Recognition: unknown
Domain-Specialized Object Detection via Model-Level Mixtures of Experts
Pith reviewed 2026-05-10 04:23 UTC · model grok-4.3
The pith
Mixtures of experts with domain-specialized detectors outperform standard ensembles in object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose an MoE architecture that combines YOLO-based detectors trained on semantically disjoint data subsets, with a learned gating network that dynamically weights expert contributions. We study different strategies for fusing detection outputs and for training the gating mechanism, including balancing losses to prevent expert collapse. Experiments on the BDD100K dataset demonstrate that the proposed MoE consistently outperforms standard ensemble approaches and provides insights into expert specialization across domains.
What carries the argument
A model-level mixture of experts in which each expert is a complete YOLO detector trained on a semantically disjoint subset, fused by a trainable gating network that learns dynamic weights for the dense outputs.
If this is right
- The MoE approach yields higher accuracy than conventional ensembling when detectors are trained on domain-disjoint data.
- Insights into expert specialization across domains become available through the gating weights and per-expert performance breakdowns.
- Balancing losses during gating training prevents expert collapse and preserves overall detection quality.
- Model-level MoEs provide a practical alternative to traditional ensembles for tasks with dense, structured outputs like object detection.
Where Pith is reading between the lines
- The same architecture could be tested on other dense-prediction tasks such as semantic segmentation or depth estimation to check whether fusion strategies transfer.
- New experts could be added incrementally for novel domains without retraining the full system, enabling efficient lifelong adaptation.
- The observed specialization patterns might guide targeted data collection or active learning strategies that focus on underrepresented domains.
- In safety-critical settings the gating decisions could offer post-hoc explanations of which domain expert handled a given input.
Load-bearing premise
Training detectors on semantically disjoint subsets will produce meaningfully specialized experts whose outputs the gating network can fuse without collapse or loss of accuracy.
What would settle it
On the BDD100K dataset the mixture-of-experts model shows no mAP gain over standard ensembles or the experts exhibit no distinct specialization patterns in their error profiles.
Figures





read the original abstract
Mixture-of-Experts (MoE) models provide a structured approach to combining specialized neural networks and offer greater interpretability than conventional ensembles. While MoEs have been successfully applied to image classification and semantic segmentation, their use in object detection remains limited due to challenges in merging dense and structured predictions. In this work, we investigate model-level mixtures of object detectors and analyze their suitability for improving performance and interpretability in object detection. We propose an MoE architecture that combines YOLO-based detectors trained on semantically disjoint data subsets, with a learned gating network that dynamically weights expert contributions. We study different strategies for fusing detection outputs and for training the gating mechanism, including balancing losses to prevent expert collapse. Experiments on the BDD100K dataset demonstrate that the proposed MoE consistently outperforms standard ensemble approaches and provides insights into expert specialization across domains, highlighting model-level MoEs as a viable alternative to traditional ensembling for object detection. Our code is available at https://github.com/KASTEL-MobilityLab/mixtures-of-experts/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a model-level Mixture of Experts (MoE) architecture for object detection that trains separate YOLO-based detectors on semantically disjoint subsets of the BDD100K dataset and combines their dense outputs via a learned gating network. Multiple fusion strategies are examined, including score-weighted NMS and per-class gating, together with explicit balancing losses in the gating objective to avoid expert collapse. Experiments demonstrate that the resulting MoE consistently outperforms standard ensemble baselines while yielding interpretable specialization patterns across domains.
Significance. If the reported gains hold, the work provides a practical and interpretable alternative to conventional ensembling for multi-domain object detection. By showing that domain-specialized experts can be fused without collapse and that the gating network learns meaningful routing, the manuscript extends MoE techniques from classification/segmentation to structured prediction tasks and supplies concrete ablation evidence on specialization metrics.
minor comments (4)
- The abstract states that the MoE 'consistently outperforms standard ensemble approaches' but does not report the magnitude of the mAP gains or the number of runs; adding these quantitative highlights would strengthen the summary.
