Recognition: unknown
Decisive: Guiding User Decisions with Optimal Preference Elicitation from Unstructured Documents
Pith reviewed 2026-05-10 05:08 UTC · model grok-4.3
The pith
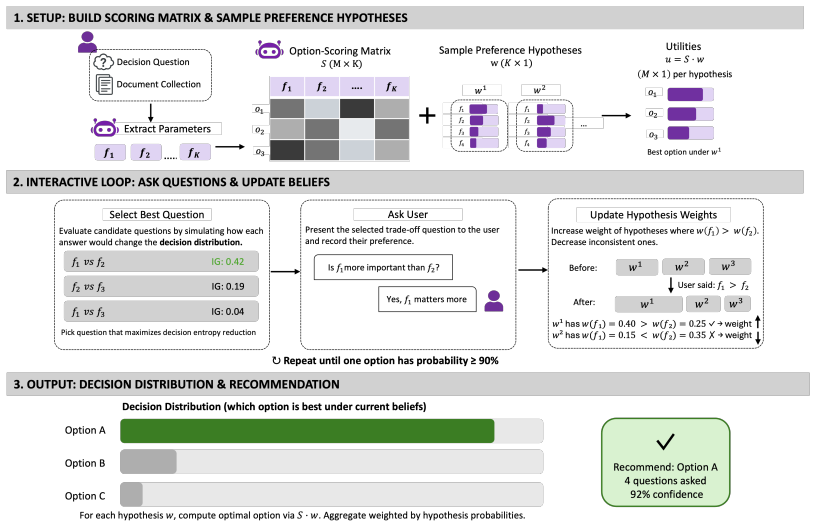
Decisive improves decision accuracy up to 20% by extracting option scores from documents and adaptively learning user preferences through targeted pairwise questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that grounding decisions in a document-derived option-scoring matrix and updating a latent preference vector via information-gain-maximizing pairwise elicitations produces more accurate, transparent, and personalized recommendations than existing LLM-based or decision-support approaches.
What carries the argument
The adaptive elicitation module that selects pairwise questions to maximize expected information gain over the final decision, paired with Bayesian updates to the user's latent preference vector.
Load-bearing premise
The method assumes that an accurate and complete option-scoring matrix can be extracted from unstructured documents and that user preferences are adequately captured by a low-dimensional latent vector.
What would settle it
An experiment in which the automatically extracted scoring matrix contains systematic errors or in which real user preferences require more than the assumed number of dimensions, resulting in no accuracy gain over baselines.
Figures


read the original abstract
Decision-making is a cognitively intensive task that requires synthesizing relevant information from multiple unstructured sources, weighing competing factors, and incorporating subjective user preferences. Existing methods, including large language models and traditional decision-support systems, fall short: they often overwhelm users with information or fail to capture nuanced preferences accurately. We present Decisive, an interactive decision-making framework that combines document-grounded reasoning with Bayesian preference inference. Our approach grounds decisions in an objective option-scoring matrix extracted from source documents, while actively learning a user's latent preference vector through targeted elicitation. Users answer pairwise tradeoff questions adaptively selected to maximize information gain over the final decision. This process converges efficiently, minimizing user effort while ensuring recommendations remain transparent and personalized. Through extensive experiments, we demonstrate that our approach significantly outperforms both general-purpose LLMs and existing decision-making frameworks achieving up to 20% improvement in decision accuracy over strong baselines across domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Decisive, an interactive decision-making framework that extracts an option-scoring matrix from unstructured documents to ground decisions objectively, then uses Bayesian inference to learn a user's low-dimensional latent preference vector via adaptively selected pairwise tradeoff questions that maximize information gain, claiming up to 20% gains in decision accuracy over general-purpose LLMs and existing frameworks across domains.
