Recognition: unknown
One Pass for All: A Discrete Diffusion Model for Knowledge Graph Triple Set Prediction
Pith reviewed 2026-05-10 05:07 UTC · model grok-4.3
The pith
A discrete diffusion model generates entire sets of missing triples in knowledge graphs by reversing a progressive masking process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiffTSP models the triple set prediction as a discrete diffusion generative task. It adds noise by progressively masking relational edges in the knowledge graph during the forward process. The reverse process then employs a structure-aware denoising network, which combines a relational context encoder and a relational graph diffusion transformer, to reconstruct the full set of triples conditioned on the observed graph, allowing all missing triples to be generated simultaneously while respecting their dependencies.
What carries the argument
The discrete diffusion process on relational edges, reversed by an integrated relational context encoder and graph diffusion transformer that conditions the generation on the incomplete graph structure.
If this is right
- DiffTSP produces consistent triple sets by modeling their joint distribution rather than independent predictions.
- The approach eliminates the need for sequential triple generation, reducing potential error accumulation.
- Performance reaches state-of-the-art levels on three public knowledge graph datasets.
- The method can handle the realistic scenario where no partial information about missing triples is provided.
Where Pith is reading between the lines
- If the diffusion schedule works well for graphs, similar techniques might improve other structured prediction tasks like molecule design or program synthesis.
- This could lead to more robust knowledge graph applications in question answering or recommendation systems by reducing contradictory facts.
- Testing on very large graphs would reveal whether the one-pass advantage scales computationally.
Load-bearing premise
That the chosen discrete noise schedule of masking edges allows the reverse denoising process to recover valid and consistent triple sets without introducing spurious relations.
What would settle it
Observing whether the model outputs triples that violate known logical constraints in the graph, such as predicting both a relation and its negation, more often than baseline methods.
Figures





read the original abstract
Knowledge Graphs (KGs) are composed of triples, and the goal of Knowledge Graph Completion (KGC) is to infer the missing factual triples. Traditional KGC tasks predict missing elements in a triple given one or two of its elements. As a more realistic task, the Triple Set Prediction (TSP) task aims to infer the set of missing triples conditioned only on the observed knowledge graph, without assuming any partial information about the missing triples. Existing TSP methods predict the set of missing triples in a triple-by-triple manner, falling short in capturing the dependencies among the predicted triples to ensure consistency. To address this issue, we propose a novel discrete diffusion model termed DiffTSP that treats TSP as a generative task. DiffTSP progressively adds noise to the KG through a discrete diffusion process, achieved by masking relational edges. The reverse process then gradually recovers the complete KG conditioned on the incomplete graph. To this end, we design a structure-aware denoising network that integrates a relational context encoder with a relational graph diffusion transformer for knowledge graph generation. DiffTSP can generate the complete set of triples in a one-pass manner while ensuring the dependencies among the predicted triples. Our approach achieves state-of-the-art performance on three public datasets. Code: https://github.com/ADMIS-TONGJI/DiffTSP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffTSP, a discrete diffusion model for the Triple Set Prediction (TSP) task on knowledge graphs. It frames TSP as a generative problem: a forward process progressively masks relational edges to add noise to the observed KG, while a reverse process uses a structure-aware denoising network (combining a relational context encoder with a relational graph diffusion transformer) to recover the full set of triples in one pass. The key claim is that this captures dependencies among predicted triples to ensure consistency, outperforming sequential TSP methods and achieving state-of-the-art results on three public datasets.
Significance. If the central claims are validated, the work provides a novel generative approach to TSP that directly addresses dependency and consistency limitations of triple-by-triple prediction. The discrete diffusion formulation on relational graphs could influence future structured prediction tasks in KGs and beyond, particularly if the one-pass generation reliably produces valid triple sets without post-processing.
major comments (2)
- [§3] §3 (Forward Diffusion Process): The definition of the discrete diffusion via progressive masking of relational edges does not include a closed-form marginal or proof that every masked state has positive probability of denoising to a globally consistent triple set. The edge-centric schedule can violate entity-relation constraints (e.g., cardinality or functional dependencies) that are not explicitly restored by the denoiser, leaving the consistency guarantee dependent on implicit learning rather than enforced structure.
