Recognition: unknown
RASP-Tuner: Retrieval-Augmented Soft Prompts for Context-Aware Black-Box Optimization in Non-Stationary Environments
Pith reviewed 2026-05-10 04:41 UTC · model grok-4.3
The pith
RASP-Tuner retrieves similar past contexts to supply soft prompts that let a mixture-of-experts surrogate adapt black-box tuning to non-stationary regimes at low per-step cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RASP-Tuner instantiates a first-principles decomposition for context-aware black-box optimization: (i) identify the active regime by nearest-neighbor retrieval of past contexts, (ii) predict short-horizon loss with a mixture-of-experts surrogate whose input is the concatenation of parameters, context, and a retrieved soft prompt, and (iii) adapt chiefly inside the prompt subspace, invoking expensive full surrogate refits only when scalarized prediction error or expert disagreement exceeds a threshold. The RealErrorComposer supplies a differentiable training target by mapping heterogeneous metrics to [0,1] via EMA-stabilized logistic scores. Under an idealized RA-GD analysis in a cluster-sepa
What carries the argument
Retrieval-augmented soft prompt: a low-dimensional vector retrieved from similar past contexts that is concatenated to the surrogate input and becomes the primary subspace for online adaptation.
If this is right
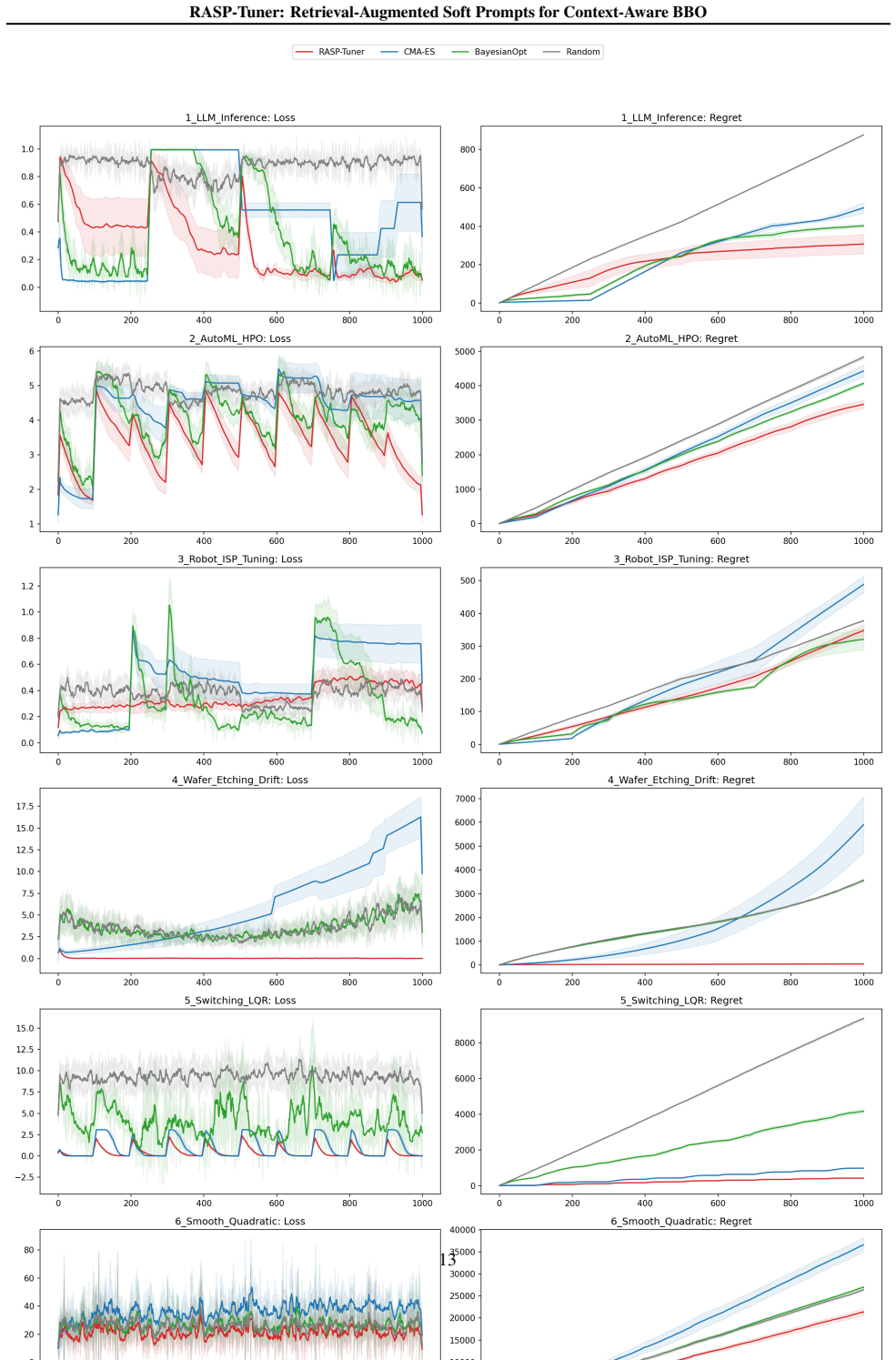
