Recognition: unknown
Reliability of AI Bots Footprints in GitHub Actions CI/CD Workflows
Pith reviewed 2026-05-10 04:22 UTC · model grok-4.3
The pith
AI coding bots produce CI/CD workflow runs whose success rates drop as their pull requests become more frequent in a repository.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using pull requests, commits, and repositories from the AIDev dataset, the authors retrieved 61,837 GitHub Actions workflow runs across 2,355 repositories that had been triggered by PRs authored by Claude, Devin, Cursor, Copilot, or Codex. Copilot and Codex showed the highest success rates at roughly 93 percent and 94 percent. At the repository level they measured a negative correlation between the frequency of AI-agent contributions and workflow success rate, which they interpret as evidence that heavier use of these agents can reduce CI/CD reliability. They further classified 3,067 failed runs into 13 categories and observed shifts from functional to non-functional failure types over time,
What carries the argument
The negative correlation between AI-agent PR frequency and repository-level CI/CD workflow success rate, measured by linking AIDev pull requests to GitHub Actions run outcomes via the public API.
Load-bearing premise
The AIDev dataset and its 2,355 repositories accurately represent typical AI-bot usage, and the five bots can be identified as PR authors without meaningful mislabeling or selection bias.
What would settle it
A larger or differently sampled collection of repositories that showed no negative correlation, or a positive correlation, between AI PR frequency and workflow success rate would falsify the central repository-level claim.
Figures


read the original abstract
Continuous Integration and Deployment (CI/CD) workflows are central to modern software delivery, yet the reliability of agentic AI bots operating within these workflows remain underexplored. Using pull requests (PRs), commits, and repositories from the AIDev dataset, we retrieved associated CI/CD workflow runs via the GitHub Actions API and analyzed 61,837 runs from 2,355 repositories, all triggered by PRs generated by five AI bots: Claude, Devin, Cursor, Copilot, and Codex. We observed substantial agent-dependent differences in workflow reliability, with Copilot and Codex achieving the highest success rates ~93% and ~94% respectively. At the repository level, we find a negative correlation between AI agent contribution frequency and workflow success rate, suggesting that a higher frequency of Agentic PRs may hinder CI/CD workflow reliability. We defined a taxonomy of 13 categories against 3,067 agentic PRs whose associated workflows failed, and observed a trend analysis that indicates visually observable shifts from functional to non-functional PR categories over time, although these trends are not statistically significant. Our findings motivate the need for actionable guidance on integrating AI agents into CI/CD workflows and prioritizing safeguards in workflows where failures are most likely to occur.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an observational study of 61,837 GitHub Actions CI/CD workflow runs triggered by PRs from five AI bots (Claude, Devin, Cursor, Copilot, Codex) across 2,355 repositories drawn from the AIDev dataset. It reports bot-specific success rates (highest for Copilot and Codex at ~93-94%), a negative correlation at the repository level between AI-agent PR frequency and workflow success rate, and applies a 13-category failure taxonomy to 3,067 failed runs, noting a visually observable but non-statistically-significant shift in failure categories over time.
Significance. If the negative correlation is robust to controls for repository size/activity and to accurate bot attribution, the work would supply concrete empirical grounding for concerns about AI-bot integration in production CI/CD pipelines and would motivate targeted safeguards and usage guidelines in software engineering practice.
major comments (3)
- [Abstract (repository-level analysis) and associated results] The repository-level negative correlation between AI contribution frequency and workflow success rate is presented without reported p-values, confidence intervals, or controls for confounding variables such as repository size, activity level, or language ecosystem; this omission directly weakens the claim that higher frequency 'may hinder' reliability.
- [Data and methods (AIDev dataset usage)] PR authorship attribution to the five bots is load-bearing for both the frequency variable and the success-rate variable, yet the manuscript provides no validation metrics, false-positive/negative rates, or sensitivity analysis for the AIDev dataset labeling heuristics; systematic misattribution would distort the central correlation.
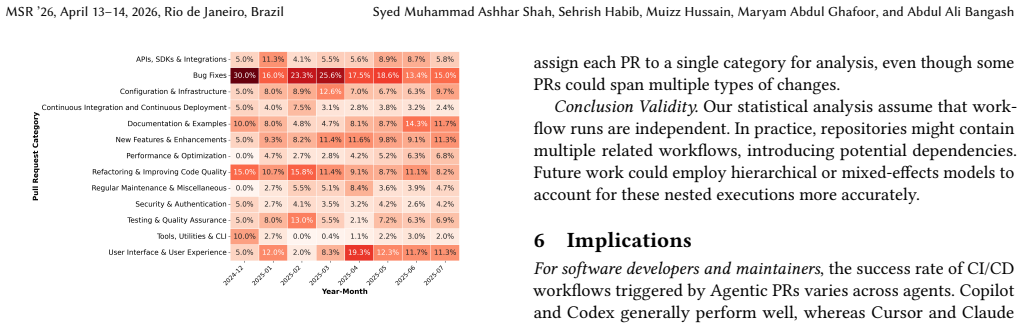
- [Failure taxonomy and trend analysis] The trend analysis of the 13-category failure taxonomy reports a 'visually observable' shift from functional to non-functional categories over time while explicitly noting that the trends are not statistically significant; this framing risks overstating an acknowledged non-result.
