Recognition: unknown
Scalable Neighborhood-Based Multi-Agent Actor-Critic
Pith reviewed 2026-05-10 05:15 UTC · model grok-4.3
The pith
MADDPG-K restricts each agent's critic to the k closest agents by Euclidean distance to keep critic input size constant as the number of agents grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MADDPG-K is a modification to MADDPG where each agent's critic is conditioned only on the observations and actions of the k closest agents according to Euclidean distance. This produces a constant-size critic input, reducing the growth in computational cost from linear in the number of agents to a fixed size per agent while retaining the benefits of centralized training during learning.
What carries the argument
The k-nearest-neighbor restriction on the critic input using Euclidean distance, which selects a fixed number of agents to include in the value estimation regardless of total population size.
Load-bearing premise
The assumption that the k closest agents under Euclidean distance provide enough information for the critic to accurately estimate the joint value, with distant agents contributing little.
What would settle it
An experiment in which performance of MADDPG-K drops significantly below MADDPG for large agent counts or in environments where non-local interactions dominate.
Figures
















read the original abstract
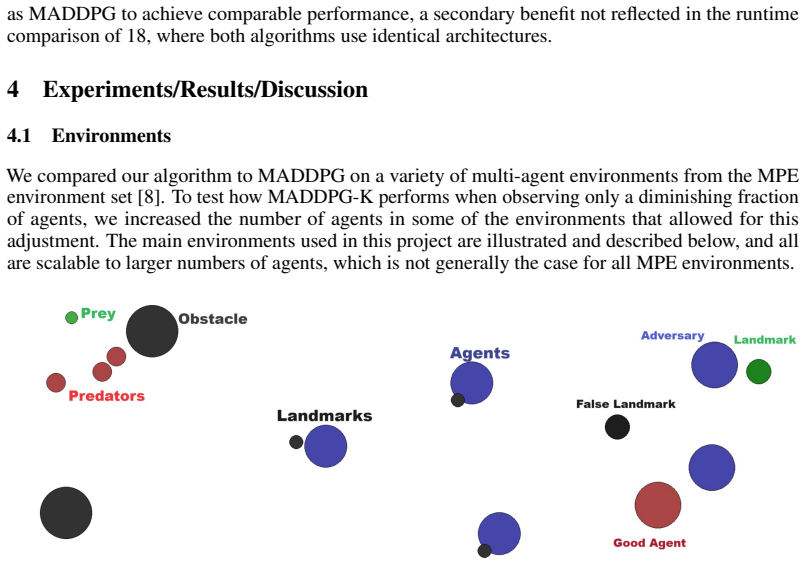
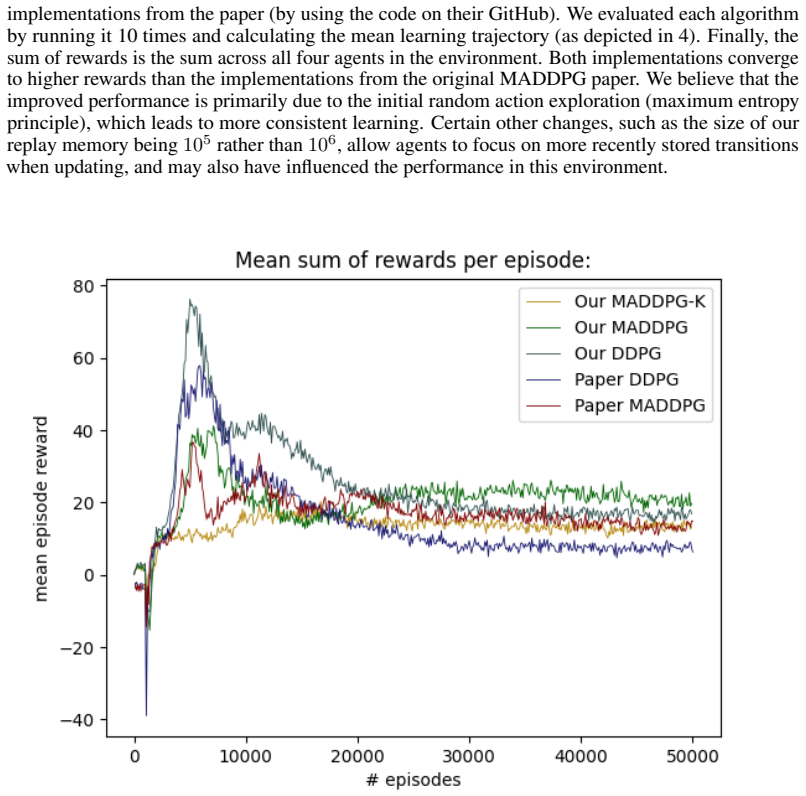
We propose MADDPG-K, a scalable extension to Multi-Agent Deep Deterministic Policy Gradient (MADDPG) that addresses the computational limitations of centralized critic approaches. Centralized critics, which condition on the observations and actions of all agents, have demonstrated significant performance gains in cooperative and competitive multi-agent settings. However, their critic networks grow linearly in input size with the number of agents, making them increasingly expensive to train at scale. MADDPG-K mitigates this by restricting each agent's critic to the $k$ closest agents under a chosen metric which in our case is Euclidean distance. This ensures a constant-size critic input regardless of the total agent count. We analyze the complexity of this approach, showing that the quadratic cost it retains arises from cheap scalar distance computations rather than the expensive neural network matrix multiplications that bottleneck standard MADDPG. We validate our method empirically across cooperative and adversarial environments from the Multi-Particle Environment suite, demonstrating competitive or superior performance compared to MADDPG, faster convergence in cooperative settings, and better runtime scaling as the number of agents grows. Our code is available at https://github.com/TimGop/MADDPG-K .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MADDPG-K, a scalable extension of MADDPG in which each agent's critic is restricted to the observations and actions of only the k nearest agents (selected by Euclidean distance). This keeps critic input size constant independent of total agent count N. The authors provide a complexity argument that the retained quadratic term consists of inexpensive scalar distance computations rather than costly neural-network matrix multiplies, and they report empirical results on cooperative and competitive tasks from the Multi-Particle Environment showing competitive performance, faster convergence in some settings, and improved runtime scaling with growing N.