- On nine synthetic benchmarks at T=100 the method improves or matches paired-test regret against GP-UCB and CMA-ES on seven tasks.
- Wall-clock time per step is 8-12 times lower than sliding-window GP-UCB on the same hardware.
- The RA-GD analysis gives sufficient conditions for bounded dynamic regret when regimes are cluster-separated and strongly convex.
- The RealErrorComposer produces a single differentiable target from any collection of heterogeneous streaming metrics.
Where Pith is reading between the lines
- The same retrieval-plus-soft-prompt pattern could be inserted into other online optimizers that already maintain a low-dimensional adaptation subspace.
- If context similarity can be computed incrementally, the approach may extend to continuous or slowly drifting context spaces without requiring an explicit regime count.
- The error-spike trigger for full updates offers a general way to trade off surrogate fidelity against compute in any streaming surrogate-based optimizer.
Load-bearing premise
Contexts revisit a small set of latent regimes so that retrieving similar past contexts reliably supplies useful soft prompts.
What would settle it
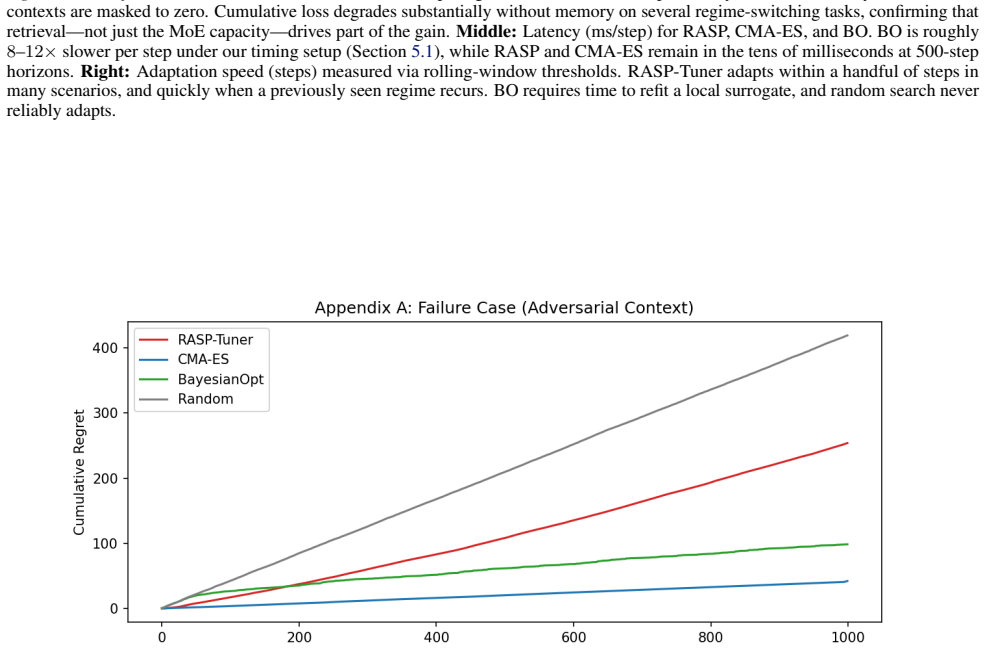
Run the method on a stream whose contexts are all distinct and never repeat; if cumulative regret then equals that of a non-retrieval baseline, the retrieval premise does not hold.
