Recognition: unknown
CADMAS-CTX: Contextual Capability Calibration for Multi-Agent Delegation
Pith reviewed 2026-05-10 05:27 UTC · model grok-4.3
The pith
Agent capabilities depend on task context, so multi-agent delegation using context-specific Beta posteriors and uncertainty penalties achieves lower regret than static skill profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
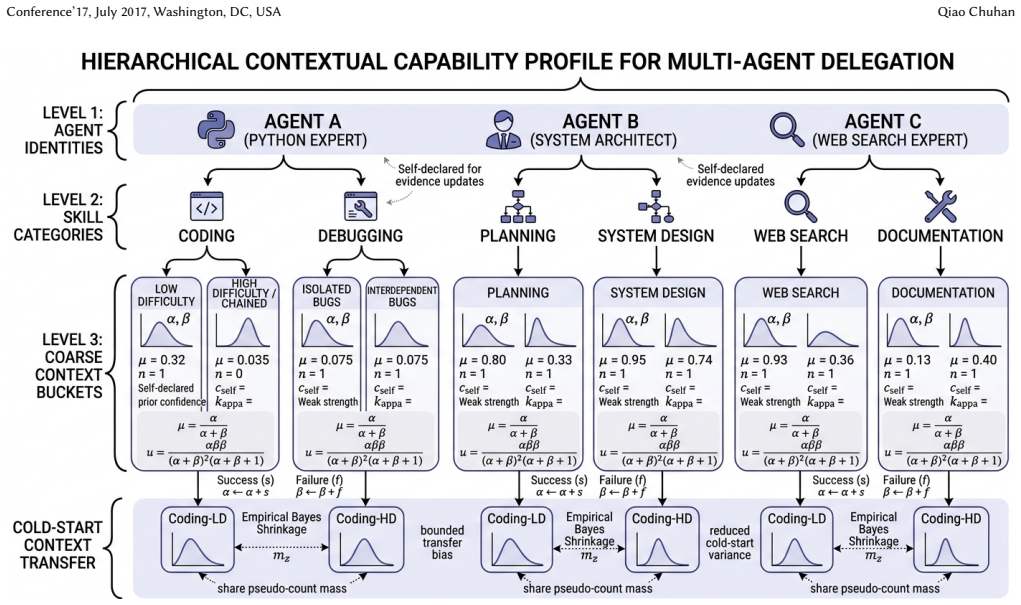
We revisit multi-agent delegation under the assumption that an agent's capability is not fixed but depends on task context. For each agent, skill, and coarse context bucket, CADMAS-CTX maintains a Beta posterior that captures stable experience in that part of the task space. Delegation then uses a risk-aware score that combines the posterior mean with an uncertainty penalty, so agents delegate only when a peer appears better and the assessment is sufficiently supported by evidence. This yields lower cumulative regret than static routing under sufficient context heterogeneity and lifts accuracy on GAIA from 0.381 to 0.442 while raising SWE-bench Lite resolve rate from 22.3% to 31.4%.
What carries the argument
The hierarchical contextual capability profile that maintains a Beta posterior per agent-skill-context bucket and feeds it into a risk-aware delegation score that penalizes high uncertainty.
If this is right
- Context-aware routing achieves lower cumulative regret than static routing under sufficient context heterogeneity.
- On GAIA with GPT-4o agents, accuracy reaches 0.442 with non-overlapping 95% confidence intervals over the static baseline of 0.381.
- On SWE-bench Lite the resolve rate improves from 22.3% to 31.4%.
- The uncertainty penalty increases robustness against noise in context tagging.
Where Pith is reading between the lines
- The same posterior-plus-penalty structure could be applied to human-AI teams where human performance also varies by task type.
- Online updating of the posteriors as new tasks arrive would allow the regret advantage to persist in long-running agent systems.
- Testing whether finer or learned context boundaries tighten the regret bound further would clarify the optimal granularity of buckets.
Load-bearing premise
Coarse context buckets must capture stable patterns in agent performance and context tagging noise must stay low enough for the uncertainty penalty to guide reliable decisions.
What would settle it
If accuracy and regret improvements vanish when all tasks are collapsed into a single context bucket or when context tags are assigned randomly, that would show the gains depend on meaningful context separation.
