Recognition: unknown
Similarity-based Portfolio Construction for Black-box Optimization
Pith reviewed 2026-05-10 03:29 UTC · model grok-4.3
The pith
A naive portfolio of black-box optimizers built from training data already outperforms the virtual best solver.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
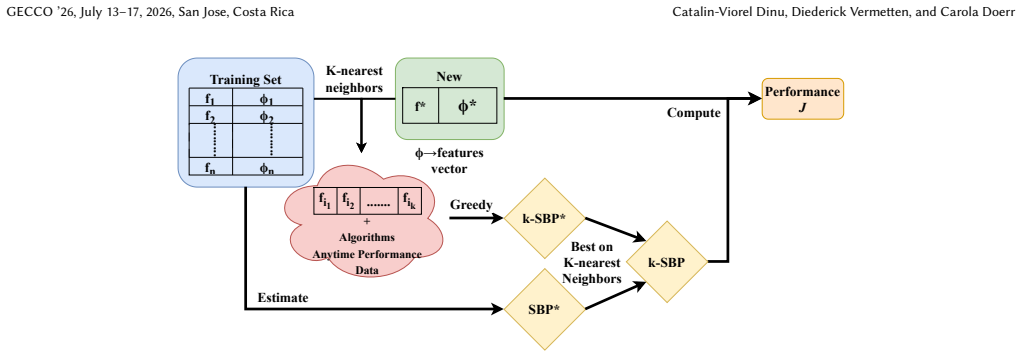
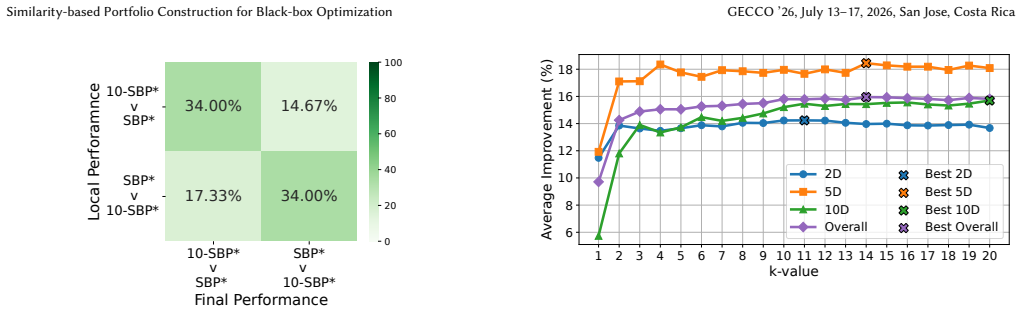
The authors show that a naive portfolio constructed over the full training set already outperforms the virtual best solver. They then introduce a k-nearest-neighbor-based finetuning approach that builds portfolios tailored to each unseen instance by drawing on similar training problems, and this step produces additional improvements. The work thereby establishes that portfolio construction is effective in the algorithm selection setting for fixed-budget black-box optimization.
What carries the argument
k-nearest-neighbor-based finetuning, which selects similar training instances to form an instance-specific portfolio of algorithms.
If this is right
- Portfolio allocation across algorithms reduces variance and exploits complementarities that single solvers miss.
- Even a training-set-wide portfolio exceeds the virtual best solver without any instance-specific adjustment.
- Similarity-based selection lets the portfolio adapt to new instances while retaining the benefits of diversification.
- The method works in fixed-budget regimes where the total number of evaluations is limited in advance.
Where Pith is reading between the lines
- Stronger or differently chosen similarity features could widen the performance gap shown here.
- The same portfolio logic could be tested on hyperparameter tuning or other selection tasks that involve multiple solvers.
- Applying the approach to fresh benchmark collections would test how far the similarity premise travels.
Load-bearing premise
Similarity between problem instances, measured by the chosen features, reliably indicates which algorithms will succeed on a new instance.
What would settle it
On a held-out collection of new problems, the similarity-based portfolio achieves lower average performance than the virtual best solver.
Figures



read the original abstract
In black-box optimization, a central question is which algorithm to use to solve a given, previously unseen, problem. Selecting a single algorithm, however, entails inherent risks: inaccuracies in the selector may lead to poor choices, and even well-performing algorithms with high variance can yield unsatisfactory results in a single run. A natural remedy is to split the evaluation budget across multiple runs of potentially different algorithms. Such sequential algorithm portfolios benefit from variance reduction and complementarities between algorithms, often outperforming approaches that allocate the entire budget to a single solver. While effective portfolios can be constructed post-hoc, transferring this idea to the algorithm selection setting is non-trivial. We show that a naive portfolio constructed over the full training set already outperforms the strongest traditional baseline, the virtual best solver. We then propose a simple yet effective k-nearest-neighbor-based finetuning approach to construct portfolios tailored to unseen instances, yielding further improvements and highlighting the effectiveness of portfolio selection in fixed-budget black-box optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript addresses algorithm selection for unseen black-box optimization problems by constructing sequential portfolios that split a fixed evaluation budget across multiple algorithms. It claims that a naive portfolio built from the full training set already outperforms the virtual best solver (VBS), and that a k-nearest-neighbor finetuning method using instance similarity yields further gains over this baseline.
