Recognition: unknown
MASFuzzer: Fuzz Driver Generation and Adaptive Scheduling via Multidimensional API Sequences
Pith reviewed 2026-05-10 05:06 UTC · model grok-4.3
The pith
MASFuzzer builds multidimensional API sequences from code examples to let LLMs generate fuzz drivers that reach deeper library code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
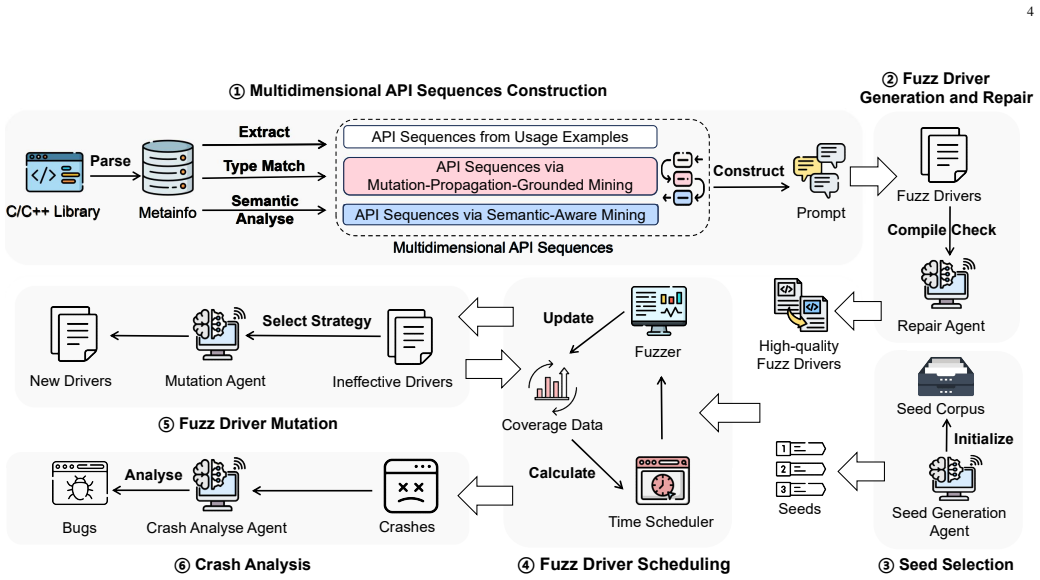
MASFuzzer synthesizes context-relevant API call sequences by referring to API usage examples from the codebase and applying mutation-propagation-based and semantic-aware API sequence mining. These multidimensional API sequences serve as the basis for LLMs to generate effective initial drivers. In addition, MASFuzzer incorporates a coverage-guided scheduler that prioritizes testing time for the most promising drivers, along with a driver mutation strategy to evolve them. This enables systematic generation of fuzz drivers to explore previously untested code regions.
What carries the argument
multidimensional API sequences mined from codebase usage examples via mutation-propagation and semantic-aware methods, which prompt LLMs for driver generation and guide adaptive scheduling
If this is right
- The generated drivers achieve 8.54 percent higher code coverage than state-of-the-art techniques across the evaluated libraries.
- The approach uncovers 16 previously unknown vulnerabilities in well-tested libraries, with 14 confirmed by developers.
- Nine of the discovered issues receive CVE identifiers.
- Adaptive scheduling and driver mutation allow systematic expansion into untested code regions over time.
Where Pith is reading between the lines
- The mining techniques might transfer to generating test cases for other structured interfaces such as REST APIs or device drivers.
- If mining quality varies across codebases with sparse usage examples, the coverage gains would likely diminish.
- Pairing the sequence construction with static analysis could strengthen the relevance of sequences for specific vulnerability classes.
Load-bearing premise
API usage examples extracted from the codebase and mined via mutation-propagation and semantic methods will reliably produce context-relevant sequences that enable LLMs to generate drivers reaching deep, previously untested branches.
What would settle it
An independent run of MASFuzzer against the same 12 libraries that yields code coverage no higher than existing tools or zero new vulnerabilities would falsify the performance claims.
