Recognition: unknown
MU-GeNeRF: Multi-view Uncertainty-guided Generalizable Neural Radiance Fields for Distractor-aware Scene
Pith reviewed 2026-05-10 05:22 UTC · model grok-4.3
The pith
MU-GeNeRF decomposes uncertainty into source-view and target-view components so generalizable NeRFs can suppress transient distractors without per-scene optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
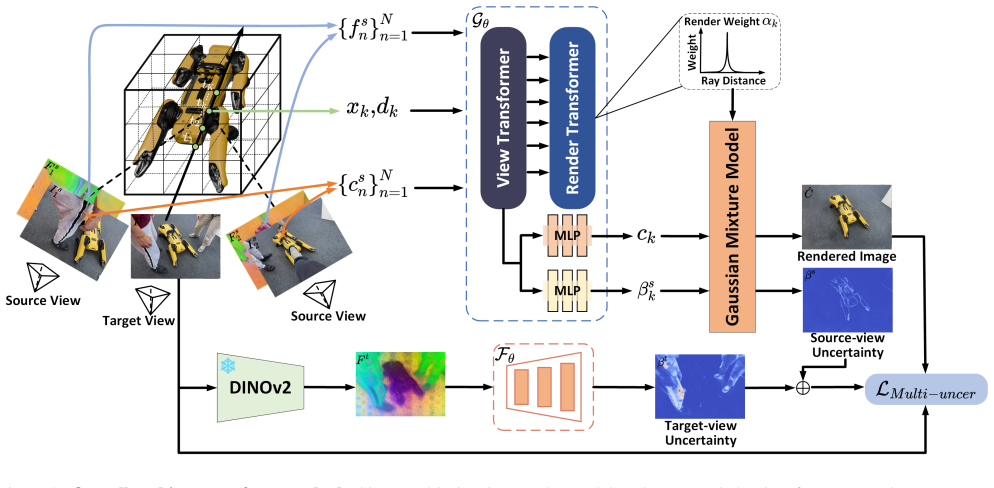
The central claim is that decomposing distractor awareness into source-view uncertainty, which captures structural discrepancies across source views caused by viewpoint changes or dynamic factors, and target-view uncertainty, which detects observation anomalies in the target image induced by transient distractors, allows their combination through a heteroscedastic reconstruction loss to adaptively modulate supervision, enabling more robust distractor suppression and geometric modeling than prior generalizable NeRF approaches.
What carries the argument
The two complementary uncertainty components (source-view discrepancies across inputs and target-view anomalies in the novel view) integrated via the heteroscedastic reconstruction loss that adaptively weights supervision.
If this is right
- The approach surpasses existing generalizable NeRF methods on scenes containing transient objects.
- Reconstruction quality becomes comparable to scene-specific distractor-free NeRFs.
- Geometric modeling improves because supervision is modulated rather than uniformly corrupted.
- Cross-scene generalization remains possible while handling dynamic elements that break consistency.
Where Pith is reading between the lines
- The same uncertainty split could reduce reliance on manual cleaning of training datasets for neural rendering.
- Similar multi-view uncertainty checks might transfer to other tasks that need robust 3D modeling from imperfect image sets.
Load-bearing premise
That the proposed source-view and target-view uncertainties can be computed reliably from reconstruction errors and viewpoint discrepancies without misclassifying consistent static structures as distractors.
What would settle it
A controlled test scene with known static geometry that appears inconsistent across views due only to viewpoint change, where the method degrades reconstruction quality below a baseline GeNeRF that uses no uncertainty weighting.