Figures



read the original abstract
Many deployed systems expose black-box objectives whose minimizing configuration shifts with an externally observed context. When contexts revisit a small set of latent regimes, an optimizer that discards history pays repeated adaptation cost; when each step must remain inexpensive, full Gaussian-process (GP) refits at high observation counts are difficult to sustain. We cast online tuning as context-conditioned regret minimization and present RASP-Tuner, which instantiates a decomposition motivated by first principles: (i) identify a regime proxy by retrieving similar past contexts; (ii) predict short-horizon loss with a mixture-of-experts surrogate whose input concatenates parameters, context, and a retrieved soft prompt; (iii) adapt chiefly in a low-dimensional prompt subspace, invoking full surrogate updates only when scalarized error or disagreement spikes. A RealErrorComposer maps heterogeneous streaming metrics to [0,1] via EMA-stabilized logistic scores, supplying a single differentiable training target. On nine synthetic non-stationary benchmarks, an adversarial-context sanity check, and three tabular real-world streams (Section on real-world experiments), RASP-Tuner improves or matches cumulative regret relative to our GP-UCB and CMA-ES implementations on seven of nine synthetic tasks under paired tests at horizon T=100, while recording 8-12 times lower wall-clock per step than sliding-window GP-UCB on identical hardware. Idealized analysis in a cluster-separated, strongly convex regime model (RA-GD) supplies sufficient conditions for bounded dynamic regret; the deployed pipeline violates several of these premises, and we articulate which gaps remain open.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RASP-Tuner for context-aware black-box optimization in non-stationary environments. It retrieves similar past contexts to supply soft prompts to a mixture-of-experts surrogate (input concatenates parameters, context, and prompt), adapts primarily in the low-dimensional prompt subspace, triggers full surrogate updates only on error or disagreement spikes, and uses a RealErrorComposer (EMA-stabilized logistic scores) to map heterogeneous metrics to a [0,1] differentiable target. On nine synthetic non-stationary benchmarks plus an adversarial-context check and three real tabular streams, it improves or matches cumulative regret versus GP-UCB and CMA-ES on seven of nine tasks under paired tests at horizon T=100 while achieving 8-12x lower wall-clock time per step than sliding-window GP-UCB. An idealized RA-GD analysis in a cluster-separated strongly convex regime supplies sufficient conditions for bounded dynamic regret, but the authors explicitly note that the deployed pipeline violates several of those premises and articulate the remaining gaps.
Significance. If the empirical improvements are robust and the method can be placed on firmer theoretical footing, RASP-Tuner would offer a practical, low-cost alternative to repeated full GP refits for online tuning tasks where contexts recur across a small number of latent regimes. The computational savings and the honest acknowledgment of analysis gaps are strengths, but the absence of a regret bound that covers the implemented algorithm limits the significance of the theoretical contribution.
major comments (1)
- [Abstract and RA-GD analysis] Abstract and RA-GD analysis section: the idealized RA-GD model supplies sufficient conditions for bounded dynamic regret under cluster-separated, strongly convex regimes, yet the deployed pipeline (retrieval + mixture-of-experts surrogate + prompt-subspace adaptation + RealErrorComposer) is stated to violate several of those premises. No alternative regret analysis is supplied for the actual algorithm, so the central claim that RASP-Tuner improves or matches regret on seven of nine tasks lacks theoretical grounding that would explain why the method succeeds when the analyzed conditions fail. This gap is load-bearing for the paper's positioning as a principled context-aware optimizer.
minor comments (2)
- [Method description] The EMA decay rate in RealErrorComposer and the disagreement threshold for triggering full surrogate updates are listed as free parameters; their sensitivity to performance and any default values or tuning protocol should be reported explicitly.
