Recognition: unknown
CFSR: Geometry-Conditioned Shadow Removal via Physical Disentanglement
Pith reviewed 2026-05-10 04:52 UTC · model grok-4.3
The pith
CFSR removes shadows by conditioning restoration on 3D geometry and semantic priors to enforce physical lighting rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CFSR maps inputs to HVI color space, fuses depth priors, modulates attention affinity directly with DINO features and 3D normals, injects CLIP priors for degraded areas, and uses a Frequency Collaborative Reconstruction Module that separates high-frequency boundary recovery from low-frequency illumination restoration, all conditioned on geometric cues.
What carries the argument
Geometric & Semantic Dual Explicit Guided Attention mechanism that modulates the attention matrix with DINO features and 3D surface normals to embed physical lighting constraints into the network.
If this is right
- Shadow removal can separate high-frequency occlusion edges from low-frequency illumination without separate post-processing stages.
- Depth and normal priors can be injected early to reduce the need for heavy post-correction of lighting errors.
- Frozen foundation-model encoders supply stable semantic context for regions where local evidence is destroyed by shadows.
- Decoupled frequency reconstruction produces sharper boundaries while preserving smooth shading across the image.
Where Pith is reading between the lines
- The same geometry-conditioned attention pattern could be tested on related restoration problems such as reflection removal or low-light enhancement.
- If depth estimation improves, the method's performance gap to oracle 3D inputs would indicate how much the current results depend on accurate geometry.
- Extending the frequency module to video frames might reveal whether the per-frame physical constraints remain stable across time.
Load-bearing premise
That fusing HVI-mapped observations with depth priors and modulating attention via DINO features plus 3D normals will reliably enforce physical lighting constraints and close the 2D-3D gap.
What would settle it
A test set of images containing physically inconsistent shadows (for example, multiple light directions that violate a single light source) where the output still shows mismatched illumination or new artifacts at boundaries.
Figures



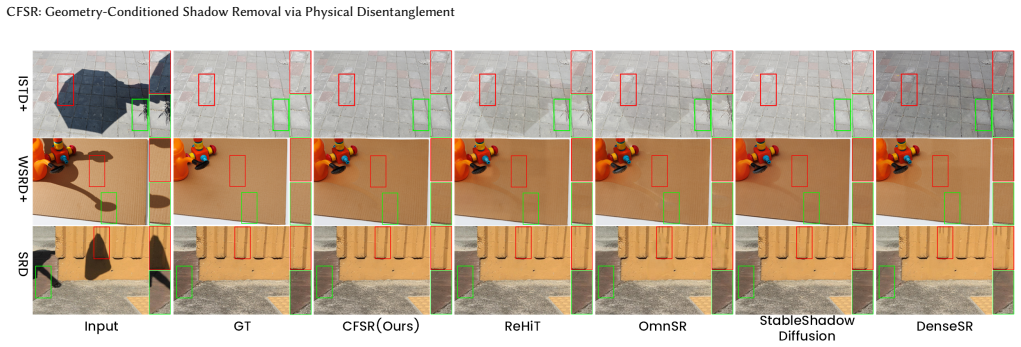


read the original abstract
Traditional shadow removal networks often treat image restoration as an unconstrained mapping, lacking the physical interpretability required to balance localized texture recovery with global illumination consistency. To address this, we propose CFSR, a multi-modal prior-driven framework that reframes shadow removal as a physics-constrained restoration process. By seamlessly integrating 3D geometric cues with large-scale foundation model semantics, CFSR effectively bridges the 2D-3D domain gap. Specifically, we first map observations into a custom HVI color space to suppress shadow-induced noise and robustly fuse RGB data with estimated depth priors. At its core, our Geometric & Semantic Dual Explicit Guided Attention mechanism utilizes DINO features and 3D surface normals to directly modulate the attention affinity matrix, structurally enforcing physical lighting constraints. To recover severely degraded regions, we inject holistic priors via a frozen CLIP encoder. Finally, our Frequency Collaborative Reconstruction Module (FCRM) achieves an optimal synthesis by decoupling the decoding process. Conditioned on geometric priors, FCRM seamlessly harmonizes the reconstruction of sharp high-frequency occlusion boundaries with the restoration of low-frequency global illumination. Extensive experiments demonstrate that CFSR achieves state-of-the-art performance across multiple challenging benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CFSR, a multi-modal shadow removal network that maps inputs to a custom HVI color space, fuses RGB with depth priors, employs Geometric & Semantic Dual Explicit Guided Attention (modulating attention via DINO features and 3D normals), injects frozen CLIP priors for degraded regions, and uses a Frequency Collaborative Reconstruction Module (FCRM) to separately handle high-frequency boundaries and low-frequency illumination. It claims this reframes shadow removal as physics-constrained restoration that bridges the 2D-3D gap and achieves state-of-the-art results on multiple benchmarks.
