Recognition: unknown
Linear-Time and Constant-Memory Text Embeddings Based on Recurrent Language Models
Pith reviewed 2026-05-10 04:31 UTC · model grok-4.3
The pith
Recurrent models generate text embeddings in linear time with memory that stays constant beyond a fixed chunk size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning Mamba2 models with vertically chunked inference produces general-purpose text embeddings that remain competitive on a range of benchmarks while delivering linear-time computation and constant memory usage for input lengths that exceed the chosen chunk size.
What carries the argument
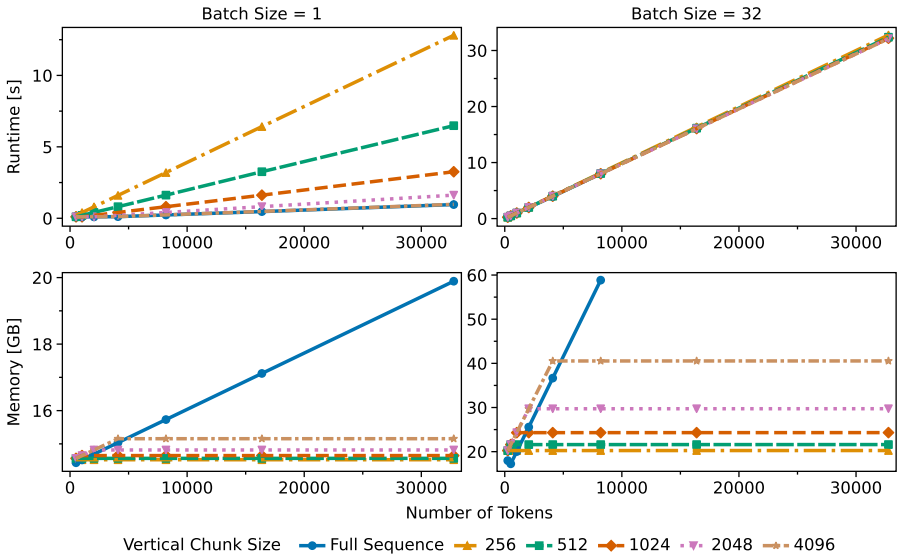
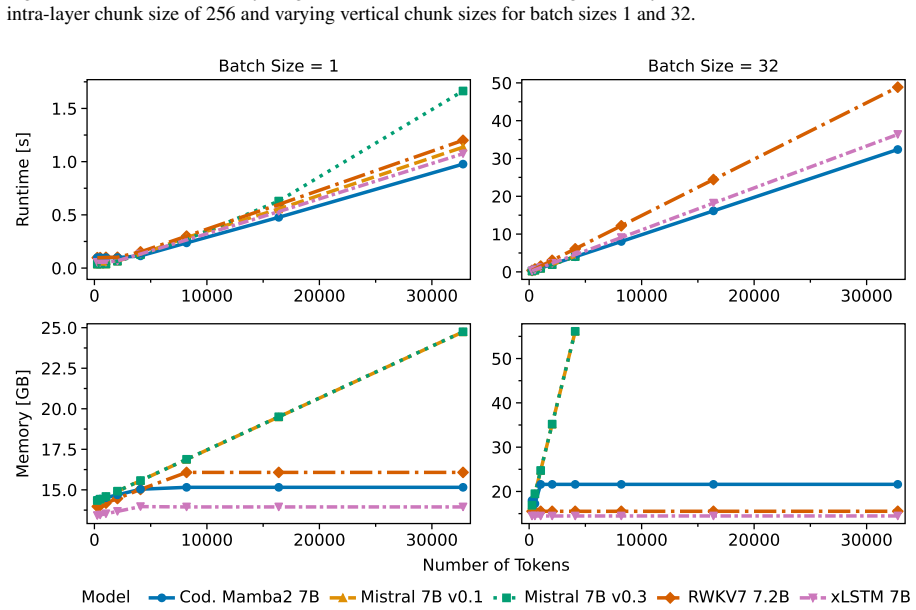
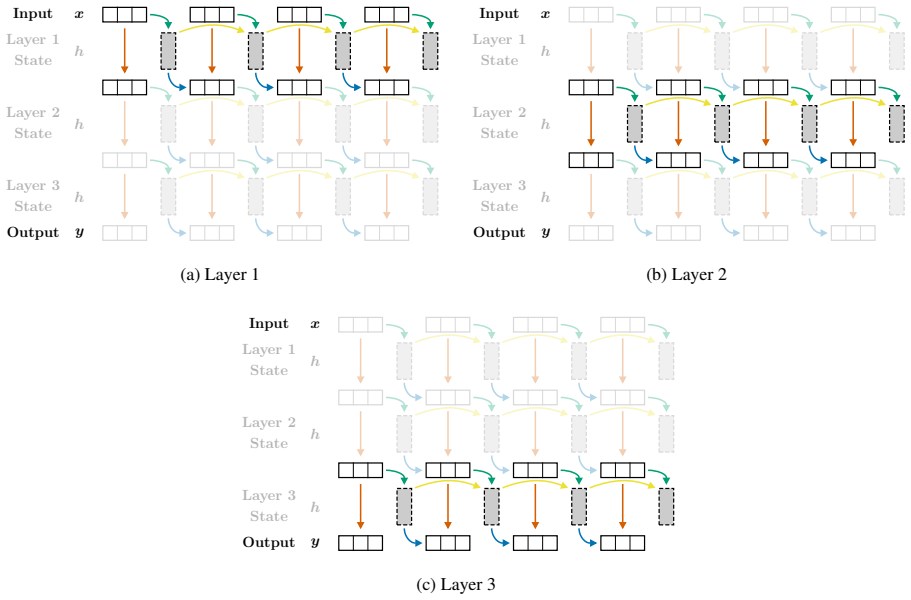
Vertically chunked inference, which divides the sequence dimension into fixed-size blocks so that the recurrent state is updated block by block, keeping memory independent of total sequence length.