Significance. If the document extraction step can be shown to be reliable and the experimental results hold under scrutiny, the work could advance interactive decision support by combining document grounding with efficient, transparent preference elicitation that minimizes user effort. The information-gain selection mechanism is a standard but well-applied strength here.
major comments (2)
- [Abstract] Abstract: the central claim of 'up to 20% improvement in decision accuracy over strong baselines' is stated without any details on experimental design, baseline implementations, statistical tests, error bars, or domain specifications, making it impossible to assess whether the data support the claim.
- [Method] Method section (option-scoring matrix extraction): the framework's performance claims rest on the assumption that an accurate and complete option-scoring matrix can be reliably extracted from unstructured documents, yet no human-validated extraction accuracy, inter-annotator agreement, or ablation on extraction noise is reported; this is load-bearing because any downstream Bayesian gains cannot be attributed to the elicitation if the matrix is systematically distorted.
minor comments (1)
- [Abstract] The abstract could clarify the specific domains tested and the exact definition of 'decision accuracy' used in the experiments.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our paper. We provide point-by-point responses to the major comments and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'up to 20% improvement in decision accuracy over strong baselines' is stated without any details on experimental design, baseline implementations, statistical tests, error bars, or domain specifications, making it impossible to assess whether the data support the claim.
Authors: We agree that the abstract would be strengthened by including more details about the claim. In the revised manuscript, we have updated the abstract to mention the specific domains (product selection, travel planning, and medical decision support), the baselines (general-purpose LLMs such as GPT-4 and existing decision frameworks), and that the improvements are statistically significant with error bars provided in the main experimental results. This allows readers to better evaluate the claim without exceeding abstract length limits. revision: yes
-
Referee: [Method] Method section (option-scoring matrix extraction): the framework's performance claims rest on the assumption that an accurate and complete option-scoring matrix can be reliably extracted from unstructured documents, yet no human-validated extraction accuracy, inter-annotator agreement, or ablation on extraction noise is reported; this is load-bearing because any downstream Bayesian gains cannot be attributed to the elicitation if the matrix is systematically distorted.
Authors: This comment correctly identifies a gap in the original submission. We did not report human validation or noise ablation for the matrix extraction. We will add an ablation study in the revised Experiments section that simulates extraction noise by perturbing the scoring matrix entries and measures the resulting change in decision accuracy. This will show that the adaptive elicitation provides benefits even under moderate distortion. However, a full human validation study with inter-annotator agreement was not conducted in the original work and would require additional resources; we note this as a limitation and plan to address it in follow-up research. revision: partial
- Full human-validated extraction accuracy and inter-annotator agreement for the option-scoring matrix extraction, as this was not performed in the original experiments.
Circularity Check
No circularity: standard Bayesian elicitation loop with independent extraction step
full rationale
The paper describes a pipeline that first extracts an option-scoring matrix from documents (treated as an external input) and then runs a standard Bayesian update on a latent preference vector using information-gain-selected pairwise queries. No equation, algorithm, or claim in the abstract or described framework reduces the final accuracy improvement or the preference vector itself to a fitted parameter or self-referential quantity by construction. The derivation chain remains open to external validation of the extraction accuracy and does not collapse into its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption User preferences can be represented as a latent vector that is updated via Bayesian inference from pairwise comparisons
- domain assumption An objective option-scoring matrix can be extracted from unstructured source documents
