Recognition: unknown
Efficient Low-Resource Language Adaptation via Multi-Source Dynamic Logit Fusion
Pith reviewed 2026-05-10 05:24 UTC · model grok-4.3
The pith
TriMix dynamically fuses logits from three sources to adapt large language models to low-resource languages without task annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
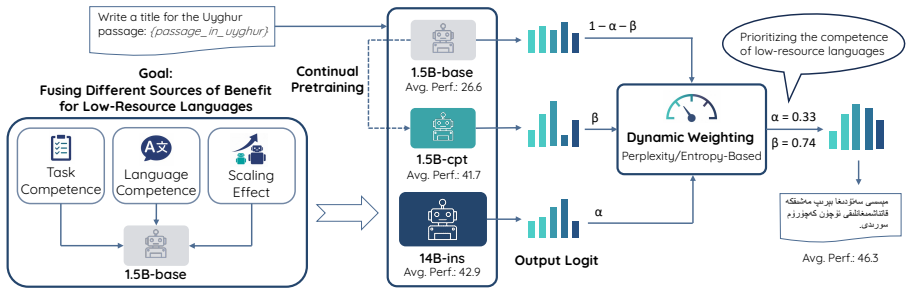
TriMix is a test-time logit fusion framework that dynamically balances LRL competence from a continually pretrained small model, task competence from high-resource language instruction tuning, and the scaling benefits of large models; it requires no LRL task annotations and outperforms single-model baselines and Proxy Tuning across four model families and eight LRLs, with prioritizing the small LRL-specialized model's logits proving crucial.
What carries the argument
TriMix, a test-time logit fusion framework that dynamically weights and combines logits from a small continually pretrained LRL model, a high-resource tuned model, and a large model.
If this is right
- TriMix enables efficient LRL adaptation using only continual pretraining on a small model and existing high-resource tuning data.
- The method applies across multiple model families without requiring LRL-specific task annotations.
- Prioritizing logits from the small LRL-specialized model is necessary for the fusion to succeed, contrary to large-model-dominant assumptions.
- The framework remains data-efficient and compute-light at inference time.
Where Pith is reading between the lines
- Fusion weights could be learned or adapted per language or task without manual tuning, extending the dynamic aspect further.
- Similar three-source balancing might transfer to other adaptation settings like domain shift or specialized skills where small experts complement large models.
- Testing TriMix on even scarcer languages or with zero high-resource overlap would clarify the limits of the small-model prioritization.
Load-bearing premise
That the small model's LRL competence from continual pretraining can be dynamically balanced with the other sources without the large model's weak LRL performance overwhelming the fusion, and that this holds without any LRL task annotations.
What would settle it
An experiment on new LRLs where even optimized dynamic weighting in TriMix produces no gains over Proxy Tuning or single small-model baselines, or where forcing higher weight on the small model hurts rather than helps results.
Figures


read the original abstract
Adapting large language models (LLMs) to low-resource languages (LRLs) is constrained by the scarcity of task data and computational resources. Although Proxy Tuning offers a logit-level strategy for introducing scaling effects, it often fails in LRL settings because the large model's weak LRL competence might overwhelm the knowledge of specialized smaller models. We thus propose TriMix, a test-time logit fusion framework that dynamically balances capabilities from three different sources: LRL competence from a continually pretrained small model, task competence from high-resource language instruction tuning, and the scaling benefits of large models. It is data- and compute-efficient, requiring no LRL task annotations, and only continual pretraining on a small model. Experiments across four model families and eight LRLs show that TriMix consistently outperforms single-model baselines and Proxy Tuning. Our analysis reveals that prioritizing the small LRL-specialized model's logits is crucial for success, challenging the prevalent large-model-dominant assumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TriMix, a test-time dynamic logit fusion framework for adapting LLMs to low-resource languages without task annotations or additional training. It fuses logits from three sources—a small model continually pretrained on the target LRL, a high-resource instruction-tuned model, and the large model—claiming consistent outperformance over single-model baselines and Proxy Tuning across four model families and eight LRLs, with analysis indicating that prioritizing the small LRL-specialized model's logits is crucial.
