Recognition: unknown
Towards E-Value Based Stopping Rules for Bayesian Deep Ensembles
Pith reviewed 2026-05-10 05:39 UTC · model grok-4.3
The pith
E-value sequential tests give a principled early stopping rule for MCMC sampling in Bayesian deep ensembles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a stopping rule based on E-values. We formulate the ensemble construction as a sequential anytime-valid hypothesis test, providing a principled way to decide whether or not to reject the null hypothesis that MCMC offers no improvement over a strong baseline, to early stop the sampling. Empirically, we study this approach for diverse settings. Our results demonstrate the efficacy of our approach and reveal that only a fraction of the full-chain budget is often required.
What carries the argument
An E-value based sequential anytime-valid hypothesis test that rejects the null of no improvement from additional MCMC samples over the initial deep-ensemble baseline.
If this is right
- Only a fraction of the usual full-chain sampling budget is typically needed.
- The procedure supplies a statistically valid, fixed-budget-independent criterion for halting MCMC.
- The same rule can be applied across varied network architectures and data sets without retuning.
- Early stopping preserves the uncertainty-quantification gains that MCMC is known to deliver over plain deep ensembles.
Where Pith is reading between the lines
- The same E-value construction could be reused to monitor other sequential Monte-Carlo or variational procedures whose cost grows with iteration count.
- If the test is combined with cheaper surrogate models for the null, overall wall-clock time for Bayesian neural-network training could drop further.
- Deployment pipelines that already cache deep-ensemble checkpoints could insert the E-value monitor with negligible extra code.
Load-bearing premise
The E-value sequential test stays valid and correctly detects when extra MCMC samples stop improving the ensemble beyond the deep-ensemble baseline in the neural-network regimes examined.