- [Experiments] The abstract reports results at horizon T=100; longer-horizon experiments or scaling behavior with observation count would strengthen the practical claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comment below, with an honest assessment of what can and cannot be revised.
read point-by-point responses
-
Referee: [Abstract and RA-GD analysis] Abstract and RA-GD analysis section: the idealized RA-GD model supplies sufficient conditions for bounded dynamic regret under cluster-separated, strongly convex regimes, yet the deployed pipeline (retrieval + mixture-of-experts surrogate + prompt-subspace adaptation + RealErrorComposer) is stated to violate several of those premises. No alternative regret analysis is supplied for the actual algorithm, so the central claim that RASP-Tuner improves or matches regret on seven of nine tasks lacks theoretical grounding that would explain why the method succeeds when the analyzed conditions fail. This gap is load-bearing for the paper's positioning as a principled context-aware optimizer.
Authors: We agree that the RA-GD analysis applies strictly to an idealized retrieval-augmented gradient descent procedure under cluster-separated strongly convex assumptions and does not bound the full deployed pipeline. The manuscript already states that the implemented system violates several of those premises. The RA-GD section is offered as a source of intuition for the retrieval-plus-prompt-adaptation decomposition rather than a guarantee for the mixture-of-experts surrogate, RealErrorComposer, or approximate retrieval. No alternative regret bound for the complete algorithm is supplied because extending the analysis to cover these components appears technically difficult and is left open. The central empirical claim (competitive regret on seven of nine tasks with 8-12x lower per-step cost) is presented as an experimental result, not as a consequence of the idealized bound. We will revise the abstract and the RA-GD section to state more explicitly that the theoretical results apply only to the simplified model and do not extend to the deployed RASP-Tuner, thereby clarifying the paper's positioning as a practical method with partial theoretical support. revision: partial
- A regret bound that covers the full deployed RASP-Tuner (including retrieval approximation, mixture-of-experts dynamics, and RealErrorComposer) is not provided and cannot be derived within the scope of this work.
Circularity Check
No circularity: empirical claims independent of idealized RA-GD analysis
full rationale
The paper states its performance claims solely via empirical paired tests on nine synthetic benchmarks and real-world streams at T=100, without deriving those outcomes from the RA-GD model. It explicitly notes that the deployed pipeline (retrieval + mixture-of-experts + prompt adaptation + RealErrorComposer) violates several premises of the cluster-separated strongly-convex RA-GD regime used only for sufficient conditions on bounded dynamic regret. No equations reduce a prediction or first-principles result to its own inputs by construction, no self-citation supplies a load-bearing uniqueness theorem, and no fitted parameter is relabeled as a prediction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- EMA decay rate in RealErrorComposer
- Disagreement threshold for full surrogate update
axioms (2)
- domain assumption Contexts revisit a small set of latent regimes
- domain assumption Short-horizon loss is predictable from parameter-context-prompt concatenation
invented entities (1)
-
RealErrorComposer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evolutionary computation , volume=
Completely derandomized self-adaptation in evolution strategies , author=. Evolutionary computation , volume=. 2001 , publisher=
2001
-
[2]
Advances in neural information processing systems , volume=