Figures








read the original abstract
Generalizable Neural Radiance Fields (GeNeRFs) enable high-quality scene reconstruction from sparse views and can generalize to unseen scenes. However, in real-world settings, transient distractors break cross-view structural consistency, corrupting supervision and degrading reconstruction quality. Existing distractor-free NeRF methods rely on per-scene optimization and estimate uncertainty from per-view reconstruction errors, which are not reliable for GeNeRFs and often misjudge inconsistent static structures as distractors. To this end, we propose MU-GeNeRF, a Multi-view Uncertainty-guided distractor-aware GeNeRF framework designed to alleviate GeNeRF's robust modeling challenges in the presence of transient distractions. We decompose distractor awareness into two complementary uncertainty components: Source-view Uncertainty, which captures structural discrepancies across source views caused by viewpoint changes or dynamic factors; and Target-view Uncertainty, which detects observation anomalies in the target image induced by transient distractors.These two uncertainties address distinct error sources and are combined through a heteroscedastic reconstruction loss, which guides the model to adaptively modulate supervision, enabling more robust distractor suppression and geometric modeling.Extensive experiments show that our method not only surpasses existing GeNeRFs but also achieves performance comparable to scene-specific distractor-free NeRFs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MU-GeNeRF, a generalizable NeRF framework that incorporates two uncertainty components—source-view uncertainty capturing structural discrepancies across input views and target-view uncertainty detecting anomalies in the rendered target—to handle transient distractors. These are combined in a heteroscedastic reconstruction loss to adaptively down-weight corrupted supervision. The central claim is that this enables the model to surpass prior GeNeRF methods while matching the quality of per-scene distractor-free NeRFs.
Significance. If the uncertainty estimates can be shown to isolate transient distractors without attenuating supervision on static geometry, the work would meaningfully extend generalizable NeRFs to real-world scenes containing moving objects or occluders. The decomposition into complementary source- and target-view terms is a reasonable response to the limitations of per-scene uncertainty methods when applied to feed-forward architectures.
major comments (3)
- [Abstract] Abstract: the performance claims ('surpasses existing GeNeRFs' and 'achieves performance comparable to scene-specific distractor-free NeRFs') are presented without any quantitative metrics, PSNR/SSIM values, dataset names, or references to tables/figures. This absence prevents evaluation of the magnitude of improvement and is load-bearing for the central contribution.
- [§3] §3 (Method): the source-view uncertainty (structural discrepancies) and target-view uncertainty (observation anomalies) are defined from reconstruction errors and viewpoint differences. Because the model is a feed-forward GeNeRF rather than per-scene optimized, these errors can equally arise from imperfect generalization of the shared weights to the current scene; the manuscript provides no analysis, ablation, or diagnostic to show that the heteroscedastic loss does not suppress valid static content under this regime.
- [§4] §4 (Experiments): no ablation isolating the contribution of each uncertainty term, no comparison of uncertainty maps against ground-truth distractor masks, and no discussion of how reconstruction-error thresholds are chosen or whether they vary with scene complexity. These omissions leave the robustness claims unverified.
minor comments (2)
- [Abstract] The abstract would be strengthened by a single sentence listing the datasets and the key quantitative gains (e.g., average PSNR improvement).
- [§3] Notation for the two uncertainty maps and the combined heteroscedastic loss should be introduced with explicit equations early in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to strengthen the presentation of results, provide additional analysis on uncertainty behavior, and include requested ablations and diagnostics.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims ('surpasses existing GeNeRFs' and 'achieves performance comparable to scene-specific distractor-free NeRFs') are presented without any quantitative metrics, PSNR/SSIM values, dataset names, or references to tables/figures. This absence prevents evaluation of the magnitude of improvement and is load-bearing for the central contribution.
Authors: We agree that the abstract should include concrete quantitative support for the central claims. In the revised manuscript we have updated the abstract to report specific PSNR and SSIM gains on the LLFF and Blender datasets (with references to Tables 1 and 2) while preserving the original length constraints. revision: yes
-
Referee: [§3] §3 (Method): the source-view uncertainty (structural discrepancies) and target-view uncertainty (observation anomalies) are defined from reconstruction errors and viewpoint differences. Because the model is a feed-forward GeNeRF rather than per-scene optimized, these errors can equally arise from imperfect generalization of the shared weights to the current scene; the manuscript provides no analysis, ablation, or diagnostic to show that the heteroscedastic loss does not suppress valid static content under this regime.