What would settle it
An experiment in which the rule stops sampling and the resulting ensemble performs no better than the deep-ensemble baseline, even though continuing the full MCMC run would have produced a clear improvement.
Figures


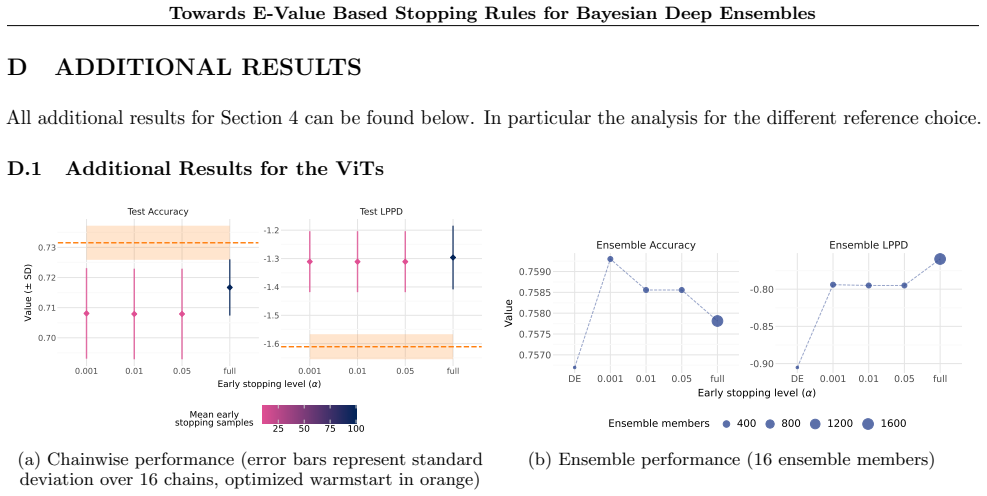

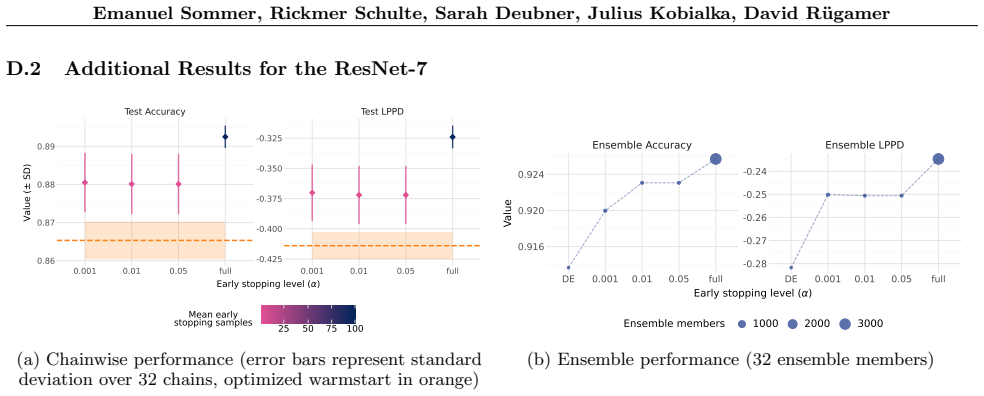
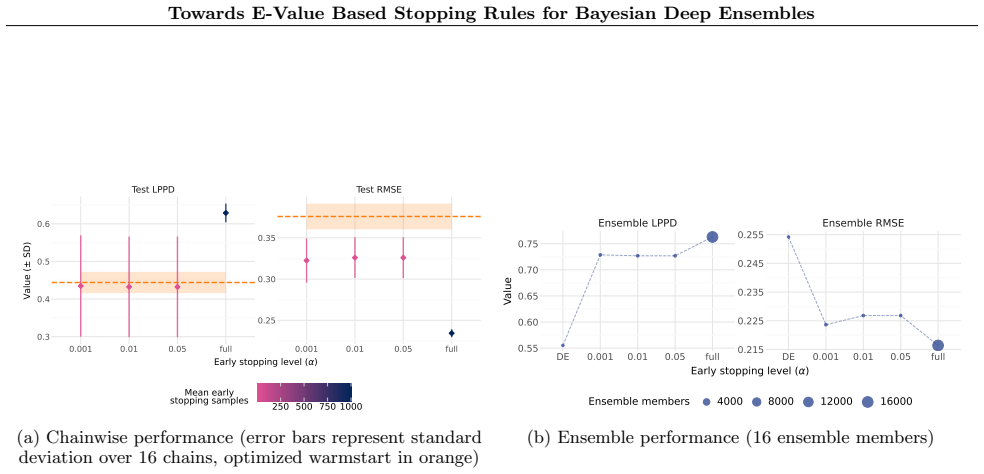


read the original abstract
Bayesian Deep Ensembles (BDEs) represent a powerful approach for uncertainty quantification in deep learning, combining the robustness of Deep Ensembles (DEs) with flexible multi-chain MCMC. While DEs are affordable in most deep learning settings, (long) sampling of Bayesian neural networks can be prohibitively costly. Yet, adding sampling after optimizing the DEs has been shown to yield significant improvements. This leaves a critical practical question: How long should the sequential sampling process continue to yield significant improvements over the initial optimized DE baseline? To tackle this question, we propose a stopping rule based on E-values. We formulate the ensemble construction as a sequential anytime-valid hypothesis test, providing a principled way to decide whether or not to reject the null hypothesis that MCMC offers no improvement over a strong baseline, to early stop the sampling. Empirically, we study this approach for diverse settings. Our results demonstrate the efficacy of our approach and reveal that only a fraction of the full-chain budget is often required.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an E-value-based stopping rule for Bayesian Deep Ensembles (BDEs), framing the sequential addition of MCMC samples as an anytime-valid hypothesis test. The null hypothesis is that further MCMC sampling yields no improvement over a fixed deep ensemble (DE) baseline; the procedure rejects the null (and continues sampling) while the cumulative E-value exceeds a threshold, with the goal of early-stopping once gains plateau. Empirical studies across diverse settings indicate that only a fraction of the full-chain MCMC budget is typically required.