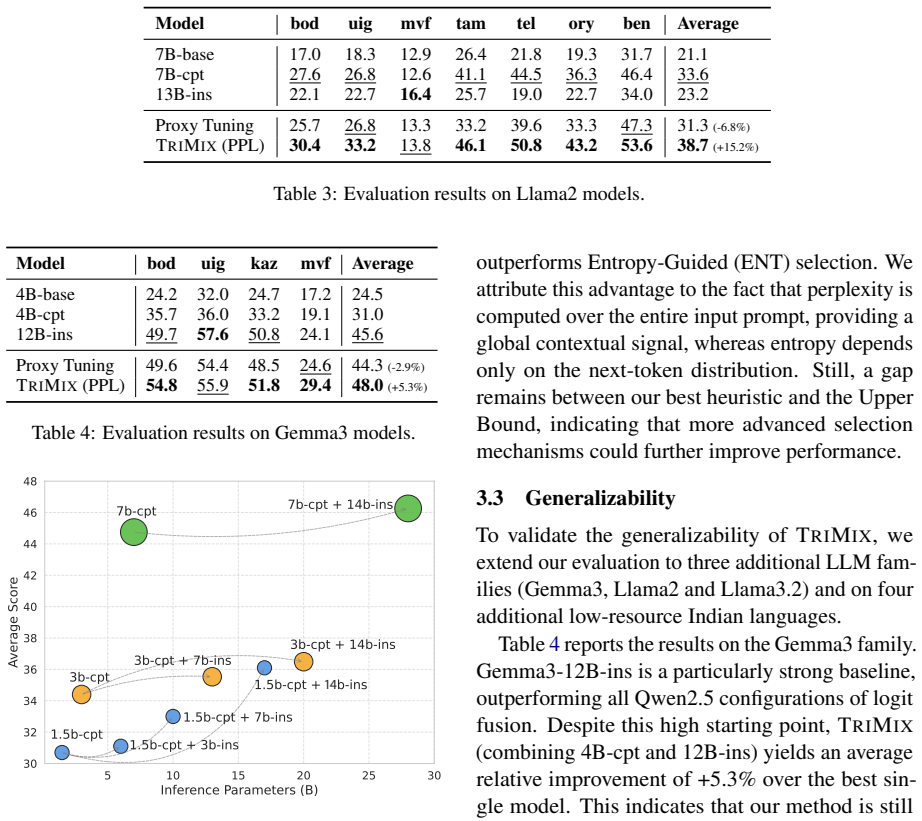
Significance. If the dynamic fusion mechanism reliably up-weights the small model's LRL competence without supervision, the approach would offer a practical, low-resource method for LLM adaptation that avoids the dominance issues of Proxy Tuning. The multi-family, multi-language empirical evaluation provides broad support for the central claim, though the lack of mechanistic transparency limits assessment of generalizability.
major comments (2)
- [methods section] The description of the TriMix fusion (methods section): no explicit equation, algorithm, or weighting rule is provided for how the three logit sources are dynamically balanced at test time. This is load-bearing for the central claim, because without a specified mechanism (e.g., entropy-based, magnitude-based, or otherwise) that demonstrably prioritizes the small model on LRL inputs, it remains unclear why large-model logits would not dominate as they do in Proxy Tuning.
- [experimental results] Experimental results (across the four model families and eight LRLs): the abstract and results claim consistent outperformance but report no error bars, variance across seeds, or statistical significance tests. This undermines confidence in the empirical support for the claim that TriMix reliably succeeds where baselines fail.
minor comments (1)
- [abstract] The abstract would be strengthened by a one-sentence outline of the fusion weighting strategy to allow readers to immediately grasp the technical contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas for improvement in clarity and empirical rigor. We address each major comment below and have made corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [methods section] The description of the TriMix fusion (methods section): no explicit equation, algorithm, or weighting rule is provided for how the three logit sources are dynamically balanced at test time. This is load-bearing for the central claim, because without a specified mechanism (e.g., entropy-based, magnitude-based, or otherwise) that demonstrably prioritizes the small model on LRL inputs, it remains unclear why large-model logits would not dominate as they do in Proxy Tuning.