Figures






read the original abstract
Fuzz testing of software libraries relies on fuzz drivers to invoke library APIs. Traditionally, these drivers are written manually by developers - a process that is time-consuming and often inadequate for exercising complex program behaviors. While recent studies have explored the use of Large Language Models (LLMs) to automate fuzz driver generation, the resulting drivers often fail to cover deep program branches. To address these challenges, we propose MASFUZZER, a fuzzing framework that integrates multidimensional API sequence construction with adaptive fuzzing scheduling strategies to improve library testing. At its core, MASFUZZER synthesizes context-relevant API call sequences by referring to API usage examples from the codebase and applying mutation-propagation-based and semantic-aware API sequence mining. These multidimensional API sequences serve as the basis for LLMs to generate effective initial drivers. In addition, MASFUZZER incorporates a coverage-guided scheduler that prioritizes testing time for the most promising drivers, along with a driver mutation strategy to evolve them. This enables systematic generation of fuzz drivers to explore previously untested code regions. We evaluate MASFUZZER on 12 widely used open-source libraries. The results show that MASFUZZER achieves 8.54 percent higher code coverage than state-of-the-art techniques. Moreover, MASFUZZER uncovers 16 previously unknown vulnerabilities in extensively tested libraries, with 14 confirmed by developers and 9 assigned CVE identifiers. These results indicate that MASFUZZER provides an efficient and practical approach for fuzzing software libraries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MASFUZZER, a fuzzing framework that synthesizes context-relevant multidimensional API sequences from codebase usage examples via mutation-propagation and semantic-aware mining; these sequences guide LLMs to generate initial fuzz drivers, which are then evolved via a coverage-guided adaptive scheduler and driver mutation strategy. Evaluated on 12 open-source libraries, it claims 8.54% higher code coverage than state-of-the-art techniques and the discovery of 16 previously unknown vulnerabilities (14 developer-confirmed, 9 with CVEs).
Significance. If the empirical results hold under rigorous validation, the work would meaningfully advance automated library fuzzing by addressing the driver-generation bottleneck and enabling deeper branch coverage without extensive manual effort. The real-world bug findings in mature libraries add practical value, and the integration of mined sequences with adaptive scheduling offers a promising direction for LLM-assisted testing.
major comments (2)
- [Evaluation section] Evaluation section: The headline claim attributes the 8.54% coverage gain and 16 new vulnerabilities specifically to the multidimensional API sequence construction (via mutation-propagation and semantic mining). However, no ablation is reported that holds the coverage-guided scheduler and driver mutation fixed while replacing the mined sequences with random or single-API baselines. Without this isolation, it is impossible to establish that the sequence-mining component is load-bearing for the central claims rather than the scheduler alone driving the gains.
- [Evaluation section] Evaluation section: The reported quantitative improvements lack supporting details on baseline selection criteria, library sampling method, exact coverage measurement (e.g., line/branch coverage tool and granularity), or statistical significance testing for the 8.54% difference. These omissions prevent independent assessment of whether the results support the stated superiority over state-of-the-art techniques.
minor comments (1)
- [Abstract] Abstract: The phrase 'multidimensional API sequences' is used without a concise definition or illustrative example, which would aid reader comprehension before the detailed description in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation section. We address each major comment point by point below and will revise the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The headline claim attributes the 8.54% coverage gain and 16 new vulnerabilities specifically to the multidimensional API sequence construction (via mutation-propagation and semantic mining). However, no ablation is reported that holds the coverage-guided scheduler and driver mutation fixed while replacing the mined sequences with random or single-API baselines. Without this isolation, it is impossible to establish that the sequence-mining component is load-bearing for the central claims rather than the scheduler alone driving the gains.
Authors: We agree that an ablation isolating the multidimensional API sequence construction would provide stronger evidence for its specific contribution. While our main evaluation compares against state-of-the-art techniques that lack this component, we acknowledge the need for an internal controlled comparison. In the revised manuscript, we will add an ablation study that keeps the coverage-guided scheduler and driver mutation strategy fixed and varies only the initial driver generation source (mined multidimensional sequences versus random sequences and single-API baselines). This will quantify the incremental benefit attributable to the sequence-mining step. revision: yes
-
Referee: [Evaluation section] Evaluation section: The reported quantitative improvements lack supporting details on baseline selection criteria, library sampling method, exact coverage measurement (e.g., line/branch coverage tool and granularity), or statistical significance testing for the 8.54% difference. These omissions prevent independent assessment of whether the results support the stated superiority over state-of-the-art techniques.