Significance. If the locality heuristic proves robust, the method offers a practical route to scaling centralized-critic MARL to agent populations that would otherwise be computationally prohibitive. The explicit separation of cheap distance calculations from expensive network operations is a useful engineering insight, and the public code release supports reproducibility.
major comments (1)
- [Empirical validation] Empirical validation section: the central claim that k-nearest Euclidean neighbors preserve sufficient information for accurate value estimation is load-bearing yet supported only by aggregate performance numbers. No ablation on the choice of k, no comparison against random or learned neighbor selection, and no statistical tests (multiple seeds, error bars, significance) are described, leaving the weakest assumption untested and the scaling claims difficult to evaluate.
minor comments (1)
- [Abstract] The abstract states that runtime scaling improves 'as the number of agents grows' but does not indicate the concrete range of N tested or how wall-clock time was measured; adding these details would strengthen the complexity narrative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on empirical validation below and will incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Empirical validation] Empirical validation section: the central claim that k-nearest Euclidean neighbors preserve sufficient information for accurate value estimation is load-bearing yet supported only by aggregate performance numbers. No ablation on the choice of k, no comparison against random or learned neighbor selection, and no statistical tests (multiple seeds, error bars, significance) are described, leaving the weakest assumption untested and the scaling claims difficult to evaluate.
Authors: We agree that the sufficiency of the k-nearest Euclidean neighbors for value estimation is a central assumption and that the current empirical section relies primarily on aggregate performance metrics. While the reported results demonstrate competitive performance against MADDPG and improved runtime scaling, we acknowledge the absence of targeted ablations and statistical rigor. In the revised manuscript we will add: (1) an ablation study varying k across the evaluated environments, (2) a comparison against random neighbor selection (and, space permitting, a simple learned selection baseline), and (3) results averaged over multiple random seeds with error bars and appropriate statistical significance tests. These additions will directly test the locality heuristic and strengthen the scaling claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces MADDPG-K as a practical algorithmic modification to MADDPG, restricting each critic to the k Euclidean-nearest agents to achieve constant input size. This is justified by explicit complexity analysis (quadratic scalar distances vs. neural-network matrix multiplies) and empirical results on MPE tasks. No load-bearing derivation, fitted-parameter prediction, self-referential definition, or self-citation chain reduces the central claim to its own inputs by construction. The locality heuristic is presented as a domain-appropriate engineering choice rather than a mathematically derived necessity.
