Recognition: unknown
Hard to Be Heard: Phoneme-Level ASR Analysis of Phonologically Complex, Low-Resource Endangered Languages
Pith reviewed 2026-05-10 04:20 UTC · model grok-4.3
The pith
Many ASR errors in phonologically complex low-resource languages stem from data scarcity rather than complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
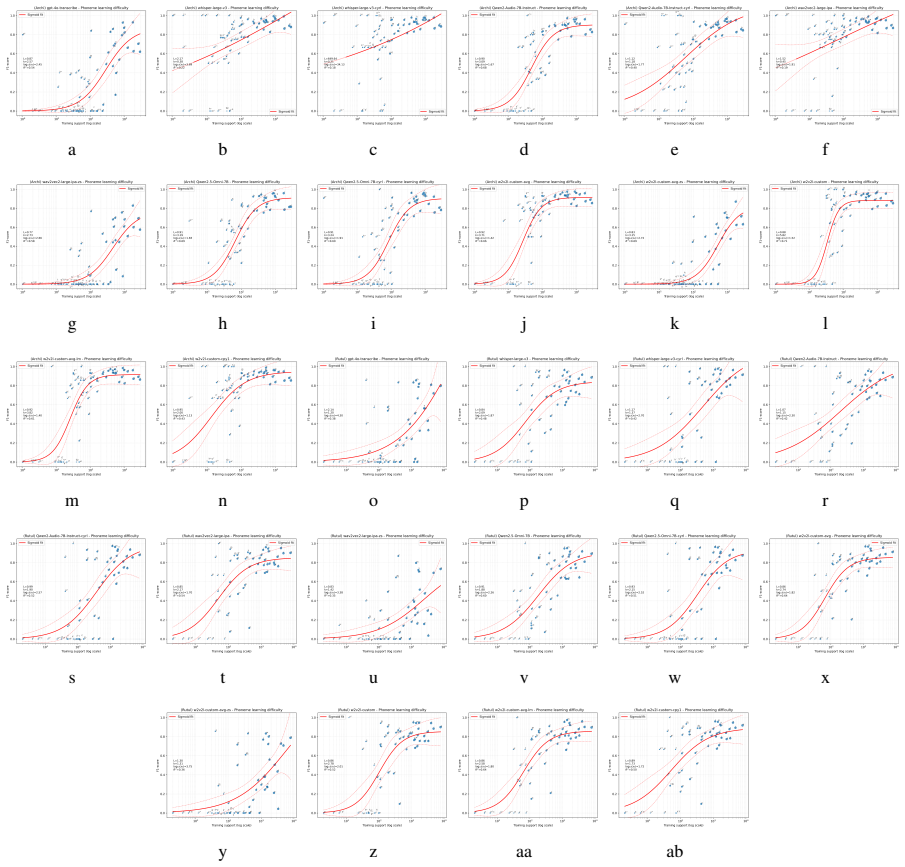
In these extremely low-resource settings, phoneme recognition accuracy strongly correlates with training frequency and exhibits a characteristic sigmoid-shaped learning curve. This relationship holds for most evaluated models, supporting the view that data scarcity accounts for many errors previously linked to phonological complexity. For wav2vec2, a language-specific phoneme vocabulary combined with heuristic output-layer initialization yields consistent improvements, reaching performance comparable to or better than Whisper. The analysis demonstrates the utility of phoneme-level evaluation in understanding ASR behavior for typologically complex languages with minimal data.
What carries the argument
The frequency-correlated phoneme error analysis revealing a sigmoid learning curve, together with language-specific phoneme vocabulary and heuristic output-layer initialization for wav2vec2.
If this is right
- Phoneme accuracy improves predictably with training frequency according to a sigmoid pattern across most models.
- Many errors attributed to phonological complexity are instead explained by data scarcity.
- Language-specific phoneme vocabulary with heuristic initialization allows wav2vec2 to match or exceed Whisper in these settings.
- Phoneme-level analysis reveals model behaviors that word and character error rates obscure.
- Consolidating and standardizing existing recordings enables viable ASR training for endangered languages.
Where Pith is reading between the lines
- Targeted collection of additional examples for rare phonemes could shift the learning curve and lower overall error rates.
- The same frequency-based analysis could guide data prioritization for other endangered languages with complex sound inventories.
- Architectures like Whisper may carry inductive biases that aid generalization to complex phonologies even when data is limited.
- Testing whether the sigmoid pattern holds or changes with datasets several times larger would clarify the role of data volume.
Load-bearing premise
The small curated datasets of roughly 50 minutes for Archi and 80 minutes for Rutul are representative enough for phoneme-level conclusions and that performance differences arise from the studied factors rather than unexamined variables like training procedures.
What would settle it
Adding substantially more balanced data for Archi or Rutul and checking whether the sigmoid frequency-accuracy curve flattens or whether error rates remain high despite equalized phoneme frequencies.
