Recognition: unknown
FreezeEmpath: Efficient Training for Empathetic Spoken Chatbots with Frozen LLMs
Pith reviewed 2026-05-10 04:53 UTC · model grok-4.3
The pith
Empathetic spoken chatbots can be trained by freezing the LLM and adapting only its non-LLM components on existing speech instruction and emotion data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FreezeEmpath demonstrates that an end-to-end empathetic spoken chatbot can be obtained by keeping the LLM frozen and training only the non-LLM components on existing speech instruction data and speech emotion recognition data, resulting in emotionally expressive speech output that outperforms other empathetic models on empathetic dialogue, SER, and SpokenQA tasks.
What carries the argument
Freezing the LLM parameters while training auxiliary speech and emotion modules solely on standard instruction and SER datasets.
If this is right
- The model generates emotionally expressive speech that reflects detected user emotions.
- It achieves higher performance than prior empathetic models on empathetic dialogue tasks.
- It improves accuracy on speech emotion recognition tasks.
- It delivers better results on SpokenQA tasks.
- The frozen LLM retains its original general capabilities with no observed degradation.
Where Pith is reading between the lines
- The same freezing pattern could be applied to add other specialized behaviors to LLMs without full retraining.
- Developers working with limited resources might replicate the approach using only public speech datasets for new languages or domains.
- Updating the underlying LLM later would require retraining only the auxiliary modules rather than the entire empathetic system.
Load-bearing premise
That training only the non-LLM parts on existing speech instruction and SER data is enough to add both empathetic responses and emotional expressiveness without any loss in the frozen LLM's abilities.
What would settle it
A direct comparison showing that FreezeEmpath's responses to emotional speech inputs receive empathy ratings no higher than those from an unmodified frozen LLM paired with a basic text-to-speech system, or that its output speech exhibits no measurable variation in prosody tied to detected emotions.
Figures



read the original abstract
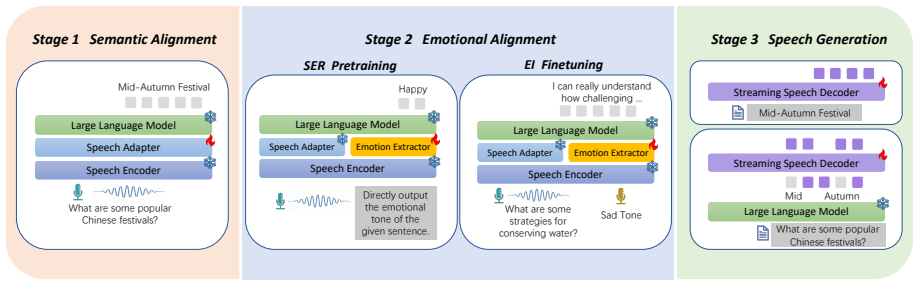
Empathy is essential for fostering natural interactions in spoken dialogue systems, as it enables machines to recognize the emotional tone of human speech and deliver empathetic responses. Recent research has made significant progress in developing empathetic spoken chatbots based on large language models (LLMs). However, several challenges still exist when training such models, including reliance on costly empathetic speech instruction data and a lack of emotional expressiveness in the generated speech. Finetuning LLM with cross-modal empathetic instruction data may also lead to catastrophic forgetting and a degradation of its general capability. To address these challenges, we propose FreezeEmpath, an end-to-end empathetic spoken chatbot trained in a simple and efficient manner. The entire training process relies solely on existing speech instruction data and speech emotion recognition (SER) data, while keeping the LLM's parameters frozen. Experiments demonstrate that FreezeEmpath is able to generate emotionally expressive speech and outperforms other empathetic models in empathetic dialogue, SER, and SpokenQA tasks, demonstrating the effectiveness of our training strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FreezeEmpath, an end-to-end empathetic spoken chatbot that freezes the LLM parameters entirely and trains only non-LLM components (adapters, SER head, and TTS) using existing speech instruction data and speech emotion recognition (SER) corpora. It claims this avoids catastrophic forgetting, eliminates the need for costly empathetic speech instruction data, produces emotionally expressive speech output, and outperforms prior empathetic models on empathetic dialogue, SER, and SpokenQA tasks.
