Recognition: unknown
Identifying Ethical Biases in Action Recognition Models
Pith reviewed 2026-05-10 05:11 UTC · model grok-4.3
The pith
Synthetic videos with fixed motion but varied skin color reveal biases in some human action recognition models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
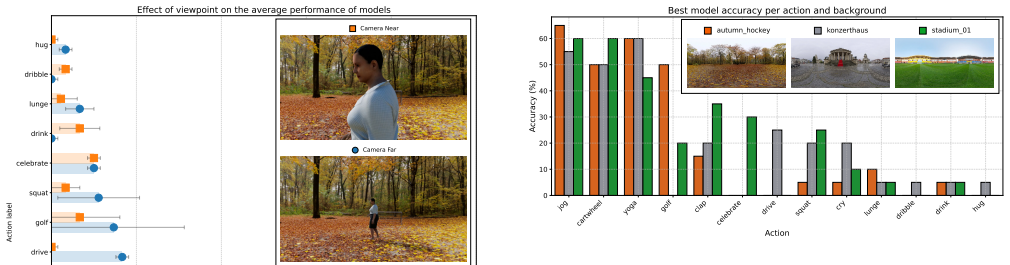
The authors develop a framework that uses synthetic video data with full control over visual identity attributes to audit bias in human action recognition models. By preserving temporal consistency and changing only one attribute at a time, such as skin color, they demonstrate that certain models exhibit statistically significant biases toward skin color despite identical motions. This highlights how models may encode unwanted visual associations and provides evidence of systematic errors across groups.
What carries the argument
A bias auditing framework that generates synthetic videos allowing isolated changes to a single attribute like skin color while keeping motion and temporal structure fixed.
If this is right
- Some popular models produce different outputs for the same action when only skin color varies.
- Models can encode visual associations that lead to systematic errors across appearance groups.
- The auditing approach supplies a practical tool for checking fairness before deployment.
- The findings connect to the need for transparent systems ahead of new regulatory requirements.
Where Pith is reading between the lines
- The same controlled-video method could be applied to check bias on other changeable attributes such as clothing style or body shape.
- Model developers could use repeated tests of this kind to guide retraining that reduces appearance-based errors.
- Extending the approach beyond action recognition might help audit other video-understanding tasks that rely on appearance cues.
Load-bearing premise
The synthetic videos isolate skin color changes without introducing other visual differences or artifacts that could independently affect model predictions.
What would settle it
Testing the same models on real videos that differ only in skin color while matching motion exactly and finding no statistically significant prediction differences would undermine the bias claim.
Figures












read the original abstract
Human Action Recognition (HAR) models are increasingly deployed in high-stakes environments, yet their fairness across different human appearances has not been analyzed. We introduce a framework for auditing bias in HAR models using synthetic video data, generated with full control over visual identity attributes such as skin color. Unlike prior work that focuses on static images or pose estimation, our approach preserves temporal consistency, allowing us to isolate and test how changes to a single attribute affect model predictions. Through controlled interventions using the BEDLAM simulation platform, we show whether some popular HAR models exhibit statistically significant biases on the skin color even when the motion remains identical. Our results highlight how models may encode unwanted visual associations, and we provide evidence of systematic errors across groups. This work contributes a framework for auditing HAR models and supports the development of more transparent, accountable systems in light of upcoming regulatory standards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a framework for auditing biases in Human Action Recognition (HAR) models using synthetic videos from the BEDLAM simulation platform. By performing controlled interventions that change skin color while holding motion and other visual attributes fixed, the authors claim to demonstrate that some popular HAR models exhibit statistically significant biases with respect to skin color.
Significance. If the methodological controls prove valid and the statistical claims are substantiated with full details, this work would offer a useful auditing procedure for fairness in temporal video models, extending prior image-based bias studies and supporting regulatory compliance efforts in computer vision applications.
major comments (2)
- [Methods] Methods section: The central claim requires that skin-color interventions isolate only that attribute. No quantitative validation is described (e.g., non-skin-region histogram equality, pixel-difference maps outside skin areas, or feature-map cosine similarity between paired videos) to confirm that albedo changes do not alter reflectance, cast shadows, or subsurface scattering. Without such checks, any observed prediction shift could arise from rendering artifacts rather than skin-tone bias.