minor comments (2)
- [Methods] Clarify the exact operational definition of 'workflow success rate' (e.g., whether it is per-run or per-PR aggregated) and how 'AI agent contribution frequency' is normalized across repositories.
- [Data collection] Provide the total number of repositories screened versus the final 2,355 used, and any inclusion/exclusion criteria applied to the AIDev dataset.
Simulated Author's Rebuttal
Thank you for the constructive and detailed feedback on our manuscript. We address each major comment below and have revised the manuscript to strengthen the statistical reporting, clarify limitations, and avoid potential overstatement of results.
read point-by-point responses
-
Referee: [Abstract (repository-level analysis) and associated results] The repository-level negative correlation between AI contribution frequency and workflow success rate is presented without reported p-values, confidence intervals, or controls for confounding variables such as repository size, activity level, or language ecosystem; this omission directly weakens the claim that higher frequency 'may hinder' reliability.
Authors: We agree that formal statistical measures and controls would strengthen the repository-level analysis. In the revised manuscript we have added a multiple linear regression with AI PR frequency as the predictor and workflow success rate as the outcome. Controls include repository size (log stars and contributors), activity level (total PRs), and language ecosystem (categorical variable for primary language). The negative coefficient for AI frequency remains significant after controls; we now report the p-value and 95% confidence interval in the results section and have updated the abstract to reference the controlled analysis. revision: yes
-
Referee: [Data and methods (AIDev dataset usage)] PR authorship attribution to the five bots is load-bearing for both the frequency variable and the success-rate variable, yet the manuscript provides no validation metrics, false-positive/negative rates, or sensitivity analysis for the AIDev dataset labeling heuristics; systematic misattribution would distort the central correlation.
Authors: The AIDev dataset labels are produced by heuristics described in its source publication; we did not collect independent ground-truth validation for this study. We have added an explicit limitations paragraph on heuristic-based attribution and performed a sensitivity analysis that randomly flips 5% and 10% of bot labels before re-estimating the correlation. The direction and significance of the negative association are robust under these perturbations. We have also cited the original labeling procedure more prominently in the methods. revision: partial
-
Referee: [Failure taxonomy and trend analysis] The trend analysis of the 13-category failure taxonomy reports a 'visually observable' shift from functional to non-functional categories over time while explicitly noting that the trends are not statistically significant; this framing risks overstating an acknowledged non-result.
Authors: We accept that the phrase 'visually observable' could be read as giving undue weight to a non-significant result. In the revision we have replaced it with: 'A visual inspection of the time-series plot indicates a possible shift from functional to non-functional failure categories, yet the trend does not reach statistical significance (p > 0.05) and remains exploratory.' We have also added a sentence underscoring that no causal or definitive conclusions should be drawn from this observation. revision: yes
Circularity Check
No circularity: purely observational analysis of external dataset and API data
full rationale
The paper conducts an observational study by retrieving 61,837 GitHub Actions workflow runs from the AIDev dataset and GitHub API for PRs attributed to five AI bots. It computes success rates, repository-level correlations, and a taxonomy of failure categories directly from the measured data. No equations, fitted parameters, predictions, self-citations, or derivations are present that reduce any result to an input by construction. The negative correlation and agent-dependent differences are reported as empirical observations without any self-referential modeling steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pull-request authorship labels in the AIDev dataset correctly identify the five AI bots without substantial error.
- domain assumption GitHub Actions API returns complete and accurate workflow-run status for the sampled PRs.
invented entities (1)
-
13-category failure taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho, Monica S
Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. 2006.Compilers: Principles, Techniques, and Tools. Pearson, Boston, MA. Reliability of AI Bots Footprints in GitHub Actions CI/CD Workflows MSR ’26, April 13–14, 2026, Rio de Janeiro, Brazil
2006
- [2]
- [3]
-
[4]
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2022. Grounded Copilot: How Programmers Interact with Code-Generating Models. arXiv:2206.15000 [cs.HC] https://arxiv.org/abs/2206.15000
-
[5]
Moritz Beller, Georgios Gousios, and Andy Zaidman. 2017. Oops, My Tests Broke the Build: An Explorative Analysis of Travis CI with GitHub. In2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR). 356–367. doi:10.1109/MSR.2017.62
-
[6]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psy- chology.Qualitative Research in Psychology3 (01 2006), 77–101. doi:10.1191/ 1478088706qp063oa
2006
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Moataz Chouchen, Narjes Bessghaier, Mahi Begoug, Ali Ouni, Eman Alomar, and Mohamed Wiem Mkaouer. 2024. How Do Software Developers Use Chat- GPT? An Exploratory Study on GitHub Pull Requests. InProceedings of the 21st International Conference on Mining Software Repositories(Lisbon, Portugal) (MSR ’24). Association for Computing Machinery, New York, NY, US...