If this is right
- Embedding generation for documents or dialogues much longer than typical context windows becomes practical on hardware with limited RAM.
- Inference latency grows linearly rather than quadratically, enabling real-time embedding of streaming or very long texts.
- The same chunked strategy applies across multiple recurrent families, indicating the efficiency gain is architectural rather than model-specific.
Where Pith is reading between the lines
- Retrieval systems that currently truncate inputs could embed entire books or code repositories without custom truncation rules.
- On-device or edge deployment of embedding models becomes feasible for applications that previously required cloud-scale memory.
- The approach opens a route to parameter-efficient fine-tuning of recurrent backbones specifically for embedding tasks rather than next-token prediction.
Load-bearing premise
Splitting long inputs into vertical chunks during inference preserves the same embedding quality that would be obtained by processing the full sequence at once.
What would settle it
Embeddings or downstream retrieval scores on sequences longer than the chunk size degrade sharply when chunking is applied, while non-chunked recurrent or transformer runs on the same data remain stable.
Figures







read the original abstract
Transformer-based embedding models suffer from quadratic computational and linear memory complexity, limiting their utility for long sequences. We propose recurrent architectures as an efficient alternative, introducing a vertically chunked inference strategy that enables fast embedding generation with memory usage that becomes constant in the input length once it exceeds the vertical chunk size. By fine-tuning Mamba2 models, we demonstrate their viability as general-purpose text embedders, achieving competitive performance across a range of benchmarks while maintaining a substantially smaller memory footprint compared to transformer-based counterparts. We empirically validate the applicability of our inference strategy to Mamba2, RWKV, and xLSTM models, confirming consistent runtime-memory trade-offs across architectures and establishing recurrent models as a compelling alternative to transformers for efficient embedding generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes recurrent language models (Mamba2, RWKV, xLSTM) as alternatives to transformers for text embeddings. It introduces a vertically chunked inference strategy to achieve linear-time computation and constant memory usage once sequence length exceeds the chunk size. After fine-tuning, Mamba2 models are shown to deliver competitive benchmark performance with substantially lower memory footprint than transformer counterparts, with the approach validated empirically across the three architectures.
Significance. If the chunking strategy preserves embedding quality, the work could enable practical embedding of very long sequences where quadratic transformer costs become prohibitive. The cross-architecture consistency and focus on memory efficiency constitute a clear practical contribution, especially if accompanied by reproducible code or parameter-free derivations (none explicitly noted in the provided description).
major comments (2)
- The vertically chunked inference strategy (described in the abstract and presumably §3) is load-bearing for both the constant-memory and competitiveness claims, yet the manuscript provides no quantitative validation that embeddings for sequences >> chunk size match full-context processing. No ablations of chunk size versus full-sequence cosine similarity, no measurement of approximation error at boundaries, and no long-input retrieval metrics are referenced, leaving open the possibility that state carry-over or reset introduces artifacts that degrade downstream similarity or retrieval performance even if per-chunk perplexity remains acceptable.