Authors: This is a valid concern. While the two uncertainty terms are designed to capture distinct error sources (cross-view structural inconsistency versus target-view anomalies), we acknowledge that the original submission lacked explicit verification that generalization errors are not misclassified as distractors. We have added a new subsection (3.4) with an analysis on static scenes without transients, showing that both uncertainty maps remain low on consistent geometry and that removing the heteroscedastic weighting does not improve (and slightly degrades) reconstruction quality. Corresponding quantitative results and visualizations are now included. revision: yes
-
Referee: [§4] §4 (Experiments): no ablation isolating the contribution of each uncertainty term, no comparison of uncertainty maps against ground-truth distractor masks, and no discussion of how reconstruction-error thresholds are chosen or whether they vary with scene complexity. These omissions leave the robustness claims unverified.
Authors: We agree these elements would strengthen the experimental validation. The revised experiments section now contains (i) an ablation isolating source-view versus target-view uncertainty contributions, (ii) qualitative side-by-side comparisons of predicted uncertainty maps against available ground-truth distractor masks on the synthetic and real distractor datasets, and (iii) a brief discussion clarifying that thresholds are not manually set but emerge from the learned heteroscedastic variance parameters, which adapt per scene without explicit dependence on scene complexity. revision: yes
Circularity Check
No circularity; uncertainty terms are independently computed from input discrepancies
full rationale
The MU-GeNeRF framework introduces source-view structural discrepancy and target-view observation anomaly as two new uncertainty components, each derived directly from measurable reconstruction errors and viewpoint differences in the input views. These feed into a heteroscedastic loss that modulates supervision weights. No equation reduces the claimed distractor suppression or performance gains to a parameter fitted from the target result itself. The method extends prior GeNeRF architectures with these explicit, data-driven terms rather than renaming or self-defining the output. No load-bearing self-citation chains or imported uniqueness theorems appear in the derivation; empirical comparisons to baselines are presented as external validation. This is the normal case of an incremental architectural extension whose central claims remain falsifiable against held-out scenes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Light- ning nerf: Efficient hybrid scene representation for au- tonomous driving
Junyi Cao, Zhichao Li, Naiyan Wang, and Chao Ma. Light- ning nerf: Efficient hybrid scene representation for au- tonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16803–16809. IEEE, 2024. 1
2024
-
[2]
Mvsnerf: Fast general- izable radiance field reconstruction from multi-view stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. Mvsnerf: Fast general- izable radiance field reconstruction from multi-view stereo. InProceedings of the IEEE/CVF international conference on computer vision, pages 14124–14133, 2021. 2
2021
-
[3]
Nerf-hugs: Improved neural radiance fields in non-static scenes using heuristics-guided segmentation
Jiahao Chen, Yipeng Qin, Lingjie Liu, Jiangbo Lu, and Guanbin Li. Nerf-hugs: Improved neural radiance fields in non-static scenes using heuristics-guided segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 19436–19446, 2024. 2
2024
-
[4]
Hallucinated neural radiance fields in the wild
Xingyu Chen, Qi Zhang, Xiaoyu Li, Yue Chen, Ying Feng, Xuan Wang, and Jue Wang. Hallucinated neural radiance fields in the wild. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 12943–12952, 2022. 2
2022
-
[5]
Explicit correspondence matching for generalizable neural radiance fields.IEEE Transactions on Pattern Analysis and Machine Intelligence,