- [§5] §5 (Experiments): The SOTA claim on three datasets is presented without reported standard deviations across runs, ablation results isolating the contribution of the relational graph diffusion transformer versus the context encoder, or direct comparisons showing improved dependency metrics (e.g., consistency scores on conflicting relations). This weakens support for the central claim that one-pass generation reliably captures inter-triple dependencies.
minor comments (3)
- [§4.2] §4.2 (Denoising Network): The integration of the relational context encoder with the diffusion transformer is described at a high level; provide pseudocode or a detailed diagram showing how relational context is injected at each diffusion step.
- [Notation] Notation throughout: Define the exact masking probability schedule (e.g., linear vs. cosine) and the precise form of the reverse transition kernel p_θ(x_{t-1}|x_t, G_obs) to allow reproduction.
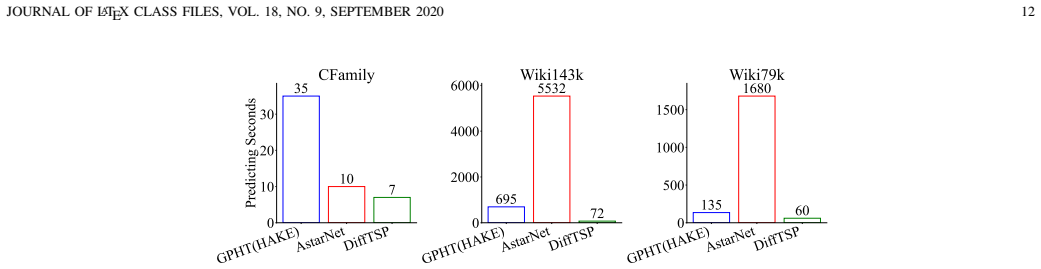
- [Results] Table 1 or results section: Include the number of parameters and inference time per sample for DiffTSP versus baselines to contextualize the one-pass efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which have helped us identify areas for improvement in the manuscript. We address each major comment point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (Forward Diffusion Process): The definition of the discrete diffusion via progressive masking of relational edges does not include a closed-form marginal or proof that every masked state has positive probability of denoising to a globally consistent triple set. The edge-centric schedule can violate entity-relation constraints (e.g., cardinality or functional dependencies) that are not explicitly restored by the denoiser, leaving the consistency guarantee dependent on implicit learning rather than enforced structure.
Authors: We appreciate the referee's emphasis on the theoretical foundations of the diffusion process. The forward process is defined via progressive edge masking to enable one-pass recovery of the full triple set, consistent with discrete diffusion frameworks for structured data. We do not derive a closed-form marginal because the model prioritizes empirical performance on the TSP task over analytical tractability. The denoiser is structure-aware and trained to recover consistent graphs from corrupted inputs, but we acknowledge that consistency is learned implicitly rather than enforced via explicit constraints. In the revision, we will expand §3 with a clearer description of the masking schedule, add a discussion of the implicit consistency mechanism, and note the absence of hard constraint enforcement as a limitation with suggestions for future work (e.g., constrained decoding). A formal proof of positive probability for denoising to globally consistent sets is not feasible within the current scope and would require substantial additional theoretical development. revision: partial
-
Referee: [§5] §5 (Experiments): The SOTA claim on three datasets is presented without reported standard deviations across runs, ablation results isolating the contribution of the relational graph diffusion transformer versus the context encoder, or direct comparisons showing improved dependency metrics (e.g., consistency scores on conflicting relations). This weakens support for the central claim that one-pass generation reliably captures inter-triple dependencies.