Significance. If the central empirical claims hold after clarification, the work would be significant for black-box optimization and algorithm selection. It challenges the conventional preference for single-algorithm allocation (even against an oracle) by demonstrating practical benefits from variance reduction and complementarity in fixed-budget settings, while offering a simple similarity-based method for instance-specific portfolios that could be adopted in solver selection frameworks.
major comments (1)
- [Abstract and experimental results] Abstract and experimental results section: The load-bearing claim that 'a naive portfolio constructed over the full training set already outperforms the strongest traditional baseline, the virtual best solver' requires explicit justification. By standard definition, the VBS assigns the entire budget to the single best algorithm per instance, while any portfolio divides the budget across runs; outperformance is possible only under conditions such as high variance or strong algorithmic complementarity that offset the loss of evaluations. The manuscript should supply per-instance breakdowns, variance analysis, or statistical comparisons to substantiate this result rather than reporting aggregate outperformance alone.
minor comments (3)
- [Method] The description of the similarity measure used for kNN-based portfolio construction should be expanded with the specific instance features, distance metric, and choice of k (including any sensitivity analysis).
- [Experimental results] Experimental results should report error bars, confidence intervals, or statistical significance tests alongside the performance comparisons to allow readers to assess the reliability of the reported improvements.
- [Experimental setup] The number of problem instances, algorithms considered, and details of the train/test split should be stated explicitly to support reproducibility of the naive portfolio and kNN results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the claim of naive portfolio outperformance over the VBS requires stronger substantiation and will revise the manuscript to include the requested analyses.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results section: The load-bearing claim that 'a naive portfolio constructed over the full training set already outperforms the strongest traditional baseline, the virtual best solver' requires explicit justification. By standard definition, the VBS assigns the entire budget to the single best algorithm per instance, while any portfolio divides the budget across runs; outperformance is possible only under conditions such as high variance or strong algorithmic complementarity that offset the loss of evaluations. The manuscript should supply per-instance breakdowns, variance analysis, or statistical comparisons to substantiate this result rather than reporting aggregate outperformance alone.
Authors: We acknowledge that outperformance of a budget-splitting portfolio over the per-instance VBS is counter-intuitive and merits explicit justification rather than aggregate reporting alone. The underlying mechanism is variance reduction from multiple shorter runs combined with complementarity among the algorithms in the portfolio, which can improve expected performance under fixed total budget. In the revised version we will add per-instance performance breakdowns (showing for which instances the portfolio wins or loses), variance analysis across runs and instances, and statistical comparisons (e.g., paired tests or confidence intervals) between the naive portfolio and the VBS. These additions will be placed in the experimental results section and will directly address the conditions under which the observed gains occur. revision: yes
Circularity Check
No circularity: empirical portfolio comparisons against external VBS baseline
full rationale
The paper's central claims rest on empirical evaluations of naive and kNN-tuned portfolios versus the virtual best solver (VBS) and other baselines on held-out instances. No equations, fitted parameters, or self-citations are invoked to derive the outperformance; the VBS is an independent oracle baseline defined outside the method. The derivation chain consists of standard train/test splits and performance measurements that do not reduce to tautological re-use of the same quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- k (number of neighbors)
axioms (1)
- domain assumption Problem instances admit a feature-based similarity measure that correlates with algorithm performance
Reference graph
Works this paper leans on
-
[1]
Dinu Catalin-Viorel, Vermetten Diederick, and Doerr Carola. 2026. Reproducibil- ity and additional files.Zenodo(2026). doi:10.5281/zenodo.18351564
-
[2]