- [Results] Results section: The abstract asserts 'statistically significant biases' yet supplies no information on the specific HAR models evaluated, the number of synthetic videos per condition, the exact statistical tests, p-values, effect sizes, or corrections for multiple comparisons. This information is required to assess whether the reported significance supports the headline claim.
minor comments (1)
- [Abstract] The abstract would be strengthened by including one concrete sentence summarizing the models tested and the magnitude of the observed effects.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects for strengthening the methodological rigor and transparency of our work. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] Methods section: The central claim requires that skin-color interventions isolate only that attribute. No quantitative validation is described (e.g., non-skin-region histogram equality, pixel-difference maps outside skin areas, or feature-map cosine similarity between paired videos) to confirm that albedo changes do not alter reflectance, cast shadows, or subsurface scattering. Without such checks, any observed prediction shift could arise from rendering artifacts rather than skin-tone bias.
Authors: We agree that explicit validation is necessary to confirm the interventions isolate skin color. Although the BEDLAM platform provides independent control over rendering parameters including albedo, we did not include quantitative checks in the original submission. In the revised manuscript, we will add such validations in the Methods section, including non-skin-region histogram equality tests, pixel-difference maps restricted to non-skin areas, and cosine similarity of feature maps between paired videos to demonstrate that changes are limited to skin tone and do not introduce rendering artifacts. revision: yes
-
Referee: [Results] Results section: The abstract asserts 'statistically significant biases' yet supplies no information on the specific HAR models evaluated, the number of synthetic videos per condition, the exact statistical tests, p-values, effect sizes, or corrections for multiple comparisons. This information is required to assess whether the reported significance supports the headline claim.
Authors: We acknowledge that the abstract and results presentation would benefit from greater specificity to allow readers to evaluate the statistical claims. The manuscript describes the overall approach but does not provide the requested granular details. In the revision, we will expand the Results section and abstract to specify the exact HAR models evaluated, the number of synthetic videos generated per condition, the statistical tests used (including p-values, effect sizes, and any multiple-comparison corrections), thereby fully substantiating the reported significance. revision: yes
Circularity Check
No significant circularity; empirical auditing with external simulator
full rationale
The paper presents an empirical auditing framework that generates synthetic videos via the external BEDLAM platform and measures statistical differences in HAR model outputs under controlled attribute interventions. No mathematical derivations, parameter fits, or predictions are claimed; results are obtained by direct evaluation on generated data. The abstract and described method contain no self-citations that bear the central claim, no ansatzes smuggled via prior work, and no renaming of known results as novel organization. The contribution is self-contained against external benchmarks and falsifiable by re-running the interventions on the same or alternative simulators.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic videos from BEDLAM preserve temporal consistency and isolate single visual attributes such as skin color without introducing independent artifacts that affect HAR predictions.
Reference graph
Works this paper leans on
-
[1]
A Review of State-of-the-Art Methodologies and Applications in Action Recognition
Lanfei Zhao et al. “A Review of State-of-the-Art Methodologies and Applications in Action Recognition”. In:Electronics13.23 (2024), p. 4733
2024
-
[2]
LAYING DOWN and INTELLIGENCE ACT. “Proposal for a Regulation of the European Parliament and of the Council laying down harmonised rules on Artificial Intelligence (Artificial Intelligence Act) and amending certain Union legislative acts”. In: (2021). https : / / eur - lex . europa . eu / legal - content/EN/TXT/?uri=CELEX:52021PC0206
2021
-
[3]
The EU AI Act: a summary of its significance and scope
Lilian Edwards. “The EU AI Act: a summary of its significance and scope”. In:Artificial Intelligence (the EU AI Act)1 (2021)
2021
-
[4]
Is appearance free action recognition possible?