Significance. If the guided-attention modulation and FCRM can be shown to impose verifiable physical consistency (e.g., albedo invariance or illumination smoothness) beyond standard learned priors, the approach would offer a principled way to incorporate geometric cues into restoration tasks and improve generalization on challenging shadow cases.
major comments (3)
- [Abstract, §3.2] Abstract and §3.2 (Geometric & Semantic Dual Explicit Guided Attention): the claim that DINO features plus 3D normals 'directly modulate the attention affinity matrix, structurally enforcing physical lighting constraints' is not supported by any explicit constraint equation, regularization term, or diagnostic metric (such as shadow-edge gradient consistency or albedo variance across lit/shadow regions). Without these, the mechanism reduces to an empirical attention prior whose physical interpretation remains unverified.
- [Abstract, Experiments] Abstract and Experiments section: the assertion of 'state-of-the-art performance across multiple challenging benchmarks' is presented without any quantitative tables, baseline comparisons, error bars, or ablation results in the provided text. This prevents assessment of whether the reported gains are statistically meaningful or attributable to the proposed physical-disentanglement components rather than architecture scale.
- [§3.3] §3.3 (FCRM): the description of decoupling high-frequency occlusion boundaries from low-frequency global illumination via frequency collaboration is conceptually appealing, but no loss formulation or frequency-domain analysis is supplied to demonstrate that the module enforces illumination consistency that standard decoders lack.
minor comments (2)
- [§3.1] Notation for the HVI color space and the exact form of the attention-affinity modulation should be defined with equations rather than prose descriptions.
- [§4] The manuscript would benefit from a clear statement of the overall training objective (including any auxiliary losses for depth or normal estimation) to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below with clarifications and commitments to revisions that strengthen the physical grounding and empirical support of the method without overstating current claims.
read point-by-point responses
-
Referee: [Abstract, §3.2] Abstract and §3.2 (Geometric & Semantic Dual Explicit Guided Attention): the claim that DINO features plus 3D normals 'directly modulate the attention affinity matrix, structurally enforcing physical lighting constraints' is not supported by any explicit constraint equation, regularization term, or diagnostic metric (such as shadow-edge gradient consistency or albedo variance across lit/shadow regions). Without these, the mechanism reduces to an empirical attention prior whose physical interpretation remains unverified.
Authors: We agree that the current wording overstates the enforcement as 'structural' without supporting formalism. The modulation occurs by adding projected DINO and normal features to the attention logits before the softmax, which empirically biases attention toward geometrically consistent regions, but this remains a learned prior. In revision we will replace the claim with precise equations for the guided attention (A' = softmax((QK^T + g(DINO, N))/√d_k)), add a dedicated diagnostic subsection with metrics (albedo variance across lit/shadow pairs and shadow-edge gradient consistency), and report these results on the benchmarks. revision: yes
-
Referee: [Abstract, Experiments] Abstract and Experiments section: the assertion of 'state-of-the-art performance across multiple challenging benchmarks' is presented without any quantitative tables, baseline comparisons, error bars, or ablation results in the provided text. This prevents assessment of whether the reported gains are statistically meaningful or attributable to the proposed physical-disentanglement components rather than architecture scale.
Authors: The full manuscript contains an Experiments section with tables reporting PSNR/SSIM on ISTD, SRD, and ISTD+ benchmarks against recent baselines, plus ablations isolating each component and standard-deviation error bars. We acknowledge that the abstract does not reference these numbers and that the review copy may have obscured the tables. We will revise the abstract to cite the key quantitative margins and ensure all tables explicitly include error bars, statistical significance, and component-wise ablations demonstrating that gains derive from the geometric and frequency modules rather than scale alone. revision: partial
-
Referee: [§3.3] §3.3 (FCRM): the description of decoupling high-frequency occlusion boundaries from low-frequency global illumination via frequency collaboration is conceptually appealing, but no loss formulation or frequency-domain analysis is supplied to demonstrate that the module enforces illumination consistency that standard decoders lack.