Authors: We agree that the methods section would benefit from greater formalization. The original manuscript describes the dynamic balancing of the three logit sources in prose and demonstrates through analysis that the small LRL-specialized model is effectively prioritized. However, we acknowledge the absence of an explicit equation or algorithm for the weighting rule. In the revised manuscript, we have added a formal equation defining the fused logits as a weighted sum and included pseudocode for the test-time fusion procedure. This addition makes the dynamic mechanism explicit and shows how it mitigates large-model dominance, consistent with the empirical results and analysis already present in the paper. revision: yes
-
Referee: [experimental results] Experimental results (across the four model families and eight LRLs): the abstract and results claim consistent outperformance but report no error bars, variance across seeds, or statistical significance tests. This undermines confidence in the empirical support for the claim that TriMix reliably succeeds where baselines fail.
Authors: We appreciate this point on statistical reporting. The original experiments were conducted with fixed seeds to ensure reproducibility across the eight languages and four model families, but we agree that variance estimates and significance testing would increase confidence in the reliability of the gains. In the revised manuscript, we have added error bars (standard deviations computed over three independent runs with different seeds) to all main result tables and figures. We have also included paired statistical significance tests (t-tests) comparing TriMix against the strongest baseline in each setting, confirming that the reported improvements are statistically significant (p < 0.05) in the majority of cases. revision: yes
Circularity Check
No derivation chain; purely empirical comparisons
full rationale
The paper introduces TriMix as a test-time logit fusion method and supports its claims solely through experimental results across model families and LRLs, outperforming baselines like Proxy Tuning. No equations, first-principles derivations, or parameter-fitting steps are presented that could reduce to inputs by construction. The central claims rest on observed performance gains and post-hoc analysis of logit prioritization, without self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations that substitute for independent evidence. This is a standard empirical NLP adaptation paper with no circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Continual pretraining on a small model imparts usable LRL competence that can be fused with other sources
- domain assumption Dynamic logit fusion can balance the three sources effectively at test time
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review arXiv
-
[2]
Qwen2. 5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
First Conference on Language Modeling , year=
Tuning Language Models by Proxy , author=. First Conference on Language Modeling , year=
-
[6]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[7]
Costas Mavromatis and Petros Karypis and George Karypis , booktitle=. Pack of. 2024 , url=
2024
-
[8]
Sheng Cao and Mingrui Wu and Karthik Prasad and Yuandong Tian and Zechun Liu , booktitle=. Param\. 2025 , url=
2025
-
[9]
2023 , url=
Prateek Yadav and Derek Tam and Leshem Choshen and Colin Raffel and Mohit Bansal , booktitle=. 2023 , url=
2023
-
[10]
Nature Machine Intelligence , volume=
Evolutionary optimization of model merging recipes , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
-
[11]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[12]
BLOOM +1: Adding Language Support to BLOOM for Zero-Shot Prompting
Yong, Zheng Xin and Schoelkopf, Hailey and Muennighoff, Niklas and Aji, Alham Fikri and Adelani, David Ifeoluwa and Almubarak, Khalid and Bari, M Saiful and Sutawika, Lintang and Kasai, Jungo and Baruwa, Ahmed and Winata, Genta and Biderman, Stella and Raff, Edward and Radev, Dragomir and Nikoulina, Vassilina. BLOOM +1: Adding Language Support to BLOOM fo...