Filip Ilic, Thomas Pock, and Richard P Wildes. “Is appearance free action recognition possible?” In: European Conference on Computer Vision. Springer. 2022, pp. 156–173
2022
-
[5]
Predicting actions from static scenes
Tuan-Hung Vu et al. “Predicting actions from static scenes”. In:Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer. 2014, pp. 421–436
2014
-
[6]
Human action recognition without human
Yun He et al. “Human action recognition without human”. In:Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part III 14. Springer. 2016, pp. 11–17
2016
-
[7]
Why can’t i dance in the mall? learning to mitigate scene bias in action recognition
Jinwoo Choi et al. “Why can’t i dance in the mall? learning to mitigate scene bias in action recognition”. In:Advances in Neural Information Processing Systems32 (2019)
2019
-
[8]
Enabling detailed action recognition evaluation through video dataset augmentation
Jihoon Chung, Yu Wu, and Olga Russakovsky. “Enabling detailed action recognition evaluation through video dataset augmentation”. In:Advances in Neural Information Processing Systems35 (2022), pp. 39020–39033
2022
-
[9]
European Union.Charter of Fundamental Rights of the European Union. Dec. 2000.URL: https://www. europarl.europa.eu/charter/pdf/text en.pdf
2000
-
[10]
Gender shades: Intersectional accuracy disparities in commercial gender classification
Joy Buolamwini and Timnit Gebru. “Gender shades: Intersectional accuracy disparities in commercial gender classification”. In:Conference on fairness, accountability and transparency. PMLR. 2018, pp. 77–91
2018
-
[11]
Balanced datasets are not enough: Estimating and mitigating gender bias in deep image representations
Tianlu Wang et al. “Balanced datasets are not enough: Estimating and mitigating gender bias in deep image representations”. In:Proceedings of the IEEE/CVF international conference on computer vision. 2019, pp. 5310–5319
2019
-
[12]
Benchmarking algorithmic bias in face recognition: An experimental approach using synthetic faces and human evaluation
Hao Liang, Pietro Perona, and Guha Balakrishnan. “Benchmarking algorithmic bias in face recognition: An experimental approach using synthetic faces and human evaluation”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, pp. 4977–4987
2023
-
[13]
Are Pose Estimators Ready for the Open World? STAGE: Synthetic Data Generation Toolkit for Auditing 3D Human Pose Estimators
Nikita Kister et al. “Are Pose Estimators Ready for the Open World? STAGE: Synthetic Data Generation Toolkit for Auditing 3D Human Pose Estimators”. In: (2024)
2024
-
[14]
Bedlam: A synthetic dataset of bodies exhibiting detailed lifelike animated motion
Michael J Black et al. “Bedlam: A synthetic dataset of bodies exhibiting detailed lifelike animated motion”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, pp. 8726–8737
2023
-
[15]
Leander Girrbach et al. “A Large Scale Analysis of Gender Biases in Text-to-Image Generative Models”. In:arXiv preprint arXiv:2503.23398(2025)
-
[16]
VisBias: Measuring Explicit and Implicit Social Biases in Vision Language Models
Jen-tse Huang et al. “VisBias: Measuring Explicit and Implicit Social Biases in Vision Language Models”. In:arXiv preprint arXiv:2503.07575(2025)
-
[17]
Revealing the unseen: Benchmarking video action recognition under occlusion
Shresth Grover, Vibhav Vineet, and Yogesh Rawat. “Revealing the unseen: Benchmarking video action recognition under occlusion”. In:Advances in Neural Information Processing Systems36 (2023), pp. 65642–65664
2023
-
[18]
A large-scale robustness analysis of video action recognition models
Madeline Chantry Schiappa et al. “A large-scale robustness analysis of video action recognition models”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023, pp. 14698–14708
2023
-
[19]
Metamorphic Testing for Pose Estimation Systems
Matias Duran et al. “Metamorphic Testing for Pose Estimation Systems”. In:arXiv preprint arXiv:2502.09460(2025)
-
[20]
PulseCheck457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models
Xingrui Wang et al. “PulseCheck457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models”. In:arXiv e-prints(2025), arXiv–2502
2025
-
[21]
Integralaction: Pose-driven feature integration for robust human action recognition in videos
Gyeongsik Moon et al. “Integralaction: Pose-driven feature integration for robust human action recognition in videos”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021, pp. 3339–3348
2021
-
[22]
Viewpoint invariant RGB-D human action recognition