Figures


read the original abstract
We present a phoneme-level analysis of automatic speech recognition (ASR) for two low-resourced and phonologically complex East Caucasian languages, Archi and Rutul, based on curated and standardized speech-transcript resources totaling approximately 50 minutes and 1 hour 20 minutes of audio, respectively. Existing recordings and transcriptions are consolidated and processed into a form suitable for ASR training and evaluation. We evaluate several state-of-the-art audio and audio-language models, including wav2vec2, Whisper, and Qwen2-Audio. For wav2vec2, we introduce a language-specific phoneme vocabulary with heuristic output-layer initialization, which yields consistent improvements and achieves performance comparable to or exceeding Whisper in these extremely low-resource settings. Beyond standard word and character error rates, we conduct a detailed phoneme-level error analysis. We find that phoneme recognition accuracy strongly correlates with training frequency, exhibiting a characteristic sigmoid-shaped learning curve. For Archi, this relationship partially breaks for Whisper, pointing to model-specific generalization effects beyond what is predicted by training frequency. Overall, our results indicate that many errors attributed to phonological complexity are better explained by data scarcity. These findings demonstrate the value of phoneme-level evaluation for understanding ASR behavior in low-resource, typologically complex languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a phoneme-level analysis of ASR performance on two phonologically complex, low-resource endangered languages, Archi (approximately 50 minutes of audio) and Rutul (approximately 80 minutes). They consolidate existing recordings into standardized resources, evaluate models including wav2vec2 (with a language-specific phoneme vocabulary and heuristic output-layer initialization), Whisper, and Qwen2-Audio, and perform detailed phoneme-level error analysis. They report a strong correlation between phoneme recognition accuracy and training frequency that follows a sigmoid-shaped learning curve, with a partial breakdown of this relationship for Whisper on Archi. The authors conclude that many errors attributed to phonological complexity are better explained by data scarcity.
Significance. If the central empirical relationship holds under more rigorous validation, the work provides useful guidance for ASR development in low-resource, typologically complex languages by shifting focus from inherent phonological difficulty to data collection priorities. The phoneme-level evaluation framework and the practical adaptation of wav2vec2 via custom vocabulary initialization represent concrete contributions that could be extended to other endangered languages.
major comments (1)
- The central claim that data scarcity better explains ASR errors than phonological complexity depends on the reported strong, sigmoid-shaped correlation between phoneme accuracy and training frequency (detailed in the phoneme-level error analysis). With only ~50 minutes of Archi audio and ~80 minutes of Rutul audio, per-phoneme token counts are necessarily small and unevenly distributed, especially for complex phonemes such as ejectives and uvulars. The manuscript reports neither per-phoneme counts, binomial confidence intervals on accuracy, nor any statistical test or robustness check (e.g., bootstrap or leave-one-phoneme-out) for the correlation or the Whisper deviation. Accuracy estimates based on fewer than 20 tokens per phoneme are dominated by sampling variance, rendering the observed relationship and model-specific exception potentially artifactual rather than evidence for the data
minor comments (2)
- The abstract states that the wav2vec2 adaptation 'yields consistent improvements' but supplies no numerical WER/CER deltas or statistical significance relative to the baseline.
- Reproducibility would be aided by explicit description of the heuristic used for output-layer initialization when the phoneme vocabulary is changed for wav2vec2.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the statistical robustness of our phoneme-level analysis. We agree that the small dataset sizes necessitate additional validation and will revise the manuscript accordingly to strengthen the evidence for our central claims.
read point-by-point responses
-
Referee: The central claim that data scarcity better explains ASR errors than phonological complexity depends on the reported strong, sigmoid-shaped correlation between phoneme accuracy and training frequency (detailed in the phoneme-level error analysis). With only ~50 minutes of Archi audio and ~80 minutes of Rutul audio, per-phoneme token counts are necessarily small and unevenly distributed, especially for complex phonemes such as ejectives and uvulars. The manuscript reports neither per-phoneme counts, binomial confidence intervals on accuracy, nor any statistical test or robustness check (e.g., bootstrap or leave-one-phoneme-out) for the correlation or the Whisper deviation. Accuracy estimates based on fewer than 20 tokens per phoneme are dominated by sampling variance, rendering the observed relationship and model-specific exception potentially artifactual rather than evidence for the data
Authors: We acknowledge that the extremely limited audio resources result in small and uneven per-phoneme token counts, which can introduce sampling variance, particularly for low-frequency phonemes such as ejectives and uvulars. In the revised manuscript we will add a table or appendix reporting the exact token count for every phoneme in both languages. We will also include binomial confidence intervals on all per-phoneme accuracy estimates and perform a formal statistical assessment of the reported correlation (Spearman rank correlation with p-values, supplemented by bootstrap resampling or a leave-one-phoneme-out check). The same validation will be applied to the Whisper deviation on Archi to determine whether it remains outside the range expected from sampling variance alone. These additions directly address the concern that the observed sigmoid relationship and model-specific exception could be artifactual; we expect the strengthened analysis to provide clearer support for the conclusion that data scarcity is the dominant explanatory factor. revision: yes
Circularity Check
No circularity: empirical correlations from direct measurements
full rationale
The paper's central claims rest on training ASR models (wav2vec2 with custom phoneme vocab, Whisper, Qwen2-Audio) on the small Archi (~50 min) and Rutul (~80 min) corpora, then directly measuring phoneme recognition accuracy and its correlation with per-phoneme training frequency counts. The observed sigmoid-shaped relationship and the partial deviation for Whisper on Archi are presented as empirical patterns, not as outputs of any fitted model, self-referential definition, or derivation that reduces to the inputs by construction. The attribution that data scarcity better explains errors than phonological complexity is an interpretive summary of these comparisons, with no load-bearing self-citations, uniqueness theorems, or ansatzes invoked. This is a standard empirical study whose results are falsifiable against the raw frequency-accuracy tables.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine learning assumptions for ASR hold, including that training and test data splits are representative and that phoneme vocabularies can be aligned across models.