Authors: We agree that these methodological details are essential for reproducibility and rigorous assessment. In the revised evaluation section, we will explicitly describe the baseline selection criteria (focusing on recent LLM-assisted and sequence-based fuzzing methods), the library sampling approach (12 diverse, widely-used open-source libraries chosen for domain variety and maturity), the coverage measurement process (including the specific tool and whether line/branch coverage is reported at function or statement granularity), and the statistical significance testing applied to the coverage differences (e.g., paired statistical tests with p-values). revision: yes
Circularity Check
No circularity: purely empirical system evaluation
full rationale
The paper presents MASFUZZER as an engineering framework that mines multidimensional API sequences from codebases, feeds them to LLMs for initial driver generation, and applies coverage-guided scheduling plus mutation. All headline results (8.54% coverage lift, 16 new bugs) are obtained by running the complete system on 12 external open-source libraries and comparing against published baselines. No equations, fitted parameters, uniqueness theorems, or self-citation chains appear in the derivation; the evaluation is externally falsifiable and does not reduce any claimed outcome to a re-labeling of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Afl++: Combining incremental steps of fuzzing research,
A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “Afl++: Combining incremental steps of fuzzing research,” in 14th USENIX Workshop on Offensive Technologies (WOOT 20) . USENIX Association, 2020. [Online]. Available: https://www.usenix.org/conference/woot20/present ation/fioraldi
2020
-
[2]
Continuous fuzzing with libfuzzer and addresssanitizer,
K. Serebryany, “Continuous fuzzing with libfuzzer and addresssanitizer,” in IEEE Cybersecurity Development Conference (SecDev) , 2016
2016
-
[3]
Boosting fuzzer efficiency: An information theoretic perspective,
M. B ¨ohme, V . J. M. Man`es, and S. K. Cha, “Boosting fuzzer efficiency: An information theoretic perspective,” in ACM Joint Meeting on Foun- dations of Software Engineering (FSE) . ACM, 2020
2020
-
[4]
The art, science, and engineering of fuzzing: A survey,
V . J. Manes, H. Han, C. Han, S. K. Cha, M. Egele, E. J. Schwartz, and M. Woo, “The art, science, and engineering of fuzzing: A survey,” arXiv preprint arXiv:1812.00140, 2018
-
[5]
Vulnerability detection through machine learning-based fuzzing: A systematic review,
S. B. Chafjiri, P. Legg, J. Hong, and M.-A. Tsompanas, “Vulnerability detection through machine learning-based fuzzing: A systematic review,” Computers & Security , vol. 143, p. 103903, 2024
2024
-
[6]
{FuzzGen}: Auto- matic fuzzer generation,
K. Ispoglou, D. Austin, V . Mohan, and M. Payer, “ {FuzzGen}: Auto- matic fuzzer generation,” in 29th USENIX Security Symposium (USENIX Security 20), 2020, pp. 2271–2287. 13
2020
-
[7]
Afgen: Whole-function fuzzing for applications and libraries,
Y . Liu, Y . Wang, X. Jia, Z. Zhang, and P. Su, “Afgen: Whole-function fuzzing for applications and libraries,” in 2024 IEEE Symposium on Security and Privacy (SP) . IEEE, 2024, pp. 1901–1919
2024
-
[8]
OSS-Fuzz: Google’s continuous fuzzing service for open source software,
K. Serebryany, “OSS-Fuzz: Google’s continuous fuzzing service for open source software,” in USENIX Security Symposium , 2017
2017
-
[9]
Llm4tdg: test- driven generation of large language models based on enhanced constraint reasoning,
J. Liu, R. Liang, X. Zhu, Y . Zhang, Y . Liu, and Q. Liu, “Llm4tdg: test- driven generation of large language models based on enhanced constraint reasoning,” Cybersecurity, vol. 8, no. 1, p. 32, 2025
2025
-
[10]
Utopia: Automatic generation of fuzz driver using unit tests,
B. Jeong, J. Jang, H. Yi, J. Moon, J. Kim, I. Jeon, T. Kim, W. Shim, and Y . H. Hwang, “Utopia: Automatic generation of fuzz driver using unit tests,” in 2023 IEEE Symposium on Security and Privacy (SP) . IEEE, 2023, pp. 2676–2692
2023
-
[11]
Fudge: fuzz driver generation at scale,
D. Babi ´c, S. Bucur, Y . Chen, F. Ivan ˇci´c, T. King, M. Kusano, C. Lemieux, L. Szekeres, and W. Wang, “Fudge: fuzz driver generation at scale,” in Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering , 2019, pp. 975–985
2019
-
[12]
Graphfuzz: Library api fuzzing with lifetime-aware dataflow graphs,
H. Green and T. Avgerinos, “Graphfuzz: Library api fuzzing with lifetime-aware dataflow graphs,” inProceedings of the 44th International Conference on Software Engineering , 2022, pp. 1070–1081