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2025 , eprint=
Exploring the Impact of Explainable AI and Cognitive Capabilities on Users' Decisions , author=. 2025 , eprint=
2025
-
[5]
Perspectives on Psychological Science , year =
Mark Steyvers and Akshay Kumar , title =. Perspectives on Psychological Science , year =. doi:10.1177/17456916231181102 , pmid =
-
[6]
2024 , eprint=
DeLLMa: Decision Making Under Uncertainty with Large Language Models , author=. 2024 , eprint=
2024
-
[7]
2025 , eprint=
DecisionFlow: Advancing Large Language Model as Principled Decision Maker , author=. 2025 , eprint=
2025
-
[8]
Jurnal Informatika Ekonomi Bisnis , author=
Artificial Intelligence in Financial Decision-Making: Opportunities and Challenges for Investment Strategies , volume=. Jurnal Informatika Ekonomi Bisnis , author=. 2025 , month=. doi:10.37034/infeb.v7i2.1140 , abstractNote=
-
[9]
Education Sciences , VOLUME =
Shi, Lehong and Ding, Ai-Chu (Elisha) and Choi, Ikseon , TITLE =. Education Sciences , VOLUME =. 2024 , NUMBER =
2024
-
[10]
Health Services Research and Managerial Epidemiology , volume =
Khosravi, Maryam and Zare, Zahra and Mojtabaeian, Seyed Mohammad and Izadi, Reza , title =. Health Services Research and Managerial Epidemiology , volume =. 2024 , publisher =
2024
-
[11]
2024 , eprint=
Language Models are Alignable Decision-Makers: Dataset and Application to the Medical Triage Domain , author=. 2024 , eprint=
2024
-
[12]
2024 , eprint=
Large language models in healthcare and medical domain: A review , author=. 2024 , eprint=
2024
-
[13]
Jia Li and Zichun Zhou and Han Lyu and Zhenchang Wang , keywords =. Large language models-powered clinical decision support: enhancing or replacing human expertise? , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.imed.2025.01.001 , url =
-
[14]
Maity, S. and Saikia, M. J. , title =. Bioengineering (Basel) , year =. doi:10.3390/bioengineering12060631 , pmid =
-
[15]
2024 , eprint=
MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making , author=. 2024 , eprint=
2024
-
[16]
Indraprasta and Ach Salman Faridzi and Bagus M
Khanisyah Erza Gumilar and Birama R. Indraprasta and Ach Salman Faridzi and Bagus M. Wibowo and Aditya Herlambang and Eccita Rahestyningtyas and Budi Irawan and Zulkarnain Tambunan and Ahmad Fadhli Bustomi and Bagus Ngurah Brahmantara and Zih-Ying Yu and Yu-Cheng Hsu and Herlangga Pramuditya and Very Great E. Putra and Hari Nugroho and Pungky Mulawardhana...
-
[17]
Foo, Charisse and Foong, Pin Sym and Nadal, Camille and Ureyang, Natasha and Naylin, Thant and Koh, Gerald Choon Huat , title =. Proceedings of the 2025 ACM Designing Interactive Systems Conference , pages =. 2025 , isbn =. doi:10.1145/3715336.3735779 , abstract =
-
[18]
2024 , eprint=
Determinants of LLM-assisted Decision-Making , author=. 2024 , eprint=
2024
-
[19]
Management Journal for Advanced Research , year =
Alexander Changeux and Stephen Montagnier , title =. Management Journal for Advanced Research , year =. doi:10.5281/zenodo.13444483 , url =
-
[20]
2025 , eprint=
Large Language Models for Supply Chain Decisions , author=. 2025 , eprint=
2025
-
[21]
2024 , eprint=
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent , author=. 2024 , eprint=
2024
-
[22]
2024 , eprint=
FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making , author=. 2024 , eprint=
2024
-
[23]
2024 , eprint=
MAPLE: A Framework for Active Preference Learning Guided by Large Language Models , author=. 2024 , eprint=
2024
-
[24]
The First Workshop on System-2 Reasoning at Scale, NeurIPS'24 , year=
Can Language Models Perform Implicit Bayesian Inference Over User Preference States? , author=. The First Workshop on System-2 Reasoning at Scale, NeurIPS'24 , year=
-
[25]
2024 , eprint=
STaR-GATE: Teaching Language Models to Ask Clarifying Questions , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
TO-GATE: Clarifying Questions and Summarizing Responses with Trajectory Optimization for Eliciting Human Preference , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions , author=. 2025 , eprint=
2025
-
[28]
2024 , eprint=
Active Preference Inference using Language Models and Probabilistic Reasoning , author=. 2024 , eprint=
2024
-
[29]
Language Models are Alignable Decision-Makers: Dataset and Application to the Medical Triage Domain
Hu, Brian and Ray, Bill and Leung, Alice and Summerville, Amy and Joy, David and Funk, Christopher and Basharat, Arslan. Language Models are Alignable Decision-Makers: Dataset and Application to the Medical Triage Domain. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techn...
