Recognition: no theorem link
Architecture Matters More Than Scale: A Comparative Study of Retrieval and Memory Augmentation for Financial QA Under SME Compute Constraints
Pith reviewed 2026-05-12 01:51 UTC · model grok-4.3
The pith
Structured memory raises precision on exact financial calculations while retrieval methods win on conversational questions, using the same 8B model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
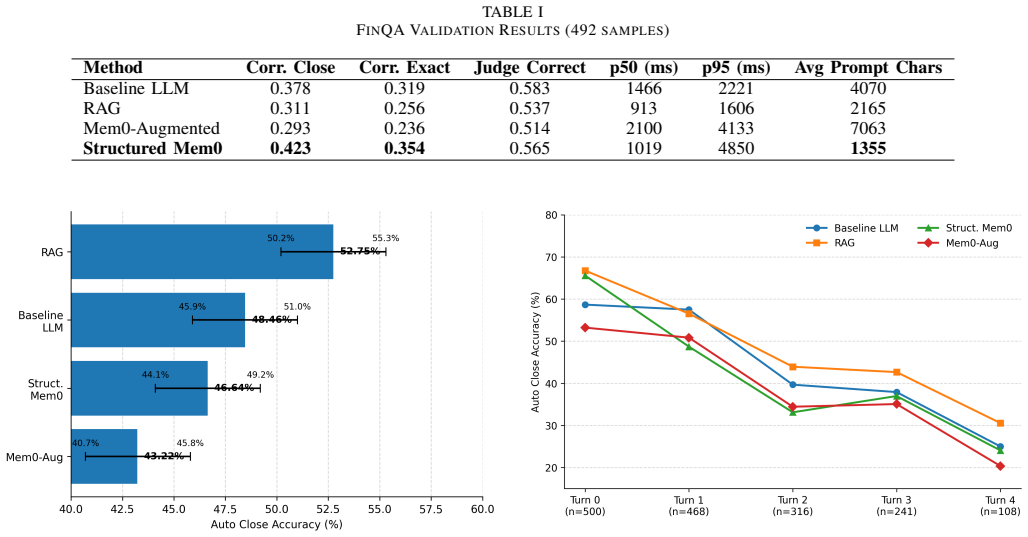
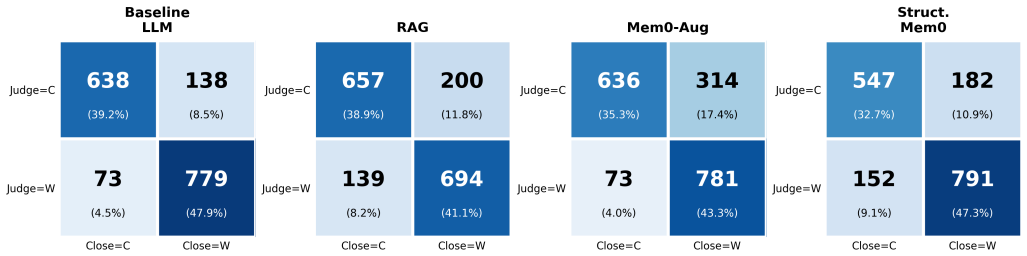
Experiments on FinQA and ConvFinQA show a consistent architectural inversion: structured memory improves precision in deterministic, operand-explicit tasks, while retrieval-based approaches outperform memory-centric methods in conversational, reference-implicit settings.
What carries the argument
The direct head-to-head comparison of retrieval-augmented generation against structured memory under fixed 8B-model and SME infrastructure constraints, which isolates architecture effects from scale.
If this is right
- A hybrid router that selects memory for operand-explicit queries and retrieval for conversational ones can raise end-to-end accuracy without any increase in model size.
- SMEs can achieve usable financial QA on local hardware by matching architecture to query type rather than scaling model parameters.
- Audit trails become easier to maintain when memory is reserved for numerical tasks whose reasoning steps are stored explicitly.
- Overall infrastructure cost stays bounded because every method runs on the identical 8B model.
Where Pith is reading between the lines
- The same task-type split may appear in legal or medical QA where exact extraction competes with contextual reference.
- Query features such as presence of numbers or pronouns could be used to train an automatic router between the two strategies.
- Regulatory audits might still prefer memory architectures even when retrieval scores higher on raw accuracy.
Load-bearing premise
The performance patterns observed on these two benchmarks with the 8B model will generalize to real-world SME financial workflows, other model scales, and production compliance requirements.
What would settle it
Re-running the four architectures on a new financial dataset or with a different model size and finding that the same task-type inversion disappears or reverses.
