Recognition: 2 theorem links
· Lean TheoremLEPO: Latent Reasoning Policy Optimization for Large Language Models
Pith reviewed 2026-05-12 03:54 UTC · model grok-4.3
The pith
LEPO applies reinforcement learning directly to continuous latent representations in large language models by restoring stochasticity with Gumbel-Softmax
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LEPO is a framework that applies RL directly to continuous latent representations. In the rollout stage it maintains stochasticity via Gumbel-Softmax to enable diverse trajectory sampling. In the optimization stage it constructs a unified gradient estimation for both latent representations and discrete tokens. Extensive experiments show that LEPO significantly outperforms existing RL methods for discrete and latent reasoning.
What carries the argument
Gumbel-Softmax reparameterization applied to latent reasoning steps, which injects controllable stochasticity and supports unified gradient estimation across continuous latent representations and discrete tokens
If this is right
- LEPO maintains stochasticity during rollout to sample diverse reasoning trajectories from continuous latent states
- LEPO uses a single gradient estimator that jointly updates latent representations and the discrete tokens that follow them
- LEPO significantly outperforms existing RL methods applied to either discrete token reasoning or other latent techniques
- Latent reasoning becomes directly compatible with standard reinforcement learning frameworks
Where Pith is reading between the lines
- Continuous latent states may encode intermediate reasoning steps more densely than discrete token sequences, which could improve search efficiency on multi-hop tasks
- The unified treatment of latents and tokens suggests that internal activations can be optimized as policy actions without first forcing them into discrete categories
- The same Gumbel-Softmax injection might stabilize training in other settings where continuous variables must be optimized alongside discrete outputs
Load-bearing premise
That adding Gumbel-Softmax stochasticity to latent reasoning restores exploratory capacity without introducing instability or bias, and that the unified gradient estimation for latents and tokens remains stable and effective
What would settle it
A controlled experiment in which removing the Gumbel-Softmax component causes LEPO performance to fall to the level of deterministic latent baselines or in which the combined gradient estimates produce training divergence on standard reasoning benchmarks
Figures









read the original abstract
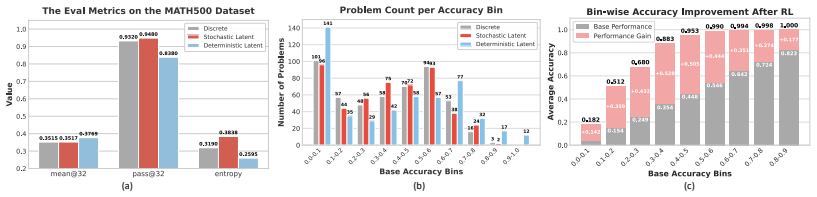
Recently, latent reasoning has been introduced into large language models (LLMs) to leverage rich information within a continuous space. However, without stochastic sampling, these methods inevitably collapse to deterministic inference, failing to discover diverse reasoning paths. To bridge the gap, we inject controllable stochasticity into latent reasoning via Gumbel-Softmax, restoring LLMs' exploratory capacity and enhancing their compatibility with Reinforcement Learning (RL). Building on this, we propose \textbf{\underline{L}}atent R\textbf{\underline{e}}asoning \textbf{\underline{P}}olicy \textbf{\underline{O}}ptimization~(\textbf{LEPO}), a novel framework that applies RL directly to continuous latent representations. Specifically, in rollout stage, LEPO maintains stochasticity to enable diverse trajectory sampling, while in optimization stage, LEPO constructs a unified gradient estimation for both latent representations and discrete tokens. Extensive experiments show that LEPO significantly outperforms existing RL methods for discrete and latent reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LEPO, a framework that injects Gumbel-Softmax stochasticity into continuous latent reasoning in LLMs to prevent deterministic collapse and restore exploration. It then applies RL directly to latent representations via a unified gradient estimator that handles both continuous latents and discrete tokens. The central claim is that this yields significant outperformance over existing RL methods for discrete and latent reasoning, supported by extensive experiments.
Significance. If the central claims hold, the work would meaningfully advance latent reasoning by making it compatible with RL through controlled stochasticity, addressing a key limitation where latent methods lose exploratory capacity. The unified gradient construction and Gumbel-Softmax adaptation represent a technically interesting bridge between continuous and discrete spaces in policy optimization. Strengths include the explicit focus on restoring exploration without new invented entities and the potential for falsifiable predictions via the reported outperformance.
major comments (2)
- [optimization stage / unified gradient estimation] The unified gradient estimation (described in the optimization stage) applies Gumbel-Softmax reparameterization to continuous latent representations. Gumbel-Softmax is canonically for categorical variables; its direct use here risks temperature-dependent bias that does not necessarily vanish in the policy-gradient estimator when rewards are defined only on discrete token sequences. No explicit bias analysis, variance bound, or stability proof for the combined estimator is provided, which is load-bearing for the claim that LEPO restores exploration without instability.