Significance. If the sequential test is valid, the method supplies a statistically principled, computationally efficient way to allocate MCMC resources in BDE training, addressing the practical cost barrier of long-chain sampling while preserving the performance gains that MCMC can provide over DEs alone. This could make uncertainty-aware Bayesian deep learning more accessible in resource-constrained settings.
major comments (2)
- [§3] §3 (E-value construction): The central claim that the procedure yields an anytime-valid test requires that the chosen improvement statistic (predictive performance delta on a validation set) produces a supermartingale under the null of no MCMC gain. No explicit martingale construction, conditional-expectation argument, or proof is supplied showing that E[increment | filtration] ≤ 1 holds when the statistic is a non-linear functional of the posterior predictive and the DE baseline is itself optimized on overlapping data. This property is load-bearing for the validity of early stopping.
- [§4] §4 (empirical validation): The reported experiments demonstrate early stopping but do not include a direct check (e.g., type-I error rate under a synthetic null where MCMC truly adds nothing) that the E-value process remains valid in the neural-network regime. Without such a diagnostic, it is unclear whether the observed savings reflect genuine anytime-validity or merely empirical behavior on the studied tasks.
minor comments (2)
- [§2] Notation for the E-value process and the filtration should be introduced explicitly in §2 before the hypothesis-test formulation; current usage in the abstract and §3 is informal.
- [Abstract] The abstract claims “only a fraction of the full-chain budget is often required” but does not report the precise fractions or variance across runs; a table summarizing budget savings per dataset would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address the major concerns point by point below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [§3] §3 (E-value construction): The central claim that the procedure yields an anytime-valid test requires that the chosen improvement statistic (predictive performance delta on a validation set) produces a supermartingale under the null of no MCMC gain. No explicit martingale construction, conditional-expectation argument, or proof is supplied showing that E[increment | filtration] ≤ 1 holds when the statistic is a non-linear functional of the posterior predictive and the DE baseline is itself optimized on overlapping data. This property is load-bearing for the validity of early stopping.
Authors: We appreciate the referee pointing out the need for a more explicit justification of the supermartingale property. In our construction, the E-value is defined using the ratio of the likelihood under the alternative (improved model) to the null, but we acknowledge that for the specific statistic involving non-linear predictive performance on validation data with overlapping optimization, a detailed conditional expectation argument is missing. We will revise §3 to include a formal proof sketch showing that under the null of no improvement, the expected increment of the E-value is at most 1, leveraging the fact that the baseline DE is fixed and the MCMC samples are drawn from the posterior. This will ensure the anytime-validity is rigorously established. revision: yes
-
Referee: [§4] §4 (empirical validation): The reported experiments demonstrate early stopping but do not include a direct check (e.g., type-I error rate under a synthetic null where MCMC truly adds nothing) that the E-value process remains valid in the neural-network regime. Without such a diagnostic, it is unclear whether the observed savings reflect genuine anytime-validity or merely empirical behavior on the studied tasks.
Authors: We agree that a direct validation of the type-I error control under a controlled null scenario would provide stronger evidence for the method's validity. In the revised manuscript, we will add a synthetic experiment where we simulate a setting in which additional MCMC samples do not improve upon the DE baseline (e.g., by using a fixed model or a null posterior), and report the empirical type-I error rate of the stopping procedure to confirm it does not exceed the nominal level. revision: yes