Authors: We accept that the current description lacks the requested formalism. The FCRM applies separate high-frequency (edge-preserving) and low-frequency (illumination) branches with geometry-conditioned fusion; the loss includes an L1 term on high-frequency residuals and a total-variation smoothness term on the low-frequency illumination map. In revision we will insert the explicit loss equations, describe the frequency decomposition (wavelet-based), and add FFT spectrum plots plus quantitative illumination-consistency metrics comparing FCRM against a standard decoder baseline. revision: yes
Circularity Check
No circularity: empirical architecture with external benchmarks
full rationale
The paper proposes a neural architecture (HVI mapping, depth fusion, DINO+normals guided attention, FCRM) for shadow removal and reports SOTA on benchmarks. No derivation chain, equations, fitted parameters relabeled as predictions, or self-citations appear in the provided text. All performance claims rest on external evaluation rather than reducing to the method's own inputs by construction. The physical-constraint framing is a design motivation, not a self-referential proof.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xuecheng Bai, Yuxiang Wang, Boyu Hu, Qinyuan Jie, Chuanzhi Xu, Kechen Li, Hongru Xiao, and Vera Chung. 2026. DRWKV: Focusing on Object Edges for Low-Light Image Enhancement. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1554–1564
2026
- [2]
-
[3]
Worameth Chinchuthakun, Pakkapon Phongthawee, Amit Raj, Varun Jampani, Pramook Khungurn, and Supasorn Suwajanakorn. 2026. DiffusionLight-Turbo: Accelerated Light Probes for Free Via Single-Pass Chrome Ball Inpainting.IEEE Transactions on Pattern Analysis and Machine Intelligence(2026), 1–14. doi:10. 1109/TPAMI.2026.3660066
-
[4]
Xiaodong Cun, Chi-Man Pun, and Cheng Shi. 2020. Towards ghost-free shadow removal via dual hierarchical aggregation network and shadow matting gan. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 10680–10687
2020
-
[5]
Wei Dong, Han Zhou, Seyed Amirreza Mousavi, and Jun Chen. 2025. Retinex- guided histogram transformer for mask-free shadow removal. InProceedings of the Computer Vision and Pattern Recognition Conference. 1471–1481
2025
-
[6]
Wei Dong, Han Zhou, Yuqiong Tian, Jingke Sun, Xiaohong Liu, Guangtao Zhai, and Jun Chen. 2024. ShadowRefiner: Towards Mask-free Shadow Removal via Fast Fourier Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 6208–6217
2024
-
[7]
Wei Dong, Han Zhou, Yuqiong Tian, Jingke Sun, Xiaohong Liu, Guangtao Zhai, and Jun Chen. 2024. Shadowrefiner: Towards mask-free shadow removal via fast fourier transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6208–6217
2024
-
[8]
Tamir Einy, Efrat Immer, Gilad Vered, and Shai Avidan. 2022. Physics based image deshadowing using local linear model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3012–3020
2022
-
[9]
G.D. Finlayson, S.D. Hordley, Cheng Lu, and M.S. Drew. 2006. On the removal of shadows from images.IEEE Transactions on Pattern Analysis and Machine Intelligence28, 1 (2006), 59–68. doi:10.1109/TPAMI.2006.18
-
[10]
Lan Fu, Changqing Zhou, Qing Guo, Felix Juefei-Xu, Hongkai Yu, Wei Feng, Yang Liu, and Song Wang. 2021. Auto-exposure fusion for single-image shadow removal. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10571–10580
2021
-
[11]
Lanqing Guo, Siyu Huang, Ding Liu, Hao Cheng, and Bihan Wen. 2023. Shad- owFormer: Global context helps shadow removal. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 710–718
2023
-
[12]
Lanqing Guo, Chong Wang, Wenhan Yang, Siyu Huang, Yufei Wang, Hanspeter Pfister, and Bihan Wen. 2023. Shadowdiffusion: When degradation prior meets diffusion model for shadow removal. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14049–14058
2023
-
[13]
Lanqing Guo, Chong Wang, Wenhan Yang, Yufei Wang, and Bihan Wen. 2023. Boundary-aware divide and conquer: A diffusion-based solution for unsupervised shadow removal. InProceedings of the IEEE/CVF International Conference on Computer Vision. 13045–13054