- Section 4.3 (fusion strategies) introduces per-class gating and score-weighted NMS; a short pseudocode block or explicit equation for the final suppression step would improve reproducibility.
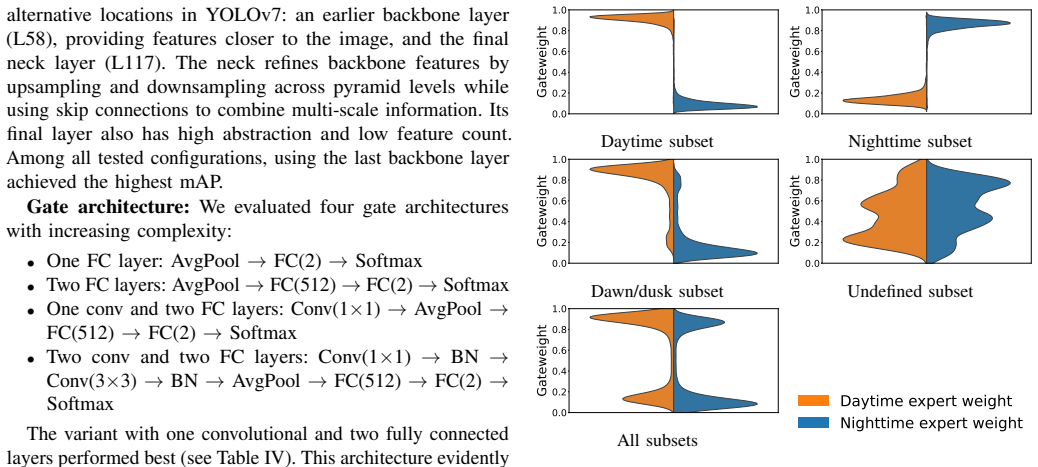
- Figure 4 (expert activation histograms) would benefit from axis labels that explicitly tie activation frequency to the domain-specific mAP improvements listed in Table 2.
- The limitations paragraph in the conclusion mentions increased inference cost but does not quantify the overhead relative to a single YOLO model; a brief runtime table would be useful.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The referee's description accurately captures the core contributions of our model-level MoE approach for domain-specialized object detection using YOLO experts on BDD100K, including the gating network, fusion strategies, and balancing losses to prevent collapse. As no specific major comments were listed in the report, we have no point-by-point rebuttals to provide. We will address any minor issues identified during the revision process.
Circularity Check
No significant circularity detected
full rationale
The paper proposes and empirically evaluates a model-level MoE for object detection by training YOLO experts on semantically disjoint subsets of BDD100K and learning a gating network (with balancing losses) to fuse outputs via strategies such as score-weighted NMS. All central claims rest on external experimental comparisons (mAP gains, expert activation histograms, ablations) rather than any derivation, prediction, or uniqueness theorem that reduces to the paper's own fitted parameters or self-citations. No equations, ansatzes, or load-bearing self-references appear in the provided text; the architecture and training procedure are explicitly described as learned and measured against independent baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural computation, vol. 3, no. 1, 1991
1991
-
[2]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”CoRR, vol. abs/2101.03961, 2021
work page internal anchor Pith review arXiv 2021
-
[3]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
D. Dai, C. Deng, C. Zhao, R. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wuet al., “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,”arXiv preprint arXiv:2401.06066, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Scaling vision with sparse mixture of experts,
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. S. Pinto, D. Keysers, and N. Houlsby, “Scaling vision with sparse mixture of experts,” inAdvances in Neural Information Processing Systems (NIPS), 2021
2021
-
[5]
Gshard: Scaling giant models with conditional computation and automatic sharding,
H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[6]
Convoluted Mixture of Deep Experts for Robust Semantic Segmentation,
A. Valada, A. Dhall, and W. Burgard, “Convoluted Mixture of Deep Experts for Robust Semantic Segmentation,” inInternational Conference on Intelligent Robots and Systems (IROS) - Workshops, 2016
2016
-
[7]
Using mixture of expert models to gain insights into semantic segmentation,
S. Pavlitskaya, C. Hubschneider, M. Weber, R. Moritz, F. H ¨uger, P. Schlicht, and J. M. Z ¨ollner, “Using mixture of expert models to gain insights into semantic segmentation,” inConference on Computer Vision and Pattern Recognition (CVPR) - Workshops, 2020
2020
-
[8]
Network of experts for large- scale image categorization,
K. Ahmed, M. H. Baig, and L. Torresani, “Network of experts for large- scale image categorization,” inEuropean Conference on Computer Vision (ECCV). Springer, 2016