Contextual gaussian process bandit optimization , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[6]
International Conference on Learning Representations , year=
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. International Conference on Learning Representations , year=
-
[7]
Advances in neural information processing systems , volume=
Practical bayesian optimization of machine learning algorithms , author=. Advances in neural information processing systems , volume=
-
[8]
2023 , eprint=
ISP meets Deep Learning: A Survey on Deep Learning Methods for Image Signal Processing , author=. 2023 , eprint=
2023
-
[9]
2014 IEEE international conference on cloud engineering , pages=
Autoscaling web applications in heterogeneous cloud infrastructures , author=. 2014 IEEE international conference on cloud engineering , pages=. 2014 , organization=
2014
-
[10]
Data Drift Quantification Metrics for Month-on-Month Semiconductor Data , year=
Bhattacharya, Nandita and Barari, Adrita and Pedapudi, Lakshmi Narayana and Kim, Hoyeon and Kim, Kyuhwan and Seo, Jihye , booktitle=. Data Drift Quantification Metrics for Month-on-Month Semiconductor Data , year=
-
[11]
Artificial intelligence and statistics , pages=
Deep kernel learning , author=. Artificial intelligence and statistics , pages=. 2016 , organization=
2016
-
[12]
Advances in neural information processing systems , volume=
Sparse Gaussian processes using pseudo-inputs , author=. Advances in neural information processing systems , volume=
-
[13]
International Conference on Machine Learning , pages=
Adaptive and safe Bayesian optimization in high dimensions via one-dimensional subspaces , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[14]
Advances in neural information processing systems , volume=
Learning to learn by gradient descent by gradient descent , author=. Advances in neural information processing systems , volume=
-
[15]
Proceedings of the IEEE , volume=
Taking the human out of the loop: A review of Bayesian optimization , author=. Proceedings of the IEEE , volume=. 2015 , publisher=
2015
-
[16]
The journal of machine learning research , volume=
Random search for hyper-parameter optimization , author=. The journal of machine learning research , volume=. 2012 , publisher=
2012
-
[17]
Automated Machine Learning: Methods, Systems, Challenges , editor =
Hyperparameter Optimization , author =. Automated Machine Learning: Methods, Systems, Challenges , editor =
-
[18]
International Conference on Learning Representations , year =
Generalization through Memorization: Nearest Neighbor Language Models , author =. International Conference on Learning Representations , year =
-
[19]
Artificial Intelligence and Statistics , pages=
Time-varying Gaussian process bandit optimization , author=. Artificial Intelligence and Statistics , pages=. 2016 , organization=
2016
-
[20]
Proceedings of the Twentieth International Conference on Machine Learning (ICML'03) , pages =
Online Convex Programming and Generalized Infinitesimal Gradient Ascent , author =. Proceedings of the Twentieth International Conference on Machine Learning (ICML'03) , pages =
-
[21]
Operations Research , volume =
Non-stationary Stochastic Optimization , author =. Operations Research , volume =. 2015 , doi =
2015
-
[22]
IEEE Journal of Selected Topics in Signal Processing , volume =
Online Convex Optimization in Dynamic Environments , author =. IEEE Journal of Selected Topics in Signal Processing , volume =. 2015 , doi =
2015
-
[23]
Foundations and Trends
Introduction to online convex optimization , author=. Foundations and Trends. 2016 , publisher=
2016
-
[24]
Proceedings of the 34th Conference on Learning Theory (COLT) , pages=
Non-stationary Reinforcement Learning without Prior Knowledge: An Optimal Black-box Approach , author=. Proceedings of the 34th Conference on Learning Theory (COLT) , pages=. 2021 , organization=
2021
-
[26]