2023
-
[14]
Ruiqi Guo, Qieyun Dai, and Derek Hoiem. 2011. Single-image shadow detection and removal using paired regions. InCVPR 2011. IEEE, 2033–2040
2011
-
[15]
Jin Hu, Mingjia Li, and Xiaojie Guo. 2025. Shadowhack: Hacking shadows via luminance-color divide and conquer. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11403–11413
2025
-
[16]
Tao Hu, Longyao Wu, Wei Dong, Peng Wu, Jinqiu Sun, Xiaogang Xu, Qingsen Yan, and Yanning Zhang. 2026. Boosting HDR Image Reconstruction via Semantic Knowledge Transfer.IEEE Transactions on Image Processing35 (2026), 1910–1922. doi:10.1109/TIP.2026.3652360
-
[17]
Xiaowei Hu, Yitong Jiang, Chi-Wing Fu, and Pheng-Ann Heng. 2019. Mask- ShadowGAN: Learning to Remove Shadows From Unpaired Data. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
- [18]
-
[19]
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. 2021. Focal frequency loss for image reconstruction and synthesis. InProceedings of the IEEE/CVF international conference on computer vision. 13919–13929
2021
-
[20]
Yeying Jin, Aashish Sharma, and Robby T Tan. 2021. Dc-shadownet: Single-image hard and soft shadow removal using unsupervised domain-classifier guided network. InProceedings of the IEEE/CVF international conference on computer vision. 5027–5036
2021
-
[21]
Dachun Kai, Jiayao Lu, Yueyi Zhang, and Xiaoyan Sun. 2026. EvTexture++: Event- Driven Texture Enhancement for Video Super-Resolution.IEEE Transactions on Pattern Analysis and Machine Intelligence(2026), 1–18. doi:10.1109/TPAMI.2026. 3660020
-
[22]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al
-
[23]
InProceedings of the IEEE/CVF international conference on computer vision
Segment anything. InProceedings of the IEEE/CVF international conference on computer vision. 4015–4026
-
[24]
Hieu Le and Dimitris Samaras. 2019. Shadow removal via shadow image decom- position. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8578–8587
2019
-
[25]
Hieu Le and Dimitris Samaras. 2020. From shadow segmentation to shadow removal. InEuropean Conference on Computer Vision. Springer, 264–281
2020
-
[26]
Hieu Le and Dimitris Samaras. 2022. Physics-Based Shadow Image Decomposi- tion for Shadow Removal.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 12 (2022), 9088–9101. doi:10.1109/TPAMI.2021.3124934
- [27]
-
[28]
Zhengqin Li, Dilin Wang, Ka Chen, Zhaoyang Lv, Thu Nguyen-Phuoc, Milim Lee, Jia-Bin Huang, Lei Xiao, Yufeng Zhu, Carl S Marshall, et al . 2025. Lirm: Large inverse rendering model for progressive reconstruction of shape, materials and view-dependent radiance fields. InProceedings of the Computer Vision and Pattern Recognition Conference. 505–517
2025
-
[29]
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Chih- Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, et al. 2025. Diffusion renderer: Neural inverse and forward rendering with video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference. 26069–26080
2025
-
[30]
Yu-Fan Lin, Chia-Ming Lee, and Chih-Chung Hsu. 2025. Densesr: Image shadow removal as dense prediction. InProceedings of the 33rd ACM International Con- ference on Multimedia. 7026–7035
2025
-
[31]
Feng Liu and Michael Gleicher. 2008. Texture-consistent shadow removal. In European Conference on Computer Vision. Springer, 437–450
2008
-
[32]
Hengxing Liu, Mingjia Li, and Xiaojie Guo. 2024. Regional attention for shadow removal. InProceedings of the 32nd ACM International Conference on Multimedia. 5949–5957
2024
-
[33]
Jiawei Liu, Qiang Wang, Huijie Fan, Wentao Li, Liangqiong Qu, and Yandong Tang. 2023. A decoupled multi-task network for shadow removal.IEEE Transac- tions on Multimedia25 (2023), 9449–9463
2023
-
[34]
Xiujin Liu. 2025. GNC-Pose: Geometry-Aware GNC-PnP for Accurate 6D Pose Estimation.arXiv preprint arXiv:2512.06565(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Zhihao Liu, Hui Yin, Xinyi Wu, Zhenyao Wu, Yang Mi, and Song Wang. 2021. From shadow generation to shadow removal. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4927–4936
2021
-