Jain Liu, Naveed Akhtar, and Ajmal Mian. “Viewpoint invariant RGB-D human action recognition”. In: 2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA). IEEE. 2017, pp. 1–8
2017
-
[23]
Human action recognition with video data: research and evaluation challenges
Manoj Ramanathan, Wei-Yun Yau, and Eam Khwang Teoh. “Human action recognition with video data: research and evaluation challenges”. In:IEEE Transactions on Human-Machine Systems 44.5 (2014), pp. 650–663
2014
-
[24]
View-invariant action recognition
Yogesh Singh Rawat and Shruti Vyas. “View-invariant action recognition”. In:Computer Vision: A Reference Guide. Springer, 2021, pp. 1341–1341
2021
-
[25]
Synthetic humans for action recognition from unseen viewpoints
G ¨ul Varol et al. “Synthetic humans for action recognition from unseen viewpoints”. In:International Journal of Computer Vision129.7 (2021), pp. 2264–2287
2021
-
[26]
An overview of the vision-based human action recognition field
Fernando Camarena et al. “An overview of the vision-based human action recognition field”. In: Mathematical and Computational Applications28.2 (2023), p. 61
2023
-
[27]
Revisiting human action recognition: Personalization vs. generalization
Andrea Zunino, Jacopo Cavazza, and Vittorio Murino. “Revisiting human action recognition: Personalization vs. generalization”. In:Image Analysis and Processing-ICIAP 2017: 19th International Conference, Catania, Italy, September 11-15, 2017, Proceedings, Part I 19. Springer. 2017, pp. 469–480
2017
-
[28]
Personalization in human activity recognition
Anna Ferrari et al. “Personalization in human activity recognition”. In:arXiv preprint arXiv:2009.00268 (2020)
-
[29]
https://deepmind.google/models/veo/. 2025
2025
-
[30]
Video generation models as world simulators. 2024
Tim Brooks et al. “Video generation models as world simulators. 2024”. In: 3 (2024). https : / / openai . com / research / video - generation - models - as - world - simulators, p. 1
2024
-
[31]
com / research / introducing-runway-gen-4
2024.URL: https : / / runwayml . com / research / introducing-runway-gen-4
2024
-
[32]
Adam Polyak et al.Movie Gen: A Cast of Media Foundation Models. 2025. arXiv: 2410 . 13720 [cs.CV].URL: https://arxiv.org/abs/2410.13720
work page internal anchor Pith review arXiv 2025
-
[33]
A comprehensive survey of vision-based human action recognition methods
Hong-Bo Zhang et al. “A comprehensive survey of vision-based human action recognition methods”. In: Sensors19.5 (2019), p. 1005
2019
-
[34]
SynthCity: A large scale synthetic point cloud
David Griffiths and Jan Boehm. “SynthCity: A large scale synthetic point cloud”. In:arXiv preprint arXiv:1907.04758(2019)
-
[35]
Taking a closer look at synthesis: Fine-grained attribute analysis for person re-identification
Suncheng Xiang et al. “Taking a closer look at synthesis: Fine-grained attribute analysis for person re-identification”. In:ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 2021, pp. 3765–3769
2021
-
[36]
Fake it till you make it: face analysis in the wild using synthetic data alone
Erroll Wood et al. “Fake it till you make it: face analysis in the wild using synthetic data alone”. In:Proceedings of the IEEE/CVF international conference on computer vision. 2021, pp. 3681–3691
2021
-
[37]
Learning joint reconstruction of hands and manipulated objects
Yana Hasson et al. “Learning joint reconstruction of hands and manipulated objects”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019, pp. 11807–11816
2019
-
[38]
ETRI-activity3D: A large-scale RGB-D dataset for robots to recognize daily activities of the elderly
Jinhyeok Jang et al. “ETRI-activity3D: A large-scale RGB-D dataset for robots to recognize daily activities of the elderly”. In:2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE. 2020, pp. 10990–10997
2020
-
[39]
SMPL: A Skinned Multi-Person Linear Model
Matthew Loper et al. “SMPL: A Skinned Multi-Person Linear Model”. In:ACM Trans. Graphics (Proc. SIGGRAPH Asia)34.6 (Oct. 2015), 248:1–248:16
2015
-
[40]
BABEL: Bodies, action and behavior with english labels
Abhinanda R Punnakkal et al. “BABEL: Bodies, action and behavior with english labels”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021, pp. 722–731
2021
-
[41]
Synthact: Towards generalizable human action recognition based on synthetic data
David Schneider et al. “Synthact: Towards generalizable human action recognition based on synthetic data”. In:2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE. 2024, pp. 13038–13045
2024
-
[42]