-
[30]
2025 , eprint=
ChoiceMates: Supporting Unfamiliar Online Decision-Making with Multi-Agent Conversational Interactions , author=. 2025 , eprint=
2025
-
[31]
2024 , eprint=
Decision-Making Behavior Evaluation Framework for LLMs under Uncertain Context , author=. 2024 , eprint=
2024
-
[32]
Clarify When Necessary: Resolving Ambiguity Through Interaction with LM s
Zhang, Michael JQ and Choi, Eunsol. Clarify When Necessary: Resolving Ambiguity Through Interaction with LM s. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.306
-
[33]
Teaching
Chang, Shane , month = may, year =. Teaching
-
[34]
2025 , eprint=
InfoQuest: Evaluating Multi-Turn Dialogue Agents for Open-Ended Conversations with Hidden Context , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
Do LLMs Recognize Your Latent Preferences? A Benchmark for Latent Information Discovery in Personalized Interaction , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Asking Clarifying Questions for Preference Elicitation With Large Language Models , author=. 2025 , eprint=
2025
-
[37]
2024 , eprint=
Bayesian Preference Elicitation with Language Models , author=. 2024 , eprint=
2024
-
[38]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =
Ma, Shuai and Chen, Qiaoyi and Wang, Xinru and Zheng, Chengbo and Peng, Zhenhui and Yin, Ming and Ma, Xiaojuan , title =. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =. 2025 , isbn =. doi:10.1145/3706598.3713423 , abstract =
-
[39]
Generative AI for decision-making: A multidisciplinary perspective , journal =
Mousa Albashrawi , keywords =. Generative AI for decision-making: A multidisciplinary perspective , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.jik.2025.100751 , url =
-
[40]
Responsible. Scientific Reports , author =. 2025 , pages =. doi:10.1038/s41598-025-22127-7 , language =
-
[41]
J ob F air: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Wang, Ze and Wu, Zekun and Guan, Xin and Thaler, Michael and Koshiyama, Adriano and Lu, Skylar and Beepath, Sachin and Ertekin, Ediz and Perez-Ortiz, Maria. J ob F air: A Framework for Benchmarking Gender Hiring Bias in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.184
-
[42]
2023 , eprint=
Are Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT , author=. 2023 , eprint=
2023
-
[43]
2021 , url =
Snehaan Bhawal , title =. 2021 , url =
2021
-
[44]
2025 , eprint=
Do LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs , author=. 2025 , eprint=
2025
-
[45]
2024 , eprint=
UMBRELA: UMbrela is the (Open-Source Reproduction of the) Bing RELevance Assessor , author=. 2024 , eprint=
2024
-
[46]
Doucet, Arnaud and Johansen, Adam M. , url =. The Oxford handbook of nonlinear filtering , title =. 2011 , series =
2011
-
[47]
IEEE Trans
A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking , author=. IEEE Trans. Signal Process. , year=
-
[48]
Pu, Pearl and Chen, Li , title =. AI Mag. , month = dec, pages =. 2008 , issue_date =. doi:10.1609/aimag.v29i4.2200 , abstract =
-
[49]
Proceedings of the 6th ACM Conference on Electronic Commerce , pages =
Pu, Pearl and Chen, Li , title =. Proceedings of the 6th ACM Conference on Electronic Commerce , pages =. 2005 , isbn =. doi:10.1145/1064009.1064038 , abstract =
-
[50]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =
Real-time Multiattribute Bayesian Preference Elicitation with Pairwise Comparison Queries , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , editor =
2010
-
[51]
Proceedings of the 18th ACM Conference on Recommender Systems , pages =
Austin, David and Korikov, Anton and Toroghi, Armin and Sanner, Scott , title =. Proceedings of the 18th ACM Conference on Recommender Systems , pages =. 2024 , isbn =. doi:10.1145/3640457.3688142 , abstract =
-
[52]
Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022
2022
-
[53]