Yuedong Chen, Haofei Xu, Qianyi Wu, Chuanxia Zheng, Tat-Jen Cham, and Jianfei Cai. Explicit correspondence matching for generalizable neural radiance fields.IEEE Transactions on Pattern Analysis and Machine Intelligence,
-
[6]
Stereo radiance fields (srf): Learning view syn- thesis for sparse views of novel scenes
Julian Chibane, Aayush Bansal, Verica Lazova, and Gerard Pons-Moll. Stereo radiance fields (srf): Learning view syn- thesis for sparse views of novel scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7911–7920, 2021. 2
2021
-
[7]
Enhancing nerf akin to enhancing llms: Generalizable nerf transformer with mixture-of-view-experts
Wenyan Cong, Hanxue Liang, Peihao Wang, Zhiwen Fan, Tianlong Chen, Mukund Varma, Yi Wang, and Zhangyang Wang. Enhancing nerf akin to enhancing llms: Generalizable nerf transformer with mixture-of-view-experts. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 3193–3204, 2023. 1
2023
-
[8]
Go-nerf: Generating objects in neural ra- diance fields for virtual reality content creation.IEEE Trans- actions on Visualization and Computer Graphics, 2025
Peng Dai, Feitong Tan, Xin Yu, Yifan Peng, Yinda Zhang, and Xiaojuan Qi. Go-nerf: Generating objects in neural ra- diance fields for virtual reality content creation.IEEE Trans- actions on Visualization and Computer Graphics, 2025. 1
2025
-
[9]
Mohamed Debbagh. Neural radiance fields (nerfs): A review and some recent developments.arXiv preprint arXiv:2305.00375, 2023. 1
-
[10]
Fov-nerf: Foveated neural radiance fields for virtual reality.IEEE Transactions on Visualization and Computer Graphics, 28(11):3854–3864, 2022
Nianchen Deng, Zhenyi He, Jiannan Ye, Budmonde Duinkharjav, Praneeth Chakravarthula, Xubo Yang, and Qi Sun. Fov-nerf: Foveated neural radiance fields for virtual reality.IEEE Transactions on Visualization and Computer Graphics, 28(11):3854–3864, 2022. 1
2022
-
[11]
Learning to render novel views from wide-baseline stereo pairs
Yilun Du, Cameron Smith, Ayush Tewari, and Vincent Sitz- mann. Learning to render novel views from wide-baseline stereo pairs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4970– 4980, 2023. 2
2023
-
[12]
Nerf: Neural radiance field in 3d vision, a comprehensive review,
Kyle Gao, Yina Gao, Hongjie He, Dening Lu, Linlin Xu, and Jonathan Li. Nerf: Neural radiance field in 3d vision, a comprehensive review.arXiv preprint arXiv:2210.00379,
-
[13]
Pc-nerf: Parent-child neural radiance fields using sparse lidar frames in autonomous driv- ing environments.IEEE Transactions on Intelligent Vehicles,
Xiuzhong Hu, Guangming Xiong, Zheng Zang, Peng Jia, Yuxuan Han, and Junyi Ma. Pc-nerf: Parent-child neural radiance fields using sparse lidar frames in autonomous driv- ing environments.IEEE Transactions on Intelligent Vehicles,
-
[14]
Karim Kassab, Antoine Schnepf, Jean-Yves Franceschi, Laurent Caraffa, Jeremie Mary, and Val ´erie Gouet-Brunet. Refinedfields: Radiance fields refinement for unconstrained scenes.arXiv preprint arXiv:2312.00639, 2023. 2
-
[15]
Up- nerf: Unconstrained pose prior-free neural radiance field
Injae Kim, Minhyuk Choi, and Hyunwoo J Kim. Up- nerf: Unconstrained pose prior-free neural radiance field. Advances in Neural Information Processing Systems, 36: 68184–68196, 2023. 2, 6
2023
-
[16]
Jaewon Lee, Injae Kim, Hwan Heo, and Hyunwoo J Kim. Semantic-aware occlusion filtering neural radiance fields in the wild.arXiv preprint arXiv:2303.03966, 2023. 2
-
[17]
Jingliang Li, Qiang Zhou, Chaohui Yu, Zhengda Lu, Jun Xiao, Zhibin Wang, and Fan Wang. Improved neural radi- ance fields using pseudo-depth and fusion.arXiv preprint arXiv:2308.03772, 2023. 1
-
[18]
Nerf-ms: Neural radiance fields with multi-sequence
Peihao Li, Shaohui Wang, Chen Yang, Bingbing Liu, We- ichao Qiu, and Haoqian Wang. Nerf-ms: Neural radiance fields with multi-sequence. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18591– 18600, 2023. 2
2023
-
[19]
Dynibar: Neural dynamic image-based rendering
Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, and Noah Snavely. Dynibar: Neural dynamic image-based rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4273– 4284, 2023. 2
2023
-
[20]
Retr: Modeling rendering via transformer for generalizable neural surface re- construction.Advances in Neural Information Processing Systems, 36:62332–62351, 2023
Yixun Liang, Hao He, and Yingcong Chen. Retr: Modeling rendering via transformer for generalizable neural surface re- construction.Advances in Neural Information Processing Systems, 36:62332–62351, 2023. 4, 6
2023
-
[21]
Uncertainty-aware 3d object-level mapping with deep shape priors
Ziwei Liao, Jun Yang, Jingxing Qian, Angela P Schoellig, and Steven L Waslander. Uncertainty-aware 3d object-level mapping with deep shape priors. In2024 IEEE international conference on robotics and automation (ICRA), pages 4082–
-
[22]
Efficient neural radiance fields for interactive free-viewpoint video
Haotong Lin, Sida Peng, Zhen Xu, Yunzhi Yan, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Efficient neural radiance fields for interactive free-viewpoint video. InSIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022. 1
2022
-
[23]
Robust dynamic radiance fields
Yu-Lun Liu, Chen Gao, Andreas Meuleman, Hung-Yu Tseng, Ayush Saraf, Changil Kim, Yung-Yu Chuang, Jo- hannes Kopf, and Jia-Bin Huang. Robust dynamic radiance fields. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 13–23, 2023. 2
2023
-
[24]
Nerf in the wild: Neural radiance fields for uncon- strained photo collections
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duck- worth. Nerf in the wild: Neural radiance fields for uncon- strained photo collections. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7210–7219, 2021. 1
2021
-
[25]
Ctnerf: Cross-time 9 transformer for dynamic neural radiance field from monocu- lar video.Pattern Recognition, 156:110729, 2024
Xingyu Miao, Yang Bai, Haoran Duan, Fan Wan, Yawen Huang, Yang Long, and Yefeng Zheng. Ctnerf: Cross-time 9 transformer for dynamic neural radiance field from monocu- lar video.Pattern Recognition, 156:110729, 2024. 2
2024
-
[26]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 1
2021
-
[27]
Entangled view-epipolar information aggregation for generalizable neural radiance fields
Zhiyuan Min, Yawei Luo, Wei Yang, Yuesong Wang, and Yi Yang. Entangled view-epipolar information aggregation for generalizable neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4906–4916, 2024. 2
2024
-
[28]
High- fidelity 3d reconstruction via unified nerf-mesh optimization with geometric and color consistency.Pattern Recognition, page 112071, 2025
Rama Bastola Neupane, Kan Li, and Zhuqing Mao. High- fidelity 3d reconstruction via unified nerf-mesh optimization with geometric and color consistency.Pattern Recognition, page 112071, 2025. 1
2025
-
[29]
Cascaded and generalizable neural radiance fields for fast view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):2758–2769, 2023
Phong Nguyen-Ha, Lam Huynh, Esa Rahtu, Jiri Matas, and Janne Heikkil¨a. Cascaded and generalizable neural radiance fields for fast view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):2758–2769, 2023. 2
2023
-
[30]
Colnerf: collaboration for general- izable sparse input neural radiance field
Zhangkai Ni, Peiqi Yang, Wenhan Yang, Hanli Wang, Lin Ma, and Sam Kwong. Colnerf: collaboration for general- izable sparse input neural radiance field. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4325– 4333, 2024. 2
2024
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Ac- tivenerf: Learning where to see with uncertainty estimation
Xuran Pan, Zihang Lai, Shiji Song, and Gao Huang. Ac- tivenerf: Learning where to see with uncertainty estimation. InEuropean Conference on Computer Vision, pages 230–
-
[33]
Urban radiance fields
Konstantinos Rematas, Andrew Liu, Pratul P Srini- vasan, Jonathan T Barron, Andrea Tagliasacchi, Thomas Funkhouser, and Vittorio Ferrari. Urban radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 12932–12942, 2022. 2