Figures


read the original abstract
The rapid adoption of artificial intelligence (AI) and large language models (LLMs) is transforming financial analytics by enabling natural language interfaces for reporting, decision support, and automated reasoning. However, limited empirical understanding exists regarding how different LLM-based reasoning architectures perform across realistic financial workflows, particularly under the cost, accuracy, and compliance constraints faced by small and medium-sized enterprises (SMEs). SMEs typically operate within severe infrastructure constraints, lacking cloud GPU budgets, dedicated AI teams, and API-scale inference capacity, making architectural efficiency a first-class concern. To ensure practical relevance, we introduce an explicit SME-constrained evaluation setting in which all experiments are conducted using a locally hosted 8B-parameter instruction-tuned model without cloud-scale infrastructure. This design isolates the impact of architectural choices within a realistic deployment environment. We systematically compare four reasoning architectures: baseline LLM, retrieval-augmented generation (RAG), structured long-term memory, and memory-augmented conversational reasoning across both FinQA and ConvFinQA benchmarks. Results reveal a consistent architectural inversion: structured memory improves precision in deterministic, operand-explicit tasks, while retrieval-based approaches outperform memory-centric methods in conversational, reference-implicit settings. Based on these findings, we propose a hybrid deployment framework that dynamically selects reasoning strategies to balance numerical accuracy, auditability, and infrastructure efficiency, providing a practical pathway for financial AI adoption in resource-constrained environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares four reasoning architectures—baseline LLM, RAG, structured long-term memory, and memory-augmented conversational reasoning—for financial question answering on the FinQA and ConvFinQA benchmarks. All experiments are performed with a locally hosted 8B-parameter instruction-tuned model to simulate SME constraints. The key finding is an architectural inversion: structured memory improves precision on deterministic, operand-explicit tasks (FinQA), while retrieval-based approaches perform better in conversational, reference-implicit settings (ConvFinQA). A hybrid deployment framework is proposed to dynamically select strategies based on task type.
Significance. The work addresses a practical gap in understanding LLM architectures for financial analytics under resource constraints typical of SMEs. The explicit focus on local 8B model deployment and the identification of task-dependent architectural preferences could inform deployment decisions if the results are robustly supported by detailed metrics and statistical analysis. The SME-constrained evaluation setting is a positive design choice, but the absence of any scale variation means the title's claim that architecture matters more than scale remains untested.
major comments (2)
- [Abstract] Abstract: The abstract states that 'results reveal a consistent architectural inversion' and proposes a hybrid framework, but supplies no metrics, error bars, statistical tests, dataset sizes, splits, or exclusion criteria. Full experimental details and quantitative results are required to assess whether the data supports the inversion claim.
- [Title and Abstract] Title and Abstract: The title asserts 'Architecture Matters More Than Scale' and the abstract positions the work as isolating architectural impact under SME constraints, yet every experiment fixes the model at exactly 8B parameters with no ablations on parameter count, no 3B/13B/70B baselines, and no scaling curves. Architectural deltas are therefore never compared against scale-induced deltas on the same tasks, so the central comparative claim is not substantiated by the reported data.
minor comments (2)
- [Abstract] The abstract mentions systematic comparison of four architectures but does not specify exact implementations, retrieval corpus details, memory structure, or hyperparameters for each variant.
- No discussion of statistical significance testing or variance across runs is mentioned, which is needed to support claims of consistent inversion across benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'results reveal a consistent architectural inversion' and proposes a hybrid framework, but supplies no metrics, error bars, statistical tests, dataset sizes, splits, or exclusion criteria. Full experimental details and quantitative results are required to assess whether the data supports the inversion claim.
Authors: We agree that the abstract should provide sufficient quantitative context to support the inversion claim. In the revised manuscript, we will expand the abstract to include key performance metrics for each architecture on both benchmarks, dataset sizes and splits, and a concise description of the evaluation protocol. Full details on error bars, statistical tests, and exclusion criteria remain in the experimental sections, but the abstract will now allow readers to assess the claims without immediate reference to the full text. revision: yes
-
Referee: [Title and Abstract] Title and Abstract: The title asserts 'Architecture Matters More Than Scale' and the abstract positions the work as isolating architectural impact under SME constraints, yet every experiment fixes the model at exactly 8B parameters with no ablations on parameter count, no 3B/13B/70B baselines, and no scaling curves. Architectural deltas are therefore never compared against scale-induced deltas on the same tasks, so the central comparative claim is not substantiated by the reported data.