Shi, Weijia and Min, Sewon and Yasunaga, Michihiro and Seo, Minjoon and James, Rich and Lewis, Mike and Zettlemoyer, Luke and Yih, Wen-tau , journal=
-
[28]
Proceedings of the 29th International Conference on Computational Linguistics (COLING) , pages=
Context-Tuning: Learning Contextualized Prompts for Natural Language Generation , author=. Proceedings of the 29th International Conference on Computational Linguistics (COLING) , pages=
-
[29]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Time-aware Prompting for Text Generation , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[30]
Anupam, Sagnik and Shypula, Alexander and Bastani, Osbert and others , journal=
-
[31]
Gupta, Taneesh and Shandilya, Shivam and Zhang, Xuchao and Madhavan, Rahul and Ghosh, Supriyo and Bansal, Chetan and Yao, Huaxiu and Rajmohan, Saravan , booktitle=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Few-Shot Recognition via Stage-Wise Retrieval-Augmented Finetuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[34]
, journal=
Chu, Jaewon and Lee, Seunghun and Kim, Hyunwoo J. , journal=
-
[35]
Proceedings of the 40th International Conference on Machine Learning (ICML) , pages=
PromptBoosting: Black-Box Text Classification with Ten Forward Passes , author=. Proceedings of the 40th International Conference on Machine Learning (ICML) , pages=
-
[37]
Context tuning for retrieval augmented generation
Anantha, R., Bethi, T., Vodianik, D., and Chappidi, S. Context tuning for retrieval augmented generation. arXiv preprint arXiv:2312.05708, 2023
-
[38]
W., Pfau, D., Schaul, T., Shillingford, B., and De Freitas, N
Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M. W., Pfau, D., Schaul, T., Shillingford, B., and De Freitas, N. Learning to learn by gradient descent by gradient descent. In Advances in neural information processing systems, volume 29, 2016
2016
-
[39]
LLM Program Optimization via Retrieval Augmented Search
Anupam, S., Shypula, A., Bastani, O., et al. LLM Program Optimization via Retrieval Augmented Search . arXiv preprint arXiv:2501.18916, 2025
-
[40]
and Bengio, Y
Bergstra, J. and Bengio, Y. Random search for hyper-parameter optimization. The journal of machine learning research, 13 0 (1): 0 281--305, 2012
2012
-
[41]
Non-stationary stochastic optimization.Operations Research, 63(5):1227–1244, 2015
Besbes, O., Gur, Y., and Zeevi, A. Non-stationary stochastic optimization. Operations Research, 63 0 (5): 0 1227--1244, 2015. doi:10.1287/opre.2015.1408
-
[42]
Time-varying gaussian process bandit optimization
Bogunovic, I., Scarlett, J., and Cevher, V. Time-varying gaussian process bandit optimization. In Artificial Intelligence and Statistics, pp.\ 314--323. PMLR, 2016
2016
-
[43]
and Wang, L
Cao, S. and Wang, L. Time-aware prompting for text generation. In Findings of the Association for Computational Linguistics: EMNLP 2022, pp.\ 7231--7246, 2022
2022
- [44]
-
[45]
Model-agnostic meta-learning for fast adaptation of deep networks
Finn, C., Abbeel, P., and Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning, pp.\ 1126--1135. PMLR, 2017
2017
-
[46]
CARMO: Dynamic Criteria Generation for Context Aware Reward Modelling
Gupta, T., Shandilya, S., Zhang, X., Madhavan, R., Ghosh, S., Bansal, C., Yao, H., and Rajmohan, S. CARMO: Dynamic Criteria Generation for Context Aware Reward Modelling . In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 2202--2261, 2025
2025
-
[47]
Hall, E. C. and Willett, R. M. Online convex optimization in dynamic environments. IEEE Journal of Selected Topics in Signal Processing, 9 0 (4): 0 647--662, 2015. doi:10.1109/JSTSP.2015.2404790
-
[48]
Online reinforcement learning in non-stationary context-driven environments
Hamadanian, P., Nasr-Esfahany, A., Schwarzkopf, M., Sen, S., and Alizadeh, M. Online reinforcement learning in non-stationary context-driven environments. arXiv preprint arXiv:2302.02182, 2023
-
[49]
and Ostermeier, A