Circularity Check
No circularity: E-value stopping rule applies external theory without self-referential reduction
full rationale
The paper formulates ensemble construction as a sequential hypothesis test using E-values to decide early stopping for MCMC sampling in Bayesian Deep Ensembles. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The central claim relies on the external validity of E-value theory for anytime-valid testing rather than deriving the supermartingale property from the paper's own fitted quantities or prior self-citations. The skeptic concern about the test statistic's martingale property under the null is a question of assumption validity and external verification, not an internal circular reduction by construction. The derivation chain remains self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math E-values provide valid anytime-valid sequential tests for the null hypothesis that MCMC sampling offers no improvement
Reference graph
Works this paper leans on
-
[1]
Metropolis
Robnik, Jakob and Cohn-Gordon, Reuben and Seljak, Uro. Metropolis. Advances in Neural Information Processing Systems , year =
-
[2]
Physical Review E , author =
Optimized. Physical Review E , author =. 2002 , note =
2002
-
[3]
Frontiers in Probabilistic Inference: Learning meets Sampling , year=
Rundel, David and Sommer, Emanuel and Bischl, Bernd and R. Frontiers in Probabilistic Inference: Learning meets Sampling , year=
-
[4]
Advances in Neural Information Processing Systems , year=
Deterministic Langevin Monte Carlo with Normalizing Flows for Bayesian Inference , author=. Advances in Neural Information Processing Systems , year=
-
[5]
Proceedings of the 36th International Conference on Machine Learning , pages =
The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Sharp Minima and Regularization Effects , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , volume =
2019
-
[6]
Strength of Minibatch Noise in
Liu Ziyin and Kangqiao Liu and Takashi Mori and Masahito Ueda , booktitle=. Strength of Minibatch Noise in
-
[7]
Advances in neural information processing systems , volume=
A complete recipe for stochastic gradient MCMC , author=. Advances in neural information processing systems , volume=
-
[8]
Computer Physics Communications , author =
Symplectic analytically integrable decomposition algorithms: classification, derivation, and application to molecular dynamics, quantum and celestial mechanics simulations , volume =. Computer Physics Communications , author =. 2003 , keywords =
2003
-
[9]
arXiv preprint arXiv:2505.18636 , year=
Asymmetric Duos: Sidekicks Improve Uncertainty , author=. arXiv preprint arXiv:2505.18636 , year=
-
[10]
Bayesian inference and maximum entropy methods in science and engineering , volume=
Nested sampling , author=. Bayesian inference and maximum entropy methods in science and engineering , volume=
-
[11]
International conference on artificial intelligence and statistics , pages=
Tuning-free generalized hamiltonian monte carlo , author=. International conference on artificial intelligence and statistics , pages=. 2022 , organization=
2022
-
[12]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[13]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[14]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[15]
Bayesian Optimization with Robust Bayesian Neural Networks , volume =
Springenberg, Jost Tobias and Klein, Aaron and Falkner, Stefan and Hutter, Frank , booktitle =. Bayesian Optimization with Robust Bayesian Neural Networks , volume =
-
[16]
Advances in Neural Information Processing Systems , volume=
Benchopt: Reproducible, efficient and collaborative optimization benchmarks , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Tran, Ba-Hien and Rossi, Simone and Milios, Dimitrios and Filippone, Maurizio , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2022 , issue_date =
2022
-
[18]
Analyzing a portion of the ROC Curve , volume =