Reference graph
Works this paper leans on
-
[1]
Qwen technical report. arXiv preprint arXiv:2309.16609. Gilles Boulianne
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InFind- ings of the Association for Computational Linguis- tics: ACL 2022, pages 2301–2308, Dublin, Ireland
Phoneme transcription of en- dangered languages: an evaluation of recent ASR architectures in the single speaker scenario. InFind- ings of the Association for Computational Linguis- tics: ACL 2022, pages 2301–2308, Dublin, Ireland. Association for Computational Linguistics. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dh...
2022
-
[3]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901. Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others
1901
-
[4]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759. Marina Chumakina, Dunstan Brown, Greville Corbett, and Harley Quilliam
work page internal anchor Pith review arXiv
-
[5]
InProceedings of Interspeech, pages 2003–2007
Speech llms in low-resource scenarios: Data volume requirements and the impact of pretrain- ing on high-resource languages. InProceedings of Interspeech, pages 2003–2007. ISCA-International Speech Communication Association. Xuelong Geng, Kun Wei, Qijie Shao, Shuiyun Liu, Zhennan Lin, Zhixian Zhao, Guojian Li, Wenjie Tian, Peikun Chen, Yangze Li, and 1 others
2003
-
[6]
OSUM: Advancing Open Speech Understanding Models with Limited Resources in Academia
Osum: Advancing open speech understanding mod- els with limited resources in academia.arXiv preprint arXiv:2501.13306. Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber
-
[7]
InIn- terspeech 2022-23rd Annual Conference of the Inter- national Speech Communication Association, pages 4905–4909
Plugging a neural phoneme recognizer into a simple language model: a workflow for low-resource settings. InIn- terspeech 2022-23rd Annual Conference of the Inter- national Speech Communication Association, pages 4905–4909. International Speech Communication As- sociation. Kenneth Heafield
2022
-
[8]
Gpt-4o system card.arXiv preprint arXiv:2410.21276. Aleksandr E. Kibrik, Sandro V . Kodzasov, Irina P. Olovyannikova, Dzhalil S. Samedov, Michael Daniel, Anna Khoroshkina, and Alexandre Arkhipov
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Adam: A Method for Stochastic Optimization
Adam: A method for stochas- tic optimization.arXiv preprint arXiv:1412.6980. Xinjian Li, Florian Metze, David R Mortensen, Alan W Black, and Shinji Watanabe
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Asr2k: Speech recognition for around 2000 languages without audio. InProc. Interspeech 2022, pages 4885–4889. Zhaolin Li and Jan Niehues. 2025a. Enhance contex- tual learning in ASR for endangered low-resource languages. InProceedings of the 1st Workshop on Language Models for Underserved Communities (LM4UC 2025), pages 1–7, Albuquerque, New Mex- ico. Ass...
2000
-
[11]
Decoupled Weight Decay Regularization
Decou- pled weight decay regularization.arXiv preprint arXiv:1711.05101. Donald W Marquardt
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Phoneme recognition through fine tuning of phonetic representations: A case study on luhya language varieties. InProc. Interspeech 2021, pages 271–275. Chihiro Taguchi, Yusuke Sakai, Parisa Haghani, and David Chiang
2021
-
[13]
Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2(3). Aad W Van der Vaart. 2000.Asymptotic statistics, vol- ume
work page internal anchor Pith review arXiv 2000
-
[14]
Qwen2. 5-omni tech- nical report.arXiv preprint arXiv:2503.20215. Qiantong Xu, Alexei Baevski, and Michael Auli
work page internal anchor Pith review arXiv
-
[15]
Simple and effective zero-shot cross-lingual phoneme recognition. InProc. Interspeech 2022, pages 2113–
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.