2022
-
[13]
Demystify the fuzzing methods: A compre- hensive survey,
S. Mallissery and Y .-S. Wu, “Demystify the fuzzing methods: A compre- hensive survey,”ACM Computing Surveys, vol. 56, no. 3, pp. 71:1–71:38, 2023
2023
-
[14]
OSS-Fuzz-Gen: Automated Fuzz Target Generation,
D. Liu, O. Chang, J. metzman, M. Sablotny, and M. Maruseac, “OSS-Fuzz-Gen: Automated Fuzz Target Generation,” May 2024. [Online]. Available: https://github.com/google/oss-fuzz-gen
2024
-
[15]
Prompt fuzzing for fuzz driver generation,
Y . Lyu, Y . Xie, P. Chen, and H. Chen, “Prompt fuzzing for fuzz driver generation,” in Proceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security , 2024, pp. 3793–3807
2024
-
[16]
Ckgfuzzer: Llm-based fuzz driver generation enhanced by code knowledge graph,
H. Xu, W. Ma, T. Zhou, Y . Zhao, K. Chen, Q. Hu, Y . Liu, and H. Wang, “Ckgfuzzer: Llm-based fuzz driver generation enhanced by code knowledge graph,” in 2025 IEEE/ACM 47th International Conference on Software Engineering: Companion Proceedings (ICSE- Companion). IEEE, 2025, pp. 243–254
2025
-
[17]
Promefuzz: A knowledge-driven approach to fuzzing harness generation with large language models,
Y . Liu, J. Deng, X. Jia, Y . Wang, M. Wang, L. Huang, T. Wei, and P. Su, “Promefuzz: A knowledge-driven approach to fuzzing harness generation with large language models,” in Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1559–1573. [On...
-
[18]
Liberating libraries through automated fuzz driver generation: Striking a balance without consumer code,
F. Toffalini, N. Badoux, Z. Tsinadze, and M. Payer, “Liberating libraries through automated fuzz driver generation: Striking a balance without consumer code,” Proceedings of the ACM on Software Engineering , vol. 2, no. FSE, pp. 2123–2145, 2025
2025
-
[19]
Fuzzing: Challenges and reflections,
M. B ¨ohme, C. Cadar, and A. Roychoudhury, “Fuzzing: Challenges and reflections,” IEEE Software, vol. 38, no. 3, pp. 79–86, 2020
2020
-
[20]
A systematic review of fuzzing,
X. Zhao, H. Qu, J. Xu, X. Li, W. Lv, and G.-G. Wang, “A systematic review of fuzzing,”Soft Computing, vol. 28, no. 6, pp. 5493–5522, 2024
2024
-
[21]
Dissecting american fuzzy lop: a fuzzbench evaluation,
A. Fioraldi, A. Mantovani, D. Maier, and D. Balzarotti, “Dissecting american fuzzy lop: a fuzzbench evaluation,” ACM transactions on software engineering and methodology , vol. 32, no. 2, pp. 1–26, 2023
2023
-
[22]
Smart greybox fuzzing,
V .-T. Pham, M. B ¨ohme, A. E. Santosa, A. R. C ˘aciulescu, and A. Roy- choudhury, “Smart greybox fuzzing,” IEEE Transactions on Software Engineering, vol. 47, no. 9, pp. 1980–1997, 2019
1980
-
[23]
Superion: Grammar-aware greybox fuzzing,
J. Wang, B. Chen, L. Wei, and Y . Liu, “Superion: Grammar-aware greybox fuzzing,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE) . IEEE, 2019, pp. 724–735
2019
-
[24]
Libfuzzer — a library for coverage-guided fuzz testing,
LLVM Project, “Libfuzzer — a library for coverage-guided fuzz testing,” https://llvm.org/docs/LibFuzzer.html, accessed: 2026-03-29
2026
-
[25]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al. , “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez et al. , “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950 , 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Towards reliable llm-driven fuzz testing: Vision and road ahead,
Y . Cheng, H. J. Kang, L. K. Shar, C. Dong, Z. Shi, S. Lv, and L. Sun, “Towards reliable llm-driven fuzz testing: Vision and road ahead,” arXiv preprint arXiv:2503.00795, 2025
-
[29]
A review on code generation with llms: Application and evaluation,
J. Wang and Y . Chen, “A review on code generation with llms: Application and evaluation,” in 2023 IEEE International Conference on Medical Artificial Intelligence (MedAI) . IEEE, 2023, pp. 284–289
2023
-
[30]
Using large language models to generate junit tests: An empirical study,
M. L. Siddiq, J. C. Da Silva Santos, R. H. Tanvir, N. Ulfat, F. Al Rifat, and V . Carvalho Lopes, “Using large language models to generate junit tests: An empirical study,” in Proceedings of the 28th international conference on evaluation and assessment in software engineering , 2024, pp. 313–322
2024
-
[31]
An empirical evaluation of using large language models for automated unit test generation,
M. Sch ¨afer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,” IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85–105, 2024
2024
-
[32]
Can llm generate regression tests for software commits?