McClish, Donna , year =. Analyzing a portion of the ROC Curve , volume =. Medical decision making : an international journal of the Society for Medical Decision Making , doi =
-
[19]
Proceedings of the 41st International Conference on Machine Learning , year=
Sommer, Emanuel and Wimmer, Lisa and Papamarkou, Theodore and Bothmann, Ludwig and Bischl, Bernd and R. Proceedings of the 41st International Conference on Machine Learning , year=
-
[20]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Towards efficient MCMC sampling in Bayesian neural networks by exploiting symmetry , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2023 , organization=
2023
-
[21]
Journal of Machine Learning Research , volume=
Stacking for non-mixing Bayesian computations: The curse and blessing of multimodal posteriors , author=. Journal of Machine Learning Research , volume=
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Sommer, Emanuel and Robnik, Jakob and Nozadze, Giorgi and Seljak, Uro. The Thirteenth International Conference on Learning Representations , year=
-
[23]
Vine Copula based Portfolio Level Conditional Risk Measure Forecasting , journal =
Emanuel Sommer and Karoline Bax and Claudia Czado , keywords =. Vine Copula based Portfolio Level Conditional Risk Measure Forecasting , journal =. 2023 , OPTissn =
2023
-
[24]
Ziegel , title =
Natalia Nolde and Johanna F. Ziegel , title =. The Annals of Applied Statistics , number =. 2017 , doi =
2017
-
[25]
Kuleshov, Volodymyr and Fenner, Nathan and Ermon, Stefano , booktitle =
-
[26]
Kompa, Benjamin and Snoek, Jasper and Beam, Andrew L. , ee =. Entropy , keywords =
-
[27]
and Ghalebikesabi, Sahra and Sejdinovic, Dino and Knoblauch, Jeremias , title =
Wild, Veit D. and Ghalebikesabi, Sahra and Sejdinovic, Dino and Knoblauch, Jeremias , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2024 , publisher =
2024
-
[28]
, year =
Adlam, Ben and Snoek, Jasper and Smith, Samuel L. , year =. Cold
-
[29]
and Hayase, Jonathan and Srinivasa, Siddhartha , year =
Ainsworth, Samuel K. and Hayase, Jonathan and Srinivasa, Siddhartha , year =. Git. Proceedings of the
-
[30]
A Statistical Theory of Cold Posteriors in Deep Neural Networks , booktitle =
Aitchison, Laurence , year =. A Statistical Theory of Cold Posteriors in Deep Neural Networks , booktitle =
-
[31]
, optEditor =
Albertini, Francesca and Sontag, Eduardo D. , optEditor =. Uniqueness of Weights for Neural Networks , booktitle =. 1994 , series =
1994
-
[32]
Structured
Alexos, Antonios and Boyd, Alex and Mandt, Stephan , keywords =. Structured
-
[33]
Andriushchenko, Maksym and D'Angelo, Francesco and Varre, Aditya and Flammarion, Nicolas , year =. Why
-
[34]
Anonymous , year =. Deep
-
[35]
Arbel, Julyan and Pitas, Konstantinos and Vladimirova, Mariia and Fortuin, Vincent , year =. A
-
[36]
Armenta, Marco Antonio and Jodoin, Pierre-Marc , year =. The. Mathematics , volume =
-
[37]
and Hu, Wei and Li, Zhiyuan and Wang, Ruosong , year =
Arora, Sanjeev and Du, Simon S. and Hu, Wei and Li, Zhiyuan and Wang, Ruosong , year =. Fine-
-
[38]
Bdl-Benchmarks , author =
-
[39]
and Maddox, Wesley J
Benton, Gregory W. and Maddox, Wesley J. and Lotfi, Sanae and Wilson, Andrew Gordon , year =. Loss. Proceedings of the 38th
-
[40]
Betancourt, Michael , year =. A
-
[41]
Bierkens, Joris and Grazzi, Sebastiano and Kamatani, Kengo and Roberts, Gareth , year =. The
-
[42]
and Kucukelbir, Alp and McAuliffe, Jon D
Blei, David M. and Kucukelbir, Alp and McAuliffe, Jon D. , year =. Variational. Journal of the American Statistical Association , volume =
-
[43]
2020 , journal =
Probabilistic. 2020 , journal =
2020
-
[44]
Blundell, Charles and Cornebise, Julien and Kavukcuoglu, Koray and Wierstra, Daan , year =. Weight. Proceedings of the 32 Nd
-
[45]
2021 , number =
Parameter Identifiability of a Deep Feedforward. 2021 , number =
2021
-
[46]
2018 , journal =
The. 2018 , journal =
2018
-
[47]
2019 , keywords =
Weight-Space Symmetry in Deep Networks Gives Rise to Permutation Saddles, Connected by Equal-Loss Valleys across the Loss Landscape , author =. 2019 , keywords =
2019
-
[48]
Bubeck, S. A. 2022 , number =
2022
-
[49]
Bayesian Neural Networks via