2018.URL: https://meshcapade.com/
2018
-
[43]
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Georgios Pavlakos et al. “Expressive Body Capture: 3D Hands, Face, and Body from a Single Image”. In:Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 2019, pp. 10975–10985
2019
-
[44]
AMASS: Archive of Motion Capture as Surface Shapes
Naureen Mahmood et al. “AMASS: Archive of Motion Capture as Surface Shapes”. In:International Conference on Computer Vision. Oct. 2019, pp. 5442–5451
2019
-
[45]
The Kinetics Human Action Video Dataset
Will Kay et al. “The kinetics human action video dataset”. In:arXiv preprint arXiv:1705.06950(2017)
work page internal anchor Pith review arXiv 2017
-
[46]
Slowfast networks for video recognition
Christoph Feichtenhofer et al. “Slowfast networks for video recognition”. In:Proceedings of the IEEE/CVF international conference on computer vision. 2019, pp. 6202–6211
2019
-
[47]
Multiscale vision transformers
Haoqi Fan et al. “Multiscale vision transformers”. In:Proceedings of the IEEE/CVF international conference on computer vision. 2021, pp. 6824–6835
2021
-
[48]
Leveraging temporal contextualization for video action recognition
Minji Kim et al. “Leveraging temporal contextualization for video action recognition”. In:European Conference on Computer Vision. Springer. 2024, pp. 74–91
2024
-
[49]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. “X3d: Expanding architectures for efficient video recognition”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, pp. 203–213
2020
-
[50]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K Soomro. “UCF101: A dataset of 101 human actions classes from videos in the wild”. In:arXiv preprint arXiv:1212.0402(2012)
work page internal anchor Pith review arXiv 2012
-
[51]
Ava: A video dataset of spatio-temporally localized atomic visual actions
Chunhui Gu et al. “Ava: A video dataset of spatio-temporally localized atomic visual actions”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 6047–6056
2018
-
[52]
HMDB: a large video database for human motion recognition
Hildegard Kuehne et al. “HMDB: a large video database for human motion recognition”. In:2011 International conference on computer vision. IEEE. 2011, pp. 2556–2563
2011
-
[53]
The” something something
Raghav Goyal et al. “The” something something” video database for learning and evaluating visual common sense”. In:Proceedings of the IEEE international conference on computer vision. 2017, pp. 5842–5850
2017
-
[54]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron et al. “Activitynet: A large-scale video benchmark for human activity understanding”. In:Proceedings of the ieee conference on computer vision and pattern recognition. 2015, pp. 961–970
2015
-
[55]
Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100
Dima Damen et al. “Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100”. In:International Journal of Computer Vision(2022), pp. 1–23
2022
-
[56]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. “Sentence-bert: Sentence embeddings using siamese bert-networks”. In:arXiv preprint arXiv:1908.10084(2019)
work page internal anchor Pith review arXiv 1908
-
[57]
Human action recognition and prediction: A survey
Yu Kong and Yun Fu. “Human action recognition and prediction: A survey”. In:International Journal of Computer Vision130.5 (2022), pp. 1366–1401
2022
-
[58]
A survey on video action recognition in sports: Datasets, methods and applications
Fei Wu et al. “A survey on video action recognition in sports: Datasets, methods and applications”. In:IEEE Transactions on Multimedia25 (2022), pp. 7943–7966
2022
-
[59]
Human action recognition from various data modalities: A review
Zehua Sun et al. “Human action recognition from various data modalities: A review”. In:IEEE transactions on pattern analysis and machine intelligence45.3 (2022), pp. 3200–3225
2022
-
[60]
Vision-based human activity recognition: a survey
Djamila Romaissa Beddiar et al. “Vision-based human activity recognition: a survey”. In:Multimedia Tools and Applications79.41 (2020), pp. 30509–30555
2020
-
[61]
When to use the B onferroni correction
Richard A Armstrong. “When to use the B onferroni correction”. In:Ophthalmic and physiological optics 34.5 (2014), pp. 502–508. A Models comparison when changing between skin colors Figure 8: Slowfast, differences when changing between skin colors. Figure 9: Mvit, differences when changing between skin colors. Figure 10: TC-clip, differences when changing...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.