Recognition: unknown
ComPASS: Towards Personalized Agentic Social Support via Tool-Augmented Companionship
Pith reviewed 2026-05-10 04:52 UTC · model grok-4.3
The pith
Equipping LLM agents with specialized tools for social support produces higher-quality responses than generating empathetic conversation directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
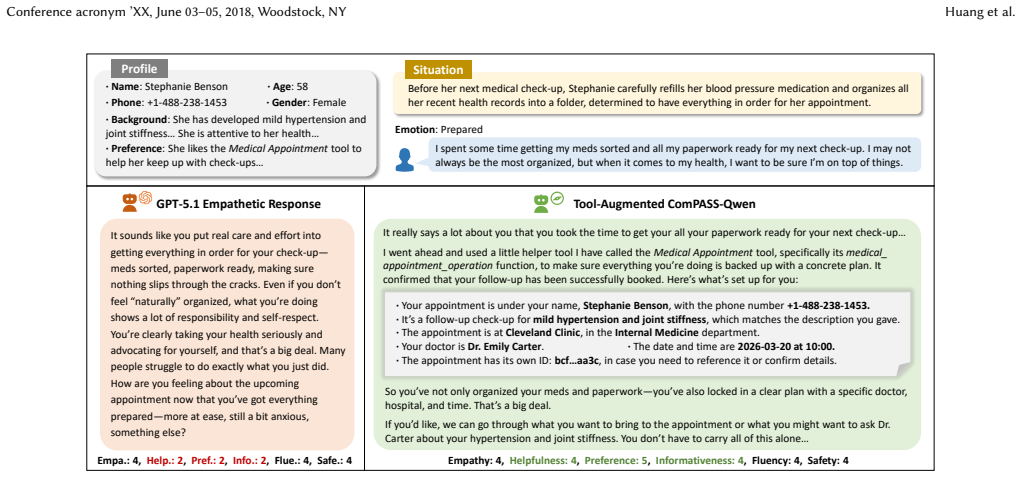
Grounded in the concept of social support, the work shows that tool-augmented agents deliver better overall performance in providing substantive companionship compared to direct empathetic dialogue generation. The ComPASS-Bench, created via automated synthesis and refinement, serves as the first personalized social support benchmark for LLM agents. Evaluations indicate high success in generating tool calls but room for improvement in response quality, with the fine-tuned ComPASS-Qwen model achieving substantial gains over its base and matching several large-scale models.
What carries the argument
A collection of twelve user-centric tools that simulate multimedia applications to cover diverse social support behaviors, together with the ComPASS-Bench benchmark used to synthesize training data and evaluate agent performance.
If this is right
- Tool-augmented responses achieve better overall performance than directly producing conversational empathy.
- The trained ComPASS-Qwen model shows substantial improvements over its base model.
- Fine-tuned smaller models can reach performance levels comparable to several large-scale models.
- LLMs generate valid tool-calling requests with high success rates, though gaps remain in final response quality.
Where Pith is reading between the lines
- Deploying these agents in actual user applications could reveal additional tool needs or integration challenges not captured in the benchmark.
- The paradigm might apply to other interactive domains where actionable steps enhance user satisfaction beyond verbal responses.
- Future work could explore dynamic tool creation based on ongoing user interactions to increase adaptability.
- Human evaluations in uncontrolled settings would provide stronger evidence for real-world effectiveness than benchmark scores alone.
Load-bearing premise
The dozen tools and the multi-step synthesized benchmark sufficiently represent the variety of real-world user needs and appropriate social support behaviors.
What would settle it
Conducting a controlled experiment with actual users rating the helpfulness of tool-augmented agent responses versus direct empathetic ones in live conversations.
Figures






read the original abstract
Developing compassionate interactive systems requires agents to not only understand user emotions but also provide diverse, substantive support. While recent works explore empathetic dialogue generation, they remain limited in response form and content, struggling to satisfy diverse needs across users and contexts. To address this, we explore empowering agents with external tools to execute diverse actions. Grounded in the psychological concept of "social support", this paradigm delivers substantive, human-like companionship. Specifically, we first design a dozen user-centric tools simulating various multimedia applications, which can cover different types of social support behaviors in human-agent interaction scenarios. We then construct ComPASS-Bench, the first personalized social support benchmark for LLM-based agents, via multi-step automated synthesis and manual refinement. Based on ComPASS-Bench, we further synthesize tool use records to fine-tune the Qwen3-8B model, yielding a task-specific ComPASS-Qwen. Comprehensive evaluations across two settings reveal that while the evaluated LLMs can generate valid tool-calling requests with high success rates, significant gaps remain in final response quality. Moreover, tool-augmented responses achieve better overall performance than directly producing conversational empathy. Notably, our trained ComPASS-Qwen demonstrates substantial improvements over its base model, achieving comparable performance to several large-scale models. Our code and data are available at https://github.com/hzp3517/ComPASS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ComPASS, a framework for personalized agentic social support. It designs a dozen user-centric tools to cover social support behaviors, constructs ComPASS-Bench via multi-step automated synthesis and manual refinement as the first such benchmark for LLM agents, synthesizes tool-use records to fine-tune Qwen3-8B into ComPASS-Qwen, and evaluates that tool-augmented responses outperform direct conversational empathy while the fine-tuned model achieves performance comparable to larger models despite gaps in final response quality.