Authors: We acknowledge that the experiments are conducted exclusively at the 8B scale to emulate SME constraints and do not include direct ablations across model sizes or scaling curves. The title phrasing was chosen to emphasize the practical priority of architectural decisions when scale increases are infeasible, but we recognize that it risks implying a comparative analysis against scale that is not present in the data. To correct this, we will revise the title to 'Architecture Matters for Financial QA Under SME Compute Constraints: A Comparative Study of Retrieval and Memory Augmentation' and update the abstract and introduction to explicitly limit the scope to architectural effects at fixed SME-scale compute, without claiming superiority over scale variations. revision: yes
Circularity Check
No circularity: purely empirical benchmark comparison with no derivations or self-referential reductions
full rationale
The paper conducts a direct empirical comparison of four reasoning architectures (baseline LLM, RAG, structured memory, memory-augmented) on the external FinQA and ConvFinQA benchmarks using a fixed 8B model under SME constraints. No equations, fitted parameters, predictions, or first-principles derivations are present in the abstract or described methodology. The reported architectural inversion is a measured outcome on standard benchmarks rather than a quantity defined in terms of itself or forced by self-citation chains. The analysis is self-contained against external benchmarks with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FinQA and ConvFinQA benchmarks adequately represent real financial QA tasks and workflows under SME constraints
Reference graph
Works this paper leans on
-
[1]
Small and medium enterprises (smes) finance,
World Bank, “Small and medium enterprises (smes) finance,” World Bank Group, 2020
work page 2020
-
[2]
Financing smes and entrepreneurs 2021: An oecd scoreboard,
OECD, “Financing smes and entrepreneurs 2021: An oecd scoreboard,” OECD Publishing, 2021
work page 2021
-
[3]
S. H. Penman,Financial statement analysis and security valuation, 5th ed. McGraw-Hill, 2013
work page 2013
-
[4]
Capital markets research in accounting,
S. P. Kothari, “Capital markets research in accounting,”Journal of Accounting and Economics, vol. 31, no. 1–3, pp. 105–231, 2001
work page 2001
-
[5]
M. S. Fridson and F. Alvarez,Financial statement analysis: A practi- tioner’s guide, 4th ed. Wiley, 2011
work page 2011
-
[6]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, and P. Dhari- wal, “Language models are few-shot learners,” inProc. NeurIPS, 2020, pp. 1877–1901
work page 2020
-
[7]
OpenAI, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, and H. Jun, “Training ver- ifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Finqa: A dataset of numerical reasoning over financial data,
Z. Chenet al., “Finqa: A dataset of numerical reasoning over financial data,” inProc. EMNLP, 2021, pp. 3368–3380
work page 2021
-
[10]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktuset al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” inProc. NeurIPS, 2020, pp. 9459–9474
work page 2020
-
[11]
Few-shot learning with retrieval augmented language models,
G. Izacard and E. Grave, “Few-shot learning with retrieval augmented language models,” inProc. NeurIPS, 2022
work page 2022
-
[12]
Large language model is semi-parametric reinforcement learning agent
W. Chenet al., “Memory: Enhancing large language models with memory,”arXiv preprint arXiv:2306.07929, 2023
-
[13]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, “Mem0: Building production-ready ai agents with scalable long-term memory,” arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Convfinqa: Exploring the chain of numerical reasoning in conversational finance qa,
Z. Chenet al., “Convfinqa: Exploring the chain of numerical reasoning in conversational finance qa,” inProc. ACL, 2022, pp. 6279–6292
work page 2022
-
[15]
Financebench: A new benchmark for financial question answering.arXiv preprint arXiv:2311.11944, 2023
P. Islam, A. Kannappan, D. Kiela, R. Qian, N. Scherrer, and B. Vidgen, “Financebench: A new benchmark for financial question answering,” arXiv preprint arXiv:2311.11944, 2023
-
[16]
Finben: A holistic financial benchmark for large language models,
Q. Xieet al., “Finben: A holistic financial benchmark for large language models,” inProc. NeurIPS Datasets and Benchmarks Track, 2024
work page 2024
-
[17]
W. Chenet al., “Program of thoughts prompting: Disentangling compu- tation from reasoning for numerical reasoning tasks,”Transactions on Machine Learning Research, 2023
work page 2023
-
[18]
Financial report chunking for effective retrieval augmented generation,
A. J. Yepes, Y . You, J. Milczek, S. Laverde, and R. Liu, “Financial report chunking for effective retrieval augmented generation,”arXiv preprint arXiv:2402.05131, 2024
-
[19]
Major entity identification: A generalizable alternative to coreference resolution,
K. Manikantan, S. Toshniwal, M. Tapaswi, and V . Gandhi, “Major entity identification: A generalizable alternative to coreference resolution,” in Proc. EMNLP, 2024, pp. 11 679–11 695. APPENDIX Supplementary Figures Fig. A1.FinQA corrected accuracy by question type. Performance is reported separately for percentage-based and non-percentage questions across...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.