[36]
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas B. Schön. 2023. Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Models. In2023 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition Workshops (CVPRW). 1680–1691. doi:10.1109/ CVPRW59228.2023.00169
-
[37]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Liangqiong Qu, Jiandong Tian, Shengfeng He, Yandong Tang, and Rynson WH Lau. 2017. Deshadownet: A multi-context embedding deep network for shadow removal. InProceedings of the IEEE conference on computer vision and pattern recognition. 4067–4075
2017
-
[39]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[40]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[41]
Dai Quoc Tran, Armstrong Aboah, Yuntae Jeon, Maged Shoman, Minsoo Park, and Seunghee Park. 2024. Low-light image enhancement framework for improved object detection in fisheye lens datasets. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7056–7065
2024
-
[42]
Florin-Alexandru Vasluianu, Tim Seizinger, and Radu Timofte. 2023. Wsrd: A novel benchmark for high resolution image shadow removal. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1826–1835
2023
-
[43]
Florin-Alexandru Vasluianu, Tim Seizinger, Zongwei Wu, Rakesh Ranjan, and Radu Timofte. 2024. Towards image ambient lighting normalization. InEuropean Conference on Computer Vision. Springer, 385–404
2024
-
[44]
Florin-Alexandru Vasluianu, Tim Seizinger, Zongwei Wu, and Radu Timofte
-
[45]
InProceedings of the IEEE/CVF International Conference on Computer Vision
After the Party: Navigating the Mapping From Color to Ambient Lighting. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9218– 9229
-
[46]
Jifeng Wang, Xiang Li, and Jian Yang. 2018. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. InProceedings of the IEEE conference on computer vision and pattern recognition. 1788–1797
2018
-
[47]
Pan Wang, Yihao Hu, Xiaodong Bai, Jingchu Yang, Leyi Zhou, Aiping Yang, Xi- angxiang Li, Meiping Ding, and Jianguo Yao. 2025. A Multi-Strategy Framework for Enhancing Shatian Pomelo Detection in Real-World Orchards.arXiv preprint arXiv:2510.09948(2025). CFSR: Geometry-Conditioned Shadow Removal via Physical Disentanglement
-
[48]
Tao Wang, Kaihao Zhang, Tianrun Shen, Wenhan Luo, Bjorn Stenger, and Tong Lu. 2023. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 2654–2662
2023
-
[49]
Jie Xiao, Xueyang Fu, Yurui Zhu, Dong Li, Jie Huang, Kai Zhu, and Zheng-Jun Zha
-
[50]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Homoformer: Homogenized transformer for image shadow removal. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 25617–25626
-
[51]
Jiamin Xu, Zelong Li, Yuxin Zheng, Chenyu Huang, Renshu Gu, Weiwei Xu, and Gang Xu. 2025. Omnisr: Shadow removal under direct and indirect lighting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8887–8895
2025
-
[52]
Jiamin Xu, Yuxin Zheng, Zelong Li, Chi Wang, Renshu Gu, Weiwei Xu, and Gang Xu. 2025. Detail-preserving latent diffusion for stable shadow removal. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7592–7602
2025
-
[53]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth Anything V2. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 21875–21911. doi:10.52202/079017-0688
-
[54]
Qingxiong Yang, Kar-Han Tan, and Narendra Ahuja. 2012. Shadow Removal Using Bilateral Filtering.IEEE Transactions on Image Processing21, 10 (2012), 4361–4368. doi:10.1109/TIP.2012.2208976
- [55]
-
[56]
Edward Zhang, Ricardo Martin-Brualla, Janne Kontkanen, and Brian L Curless
-
[57]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
No shadow left behind: Removing objects and their shadows using ap- proximate lighting and geometry. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16397–16406
-
[58]
Yurui Zhu, Jie Huang, Xueyang Fu, Feng Zhao, Qibin Sun, and Zheng-Jun Zha
-
[59]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bijective mapping network for shadow removal. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5627–5636
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.