Significance. If the empirical claims hold under rigorous controls, the approach would be significant for enabling efficient, low-cost development of multimodal empathetic dialogue systems while preserving the general capabilities of large frozen LLMs. The strategy of leveraging off-the-shelf SER data to condition response generation without LLM updates addresses a practical bottleneck in scaling empathetic spoken agents.
major comments (3)
- [§4] §4 (Experiments) and associated tables: The central claim that SER conditioning enables the frozen LLM to produce empathetic rather than generic responses lacks load-bearing ablations. No results are shown for a controlled variant with SER signals removed (or replaced by random labels) while keeping all other components fixed; without this, it is impossible to confirm that empathy arises from the injected signals rather than the base LLM or speech-instruction training alone.
- [§3.2] §3.2 (Architecture) and §4.2 (Training details): The mechanism by which SER-derived emotion embeddings are injected into the frozen LLM (e.g., prefix tokens, cross-attention layers, or adapter fusion) is described at a high level but without equations or diagrams specifying dimensionality, fusion points, or gradient flow. This makes it difficult to evaluate whether the conditioning is deep enough to meaningfully shift the LLM's output distribution on empathy-related prompts.
- [Table 2] Table 2 (Empathetic dialogue results): The reported gains over baselines are presented without statistical significance tests, confidence intervals, or human evaluation details (e.g., number of annotators, inter-annotator agreement). Given that the LLM is frozen, any improvement must be isolated to the non-LLM modules; the current presentation does not allow readers to assess whether the gains are robust or task-specific.
minor comments (2)
- [§1] The abstract and §1 claim 'outperforms other empathetic models' but do not name the exact baselines or cite their original papers in the experimental section; add explicit citations and a comparison table.
- [Figure 1] Figure 1 (system diagram) uses acronyms (SER, TTS, LLM) without a legend; expand the caption to define all components for readers unfamiliar with the pipeline.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our paper. We appreciate the opportunity to clarify and strengthen our work. Below, we provide point-by-point responses to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: §4 (Experiments) and associated tables: The central claim that SER conditioning enables the frozen LLM to produce empathetic rather than generic responses lacks load-bearing ablations. No results are shown for a controlled variant with SER signals removed (or replaced by random labels) while keeping all other components fixed; without this, it is impossible to confirm that empathy arises from the injected signals rather than the base LLM or speech-instruction training alone.
Authors: We agree that this ablation is essential to validate the contribution of SER conditioning. In the revised version, we will add experimental results for a controlled variant where SER signals are replaced by random emotion labels, with all other components unchanged. This will isolate the effect of the emotion embeddings on generating empathetic responses. revision: yes
-
Referee: §3.2 (Architecture) and §4.2 (Training details): The mechanism by which SER-derived emotion embeddings are injected into the frozen LLM (e.g., prefix tokens, cross-attention layers, or adapter fusion) is described at a high level but without equations or diagrams specifying dimensionality, fusion points, or gradient flow. This makes it difficult to evaluate whether the conditioning is deep enough to meaningfully shift the LLM's output distribution on empathy-related prompts.
Authors: We will revise §3.2 to include precise mathematical formulations for the emotion embedding injection process, specifying dimensions, fusion method (adapter-based fusion at specific layers), and confirming that gradients do not flow to the frozen LLM parameters. Additionally, we will include a detailed architecture diagram to illustrate the injection points and overall flow. revision: yes
-
Referee: Table 2 (Empathetic dialogue results): The reported gains over baselines are presented without statistical significance tests, confidence intervals, or human evaluation details (e.g., number of annotators, inter-annotator agreement). Given that the LLM is frozen, any improvement must be isolated to the non-LLM modules; the current presentation does not allow readers to assess whether the gains are robust or task-specific.