2016
-
[9]
Choosing smartly: Adaptive multimodal fusion for object detection in changing environments,
O. Mees, A. Eitel, and W. Burgard, “Choosing smartly: Adaptive multimodal fusion for object detection in changing environments,” in International Conference on Intelligent Robots and Systems (IROS), 2016
2016
-
[10]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inConference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[11]
BDD100K: A diverse driving dataset for heterogeneous multitask learning,
F. Yu, H. Chen, X. Wang, W. Xian, Y . Chen, F. Liu, V . Madhavan, and T. Darrell, “BDD100K: A diverse driving dataset for heterogeneous multitask learning,” inConference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[12]
Towards A Rigorous Science of Interpretable Machine Learning
F. Doshi-Velez and B. Kim, “Towards a rigorous science of interpretable machine learning,”arXiv preprint arXiv:1702.08608, 2017
work page internal anchor Pith review arXiv 2017
-
[13]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,
C. Rudin, “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,”Nat. Mach. Intell., 2019
2019
-
[14]
Weighted boxes fusion: Ensembling boxes from different object detection models,
R. Solovyev, W. Wang, and T. Gabruseva, “Weighted boxes fusion: Ensembling boxes from different object detection models,”Image and Vision Computing, 2021
2021
-
[15]
Cad: Scale invariant framework for real-time object detection,
H. Zhou, Z. Li, C. Ning, and J. Tang, “Cad: Scale invariant framework for real-time object detection,” inInternational Conference on Computer Vision (ICCV) - Workshops, 2017
2017
-
[16]
Soft-nms–improving object detection with one line of code,
N. Bodla, B. Singh, R. Chellappa, and L. S. Davis, “Soft-nms–improving object detection with one line of code,” inInternational Conference on Computer Vision (ICCV), 2017
2017
-
[17]
A forest fire detection system based on ensemble learning,
R. Xu, H. Lin, K. Lu, L. Cao, and Y . Liu, “A forest fire detection system based on ensemble learning,”Forests, 2021
2021
-
[18]
Ensemble methods for object detection,
´A. Casado-Garc´ıa and J. Heras, “Ensemble methods for object detection,” inEuropean Conference on Artificial Intelligence (ECAI), 2020
2020
-
[19]
Ensemble r-fcn for object detection,
J. Li, J. Qian, and Y . Zheng, “Ensemble r-fcn for object detection,” in International Conference on Ubiquitous Information Technologies and Applications, 2017
2017
-
[20]
Megdet: A large mini-batch object detector,
C. Peng, T. Xiao, Z. Li, Y . Jiang, X. Zhang, K. Jia, G. Yu, and J. Sun, “Megdet: A large mini-batch object detector,” inConference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[21]
Deep cnn ensemble with data augmentation for object detection,
J. Guo and S. Gould, “Deep cnn ensemble with data augmentation for object detection,”arXiv preprint arXiv:1506.07224, 2015
-
[22]
Cascade r-cnn: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” inConference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[23]
An ensemble method of cnn models for object detection,
J. Lee, S.-K. Lee, and S.-I. Yang, “An ensemble method of cnn models for object detection,” inInternational Conference on Information and Communication Technology Convergence (ICTC), 2018
2018
-
[24]
Ensemble of deep object detectors for page object detection,
N. D. V o, K. Nguyen, T. V . Nguyen, and K. Nguyen, “Ensemble of deep object detectors for page object detection,” inInternational Conference on Ubiquitous Information Management and Communication, 2018