2022
-
[34]
Nerf on-the-go: Exploiting uncertainty for distractor-free nerfs in the wild
Weining Ren, Zihan Zhu, Boyang Sun, Jiaqi Chen, Marc Pollefeys, and Songyou Peng. Nerf on-the-go: Exploiting uncertainty for distractor-free nerfs in the wild. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8931–8940, 2024. 1, 2, 6
2024
-
[35]
V olrecon: V olume rendering of signed ray distance functions for generalizable multi-view recon- struction
Yufan Ren, Fangjinhua Wang, Tong Zhang, Marc Pollefeys, and Sabine S¨usstrunk. V olrecon: V olume rendering of signed ray distance functions for generalizable multi-view recon- struction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16685– 16695, 2023. 4
2023
-
[36]
Robustnerf: Ig- noring distractors with robust losses
Sara Sabour, Suhani V ora, Daniel Duckworth, Ivan Krasin, David J Fleet, and Andrea Tagliasacchi. Robustnerf: Ig- noring distractors with robust losses. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20626–20636, 2023. 6
2023
-
[37]
Dynamon: Motion-aware fast and robust camera localization for dy- namic neural radiance fields.IEEE Robotics and Automation Letters, 2024
Nicolas Schischka, Hannah Schieber, Mert Asim Karaoglu, Melih Gorgulu, Florian Gr ¨otzner, Alexander Ladikos, Nas- sir Navab, Daniel Roth, and Benjamin Busam. Dynamon: Motion-aware fast and robust camera localization for dy- namic neural radiance fields.IEEE Robotics and Automation Letters, 2024. 2
2024
-
[38]
Boostmvsnerfs: Boost- ing mvs-based nerfs to generalizable view synthesis in large- scale scenes
Chih-Hai Su, Chih-Yao Hu, Shr-Ruei Tsai, Jie-Ying Lee, Chin-Yang Lin, and Yu-Lun Liu. Boostmvsnerfs: Boost- ing mvs-based nerfs to generalizable view synthesis in large- scale scenes. InACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024. 1
2024
-
[39]
Dyblurf: Dynamic neural radiance fields from blurry monocular video
Huiqiang Sun, Xingyi Li, Liao Shen, Xinyi Ye, Ke Xian, and Zhiguo Cao. Dyblurf: Dynamic neural radiance fields from blurry monocular video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7517–7527, 2024. 2
2024
-
[40]
Neural 3d reconstruction in the wild
Jiaming Sun, Xi Chen, Qianqian Wang, Zhengqi Li, Hadar Averbuch-Elor, Xiaowei Zhou, and Noah Snavely. Neural 3d reconstruction in the wild. InACM SIGGRAPH 2022 conference proceedings, pages 1–9, 2022. 2
2022
-
[41]
Global latent neu- ral rendering
Thomas Tanay and Matteo Maggioni. Global latent neu- ral rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19723– 19733, 2024. 2
2024
-
[42]
Block-nerf: Scalable large scene neural view synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Prad- han, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8248–8258, 2022. 2
2022
-
[43]
Neurad: Neural rendering for autonomous driving
Adam Tonderski, Carl Lindstr ¨om, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. Neurad: Neural rendering for autonomous driving. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14895–14904, 2024. 1
2024
-
[44]
Mega-nerf: Scalable construction of large- scale nerfs for virtual fly-throughs
Haithem Turki, Deva Ramanan, and Mahadev Satya- narayanan. Mega-nerf: Scalable construction of large- scale nerfs for virtual fly-throughs. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12922–12931, 2022. 2
2022
-
[45]
Is attention all that nerf needs?arXiv preprint arXiv:2207.13298, 2022
Peihao Wang, Xuxi Chen, Tianlong Chen, Subhashini Venu- gopalan, Zhangyang Wang, et al. Is attention all that nerf needs?arXiv preprint arXiv:2207.13298, 2022. 2
-
[46]
Ibr- net: Learning multi-view image-based rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibr- net: Learning multi-view image-based rendering. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2021. 2
2021
-
[47]
Ie-nerf: Exploring transient mask inpainting to enhance neural radiance fields in the wild.Neurocomputing, 618:129112, 2025