Authors: We agree that these experimental details are essential for rigorously validating the central claims. In the revised manuscript, we will report standard deviations computed over multiple independent runs for all reported metrics on the three datasets. We will add ablation experiments that separately evaluate the relational context encoder and the relational graph diffusion transformer to quantify their individual contributions. Additionally, we will introduce and report dependency-aware metrics, including consistency scores that measure the frequency of conflicting or invalid relation predictions (e.g., violations of functional dependencies), and provide direct comparisons against sequential baselines on these metrics to better demonstrate the benefits of one-pass generation. revision: yes
- A closed-form marginal for the forward diffusion process and a formal proof that every masked state has positive probability of denoising to a globally consistent triple set
Circularity Check
No circularity: forward masking and reverse denoising are independently specified architectural choices
full rationale
The paper defines the forward diffusion process explicitly as progressive masking of relational edges and the reverse process via a custom structure-aware denoising network (relational context encoder + relational graph diffusion transformer). No equation reduces the claimed one-pass consistent generation or SOTA performance to a fitted parameter or self-citation by construction; the consistency guarantee is presented as an empirical outcome of training the model on observed KGs and evaluating on held-out public datasets. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on knowledge graphs: Representation, acquisition, and applications,
S. Ji, S. Pan, E. Cambria, P. Marttinen, and S. Y . Philip, “A survey on knowledge graphs: Representation, acquisition, and applications,”IEEE transactions on neural networks and learning systems, vol. 33, no. 2, pp. 494–514, 2021
2021
-
[2]
Bridging the space gap: Unifying geometry knowledge graph embedding with optimal transport,
Y . Liu, Z. Cao, X. Gao, J. Zhang, and R. Yan, “Bridging the space gap: Unifying geometry knowledge graph embedding with optimal transport,” inProceedings of the ACM Web Conference 2024, 2024, pp. 2128–2137
2024
-
[3]
Query2gmm: Learning representation with gaussian mixture model for reasoning over knowl- edge graphs,
Y . Wu, Y . Xu, W. Zhang, X. Xu, and Y . Zhang, “Query2gmm: Learning representation with gaussian mixture model for reasoning over knowl- edge graphs,” inProceedings of the ACM web conference 2024, 2024, pp. 2149–2158. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 12 GPHT(HAKE) AstarNetDiffTSP 0 10 20 30Predicting Seconds 35 10 7 CFamily GP...
2024
-
[4]
Question answering over knowledge graphs: question understanding via template decomposition,
W. Zheng, J. X. Yu, L. Zou, and H. Cheng, “Question answering over knowledge graphs: question understanding via template decomposition,” Proceedings of the VLDB Endowment, vol. 11, no. 11, pp. 1373–1386, 2018
2018
-
[5]
Qa-gnn: Reasoning with language models and knowledge graphs for question answering,
M. Yasunaga, H. Ren, A. Bosselut, P. Liang, and J. Leskovec, “Qa-gnn: Reasoning with language models and knowledge graphs for question answering,”arXiv preprint arXiv:2104.06378, 2021
-
[6]
Sequence-to-sequence knowl- edge graph completion and question answering,
A. Saxena, A. Kochsiek, and R. Gemulla, “Sequence-to-sequence knowl- edge graph completion and question answering,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Association for Computational Lin...
2022
-
[7]
Alicg: Fine-grained and evolvable conceptual graph construction for semantic search at alibaba,
N. Zhang, Q. Jia, S. Deng, X. Chen, H. Ye, H. Chen, H. Tou, G. Huang, Z. Wang, N. Huaet al., “Alicg: Fine-grained and evolvable conceptual graph construction for semantic search at alibaba,” inProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, 2021, pp. 3895–3905
2021
-
[8]
A method for assessing inference patterns captured by embedding models in knowledge graphs,
N. A. Krishnan and C. R. Rivero, “A method for assessing inference patterns captured by embedding models in knowledge graphs,” in Proceedings of the ACM Web Conference 2024, 2024, pp. 2030–2041
2024
-
[9]
Path-based explana- tion for knowledge graph completion,
H. Chang, J. Ye, A. Lopez-Avila, J. Du, and J. Li, “Path-based explana- tion for knowledge graph completion,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 231–242
2024
-
[10]
Integrate temporal graph learning into llm-based temporal knowledge graph model,
H. Chang, J. Wu, Z. Tao, Y . Ma, X. Huang, and T.-S. Chua, “Integrate temporal graph learning into llm-based temporal knowledge graph model,”arXiv preprint arXiv:2501.11911, 2025
-
[11]
Convolutional 2d knowledge graph embeddings,