J. Liu, S. Lee, E. Losiouk, and M. B ¨ohme, “Can llm generate regression tests for software commits?” arXiv preprint arXiv:2501.11086 , 2025
-
[33]
arXiv preprint arXiv:2304.00385 , year=
C. S. Xia and L. Zhang, “Keep the conversation going: Fixing 162 out of 337 bugs for $0.42 each using chatgpt,” arXiv preprint arXiv:2304.00385, 2023
-
[34]
Fuzz4all: Universal fuzzing with large language models,
C. S. Xia, M. Paltenghi, J. L. Tian, M. Pradel, and L. Zhang, “Fuzz4all: Universal fuzzing with large language models,” in Proceedings of the 46th IEEE/ACM International Conference on Software Engineering , 2024, pp. 126:1–126:13
2024
-
[35]
Large language model guided protocol fuzzing,
R. Meng, M. Mirchev, M. B ¨ohme, and A. Roychoudhury, “Large language model guided protocol fuzzing,” in Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS) , vol. 2024, 2024
2024
-
[36]
Augmenting greybox fuzzing with generative AI,
J. Hu, Q. Zhang, and H. Yin, “Augmenting greybox fuzzing with generative ai,” arXiv preprint arXiv:2306.06782 , 2023
-
[37]
Fuzzing javascript interpreters with coverage-guided reinforcement learning for llm-based mutation,
J. Eom, S. Jeong, and T. Kwon, “Fuzzing javascript interpreters with coverage-guided reinforcement learning for llm-based mutation,” in Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis , 2024, pp. 1656–1668
2024
-
[38]
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,
Y . Deng, C. S. Xia, H. Peng, C. Yang, and L. Zhang, “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,” in Proceedings of the 32nd ACM SIGSOFT interna- tional symposium on software testing and analysis , 2023, pp. 423–435
2023
-
[39]
Hopper: Interpretative fuzzing for libraries,
P. Chen, Y . Xie, Y . Lyu, Y . Wang, and H. Chen, “Hopper: Interpretative fuzzing for libraries,” in Proceedings of the 2023 ACM SIGSAC Confer- ence on Computer and Communications Security , 2023, pp. 1600–1614
2023
-
[40]
Fuzzing: A survey for roadmap,
X. Zhu, S. Wen, S. Camtepe, and Y . Xiang, “Fuzzing: A survey for roadmap,” ACM Computing Surveys (CSUR), vol. 54, no. 11s, pp. 1–36, 2022
2022
-
[41]
Coverage-based grey- box fuzzing as markov chain,
M. B ¨ohme, V .-T. Pham, and A. Roychoudhury, “Coverage-based grey- box fuzzing as markov chain,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , 2016, pp. 1032–1043
2016
-
[42]
G. Sherman and S. Nagy, “No harness, no problem: Oracle-guided harnessing for auto-generating c api fuzzing harnesses,” in 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 2025, pp. 165–177. [Online]. Available: https://doi.org/10.1109/ICSE55347.2025.00239
-
[43]
Evaluating fuzz testing,
G. Klees, A. Ruef, B. Cooper, S. Wei, and M. Hicks, “Evaluating fuzz testing,” in Proceedings of the 2018 ACM SIGSAC conference on computer and communications security , 2018, pp. 2123–2138
2018
-
[44]
Sok: From systematization to best practices in fuzz driver generation,
Q. Yan, M. Huang, H. Cao, and S. Lu, “Sok: From systematization to best practices in fuzz driver generation,” in Australasian Conference on Information Security and Privacy . Springer, 2025, pp. 348–368
2025
-
[45]
Rumono: Fuzz driver synthesis for rust generic apis,
Y . Zhang, J. Wu, and H. Xu, “Rumono: Fuzz driver synthesis for rust generic apis,” ACM Transactions on Software Engineering and Methodology, vol. 34, no. 6, pp. 169:1–169:28, 2025
2025
-
[46]
Rulf: Rust library fuzzing via api dependency graph traversal,
J. Jiang, H. Xu, and Y . Zhou, “Rulf: Rust library fuzzing via api dependency graph traversal,” in 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE) . IEEE, 2021, pp. 581–592
2021
-
[47]
Rimfuzz: real-time impact-aware mutation for library api fuzzing,
X. Wang and L. Zhao, “Rimfuzz: real-time impact-aware mutation for library api fuzzing,” Journal of King Saud University Computer and Information Sciences, vol. 37, no. 4, p. 52, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.