Figures





read the original abstract
We revisit multi-agent delegation under a stronger and more realistic assumption: an agent's capability is not fixed at the skill level, but depends on task context. A coding agent may excel at short standalone edits yet fail on long-horizon debugging; a planner may perform well on shallow tasks yet degrade on chained dependencies. Static skill-level capability profiles therefore average over heterogeneous situations and can induce systematic misdelegation. We propose CADMAS-CTX, a framework for contextual capability calibration. For each agent, skill, and coarse context bucket, CADMAS-CTX maintains a Beta posterior that captures stable experience in that part of the task space. Delegation is then made by a risk-aware score that combines the posterior mean with an uncertainty penalty, so that agents delegate only when a peer appears better and that assessment is sufficiently well supported by evidence. This paper makes three contributions. First, a hierarchical contextual capability profile replaces static skill-level confidence with context-conditioned posteriors. Second, based on contextual bandit theory, we formally prove context-aware routing achieves lower cumulative regret than static routing under sufficient context heterogeneity, formalizing the bias-variance tradeoff. Third, we empirically validate our method on GAIA and SWE-bench benchmarks. On GAIA with GPT-4o agents, CADMAS-CTX achieves 0.442 accuracy, outperforming static baseline 0.381 and AutoGen 0.354 with non-overlapping 95% confidence intervals. On SWE-bench Lite, it improves resolve rate from 22.3% to 31.4%. Ablations show the uncertainty penalty improves robustness against context tagging noise. Our results demonstrate contextual calibration and risk-aware delegation significantly improve multi-agent teamwork compared with static global skill assignments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CADMAS-CTX for multi-agent delegation, replacing static skill profiles with hierarchical contextual capability profiles that maintain Beta posteriors over coarse context buckets per agent and skill. Delegation uses a risk-aware score combining posterior mean with an uncertainty penalty. It claims a formal proof, based on contextual bandit theory, that context-aware routing yields strictly lower cumulative regret than static routing under sufficient context heterogeneity, plus empirical gains on GAIA (0.442 accuracy vs. 0.381 static and 0.354 AutoGen, non-overlapping 95% CIs) and SWE-bench Lite (31.4% resolve rate vs. 22.3%), with ablations supporting the uncertainty penalty.
Significance. If the central regret bound holds under verifiable conditions and the context buckets are stably defined, the work could meaningfully advance multi-agent systems by formalizing and mitigating context-dependent misdelegation. The reported non-overlapping confidence intervals on public benchmarks and the ablation isolating the uncertainty penalty constitute reproducible empirical strengths that would support adoption if the theoretical precondition is shown to be satisfied.
major comments (2)
- [§3] §3 (Regret Analysis) and Theorem 1: The proof that context-aware routing achieves lower cumulative regret than static routing is conditioned on 'sufficient context heterogeneity,' yet no quantitative measure (e.g., KL divergence, variance threshold, or heterogeneity statistic), no numerical threshold, and no verification that GAIA or SWE-bench satisfy the condition are provided. Without this, the formal guarantee does not demonstrably apply to the reported experiments, undermining attribution of the 0.442 vs. 0.381 accuracy gain to the proven bound.
- [§2.1] §2.1 and §4.1: The central implementation relies on 'coarse context buckets' and context tagging, but the manuscript supplies no explicit definition of the buckets, no tagging procedure or noise model, and no sensitivity analysis showing that tagging errors remain below the level where the uncertainty penalty remains beneficial. This gap directly affects both the empirical claims and the applicability of the Beta-posterior model.
minor comments (2)
- [Figure 2] Figure 2 and Table 1: Axis labels and legend entries for the context-bucket ablation could be clarified to indicate which buckets correspond to which GAIA task categories.
- [§4.3] §4.3: The ablation on uncertainty penalty reports improved robustness but does not include a direct comparison of regret curves with and without the penalty term; adding this would strengthen the link to the theoretical analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and agree to revisions that strengthen the connection between the theoretical results and the experiments as well as the clarity of the implementation details.
read point-by-point responses
-
Referee: [§3] §3 (Regret Analysis) and Theorem 1: The proof that context-aware routing achieves lower cumulative regret than static routing is conditioned on 'sufficient context heterogeneity,' yet no quantitative measure (e.g., KL divergence, variance threshold, or heterogeneity statistic), no numerical threshold, and no verification that GAIA or SWE-bench satisfy the condition are provided. Without this, the formal guarantee does not demonstrably apply to the reported experiments, undermining attribution of the 0.442 vs. 0.381 accuracy gain to the proven bound.
Authors: The theorem in §3 provides a general guarantee from contextual bandit theory that holds under the stated condition of sufficient context heterogeneity; it does not claim the bound applies unconditionally. We acknowledge that the manuscript does not supply a quantitative heterogeneity measure or verify the condition on the specific benchmarks. In the revision we will define a concrete heterogeneity statistic (the average KL divergence between context-specific Beta posteriors and the marginal skill-level posterior) and report its value computed on the GAIA and SWE-bench task distributions to confirm the precondition is satisfied, thereby clarifying the link between the regret bound and the observed accuracy gains. revision: yes
-
Referee: [§2.1] §2.1 and §4.1: The central implementation relies on 'coarse context buckets' and context tagging, but the manuscript supplies no explicit definition of the buckets, no tagging procedure or noise model, and no sensitivity analysis showing that tagging errors remain below the level where the uncertainty penalty remains beneficial. This gap directly affects both the empirical claims and the applicability of the Beta-posterior model.