A Systematic Survey of Text Worlds as Embodied Natural Language Environments
Jansen, Peter. A Systematic Survey of Text Worlds as Embodied Natural Language Environments. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.1
-
[54]
A Minimal Computational Improviser Based on Oral Thought
Montfort, Nick and Bartlett Fernandez, Sebastian. A Minimal Computational Improviser Based on Oral Thought. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.2
-
[55]
Volum, Ryan and Rao, Sudha and Xu, Michael and DesGarennes, Gabriel and Brockett, Chris and Van Durme, Benjamin and Deng, Olivia and Malhotra, Akanksha and Dolan, Bill. Craft an Iron Sword: Dynamically Generating Interactive Game Characters by Prompting Large Language Models Tuned on Code. Proceedings of the 3rd Wordplay: When Language Meets Games Worksho...
-
[56]
A Sequence Modelling Approach to Question Answering in Text-Based Games
Furman, Gregory and Toledo, Edan and Shock, Jonathan and Buys, Jan. A Sequence Modelling Approach to Question Answering in Text-Based Games. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.4
-
[57]
Automatic Exploration of Textual Environments with Language-Conditioned Autotelic Agents
Teodorescu, Laetitia and Yuan, Xingdi and C \^o t \'e , Marc-Alexandre and Oudeyer, Pierre-Yves. Automatic Exploration of Textual Environments with Language-Conditioned Autotelic Agents. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.5
-
[58]
Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022
2022
-
[59]
Separating Hate Speech and Offensive Language Classes via Adversarial Debiasing
Yuan, Shuzhou and Maronikolakis, Antonis and Sch. Separating Hate Speech and Offensive Language Classes via Adversarial Debiasing. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.1
-
[60]
Towards Automatic Generation of Messages Countering Online Hate Speech and Microaggressions
Ashida, Mana and Komachi, Mamoru. Towards Automatic Generation of Messages Countering Online Hate Speech and Microaggressions. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.2
-
[61]
G rease V ision: Rewriting the Rules of the Interface
Datta, Siddhartha and Kollnig, Konrad and Shadbolt, Nigel. G rease V ision: Rewriting the Rules of the Interface. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.3
-
[62]
Ludwig, Florian and Dolos, Klara and Zesch, Torsten and Hobley, Eleanor. Improving Generalization of Hate Speech Detection Systems to Novel Target Groups via Domain Adaptation. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.4
-
[63]
`` Zo Grof ! '' : A Comprehensive Corpus for Offensive and Abusive Language in D utch
Ruitenbeek, Ward and Zwart, Victor and Van Der Noord, Robin and Gnezdilov, Zhenja and Caselli, Tommaso. `` Zo Grof ! '' : A Comprehensive Corpus for Offensive and Abusive Language in D utch. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.5
-
[64]
Counter- TWIT : An I talian Corpus for Online Counterspeech in Ecological Contexts
Goffredo, Pierpaolo and Basile, Valerio and Cepollaro, Bianca and Patti, Viviana. Counter- TWIT : An I talian Corpus for Online Counterspeech in Ecological Contexts. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.6
-
[65]
S tereo KG : Data-Driven Knowledge Graph Construction For Cultural Knowledge and Stereotypes
Deshpande, Awantee and Ruiter, Dana and Mosbach, Marius and Klakow, Dietrich. S tereo KG : Data-Driven Knowledge Graph Construction For Cultural Knowledge and Stereotypes. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.7
-
[66]
Lu, Christina and Jurgens, David. The subtle language of exclusion: Identifying the Toxic Speech of Trans-exclusionary Radical Feminists. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.8
-
[67]
Lost in Distillation: A Case Study in Toxicity Modeling