2018
-
[25]
Wildfire and smoke detection using staged yolo model and ensemble cnn,
C. Bahhar, A. Ksibi, M. Ayadi, M. M. Jamjoom, Z. Ullah, B. O. Soufiene, and H. Sakli, “Wildfire and smoke detection using staged yolo model and ensemble cnn,”Electronics, vol. 12, 2023
2023
-
[26]
YOLOv5: A state-of-the-art real-time object detection system,
Ultralytics, “YOLOv5: A state-of-the-art real-time object detection system,” 2021
2021
-
[27]
A yolo-based approach for fire and smoke detection in iot surveillance systems
D. Zhang, “A yolo-based approach for fire and smoke detection in iot surveillance systems.”International Journal of Advanced Computer Science & Applications, vol. 15, no. 1, 2024
2024
-
[28]
Incremental object detection using ensemble modeling and deep transfer learning,
P. Huayhongthong, S. Rerk-u suk, S. Booddee, P. Padungweang, and K. Warasup, “Incremental object detection using ensemble modeling and deep transfer learning,” inInternational Conference on Computing and Information Technology, 2020
2020
-
[29]
Learning a mixture of granularity-specific experts for fine-grained categorization,
L. Zhang, S. Huang, W. Liu, and D. Tao, “Learning a mixture of granularity-specific experts for fine-grained categorization,” inInter- national Conference on Computer Vision (ICCV), 2019
2019
-
[30]
Fg-moe: Heterogeneous mixture of experts model for fine-grained visual classification,
S. Yang, J. Wen, and B. Fang, “Fg-moe: Heterogeneous mixture of experts model for fine-grained visual classification,”Pattern Recognition, p. 113050, 2026
2026
-
[31]
Mocae: Mixture of calibrated experts significantly improves object detection,
K. Oksuz, S. Kuzucu, T. Joy, and P. K. Dokania, “Mocae: Mixture of calibrated experts significantly improves object detection,”Trans. Mach. Learn. Res., 2024
2024
-
[32]
Evaluating mixture-of- experts architectures for network aggregation,
S. Pavlitskaya, C. Hubschneider, and M. Weber, “Evaluating mixture-of- experts architectures for network aggregation,” inDeep Neural Networks and Data for Automated Driving: Robustness, Uncertainty Quantification, and Insights Towards Safety, 2022
2022
-
[33]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Sparsely- gated mixture-of-expert layers for cnn interpretability,
S. Pavlitska, C. Hubschneider, L. Struppek, and J. M. Z ¨ollner, “Sparsely- gated mixture-of-expert layers for cnn interpretability,” inInternational Joint Conference on Neural Networks (IJCNN), 2023
2023
-
[35]
Robust experts: the effect of adversarial training on cnns with sparse mixture-of-experts layers,
S. Pavlitska, H. Fan, K. Ditschuneit, and J. M. Z ¨ollner, “Robust experts: the effect of adversarial training on cnns with sparse mixture-of-experts layers,” inInternational Conference on Computer Vision (ICCV) - Workshops, 2025
2025
-
[36]
Yolov7: Trainable bag- of-freebies sets new state-of-the-art for real-time object detectors,
C. Wang, A. Bochkovskiy, and H. M. Liao, “Yolov7: Trainable bag- of-freebies sets new state-of-the-art for real-time object detectors,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[37]
Yolov9: Learning what you want to learn using programmable gradient information,
C. Wang, I. Yeh, and H. M. Liao, “Yolov9: Learning what you want to learn using programmable gradient information,” inEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[38]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conference on Computer Vision (ECCV). Springer, 2014, pp. 740–755
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.