Authors: We agree that the current manuscript lacks an explicit definition of the coarse context buckets, the tagging procedure, and a noise model. We will revise §2.1 to specify the bucket construction (discretization of task features such as horizon length, dependency depth, and domain type), the automated tagging pipeline used in the experiments, and a simple additive noise model for tagging errors. We will also extend the sensitivity analysis in §4.1 with new results showing the range of tagging-error rates below which the uncertainty penalty continues to improve delegation accuracy, directly addressing applicability of the Beta-posterior model. revision: yes
Circularity Check
No significant circularity; central proof invokes external contextual bandit theory
full rationale
The derivation chain for the regret bound is explicitly grounded in established contextual bandit theory rather than any internal fit, self-definition, or self-citation. The paper states it 'formally prove[s] context-aware routing achieves lower cumulative regret than static routing under sufficient context heterogeneity' by direct reference to that body of work; the heterogeneity condition is an external assumption whose satisfaction is not required to be derived from the paper's own equations. Context-bucket Beta posteriors and the risk-aware score are implementation choices for delegation, not inputs that the proof reduces to by construction. Empirical accuracy numbers on GAIA/SWE-bench are reported separately and do not retroactively define the theoretical claim. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the abstract or described contributions.
Axiom & Free-Parameter Ledger
free parameters (2)
- uncertainty penalty coefficient
- context bucket definitions
axioms (2)
- domain assumption Beta distribution is appropriate for modeling binary success/failure outcomes per context
- ad hoc to paper Context heterogeneity is sufficient for the regret inequality to hold
invented entities (1)
-
CADMAS-CTX contextual capability profile
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. The Claude 3 Model Family: Opus, Sonnet, Haiku.Technical Report(2024)
2024
-
[2]
Lingjiao Chen, Matei Zaharia, and James Zou. 2023. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.arXiv preprint arXiv:2305.05176(2023)
work page internal anchor Pith review arXiv 2023
-
[3]
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. 2023. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors.arXiv preprint arXiv:2308.10848(2023)
-
[4]
Wei Chu, Lihong Li, Lev Reyzin, and Robert Schapire. 2011. Contextual bandits with linear payoff functions.Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics(2011), 208–214
2011
-
[5]
1996.Market-based control: A paradigm for distributed resource allocation
Scott H Clearwater. 1996.Market-based control: A paradigm for distributed resource allocation. World Scientific
1996
-
[6]
Alexander Philip Dawid and Allan M Skene. 1979. Maximum Likelihood Esti- mation of Observer Error-Rates Using the EM Algorithm.Journal of the Royal Statistical Society: Series C (Applied Statistics)28, 1 (1979), 20–28
1979
-
[7]
Hybrid LLM: Cost-efficient and quality-aware query routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V.S. Lakshmanan, and Ahmed Hassan Awadallah. 2024. Hy- brid LLM: Cost-Efficient and Quality-Aware Query Routing.arXiv preprint arXiv:2404.14618(2024)
-
[8]
Abul Ehtesham, Aditi Singh, Gaurav Kumar Gupta, and Saket Kumar. 2025. A Survey of Agent Interoperability Protocols: Model Context Protocol (MCP), Agent Communication Protocol (ACP), Agent-to-Agent Protocol (A2A), and Agent Network Protocol (ANP).arXiv preprint arXiv:2505.02279(2025)
-
[9]
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Ger- rits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. 2024. Magentic-One: A Generalist Multi-Agent System for Solving Complex ...
- [10]
-
[11]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2023. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework.arXiv preprint arXiv:2308.00352(2023)
work page internal anchor Pith review arXiv 2023
- [12]
-
[13]
Trung Dong Huynh, Nicholas R Jennings, and Nigel R Shadbolt. 2006. FIRE: An integrated trust and reputation model for open multi-agent systems.ECAI (2006)
2006
- [14]
-
[15]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?arXiv preprint arXiv:2310.06770(2024)
work page internal anchor Pith review arXiv 2024
-
[16]
Lihong Li, Wei Chu, John Langford, and Robert E Schapire. 2010. A contextual- bandit approach to personalized news article recommendation.Proceedings of the 19th international conference on World wide web(2010), 661–670
2010
-
[17]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. GAIA: A Benchmark for General AI Assistants.arXiv preprint arXiv:2311.12983(2023)
work page internal anchor Pith review arXiv 2023
-
[18]
OpenAI. 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
OpenAI. 2024. OpenAI Swarm: An Ergonomic, Lightweight Multi-Agent Orches- tration Framework.GitHub Repository(2024). https://github.com/openai/swarm
2024
- [20]
-
[21]
Daniel J Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen
-
[22]
A Tutorial on Thompson Sampling.Foundations and Trends in Machine Learning11, 1 (2018), 1–96
2018
-
[23]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face.Advances in Neural Information Processing Systems36 (2023)
2023
-
[24]
Reid G Smith. 1980. The Contract Net Protocol: High-Level Communication and Control in a Distributed Problem Solver.IEEE Trans. Comput.29, 12 (1980), 1104–1113
1980
-
[25]
W Thomas L Teacy, Jigar Patel, Nicholas R Jennings, and Michael Luck. 2006. TRAVOS: Trust and reputation in the context of inaccurate information sources. Autonomous Agents and Multi-Agent Systems12, 2 (2006), 183–198
2006
- [26]
-
[27]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, CADMAS-CTX: Contextual Capability Calibration for Multi-Agent Delegation Conference’17, July 2017, Washington, DC, USA Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [28]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.