- The experimental section (abstract and results) reports competitive benchmark performance but supplies no details on exact benchmarks, baselines, error bars, number of runs, or statistical significance. This absence prevents assessment of whether the memory savings are achieved without meaningful accuracy loss and undermines the cross-architecture validation claim.
minor comments (1)
- The abstract would benefit from a concise statement of the specific benchmarks and the magnitude of memory reduction (e.g., factor or absolute values) to allow readers to gauge the practical impact immediately.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each major comment below and will revise the manuscript to incorporate additional validation and experimental details.
read point-by-point responses
-
Referee: The vertically chunked inference strategy (described in the abstract and presumably §3) is load-bearing for both the constant-memory and competitiveness claims, yet the manuscript provides no quantitative validation that embeddings for sequences >> chunk size match full-context processing. No ablations of chunk size versus full-sequence cosine similarity, no measurement of approximation error at boundaries, and no long-input retrieval metrics are referenced, leaving open the possibility that state carry-over or reset introduces artifacts that degrade downstream similarity or retrieval performance even if per-chunk perplexity remains acceptable.
Authors: We agree that direct quantitative validation of the chunking strategy for sequences substantially longer than the chunk size would strengthen the claims. The current manuscript demonstrates competitive benchmark performance and consistent runtime-memory behavior across Mamba2, RWKV, and xLSTM, but does not include explicit ablations comparing chunked embeddings to full-context processing (e.g., cosine similarity or boundary error) or long-input retrieval metrics. In the revision we will add these analyses, including chunk-size ablations and similarity measurements for long sequences, in a dedicated subsection of the experimental results. revision: yes
-
Referee: The experimental section (abstract and results) reports competitive benchmark performance but supplies no details on exact benchmarks, baselines, error bars, number of runs, or statistical significance. This absence prevents assessment of whether the memory savings are achieved without meaningful accuracy loss and undermines the cross-architecture validation claim.
Authors: We acknowledge that the experimental section would benefit from greater explicitness. While the manuscript describes the benchmarks, fine-tuning procedure, and cross-architecture results, it does not provide sufficient detail on exact benchmark suites, all baselines, number of runs, error bars, or statistical significance testing. In the revised version we will expand the experimental section to include these specifics, along with a table summarizing all evaluation settings and reproducibility information. revision: yes
Circularity Check
No significant circularity; claims rest on empirical fine-tuning and cross-architecture validation
full rationale
The paper's derivation chain consists of proposing a vertically chunked inference strategy for recurrent models, fine-tuning Mamba2 (and validating on RWKV/xLSTM), and reporting benchmark performance plus memory/runtime measurements. No equations reduce a claimed prediction to a fitted parameter by construction, no self-definitional loops appear (e.g., embedding quality defined via the chunking method itself), and no load-bearing uniqueness theorems or ansatzes are imported solely via self-citation. The central viability claim is supported by external benchmark comparisons rather than internal re-labeling of inputs. This is the expected non-finding for an empirical architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maximilian Beck, Korbinian P\" o ppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, G\" u nter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. 2024. https://doi.org/10.52202/079017-3417 xLSTM : Extended long short-term memory . In Advances in Neural Information Processing Systems, volume 37, pages 107547--107603. Curran Assoc...
-
[2]
Weili Cao, Jianyou Wang, Youze Zheng, Longtian Bao, Qirui Zheng, Taylor Berg-Kirkpatrick, Ramamohan Paturi, and Leon Bergen. 2025. https://doi.org/10.48550/arXiv.2504.03101 Single-pass document scanning for question answering . In Proceedings of the Second Conference on Language Modeling
-
[3]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. https://doi.org/10.48550/arXiv.1904.10509 Generating long sequences with sparse transformers . Preprint, arXiv:1904.10509
work page internal anchor Pith review doi:10.48550/arxiv.1904.10509 2019
-
[4]
Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, and Jy yong Sohn. 2024. https://doi.org/10.48550/arXiv.2412.03223 Linq-Embed-Mistral technical report . Preprint, arXiv:2412.03223
-
[5]
Tri Dao. 2024. https://proceedings.iclr.cc/paper_files/paper/2024/file/98ed250b203d1ac6b24bbcf263e3d4a7-Paper-Conference.pdf FlashAttention-2 : Faster attention with better parallelism and work partitioning . In International Conference on Learning Representations, volume 2024, pages 35549--35562
2024
-
[6]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R\' e . 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/67d57c32e20fd0a7a302cb81d36e40d5-Paper-Conference.pdf FlashAttention : Fast and memory-efficient exact attention with io-awareness . In Advances in Neural Information Processing Systems, volume 35, pages 16344--16359. Curran...