Gjorgjina Cenikj, Ana Nikolikj, Gašper Petelin, Niki van Stein, Carola Doerr, and Tome Eftimov. 2026. A survey of features used for representing black-box single-objective continuous optimization.Swarm and Evolutionary Computation 101 (2026), 102288
2026
-
[3]
Marco Collautti, Yuri Malitsky, Deepak Mehta, and Barry Sullivan. 2013. SNNAP: Solver-based Nearest Neighbor for Algorithm Portfolios, Vol. 8190. doi:10.1007/ 978-3-642-40994-3_28
2013
-
[4]
Jacob de Nobel, Diederick Vermetten, Hao Wang, Carola Doerr, and Thomas Bäck
-
[5]
InProceedings of the Genetic and Evolutionary Computation Conference Companion
Tuning as a Means of Assessing the Benefits of New Ideas in Interplay with Existing Algorithmic Modules. InProceedings of the Genetic and Evolutionary Computation Conference Companion. Association for Computing Machinery, New York, NY, USA, 1375–1384. doi:10.1145/3449726.3463167
- [6]
-
[7]
Carla P Gomes and Bart Selman. 2001. Algorithm portfolios.Artificial Intelligence 126, 1-2 (2001), 43–62
2001
-
[8]
Viviane Grunert da Fonseca, Carlos M Fonseca, and Andreia O Hall. 2001. In- ferential performance assessment of stochastic optimisers and the attainment function. InInternational Conference on Evolutionary Multi-Criterion Optimization. Springer, 213–225
2001
-
[9]
Alessio Guerri, Michela Milano, et al. 2004. Learning techniques for automatic algorithm portfolio selection. InECAI, Vol. 16. 475
2004
- [10]
-
[11]
Anja Janković and Carola Doerr. 2019. Adaptive landscape analysis. InProceedings of the genetic and evolutionary computation conference companion. 2032–2035
2019
-
[12]
Pascal Kerschke, Holger H Hoos, Frank Neumann, and Heike Trautmann. 2019. Automated algorithm selection: Survey and perspectives.Evolutionary computa- tion27, 1 (2019), 3–45
2019
-
[13]
Ana Kostovska, Anja Jankovic, Diederick Vermetten, Jacob de Nobel, Hao Wang, Tome Eftimov, and Carola Doerr. 2022. Per-run algorithm selection with warm- starting using trajectory-based features. InInternational Conference on Parallel Problem Solving from Nature. Springer, 46–60
2022
-
[14]
Kevin Leyton-Brown, Eugene Nudelman, Galen Andrew, Jim McFadden, Yoav Shoham, et al. 2003. A portfolio approach to algorithm selection. InIJCAI, Vol. 3. 1542–1543
2003
-
[15]
Fu Xing Long, Bas van Stein, Moritz Frenzel, Peter Krause, Markus Gitterle, and Thomas Bäck. 2022. Learning the characteristics of engineering optimization problems with applications in automotive crash. InProceedings of the Genetic and Evolutionary Computation Conference. 1227–1236
2022
-
[16]
Manuel López-Ibáñez, Diederick Vermetten, Johann Dreo, and Carola Doerr. 2024. Using the empirical attainment function for analyzing single-objective black-box optimization algorithms.IEEE Transactions on Evolutionary Computation(2024)
2024
-
[17]
Olaf Mersmann, Bernd Bischl, Heike Trautmann, Mike Preuss, Claus Weihs, and Günter Rudolph. 2011. Exploratory landscape analysis. InProceedings of the 13th annual conference on Genetic and evolutionary computation. 829–836
2011
-
[18]
Michael JD Powell. 1994. A direct search optimization method that models the objective and constraint functions by linear interpolation. InAdvances in optimization and numerical analysis. Springer, 51–67
1994
-
[19]
Rapin and O
J. Rapin and O. Teytaud. 2018. Nevergrad - A gradient-free optimization platform. https://GitHub.com/FacebookResearch/Nevergrad
2018
-
[20]
John R Rice. 1976. The algorithm selection problem. InAdvances in computers. Vol. 15. Elsevier, 65–118
1976
-
[21]
Jeroen Rook, Quentin Renau, Heike Trautmann, and Emma Hart. 2025. Efficient Online Automated Algorithm Selection in the Face of Data-Drift in Optimisa- tion Problem Instances. InProceedings of the 18th ACM/SIGEVO Conference on Foundations of Genetic Algorithms. 262–272
2025
-
[22]
Raymond Ros and Nikolaus Hansen. 2008. A simple modification in CMA-ES achieving linear time and space complexity. InInternational conference on parallel problem solving from nature. Springer, 296–305
2008
-
[23]
Kate Smith-Miles and Mario Andrés Muñoz. 2023. Instance space analysis for algorithm testing: Methodology and software tools.Comput. Surveys55, 12 (2023), 1–31
2023
-
[24]
Kate A Smith-Miles. 2009. Cross-disciplinary perspectives on meta-learning for algorithm selection.ACM Computing Surveys (CSUR)41, 1 (2009), 1–25
2009
-
[25]
Rainer Storn and Kenneth Price. 1997. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces.Journal of global optimization11, 4 (1997), 341–359
1997
-
[26]
Diederick Vermetten, Furong Ye, Thomas Bäck, and Carola Doerr. 2025. MA- BBOB: A problem generator for black-box optimization using affine combinations and shifts.ACM Transactions on Evolutionary Learning5, 1 (2025), 1–19
2025
-
[27]
Yuanting Zhong, Xincan Wang, Yuhong Sun, and Yue-Jiao Gong. 2024. Sd- dobench: A benchmark for streaming data-driven optimization with concept drift. InProceedings of the Genetic and Evolutionary Computation Conference. 59–67
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.