- [Experiments] The abstract asserts that 'extensive experiments show that LEPO significantly outperforms existing RL methods,' yet supplies no details on baselines, datasets, metrics, ablation studies (e.g., on Gumbel-Softmax temperature), or statistical significance. Without these, the outperformance claim cannot be evaluated and the weakest assumption (stable, unbiased unified estimation) remains untested.
minor comments (1)
- [Method] Notation for the latent representations and the Gumbel-Softmax temperature parameter should be introduced with explicit definitions and ranges before use in the method description.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our work. We address each of the major comments below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [optimization stage / unified gradient estimation] The unified gradient estimation (described in the optimization stage) applies Gumbel-Softmax reparameterization to continuous latent representations. Gumbel-Softmax is canonically for categorical variables; its direct use here risks temperature-dependent bias that does not necessarily vanish in the policy-gradient estimator when rewards are defined only on discrete token sequences. No explicit bias analysis, variance bound, or stability proof for the combined estimator is provided, which is load-bearing for the claim that LEPO restores exploration without instability.
Authors: We appreciate the referee's scrutiny of the unified gradient estimation. In LEPO, Gumbel-Softmax is employed to reparameterize the continuous latent variables, introducing controlled stochasticity that allows diverse sampling while enabling end-to-end gradient flow. This creates a unified estimator applicable to both latent and token levels. We recognize that a dedicated analysis of bias and variance is absent from the current manuscript. Our empirical evaluations indicate stable optimization and effective exploration restoration. In the revised manuscript, we will add a subsection providing bias analysis, including discussion of temperature effects and a sketch of the estimator's properties. revision: yes
-
Referee: [Experiments] The abstract asserts that 'extensive experiments show that LEPO significantly outperforms existing RL methods,' yet supplies no details on baselines, datasets, metrics, ablation studies (e.g., on Gumbel-Softmax temperature), or statistical significance. Without these, the outperformance claim cannot be evaluated and the weakest assumption (stable, unbiased unified estimation) remains untested.
Authors: The full manuscript provides comprehensive details on the experimental setup, including baselines, datasets, metrics, ablation studies on the Gumbel-Softmax temperature, and statistical significance testing, within the Experiments section. To enhance the self-contained nature of the abstract and facilitate quicker evaluation of the claims, we will revise the abstract to incorporate a brief overview of the experimental methodology and key findings. revision: partial
Circularity Check
No significant circularity in LEPO derivation chain
full rationale
The paper's core contribution is the LEPO framework: injecting Gumbel-Softmax for stochasticity in latent reasoning, then applying RL with a unified gradient estimator over latents and tokens. These steps build on standard reparameterization tricks and policy optimization without self-defining the target performance metric in terms of the method itself, without renaming fitted parameters as predictions, and without load-bearing self-citations that reduce the central claim to an unverified prior result by the same authors. The abstract and description present the approach as an extension of existing RL and latent reasoning techniques, with outperformance demonstrated via experiments rather than by construction. No equations or steps reduce the claimed improvement to a tautology or fitted input.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we inject controllable stochasticity into latent reasoning via Gumbel-Softmax... unified gradient estimation for both latent representations and discrete tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to rea- son in a continuous latent space. arXiv preprint arXiv:2412.06769. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Ja- cob Steinhardt. 2021a. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR). Dan Hen...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 oth- ers. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Zhenyi ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
arXiv preprint arXiv:2510.05069
Swireasoning: Switch-thinking in latent and explicit for pareto-superior reasoning llms. arXiv preprint arXiv:2510.05069. Jihoon Tack, Jack Lanchantin, Jane Yu, Andrew Co- hen, Ilia Kulikov, Janice Lan, Shibo Hao, Yuan- dong Tian, Jason Weston, and Xian Li. 2025. Llm pretraining with continuous concepts. arXiv preprint arXiv:2502.08524. Wenhui Tan, Jiaze ...
-
[4]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforce- ment learning system at scale. arXiv preprint arXiv:2503.14476. Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, and Dong Wang. 2025. Hybrid la- tent reasoning via reinforcement learning. arXiv preprint arXiv:2505.18454. Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
The sampling temperatures are set to 1.0 during training and 0.6 for testing
We apply top-p sampling with p= 0.95 and top-k sampling with k= 30 . The sampling temperatures are set to 1.0 during training and 0.6 for testing. All experiments are conducted with 8 Nvidia H20 GPUs. Training takes approx- imately 28 hours for Qwen2.5-7B, and 20 hours for Qwen2.5-3B and Llama-3.2-3B-Instruct. For LEPO, we conduct a grid search over Lg ∈ ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.