-
[13]
Continual Pre-Training for Cross-Lingual
Kazuki Fujii and Taishi Nakamura and Mengsay Loem and Hiroki Iida and Masanari Ohi and Kakeru Hattori and Hirai Shota and Sakae Mizuki and Rio Yokota and Naoaki Okazaki , booktitle=. Continual Pre-Training for Cross-Lingual. 2024 , url=
2024
-
[14]
2023 , eprint=
Dictionary-based Phrase-level Prompting of Large Language Models for Machine Translation , author=. 2023 , eprint=
2023
-
[15]
The Twelfth International Conference on Learning Representations , year=
A Benchmark for Learning to Translate a New Language from One Grammar Book , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
Seth Aycock and David Stap and Di Wu and Christof Monz and Khalil Sima'an , booktitle=. Can. 2025 , url=
2025
-
[17]
arXiv preprint arXiv:2511.06531 , year=
Ibom NLP: A Step Toward Inclusive Natural Language Processing for Nigeria's Minority Languages , author=. arXiv preprint arXiv:2511.06531 , year=
-
[18]
The Thirteenth International Conference on Learning Representations , year=
Layer Swapping for Zero-Shot Cross-Lingual Transfer in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[19]
MindMerger: Efficiently Boosting
Zixian Huang and Wenhao Zhu and Gong Cheng and Lei Li and Fei Yuan , booktitle=. MindMerger: Efficiently Boosting. 2024 , url=
2024
-
[20]
Transactions on Machine Learning Research , issn=
Adapting Chat Language Models Using Only Target Unlabeled Language Data , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[21]
Logit Arithmetic Elicits Long Reasoning Capabilities Without Training
Logit arithmetic elicits long reasoning capabilities without training , author=. arXiv preprint arXiv:2510.09354 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
The Twelfth International Conference on Learning Representations , year=
An Emulator for Fine-tuning Large Language Models using Small Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[23]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
On Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[24]
Contrastive decoding improves reasoning in large language models,
Contrastive decoding improves reasoning in large language models , author=. arXiv preprint arXiv:2309.09117 , year=
-
[25]
The Twelfth International Conference on Learning Representations , year=
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
Angelika Romanou and Negar Foroutan and Anna Sotnikova and Sree Harsha Nelaturu and Shivalika Singh and Rishabh Maheshwary and Micol Altomare and Zeming Chen and Mohamed A. Haggag and Snegha A and Alfonso Amayuelas and Azril Hafizi Amirudin and Danylo Boiko and Michael Chang and Jenny Chim and Gal Cohen and Aditya Kumar Dalmia and Abraham Diress and Shara...
-
[27]
Harvard Data Science Review , volume=
Lessons from the margins: Contextualizing, reimagining, and hacking generative AI in the Global South , author=. Harvard Data Science Review , volume=. 2025 , publisher=
2025
-
[28]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review arXiv
-
[29]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-lm: Training multi-billion parameter language models using model parallelism , author=. arXiv preprint arXiv:1909.08053 , year=
work page internal anchor Pith review arXiv 1909
-
[30]
Advances in neural information processing systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in neural information processing systems , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
ICML 2024 Next Generation of AI Safety Workshop , year=
Weak-to-Strong Jailbreaking on Large Language Models , author=. ICML 2024 Next Generation of AI Safety Workshop , year=
2024
-
[33]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on M anchu
Pei, Renhao and Liu, Yihong and Lin, Peiqin and Yvon, Fran c ois and Schuetze, Hinrich. Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on M anchu. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.429
-
[35]
MC ^2 : Towards Transparent and Culturally-Aware NLP for Minority Languages in C hina
Zhang, Chen and Tao, Mingxu and Huang, Quzhe and Lin, Jiuheng and Chen, Zhibin and Feng, Yansong. MC ^2 : Towards Transparent and Culturally-Aware NLP for Minority Languages in C hina. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.479
-
[36]
Unlocking the Potential of Model Merging for Low-Resource Languages
Tao, Mingxu and Zhang, Chen and Huang, Quzhe and Ma, Tianyao and Huang, Songfang and Zhao, Dongyan and Feng, Yansong. Unlocking the Potential of Model Merging for Low-Resource Languages. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.508
-
[37]
M i L i C -Eval: Benchmarking Multilingual LLM s for C hina ' s Minority Languages
Zhang, Chen and Tao, Mingxu and Liao, Zhiyuan and Feng, Yansong. M i L i C -Eval: Benchmarking Multilingual LLM s for C hina ' s Minority Languages. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.578
-
[38]
doi: 10.18653/v1/2024.acl-long.44
Bandarkar, Lucas and Liang, Davis and Muller, Benjamin and Artetxe, Mikel and Shukla, Satya Narayan and Husa, Donald and Goyal, Naman and Krishnan, Abhinandan and Zettlemoyer, Luke and Khabsa, Madian. The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants. Proceedings of the 62nd Annual Meeting of the Association for Com...