T. Dettmers, P. Minervini, P. Stenetorp, and S. Riedel, “Convolutional 2d knowledge graph embeddings,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[12]
Learning entity and relation embeddings for knowledge graph completion,
Y . Lin, Z. Liu, M. Sun, Y . Liu, and X. Zhu, “Learning entity and relation embeddings for knowledge graph completion,” inProceedings of the AAAI conference on artificial intelligence, vol. 29, no. 1, 2015
2015
-
[13]
Unifying large language models and knowledge graphs: A roadmap,
S. Pan, L. Luo, Y . Wang, C. Chen, J. Wang, and X. Wu, “Unifying large language models and knowledge graphs: A roadmap,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 7, pp. 3580–3599, 2024
2024
-
[14]
Reta: A schema-aware, end-to-end solution for instance completion in knowledge graphs,
P. Rosso, D. Yang, N. Ostapuk, and P. Cudr ´e-Mauroux, “Reta: A schema-aware, end-to-end solution for instance completion in knowledge graphs,” inProceedings of the Web Conference 2021, 2021, pp. 845–856
2021
-
[15]
Start from zero: Triple set prediction for automatic knowledge graph completion,
W. Zhang, Y . Xu, P. Ye, Z. Huang, Z. Xu, J. Chen, J. Z. Pan, and H. Chen, “Start from zero: Triple set prediction for automatic knowledge graph completion,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 7087–7101, 2024
2024
-
[16]
Tgformer: A graph trans- former framework for knowledge graph embedding,
F. Shi, D. Li, X. Wang, B. Li, and X. Wu, “Tgformer: A graph trans- former framework for knowledge graph embedding,”IEEE Transactions on Knowledge and Data Engineering, 2024
2024
-
[17]
Is large language model good at triple set prediction? an empirical study,
Y . Yuan, Y . Xu, and W. Zhang, “Is large language model good at triple set prediction? an empirical study,” in2024 IEEE International Conference on Knowledge Graph (ICKG). IEEE, 2024, pp. 470–476
2024
-
[18]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[19]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[20]
Repaint: Inpainting using denoising diffusion probabilistic models,
A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “Repaint: Inpainting using denoising diffusion probabilistic models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 461–11 471
2022
-
[21]
Large Language Diffusion Models
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.- R. Wen, and C. Li, “Large language diffusion models,”arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
M. Arriola, A. Gokaslan, J. T. Chiu, Z. Yang, Z. Qi, J. Han, S. S. Sahoo, and V . Kuleshov, “Block diffusion: Interpolating between autoregressive and diffusion language models,”arXiv preprint arXiv:2503.09573, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Kgdm: A diffusion model to capture multiple relation semantics for knowledge graph embedding,
X. Long, L. Zhuang, A. Li, J. Wei, H. Li, and S. Wang, “Kgdm: A diffusion model to capture multiple relation semantics for knowledge graph embedding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 8, 2024, pp. 8850–8858
2024
-
[24]
Fact embedding through diffusion model for knowledge graph completion,
X. Long, L. Zhuang, A. Li, H. Li, and S. Wang, “Fact embedding through diffusion model for knowledge graph completion,” inProceed- ings of the ACM Web Conference 2024, 2024, pp. 2020–2029
2024
-
[25]
Llm-dr: A novel llm-aided diffusion model for rule generation on temporal knowledge graphs,
K. Chen, X. Song, Y . Wang, L. Gao, A. Li, X. Zhao, B. Zhou, and Y . Xie, “Llm-dr: A novel llm-aided diffusion model for rule generation on temporal knowledge graphs,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 11, 2025, pp. 11 481–11 489
2025
-
[26]
Dpcl-diff: Temporal knowledge graph reasoning based on graph node diffusion model with dual-domain periodic contrastive learning,
Y . Cao, L. Wang, and L. Huang, “Dpcl-diff: Temporal knowledge graph reasoning based on graph node diffusion model with dual-domain periodic contrastive learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 14, 2025, pp. 14 806–14 814
2025
-
[27]
Unifying deductive and abductive reasoning in knowledge graphs with masked diffusion model,
Y . Gao, J. Bai, Y . Huang, X. Fu, Q. Sun, and Y . Song, “Unifying deductive and abductive reasoning in knowledge graphs with masked diffusion model,”arXiv preprint arXiv:2510.11462, 2025
-
[28]
Raker: A relation-aware knowledge reasoning model for inductive relation prediction,
J. Wang, W. Li, Y . Shu, J. Guan, Y . Zhang, and S. Zhou, “Raker: A relation-aware knowledge reasoning model for inductive relation prediction,”ACM Transactions on Knowledge Discovery from Data, 2025
2025
-
[29]
Translating embeddings for modeling multi-relational data,
A. Bordes, N. Usunier, A. Garc ´ıa-Dur´an, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” inAd- vances in Neural Information Processing Systems 26: 27th Annual Con- ference on Neural Information Processing Systems 2013. Proceedings of a Meeting Held December 5-8, 2013, Lake Tahoe, Nevada, United States, C. J. C. ...