Shuaixian Wang, Haoran Xu, Yaokun Li, Jiwei Chen, and Guang Tan. Ie-nerf: Exploring transient mask inpainting to enhance neural radiance fields in the wild.Neurocomputing, 618:129112, 2025. 2
2025
-
[48]
Mp-nerf: More refined deblurred neu- ral radiance field for 3d reconstruction of blurred images
Xiaohui Wang, Zhenyu Yin, Feiqing Zhang, Dan Feng, and Zisong Wang. Mp-nerf: More refined deblurred neu- ral radiance field for 3d reconstruction of blurred images. Knowledge-Based Systems, 290:111571, 2024. 1
2024
-
[49]
Golf-nrt: Integrating global context and local geometry 10 for few-shot view synthesis
You Wang, Li Fang, Hao Zhu, Fei Hu, Long Ye, and Zhan Ma. Golf-nrt: Integrating global context and local geometry 10 for few-shot view synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21349– 21359, 2025. 2
2025
-
[50]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
2004
-
[51]
Murf: multi-baseline radiance fields
Haofei Xu, Anpei Chen, Yuedong Chen, Christos Sakaridis, Yulun Zhang, Marc Pollefeys, Andreas Geiger, and Fisher Yu. Murf: multi-baseline radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20041–20050, 2024. 2, 6
2024
-
[52]
Vr-nerf: High- fidelity virtualized walkable spaces
Linning Xu, Vasu Agrawal, William Laney, Tony Garcia, Aayush Bansal, Changil Kim, Samuel Rota Bul `o, Lorenzo Porzi, Peter Kontschieder, Aljaˇz Boˇziˇc, et al. Vr-nerf: High- fidelity virtualized walkable spaces. InSIGGRAPH Asia 2023 Conference Papers, pages 1–12, 2023. 1
2023
-
[53]
Neural visibility field for uncertainty-driven active mapping
Shangjie Xue, Jesse Dill, Pranay Mathur, Frank Dellaert, Panagiotis Tsiotra, and Danfei Xu. Neural visibility field for uncertainty-driven active mapping. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18122–18132, 2024. 4
2024
-
[54]
Contranerf: Gen- eralizable neural radiance fields for synthetic-to-real novel view synthesis via contrastive learning
Hao Yang, Lanqing Hong, Aoxue Li, Tianyang Hu, Zhen- guo Li, Gim Hee Lee, and Liwei Wang. Contranerf: Gen- eralizable neural radiance fields for synthetic-to-real novel view synthesis via contrastive learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16508–16517, 2023. 1
2023
-
[55]
Cross-ray neural radiance fields for novel- view synthesis from unconstrained image collections
Yifan Yang, Shuhai Zhang, Zixiong Huang, Yubing Zhang, and Mingkui Tan. Cross-ray neural radiance fields for novel- view synthesis from unconstrained image collections. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15901–15911, 2023. 2
2023
-
[56]
Neural radiance field-based visual rendering: A comprehensive review,
Mingyuan Yao, Yukang Huo, Yang Ran, Qingbin Tian, Ruifeng Wang, and Haihua Wang. Neural radiance field- based visual rendering: A comprehensive review.arXiv preprint arXiv:2404.00714, 2024. 1
-
[57]
pixelnerf: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4578–4587, 2021. 1
2021
-
[58]
Supernerf: High-precision 3d reconstruction for large-scale scenes.IEEE Transactions on Geoscience and Remote Sens- ing, 2024
Guangyun Zhang, Chaozhong Xue, and Rongting Zhang. Supernerf: High-precision 3d reconstruction for large-scale scenes.IEEE Transactions on Geoscience and Remote Sens- ing, 2024. 1
2024
-
[59]
Dynamic scene understanding through object- centric voxelization and neural rendering.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2025
Yanpeng Zhao, Yiwei Hao, Siyu Gao, Yunbo Wang, and Xi- aokang Yang. Dynamic scene understanding through object- centric voxelization and neural rendering.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2025. 2
2025
-
[60]
Caesarnerf: Calibrated semantic representation for few-shot generalizable neural rendering
Haidong Zhu, Tianyu Ding, Tianyi Chen, Ilya Zharkov, Ram Nevatia, and Luming Liang. Caesarnerf: Calibrated semantic representation for few-shot generalizable neural rendering. InEuropean Conference on Computer Vision, pages 71–89. Springer, 2024. 2 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.