie Jiang. 2024. Ads recommendation in a collapsed and entangled world. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5566–5577
work page 2024
-
[25]
Olivier Roy and Martin Vetterli. 2007. The effective rank: A measure of effective dimensionality. In2007 15th European signal processing conference. IEEE, 606–610
work page 2007
-
[26]
Noam Shazeer. 2020. Glu variants improve transformer.arXiv preprint arXiv:2002.05202(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[27]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self- attentive neural networks. InProceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM). 1161–1170
work page 2019
-
[28]
Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng
-
[29]
InInterna- tional conference on machine learning
Synthesizer: Rethinking self-attention for transformer models. InInterna- tional conference on machine learning. PMLR, 10183–10192
-
[30]
Yuandong Tian, Xinlei Chen, and Surya Ganguli. 2021. Understanding self- supervised learning dynamics without contrastive pairs. InInternational Confer- ence on Machine Learning. PMLR, 10268–10278
work page 2021
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InNeurIPS
work page 2017
-
[32]
Chenyang Wang, Yuanqing Yu, Weizhi Ma, Min Zhang, Chong Chen, Yiqun Liu, and Shaoping Ma. 2022. Towards representation alignment and uniformity in collaborative filtering. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 1816–1825
work page 2022
-
[33]
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. 2024. Deepnet: Scaling transformers to 1,000 layers.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 10 (2024), 6761–6774
work page 2024
- [34]
-
[35]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. DCN-V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the Web Conference (WWW). 1785–1797
work page 2021
-
[36]
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. 2020. Lin- former: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[37]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational Conference on Machine Learning. PMLR, 9929–9939
work page 2020
-
[38]
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. 2020. On layer normalization in the transformer architecture. InInternational conference on machine learning. PMLR, 10524–10533
work page 2020
-
[39]
Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. 2022. Metaformer is actually what you need for vision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10819–10829
work page 2022
-
[40]
Zhichen Zeng, Xiaolong Liu, Mengyue Hang, Xiaoyi Liu, Qinghai Zhou, Chaofei Yang, Yiqun Liu, Yichen Ruan, Laming Chen, Yuxin Chen, et al. 2025. InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6225–6233
work page 2025
-
[41]
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Shen Li, Yanli Zhao, Yuchen Hao, Yantao Yao, Ellie Dingqiao Wen, et al. 2024. Wukong: Towards a Scaling Law for Large-Scale Recommendation. InInternational Conference on Machine Learning. PMLR, 59421–59434
work page 2024
- [42]
-
[43]
Wei Zhang, Dai Li, Chen Liang, Fang Zhou, Zhongke Zhang, Xuewei Wang, Ru Li, Yi Zhou, Yaning Huang, Dong Liang, et al. 2024. Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta. In Companion Proceedings of the ACM on Web Conference 2024. 47–55
work page 2024
-
[44]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.