- [9]
-
[10]
Matheus De Morais Leça, Mariana Bento, and Ronnie De Souza Santos. 2025. Responsible AI in the Software Industry: A Practitioner-Centered Perspective. In2025 IEEE/ACM International Workshop on Responsible AI Engineering (RAIE). 37–40. doi:10.1109/RAIE66699.2025.00011
-
[11]
Ahmad Fadavi and Mohsen Alizadeh. 2024. Ownership of Artificial Intelligence- Generated Works: An Overview of the Emerging Intellectual Property Challenges in the Technology Era. (11 2024). doi:10.30497/law.2024.245828.3492
-
[12]
Keheliya Gallaba and Shane McIntosh. 2018. Use and Misuse of Continuous Integration Features: An Empirical Study of Projects That (Mis)Use Travis CI. IEEE Transactions on Software EngineeringPP (05 2018), 1–1. doi:10.1109/TSE. 2018.2838131
work page doi:10.1109/tse 2018
-
[13]
Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu
Ahmed E. Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu. 2025. Agentic Software Engineering: Foundational Pillars and a Research Roadmap. arXiv:2509.06216 [cs.SE] https://arxiv.org/abs/ 2509.06216
-
[14]
Michael Hilton, Timothy Tunnell, Kai Huang, Darko Marinov, and Danny Dig
-
[15]
Usage, costs, and benefits of continuous integration in open-source projects. InProceedings of the 31st IEEE/ACM International Conference on Automated Soft- ware Engineering(Singapore, Singapore)(ASE ’16). Association for Computing Machinery, New York, NY, USA, 426–437. doi:10.1145/2970276.2970358
-
[16]
SAIL Research. 2026. AIDev Challenge Dataset: AI Teammates in Software Engineering 3.0. https://github.com/SAILResearch/AI_Teammates_in_SE3/blob/ main/AIDev_Challenge.pdf. Accessed: 2025-10-04
2026
-
[17]
Sakshi Kini Sana Ansari. 2024. The World’s First AI Software Engineer, DEVIN AI.INTERNATIONAL JOURNAL OF INNOV ATIVE RESEARCH IN TECHNOLOGY (2024)
2024
-
[18]
Jadson Santos, Daniel Alencar da Costa, and Uirá Kulesza. 2022. Investigating the Impact of Continuous Integration Practices on the Productivity and Quality of Open-Source Projects. InProceedings of the 16th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM ’22). ACM, 137–147. doi:10.1145/3544902.3546244
-
[19]
Syed Muhammad Ashhar Shah, Sehrish Habib, Muizz Hussain, Maryam Ab- dul Ghafoor, and Abdul Ali Bangash. 2025. Reliability of AI Bots Footprints in GitHub Actions CI/CD Workflows - Replication Package. doi:10.5281/zenodo. 17867301
-
[20]
Tao Xiao, Youmei Fan, Fabio Calefato, Christoph Treude, Raula Gaikovina Kula, Hideaki Hata, and Sebastian Baltes. 2025. Self-Admitted GenAI Usage in Open- Source Software. arXiv:2507.10422 [cs.SE] https://arxiv.org/abs/2507.10422
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Alan Yang and T. Andrew Yang. 2024. Social Dangers of Generative Artifi- cial Intelligence: Review and Guidelines. InProceedings of the 25th Annual In- ternational Conference on Digital Government Research(Taipei, Taiwan)(dg.o ’24). Association for Computing Machinery, New York, NY, USA, 654–658. doi:10.1145/3657054.3664243
-
[22]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer In- terfaces Enable Automated Software Engineering. arXiv:2405.15793 [cs.SE] https://arxiv.org/abs/2405.15793
work page internal anchor Pith review arXiv 2024
-
[23]
Zhimin Zhao, Yihao Chen, Abdul Ali Bangash, Bram Adams, and Ahmed E. Hassan. 2024. An empirical study of challenges in machine learning asset man- agement.Empirical Software Engineering29, 4 (June 2024). doi:10.1007/s10664- 024-10474-4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.