Axiom & Free-Parameter Ledger
free parameters (1)
- k
axioms (1)
- domain assumption Local neighborhood information under Euclidean distance is sufficient to approximate the centralized critic value function.
Reference graph
Works this paper leans on
-
[1]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.CoRR, abs/1606.01540, 2016. URL http: //arxiv.org/abs/1606.01540
work page internal anchor Pith review arXiv 2016
-
[2]
Counterfactual multi-agent policy gradients,
Jakob N. Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients.CoRR, abs/1705.08926, 2017. URL http://arxiv.org/abs/1705.08926
-
[3]
Addressing Function Approximation Error in Actor-Critic Methods
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods.CoRR, abs/1802.09477, 2018. URL http://arxiv.org/abs/1802. 09477
work page Pith review arXiv 2018
-
[5]
URLhttp://arxiv.org/abs/1801.01290
work page internal anchor Pith review arXiv
-
[6]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review arXiv 2015
-
[7]
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , url =
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments.CoRR, abs/1706.02275, 2017. URLhttp://arxiv.org/abs/1706.02275
-
[8]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning.CoRR, abs/1312.5602, 2013. URLhttp://arxiv.org/abs/1312.5602
work page internal anchor Pith review arXiv 2013
-
[9]
Emergence of grounded compositional language in multi- agent populations
Igor Mordatch and Pieter Abbeel. Emergence of grounded compositional language in multi- agent populations. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[10]
Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks,
Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V Albrecht. Com- parative evaluation of cooperative multi-agent deep reinforcement learning algorithms.arXiv preprint arXiv:2006.07869, 2020
-
[11]
Facmac: Factored multi-agent centralised policy gradients.Advances in Neural Information Processing Systems, 34:12208–12221, 2021
Bei Peng, Tabish Rashid, Christian Schroeder de Witt, Pierre-Alexandre Kamienny, Philip Torr, Wendelin Böhmer, and Shimon Whiteson. Facmac: Factored multi-agent centralised policy gradients.Advances in Neural Information Processing Systems, 34:12208–12221, 2021
2021
-
[12]
Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
2020
-
[13]
Actor-attention-critic for multi-agent reinforcement learning.International Conference on Machine Learning, 2018
Fei Sha Shariq Iqbal. Actor-attention-critic for multi-agent reinforcement learning.International Conference on Machine Learning, 2018
2018
-
[14]
Multi-agent reinforcement learning: Independent versus cooperative agents
Ming Tan. Multi-agent reinforcement learning: Independent versus cooperative agents. InIn- ternational Conference on Machine Learning, 1997. URL https://api.semanticscholar. org/CorpusID:268857333
1997
-
[15]
Terry, Benjamin Black, Ananth Hari, Luis S
Justin K. Terry, Benjamin Black, Ananth Hari, Luis S. Santos, Clemens Dieffendahl, Niall L. Williams, Yashas Lokesh, Caroline Horsch, and Praveen Ravi. Pettingzoo: Gym for multi-agent reinforcement learning.CoRR, abs/2009.14471, 2020. URL https://arxiv.org/abs/2009. 14471
-
[16]
Grandmaster level in starcraft ii using multi-agent reinforcement learning.Nature, 575(7782):350–354, 2019
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Jun- young Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning.Nature, 575(7782):350–354, 2019
2019
-
[17]
Mean field multi-agent reinforcement learning
Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. InInternational conference on machine learning, pages 5571–5580. PMLR, 2018. 10 A Appendix A.1 Configurations For both our DDPG and MADDPG implementations, we use the following hyperparameters and settings: • Adam optimizer with a learnin...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.