Chandra, Rohitash and Chen, Royce and Simmons, Joshua , year =. Bayesian Neural Networks via
-
[50]
Chen, An Mei and Lu, Haw-minn and. On the. 1993 , journal =
1993
-
[51]
2023 , keywords =
Awesome Deep Phenomena: List of Papers , author =. 2023 , keywords =
2023
-
[52]
, year =
Chen, Yifan and Huang, Daniel Zhengyu and Huang, Jiaoyang and Reich, Sebastian and Stuart, Andrew M. , year =. Gradient
-
[53]
Learning the
Cohen, Taco and Welling, Max , year =. Learning the. Proceedings of the 31st
-
[54]
and Dow, Eric and Wang, Qiqi , year =
Constantine, Paul G. and Dow, Eric and Wang, Qiqi , year =. Active Subspace Methods in Theory and Practice: Applications to Kriging Surfaces , shorttitle =. SIAM Journal on Scientific Computing , volume =
-
[55]
Journal of Open Source Software , volume =
Coullon, Jeremie and Nemeth, Christopher , year =. Journal of Open Source Software , volume =
-
[56]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[57]
Proceedings of the National Academy of Sciences of the United States of America , volume=
The distribution of chi-square , author=. Proceedings of the National Academy of Sciences of the United States of America , volume=. 1931 , publisher=
1931
-
[58]
Forty-second International Conference on Machine Learning , year=
Neighbour-Driven Gaussian Process Variational Autoencoders for Scalable Structured Latent Modelling , author=. Forty-second International Conference on Machine Learning , year=
-
[59]
and Chada, Neil K
Paulin, Daniel and Whalley, Peter A. and Chada, Neil K. and Leimkuhler, Benedict J. , year =. Sampling from. The 28th
-
[60]
Computational Statistics , year =
Daniel Andrade and Koki Sato , title =. Computational Statistics , year =
-
[61]
2011 , booktitle =
Welling, Max and Teh, Yee Whye , title =. 2011 , booktitle =
2011
-
[62]
Daxberger, Erik and Kristiadi, Agustinus and Immer, Alexander and Eschenhagen, Runa and Bauer, Matthias and Hennig, Philipp , year =. Laplace. 35th
-
[63]
Modeling
Depeweg, Stefan , year =. Modeling
-
[64]
Fortuna -
Detommaso, Gianluca and Gasparin, Alberto and Donini, Michele and Seeger, Matthias and Wilson, Andrew Gordon and Archambeau, Cedric , keywords =. Fortuna -
-
[65]
Uncertainty
Detommaso, Gianluca and Gasparin, Alberto and Wilson, Andrew and Archambeau, Cedric , year =. Uncertainty
-
[66]
Dherin, Benoit and Munn, Michael and Rosca, Mihaela and Barrett, David G. T. , year =. Why Neural Networks Find Simple Solutions: The Many Regularizers of Geometric Complexity , shorttitle =. 36th
-
[67]
and Zhai, Xiyu and Poczos, Barnabas and Singh, Aarti , year =
Du, Simon S. and Zhai, Xiyu and Poczos, Barnabas and Singh, Aarti , year =. Gradient
-
[68]
The Complexity of Explaining Neural Networks through (Group) Invariants , booktitle =
Ensign, Danielle and Neville, Scott and Paul, Arnab and Venkatasubramanian, Suresh , year =. The Complexity of Explaining Neural Networks through (Group) Invariants , booktitle =
-
[69]
Entezari, Rahim and Sedghi, Hanie and Saukh, Olga and Neyshabur, Behnam , year =. The. Proceedings of the
-
[70]
Ergen, Tolga and Pilanci, Mert , year =. Convex
-
[71]
Liberty or
Farquhar, Sebastian and Smith, Lewis and Gal, Yarin , year =. Liberty or. Proceedings of the 34th
-
[72]
Understanding
Farquhar, Sebastian , year =. Understanding
-
[73]
2023 , number =
Functional. 2023 , number =
2023
-
[74]
Ferbach, Damien and Goujaud, Baptiste and Gidel, Gauthier and Dieuleveut, Aymeric , year =. Proving
-
[75]
Fort, Stanislav and Hu, Huiyi and Lakshminarayanan, Balaji , year =. Deep
-
[76]
Proceedings of the 5th International Conference on Learning Representations , author =
Topology and. Proceedings of the 5th International Conference on Learning Representations , author =. 2017 , keywords =
2017
-
[77]
, year =
Fukumizu, K. , year =. Local Minima and Plateaus in Multilayer Neural Networks , booktitle =
-
[78]
Dropout as a
Gal, Yarin and Ghahramani, Zoubin , year =. Dropout as a. Proceedings of the 33rd
-
[79]
Uncertainty in
Gal, Yarin , year =. Uncertainty in
-
[80]
2023 , number =
Universal Approximation and Model Compression for Radial Neural Networks , author =. 2023 , number =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.