2022
-
[7]
Tri Dao and Albert Gu. 2024. https://proceedings.mlr.press/v235/dao24a.html Transformers are SSM s: Generalized models and efficient algorithms through structured state space duality . In Proceedings of the 41st International Conference on Machine Learning, volume 235, pages 10041--10071. PMLR
2024
-
[8]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/1feb87871436031bdc0f2beaa62a049b-Paper-Conference.pdf QLoRA : Efficient finetuning of quantized llms . In Advances in Neural Information Processing Systems, volume 36, pages 10088--10115. Curran Associates, Inc
2023
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long a...
-
[10]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, M\' a rton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi\' n ski, Genta Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Diganta Misra, Shreeya Dhakal, Jonathan Rystr m, Roman Solomatin, \" O mer C a g atan, and 63 others. 2025. https://proceedings.iclr.c...
2025
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://doi.org/10.48550/arXiv.2407.21783 Th...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[12]
Albert Gu and Tri Dao. 2024. https://doi.org/10.48550/arXiv.2312.00752 Mamba: Linear-time sequence modeling with selective state spaces . In Proceedings of the First Conference on Language Modeling
-
[13]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://doi.org/10.48550/arXiv.2106.09685 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2022
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://doi.org/10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[15]
Li Liang, Huan Wang, and Kai Wang. 2025. https://doi.org/10.1038/s41598-025-19628-w Cognitive-inspired xLSTM for multi-agent information retrieval . Scientific Reports, 15(1):36121
-
[16]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. 2023. https://doi.org/10.18653/v1/2023.eacl-main.148 MTEB : Massive text embedding benchmark . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014--2037, Dubrovnik, Croatia. Association for Computational Linguistics
-
[17]
Xinghan Pan. 2025. https://doi.org/10.48550/arXiv.2502.14620 Exploring RWKV for sentence embeddings: Layer-wise analysis and baseline comparison for semantic similarity . Preprint, arXiv:2502.14620
-
[18]
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Leon Derczynski, Xingjian Du, Matteo Grella, Kranthi Gv, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bart omiej Koptyra, and 13 others. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.936 RWKV : Rei...
-
[19]
RWKV-7 “Goose” with expressive dynamic state evolution, 2025
Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, Guangyu Song, Kaifeng Tan, Saiteja Utpala, Nathan Wilce, Johan S. Wind, Tianyi Wu, Daniel Wuttke, and Christian Zhou-Zheng. 2025. https://doi.org/10.48550/arXiv.2503.14456 RWKV -7 '' G oose'' with expressive dynamic state ev...
-
[20]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. https://doi.org/10.52202/079017-2193 FlashAttention-3 : Fast and accurate attention with asynchrony and low-precision . In Advances in Neural Information Processing Systems, volume 37, pages 68658--68685. Curran Associates, Inc
-
[21]
Jacob Mitchell Springer, Vaibhav Adlakha, Siva Reddy, Aditi Raghunathan, and Marius Mosbach. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1160 Understanding the influence of synthetic data for text embedders . In Findings of the Association for Computational Linguistics: ACL 2025, pages 22551--22567, Vienna, Austria. Association for Computational L...
-
[22]
Stephan Tulkens and Thomas van Dongen. 2024. https://doi.org/10.5281/zenodo.17270888 Model2Vec : Fast state-of-the-art static embeddings . Zenodo
-
[23]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2019. https://doi.org/10.48550/arXiv.1807.03748 Representation learning with contrastive predictive coding . Preprint, arXiv:1807.03748
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.03748 2019
-
[24]
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, and 70 others. 2025. https://doi.org/10.48550/arXiv.2509.20354 EmbeddingGemma : Powe...
work page internal anchor Pith review doi:10.48550/arxiv.2509.20354 2025
-
[25]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. https://doi.org/10.18653/v1/2024.acl-long.642 Improving text embeddings with large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897--11916, Bangkok, Thailand. Association f...
-
[26]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 43 others. 2024. https://doi.org/10.48550/arXiv.2407.10671 Qwen2 technical report . Preprint, arXiv:2407.10671
work page internal anchor Pith review doi:10.48550/arxiv.2407.10671 2024
-
[27]
Hanqi Zhang, Chong Chen, Lang Mei, Qi Liu, and Jiaxin Mao. 2024. https://doi.org/10.1145/3627673.3679959 Mamba retriever: Utilizing mamba for effective and efficient dense retrieval . In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM '24, pages 4268--4272, New York, NY, USA. Association for Computing Machinery
-
[28]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. https://doi.org/10.48550/arXiv.2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
work page internal anchor Pith review doi:10.48550/arxiv.2506.05176 2025
-
[29]
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, and Sujian Li. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.47 L ong E mbed: Extending embedding models for long context retrieval . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 802--816, Miami, Florida, USA. Association for Computati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.