Chvasta, Alyssa and Lees, Alyssa and Sorensen, Jeffrey and Vasserman, Lucy and Goyal, Nitesh. Lost in Distillation: A Case Study in Toxicity Modeling. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.9
-
[68]
Cleansing & expanding the HURTLEX (el) with a multidimensional categorization of offensive words
Stamou, Vivian and Alexiou, Iakovi and Klimi, Antigone and Molou, Eleftheria and Saivanidou, Alexandra and Markantonatou, Stella. Cleansing & expanding the HURTLEX (el) with a multidimensional categorization of offensive words. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.10
-
[69]
Free speech or Free Hate Speech? Analyzing the Proliferation of Hate Speech in Parler
Israeli, Abraham and Tsur, Oren. Free speech or Free Hate Speech? Analyzing the Proliferation of Hate Speech in Parler. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.11
-
[70]
Resources for Multilingual Hate Speech Detection
Arango Monnar, Ayme and Perez, Jorge and Poblete, Barbara and Salda \ n a, Magdalena and Proust, Valentina. Resources for Multilingual Hate Speech Detection. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.12
-
[71]
Enriching Abusive Language Detection with Community Context
Saleem, Haji Mohammad and Kurrek, Jana and Ruths, Derek. Enriching Abusive Language Detection with Community Context. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.13
-
[72]
DeTox: A Comprehensive Dataset for G erman Offensive Language and Conversation Analysis
Demus, Christoph and Pitz, Jonas and Sch. DeTox: A Comprehensive Dataset for G erman Offensive Language and Conversation Analysis. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.14
-
[73]
Multilingual H ate C heck: Functional Tests for Multilingual Hate Speech Detection Models
R. Multilingual H ate C heck: Functional Tests for Multilingual Hate Speech Detection Models. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.15
-
[74]
Distributional properties of political dogwhistle representations in S wedish BERT
Hertzberg, Niclas and Cooper, Robin and Lindgren, Elina and R. Distributional properties of political dogwhistle representations in S wedish BERT. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.16
-
[75]
Hate Speech Criteria: A Modular Approach to Task-Specific Hate Speech Definitions
Khurana, Urja and Vermeulen, Ivar and Nalisnick, Eric and Van Noorloos, Marloes and Fokkens, Antske. Hate Speech Criteria: A Modular Approach to Task-Specific Hate Speech Definitions. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.17
-
[76]
Accounting for Offensive Speech as a Practice of Resistance
Diaz, Mark and Amironesei, Razvan and Weidinger, Laura and Gabriel, Iason. Accounting for Offensive Speech as a Practice of Resistance. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.18
-
[77]
Zheng, Joan and Friedman, Scott and Schmer-galunder, Sonja and Magnusson, Ian and Wheelock, Ruta and Gottlieb, Jeremy and Gomez, Diana and Miller, Christopher. Towards a Multi-Entity Aspect-Based Sentiment Analysis for Characterizing Directed Social Regard in Online Messaging. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:1...
-
[78]
Flexible text generation for counterfactual fairness probing
Fryer, Zee and Axelrod, Vera and Packer, Ben and Beutel, Alex and Chen, Jilin and Webster, Kellie. Flexible text generation for counterfactual fairness probing. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.20
-
[79]
Users Hate Blondes: Detecting Sexism in User Comments on Online R omanian News
Moldovan, Andreea and Cs. Users Hate Blondes: Detecting Sexism in User Comments on Online R omanian News. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.21
-
[80]
Targeted Identity Group Prediction in Hate Speech Corpora
Sachdeva, Pratik and Barreto, Renata and Von Vacano, Claudia and Kennedy, Chris. Targeted Identity Group Prediction in Hate Speech Corpora. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.