-
[39]
and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie
Adelani, David Ifeoluwa and Liu, Hannah and Shen, Xiaoyu and Vassilyev, Nikita and Alabi, Jesujoba O. and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie. SIB -200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects. Proceedings of the 18th Conference of the European Chapter of the Association for Co...
-
[40]
Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation
Garces Arias, Esteban and Rodemann, Julian and Li, Meimingwei and Heumann, Christian and A enmacher, Matthias. Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.885
-
[41]
Contrastive Decoding: Open-ended Text Generation as Optimization , booktitle =
Li, Xiang Lisa and Holtzman, Ari and Fried, Daniel and Liang, Percy and Eisner, Jason and Hashimoto, Tatsunori and Zettlemoyer, Luke and Lewis, Mike. Contrastive Decoding: Open-ended Text Generation as Optimization. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.a...
-
[42]
Huang, Shih-Cheng and Li, Pin-Zu and Hsu, Yu-chi and Chen, Kuang-Ming and Lin, Yu Tung and Hsiao, Shih-Kai and Tsai, Richard and Lee, Hung-yi. Chat Vector: A Simple Approach to Equip LLM s with Instruction Following and Model Alignment in New Languages. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
-
[43]
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Singh, Shivalika and Vargus, Freddie and D. Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.620
-
[44]
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Su, Tong and Peng, Xin and Thillainathan, Sarubi and Guzm \'a n, David and Ranathunga, Surangika and Lee, En-Shiun. Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.263
-
[45]
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Shaham, Uri and Herzig, Jonathan and Aharoni, Roee and Szpektor, Idan and Tsarfaty, Reut and Eyal, Matan. Multilingual Instruction Tuning With Just a Pinch of Multilinguality. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.136
-
[46]
Group then Scale: Dynamic Mixture-of-Experts Multilingual Language Model
Li, Chong and Deng, Yingzhuo and Zhang, Jiajun and Zong, Chengqing. Group then Scale: Dynamic Mixture-of-Experts Multilingual Language Model. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.87
-
[47]
Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource Languages
Dimakis, Antonios and Markantonatou, Stella and Anastasopoulos, Antonios. Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource Languages. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.152
-
[48]
Teaching Large Language Models an Unseen Language on the Fly
Zhang, Chen and Liu, Xiao and Lin, Jiuheng and Feng, Yansong. Teaching Large Language Models an Unseen Language on the Fly. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.519
-
[49]
Read it in Two Steps: Translating Extremely Low-Resource Languages with Code-Augmented Grammar Books
Zhang, Chen and Lin, Jiuheng and Liu, Xiao and Zhang, Zekai and Feng, Yansong. Read it in Two Steps: Translating Extremely Low-Resource Languages with Code-Augmented Grammar Books. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.202
-
[50]
Shortcomings of LLM s for Low-Resource Translation: Retrieval and Understanding Are Both the Problem
Court, Sara and Elsner, Micha. Shortcomings of LLM s for Low-Resource Translation: Retrieval and Understanding Are Both the Problem. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.125
-
[51]
It ' s All About In-Context Learning! Teaching Extremely Low-Resource Languages to LLM s
Li, Yue and Zhao, Zhixue and Scarton, Carolina. It ' s All About In-Context Learning! Teaching Extremely Low-Resource Languages to LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1502
-
[52]
Self-Distillation for Model Stacking Unlocks Cross-Lingual NLU in 200+ Languages
Schmidt, Fabian David and Borchert, Philipp and Vuli \'c , Ivan and Glava s , Goran. Self-Distillation for Model Stacking Unlocks Cross-Lingual NLU in 200+ Languages. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.394
-
[53]
Su, Zeli and Zhang, Ziyin and Xu, Guixian and Liu, Jianing and Han, Xu and Zhang, Ting and Dong, Yushuang. Multilingual Encoder Knows more than You Realize: Shared Weights Pretraining for Extremely Low-Resource Languages. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/...