Authors: We will enhance the presentation of Table 2 by adding statistical significance tests and confidence intervals. We will also provide details on the human evaluation, including the number of annotators and inter-annotator agreement. Since the LLM is frozen, we will clarify that improvements come from the non-LLM modules. revision: yes
Circularity Check
No circularity: purely empirical training recipe with no derivations
full rationale
The paper describes an empirical training strategy for an empathetic spoken chatbot that freezes the LLM and trains only adapters, SER head, and TTS components on existing speech-instruction and SER corpora. No equations, closed-form derivations, or first-principles predictions appear; performance claims rest on experimental comparisons rather than any quantity that reduces by construction to fitted inputs or self-citations. The central premise (that SER conditioning injected into a frozen LLM suffices for empathy) is presented as a testable hypothesis evaluated on downstream tasks, not as a self-definitional or load-bearing self-citation result. This is the most common honest finding for non-mathematical engineering papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Trans- actions on Audio, Speech and Language Processing
Emozionalmente: A crowdsourced corpus of simulated emotional speech in italian. IEEE Trans- actions on Audio, Speech and Language Processing . Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou
-
[2]
Qwen2-audio technical report. Preprint, arXiv:2407.10759. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. ...
work page internal anchor Pith review arXiv 2025
-
[3]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
A canadian french emotional speech dataset. In Proceedings of the 9th ACM multimedia systems conference, pages 399–402. Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdel- rahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transaction...
work page internal anchor Pith review arXiv 2021
-
[4]
In Proceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long Papers), pages 6626–6642
Advancing large language models to capture varied speaking styles and respond properly in spoken conversations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long Papers), pages 6626–6642. Yuanyuan Liu, Wei Dai, Chuanxu Feng, Wenbin Wang, Guanghao Yin, Jiabei Zeng, and Shiguang Shan
-
[5]
A survey on speech large language models for understanding,
Mafw: A large-scale, multi-modal, com- pound affective database for dynamic facial expres- sion recognition in the wild. In Proceedings of the 30th ACM international conference on multimedia , pages 24–32. Steven R Livingstone and Frank A Russo. 2018. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of fa...
-
[6]
E-chat: Emotion-sensitive spoken dialogue system with large language models. CoRR. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report. Prepri...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Steering language model to stable speech emo- tion recognition via contextual perception and chain of thought. Preprint, arXiv:2502.18186. Kun Zhou, Berrak Sisman, Rui Liu, and Haizhou Li. 2022. Emotional voice conversion: Theory, databases and esd. Speech Communication, 137:1– 18. Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingc...
-
[8]
Efficient Training for Cross-lingual Speech Language Models
Efficient training for cross-lingual speech lan- guage models. Preprint, arXiv:2604.11096. A SER Datasets The SER datasets used for training and evaluation are summarized in Table 7. Considering the im- balance in the number of samples across different emotion categories, we retain only the data cor- responding to the following five emotions across all SE...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The user’s speech input’s text instruction, which contains an emotional expression from the user
-
[10]
The emotional tone of user’s speech input
-
[11]
## Scoring Criteria Rate each generated audio according to the two criteria below:
The model’s speech response. ## Scoring Criteria Rate each generated audio according to the two criteria below:
-
[12]
Did the style of the generated speech (tone, emotion, warmth, intensity, etc.) fit the user’s emotion? - If the user is feeling happy, the speech response should be cheerful and enthusiastic - If the user is feeling sad, the speech response should be gentle, comforting, and empathetic - If the user is feeling angry, the speech response should be empatheti...
-
[13]
Is the speech highly natural, with human-like prosody and standard pronunciation, without sounding like TTS-synthesized audio? Please directly rate the score with simple explanations. - If none of the criteria above are met, rate: [[1]], - If only one of the criteria is met, rate: [[5]] - If both criteria are met, rate: [[10]] # User’s Input Speech Instru...
2025
-
[14]
Speech Feature + Emotion Feature: The same setting of FreezeEmpath
-
[15]
Text Script + Emotion Feature: The speech features are replaced with textual transcrip- tions of the speech
-
[16]
Text Script + Emotion Label (Random): The emotion features from the emotion extractor are replaced with a random emotion label
-
[17]
The results are shown in Table 5
Text Script + Emotion Label (GT): The emo- tion features from the emotion extractor are replaced with the ground-truth emotion label. The results are shown in Table 5. The quality scores of Settings 1 and 2 are highly comparable, indi- cating the effectiveness of the semantic alignment training strategy and the speech adapter. Compared with Setting 1, Set...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.