2013
-
[30]
RotatE: Knowledge graph embedding by relational rotation in complex space,
Z. Sun, Z.-H. Deng, J.-Y . Nie, and J. Tang, “RotatE: Knowledge graph embedding by relational rotation in complex space,” in7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
2019
-
[31]
Learning hierarchy-aware knowledge graph embeddings for link prediction,
Z. Zhang, J. Cai, Y . Zhang, and J. Wang, “Learning hierarchy-aware knowledge graph embeddings for link prediction,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 03, 2020, pp. 3065–3072
2020
-
[32]
Pairre: Knowledge graph em- beddings via paired relation vectors,
L. Chao, J. He, T. Wang, and W. Chu, “Pairre: Knowledge graph em- beddings via paired relation vectors,”arXiv preprint arXiv:2011.03798, 2020
-
[33]
Modeling relational data with graph convolutional networks,
M. Schlichtkrull, T. N. Kipf, P. Bloem, R. Van Den Berg, I. Titov, and M. Welling, “Modeling relational data with graph convolutional networks,” inEuropean semantic web conference. Springer, 2018, pp. 593–607
2018
-
[34]
Composition- based multi-relational graph convolutional networks,
S. Vashishth, S. Sanyal, V . Nitin, and P. Talukdar, “Composition- based multi-relational graph convolutional networks,”arXiv preprint arXiv:1911.03082, 2019
-
[35]
Meta-knowledge transfer for inductive knowledge graph embedding,
M. Chen, W. Zhang, Y . Zhu, H. Zhou, Z. Yuan, C. Xu, and H. Chen, “Meta-knowledge transfer for inductive knowledge graph embedding,” in SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 13 2022, E. Amig ´o, P...
2020
-
[36]
A* net: A scalable path-based reasoning approach for knowledge graphs,
Z. Zhu, X. Yuan, M. Galkin, L.-P. Xhonneux, M. Zhang, M. Gazeau, and J. Tang, “A* net: A scalable path-based reasoning approach for knowledge graphs,”Advances in Neural Information Processing Sys- tems, vol. 36, pp. 59 323–59 336, 2023
2023
-
[37]
Towards foundation models for knowledge graph reasoning,
M. Galkin, X. Yuan, H. Mostafa, J. Tang, and Z. Zhu, “Towards foundation models for knowledge graph reasoning,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[38]
Score-based generative modeling of graphs via the system of stochastic differential equations,
J. Jo, S. Lee, and S. J. Hwang, “Score-based generative modeling of graphs via the system of stochastic differential equations,” inInterna- tional conference on machine learning. PMLR, 2022, pp. 10 362– 10 383
2022
-
[39]
The Eleventh International Conference on Learning Representations , publisher =
C. Vignac, I. Krawczuk, A. Siraudin, B. Wang, V . Cevher, and P. Frossard, “Digress: Discrete denoising diffusion for graph generation,” arXiv preprint arXiv:2209.14734, 2022
-
[40]
Graph diffusion transformers for multi-conditional molecular generation,
G. Liu, J. Xu, T. Luo, and M. Jiang, “Graph diffusion transformers for multi-conditional molecular generation,”Advances in Neural Informa- tion Processing Systems, vol. 37, pp. 8065–8092, 2024
2024
-
[41]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[42]
Learning structured output represen- tation using deep conditional generative models,
K. Sohn, H. Lee, and X. Yan, “Learning structured output represen- tation using deep conditional generative models,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[43]
Stochastic conditional diffusion models for robust semantic image synthesis,
J. Ko, I. Kong, D. Park, and H. J. Kim, “Stochastic conditional diffusion models for robust semantic image synthesis,”arXiv preprint arXiv:2402.16506, 2024
-
[44]
Struc- tured denoising diffusion models in discrete state-spaces,
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. Van Den Berg, “Struc- tured denoising diffusion models in discrete state-spaces,”Advances in neural information processing systems, vol. 34, pp. 17 981–17 993, 2021
2021
-
[45]
Tensorlog: Deep learning meets probabilistic dbs,
W. W. Cohen, F. Yang, and K. R. Mazaitis, “Tensorlog: Deep learning meets probabilistic dbs,”arXiv preprint arXiv:1707.05390, 2017. VIII. BIOGRAPHYSECTION Jihong Guanreceived the bachelor’s degree from Huazhong Normal University in 1991, the mas- ter’s degree from Wuhan Technical University of Surveying and Mapping (merged into Wuhan Uni- versity since 20...
-
[46]
Her research interests include databases, data mining, distributed computing, bioinformatics, and geographic information systems (GIS)
in the School of Computer, Wuhan University. Her research interests include databases, data mining, distributed computing, bioinformatics, and geographic information systems (GIS). Jiaqi Wangreceived a bachelor’s degree in Com- puter Science and Technology with a dual degree in Mathematics from Tongji University, Shanghai, China, in 2022. He is currently ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.