-
[54]
Improving Cross-Domain Low-Resource Text Generation through LLM Post-Editing: A Programmer-Interpreter Approach
Li, Zhuang and Haroutunian, Levon and Tumuluri, Raj and Cohen, Philip and Haf, Reza. Improving Cross-Domain Low-Resource Text Generation through LLM Post-Editing: A Programmer-Interpreter Approach. Findings of the Association for Computational Linguistics: EACL 2024. 2024
2024
-
[55]
SCALE : Synergized Collaboration of Asymmetric Language Translation Engines
Cheng, Xin and Wang, Xun and Ge, Tao and Chen, Si-Qing and Wei, Furu and Zhao, Dongyan and Yan, Rui. SCALE : Synergized Collaboration of Asymmetric Language Translation Engines. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.941
-
[56]
Together We Can: Multilingual Automatic Post-Editing for Low-Resource Languages
Deoghare, Sourabh and Kanojia, Diptesh and Bhattacharyya, Pushpak. Together We Can: Multilingual Automatic Post-Editing for Low-Resource Languages. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.634
-
[57]
Improving Cross Lingual Transfer by Pretraining with Active Forgetting
Aggarwal, Divyanshu and Sathe, Ashutosh and Sitaram, Sunayana. Improving Cross Lingual Transfer by Pretraining with Active Forgetting. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.120
-
[58]
Trusting Your Evidence: Hallucinate Less with Context-aware Decoding
Shi, Weijia and Han, Xiaochuang and Lewis, Mike and Tsvetkov, Yulia and Zettlemoyer, Luke and Yih, Wen-tau. Trusting Your Evidence: Hallucinate Less with Context-aware Decoding. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024. doi:...
-
[59]
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Kim, Youna and Kim, Hyuhng Joon and Park, Cheonbok and Park, Choonghyun and Cho, Hyunsoo and Kim, Junyeob and Yoo, Kang Min and Lee, Sang-goo and Kim, Taeuk. Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings...
-
[60]
Learning to Decode Collaboratively with Multiple Language Models
Shen, Zejiang and Lang, Hunter and Wang, Bailin and Kim, Yoon and Sontag, David. Learning to Decode Collaboratively with Multiple Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.701
-
[61]
DVD : Dynamic Contrastive Decoding for Knowledge Amplification in Multi-Document Question Answering
Jin, Jing and Wang, Houfeng and Zhang, Hao and Li, Xiaoguang and Guo, Zhijiang. DVD : Dynamic Contrastive Decoding for Knowledge Amplification in Multi-Document Question Answering. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.266
-
[62]
E pi C o D e: Boosting Model Performance Beyond Training with Extrapolation and Contrastive Decoding
Tao, Mingxu and Hu, Jie and Yang, Mingchuan and Liu, Yunhuai and Zhao, Dongyan and Feng, Yansong. E pi C o D e: Boosting Model Performance Beyond Training with Extrapolation and Contrastive Decoding. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.769
-
[63]
Multilingual Contrastive Decoding via Language-Agnostic Layers Skipping
Zhu, Wenhao and Liu, Sizhe and Huang, Shujian and She, Shuaijie and Wendler, Chris and Chen, Jiajun. Multilingual Contrastive Decoding via Language-Agnostic Layers Skipping. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.512
-
[64]
Sennrich, Rico and Vamvas, Jannis and Mohammadshahi, Alireza. Mitigating Hallucinations and Off-target Machine Translation with Source-Contrastive and Language-Contrastive Decoding. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.eacl-short.4
-
[65]
Contrastive Decoding Reduces Hallucinations in Large Multilingual Machine Translation Models
Waldendorf, Jonas and Haddow, Barry and Birch, Alexandra. Contrastive Decoding Reduces Hallucinations in Large Multilingual Machine Translation Models. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.155
-
[66]
Uncertainty-Aware Contrastive Decoding
Lee, Hakyung and Park, Subeen and Kim, Joowang and Lim, Sungjun and Song, Kyungwoo. Uncertainty-Aware Contrastive Decoding. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1352
-
[67]
Fu, Tingchen and Hou, Yupeng and McAuley, Julian and Yan, Rui. Unlocking Decoding-time Controllability: Gradient-Free Multi-Objective Alignment with Contrastive Prompts. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:...