Hansen, N. and Ostermeier, A. Completely derandomized self-adaptation in evolution strategies. Evolutionary computation, 9 0 (2): 0 159--195, 2001
2001
-
[50]
Hazan, E. et al. Introduction to online convex optimization. Foundations and Trends in Optimization , 2 0 (3-4): 0 157--325, 2016
2016
-
[51]
Promptboosting: Black-box text classification with ten forward passes
Hou, B., O'Connor, J., Andreas, J., Chang, S., and Zhang, Y. Promptboosting: Black-box text classification with ten forward passes. In Proceedings of the 40th International Conference on Machine Learning (ICML), pp.\ 13309--13324, 2023
2023
-
[52]
Generalization through memorization: Nearest neighbor language models
Khandelwal, U., Fan, A., Jurafsky, D., Zettlemoyer, L., and Lewis, M. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations, 2020
2020
-
[53]
and Ong, C
Krause, A. and Ong, C. Contextual gaussian process bandit optimization. Advances in neural information processing systems, 24, 2011
2011
-
[54]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021
work page internal anchor Pith review arXiv 2021
-
[55]
u ttler, H., Lewis, M., Yih, W.-t., Rockt \
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K \"u ttler, H., Lewis, M., Yih, W.-t., Rockt \"a schel, T., et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, volume 33, pp.\ 9459--9474, 2020
2020
-
[56]
Few-shot recognition via stage-wise retrieval-augmented finetuning
Liu, T., Zhang, H., Parashar, S., and Kong, S. Few-shot recognition via stage-wise retrieval-augmented finetuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[57]
P., and De Freitas, N
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and De Freitas, N. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE, 104 0 (1): 0 148--175, 2015
2015
-
[58]
arXiv preprint arXiv:2301.12652 , year=
Shi, W., Min, S., Yasunaga, M., Seo, M., James, R., Lewis, M., Zettlemoyer, L., and Yih, W.-t. REPLUG: Retrieval-Augmented Black-Box Language Models . arXiv preprint arXiv:2301.12652, 2023
-
[59]
Direct retrieval-augmented optimization: Synergizing knowledge selection and language models
Shi, Z., Yan, L., Sun, W., Feng, Y., Ren, P., Ma, X., Wang, S., Yin, D., de Rijke, M., and Ren, Z. Direct retrieval-augmented optimization: Synergizing knowledge selection and language models. arXiv preprint arXiv:2505.03075, 2025
-
[60]
and Ghahramani, Z
Snelson, E. and Ghahramani, Z. Sparse gaussian processes using pseudo-inputs. Advances in neural information processing systems, 18, 2005
2005
-
[61]
Snoek, J., Larochelle, H., and Adams, R. P. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25, 2012
2012
-
[62]
X., and Wen, J.-R
Tang, T., Li, J., Zhao, W. X., and Wen, J.-R. Context-tuning: Learning contextualized prompts for natural language generation. In Proceedings of the 29th International Conference on Computational Linguistics (COLING), pp.\ 6340--6354, 2022
2022
-
[63]
Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
Wang, Y., Ren, R., Wang, Y., Zhao, W. X., Liu, J., Wu, H., and Wang, H. Reinforced informativeness optimization for long-form retrieval-augmented generation. arXiv preprint arXiv:2505.20825, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
and Luo, H
Wei, C.-Y. and Luo, H. Non-stationary reinforcement learning without prior knowledge: An optimal black-box approach. In Proceedings of the 34th Conference on Learning Theory (COLT), pp.\ 4300--4354. PMLR, 2021
2021
-
[65]
G., Hu, Z., Salakhutdinov, R., and Xing, E
Wilson, A. G., Hu, Z., Salakhutdinov, R., and Xing, E. P. Deep kernel learning. Artificial intelligence and statistics, pp.\ 370--378, 2016
2016
-
[66]
Online convex programming and generalized infinitesimal gradient ascent
Zinkevich, M. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the Twentieth International Conference on Machine Learning (ICML'03), pp.\ 928--936, 2003
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.