-
[68]
Zhong, Qihuang and Ding, Liang and Liu, Juhua and Du, Bo and Tao, Dacheng. ROSE Doesn ' t Do That: Boosting the Safety of Instruction-Tuned Large Language Models with Reverse Prompt Contrastive Decoding. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.814
-
[69]
P rune CD : Contrasting Pruned Self Model to Improve Decoding Factuality
Yu, Byeongho and Lee, Changhun and Jin, Jun-gyu and Park, Eunhyeok. P rune CD : Contrasting Pruned Self Model to Improve Decoding Factuality. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1651
-
[70]
URL https: //aclanthology.org/2025.acl-long.919/
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[71]
Adaptation of Large Language Models
Ke, Zixuan and Ming, Yifei and Joty, Shafiq. Adaptation of Large Language Models. Proceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 5: Tutorial Abstracts). 2025. doi:10.18653/v1/2025.naacl-tutorial.5
-
[72]
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[73]
Sub-1 B Language Models for Low-Resource Languages: Training Strategies and Insights for B asque
Urbizu, Gorka and Corral, Ander and Saralegi, Xabier and San Vicente, I \ n aki. Sub-1 B Language Models for Low-Resource Languages: Training Strategies and Insights for B asque. Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025). 2025. doi:10.18653/v1/2025.mrl-main.35
-
[74]
and Lange, Lukas and Adel, Heike and Str
Hedderich, Michael A. and Lange, Lukas and Adel, Heike and Str. A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.201
-
[75]
Hit the Sweet Spot! Span-Level Ensemble for Large Language Models
Xu, Yangyifan and Chen, Jianghao and Wu, Junhong and Zhang, Jiajun. Hit the Sweet Spot! Span-Level Ensemble for Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[76]
Documenting Large Webtext Corpora:
Dodge, Jesse and Sap, Maarten and Marasovi \'c , Ana and Agnew, William and Ilharco, Gabriel and Groeneveld, Dirk and Mitchell, Margaret and Gardner, Matt. Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021....
-
[77]
doi: 10.18653/v1/2024.emnlp-industry.36
Goddard, Charles and Siriwardhana, Shamane and Ehghaghi, Malikeh and Meyers, Luke and Karpukhin, Vladimir and Benedict, Brian and McQuade, Mark and Solawetz, Jacob. Arcee ' s M erge K it: A Toolkit for Merging Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024. doi:10.18653/v...
-
[78]
Proxy Tuning for Financial Sentiment Analysis: Overcoming Data Scarcity and Computational Barriers
Wang, Yuxiang and Wang, Yuchi and Liu, Yi and Bao, Ruihan and Harimoto, Keiko and Sun, Xu. Proxy Tuning for Financial Sentiment Analysis: Overcoming Data Scarcity and Computational Barriers. Proceedings of the Joint Workshop of the 9th Financial Technology and Natural Language Processing (FinNLP), the 6th Financial Narrative Processing (FNP), and the 1st ...
2025
-
[79]
Back to School: Translation Using Grammar Books
Hus, Jonathan and Anastasopoulos, Antonios. Back to School: Translation Using Grammar Books. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1127
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.