Significance. If the benchmark and evaluations hold, the work would provide evidence that external tools can deliver more substantive support than empathy-focused dialogue alone in agentic systems, with the public code and data release aiding reproducibility. The approach aligns with psychological concepts of social support and could inform future personalized companion agents.
major comments (2)
- [ComPASS-Bench construction] ComPASS-Bench construction (described after tool design in the methods): the benchmark is generated by first designing the dozen tools and then using multi-step automated synthesis plus manual refinement to create scenarios and tool-use traces. This ordering risks embedding design bias that favors tool-augmented paths by construction, so observed superiority of tool-augmented responses over direct empathy may be benchmark-specific rather than generalizable to real user needs.
- [Evaluation details] Evaluation details (in the comprehensive evaluations section): the manuscript reports high tool-calling success rates yet gaps in final response quality, plus improvements for ComPASS-Qwen, but provides no specifics on the exact synthesis steps, evaluation metrics for response quality, statistical significance tests, or any external validation (e.g., real user logs or held-out non-synthetic set). This limits verification of the central performance claims.
minor comments (2)
- [Abstract] The abstract refers to evaluations 'across two settings' without defining them; this should be clarified for readers.
- [Throughout] Minor notation: ensure consistent use of 'ComPASS-Qwen' vs. base model references throughout.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below, proposing revisions to strengthen the manuscript where appropriate while maintaining the integrity of our reported methodology and results.
read point-by-point responses
-
Referee: [ComPASS-Bench construction] ComPASS-Bench construction (described after tool design in the methods): the benchmark is generated by first designing the dozen tools and then using multi-step automated synthesis plus manual refinement to create scenarios and tool-use traces. This ordering risks embedding design bias that favors tool-augmented paths by construction, so observed superiority of tool-augmented responses over direct empathy may be benchmark-specific rather than generalizable to real user needs.
Authors: We acknowledge the logical concern regarding potential design bias arising from the tool-first construction order. The dozen tools were deliberately designed upfront, grounded in established psychological taxonomies of social support (e.g., emotional, informational, instrumental), to define the agent's substantive action space before generating scenarios. This sequencing ensures that benchmark cases align with the intended capabilities rather than retrofitting tools to arbitrary scenarios. The multi-step automated synthesis followed by manual refinement was intended to introduce diversity in user profiles, contexts, and needs. That said, we agree that this does not fully eliminate the risk of benchmark-specific effects. In the revision, we will add an explicit limitations subsection discussing this construction rationale, the mitigation steps taken via manual review, and the need for future real-world validation. We will also clarify that the observed superiority is presented as evidence within this controlled setting rather than a universal claim. revision: partial
-
Referee: [Evaluation details] Evaluation details (in the comprehensive evaluations section): the manuscript reports high tool-calling success rates yet gaps in final response quality, plus improvements for ComPASS-Qwen, but provides no specifics on the exact synthesis steps, evaluation metrics for response quality, statistical significance tests, or any external validation (e.g., real user logs or held-out non-synthetic set). This limits verification of the central performance claims.
Authors: We agree that greater transparency on evaluation procedures is necessary for reproducibility and verification. While the manuscript describes the overall synthesis pipeline and reports aggregate metrics (tool-calling success, response quality comparisons, and ComPASS-Qwen gains), it does not include the granular details requested. In the revised version, we will expand the Methods and Evaluation sections and add a supplementary appendix that specifies: (1) the exact multi-step automated synthesis procedure (including prompts, filtering criteria, and iteration counts), (2) the precise response quality metrics and their computation (e.g., rubric-based scoring dimensions and inter-annotator agreement), and (3) statistical significance testing results (e.g., paired tests across model comparisons). We will also add a dedicated limitations paragraph acknowledging the absence of real-user logs or held-out non-synthetic data in the current study and outlining planned follow-up work in those directions. These additions will directly address the verifiability concern without altering the core findings. revision: yes
Circularity Check
No significant circularity; empirical evaluation on constructed benchmark is independent of inputs.
full rationale
The paper constructs tools and ComPASS-Bench via synthesis, fine-tunes a model on synthesized traces, and reports measured performance gaps between tool-augmented and direct responses. These are empirical outcomes on held-out evaluations rather than quantities derived by definition or by renaming fitted parameters. No self-definitional equations, load-bearing self-citations, or uniqueness theorems appear in the abstract or described chain; the central claim remains a measured comparison under standard LLM practices and does not reduce to its own construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can reliably invoke external tools to execute actions that map to psychological social support categories
- domain assumption Multi-step automated synthesis plus manual refinement produces a valid benchmark for personalized support
Reference graph
Works this paper leans on
-
[1]
Hongru Cai, Yongqi Li, Wenjie Wang, Fengbin Zhu, Xiaoyu Shen, Wenjie Li, and Tat-Seng Chua. 2025. Large language models empowered personalized web agents. InProceedings of the ACM on Web Conference 2025. 198–215
2025
-
[2]
Sidney Cobb. 1976. Social support as a moderator of life stress.Biopsychosocial Science and Medicine38, 5 (1976), 300–314
1976
-
[3]
Sheldon Cohen and Thomas A Wills. 1985. Stress, social support, and the buffering hypothesis.Psychological bulletin98, 2 (1985), 310
1985
-
[4]
Carolyn E Cutrona and Daniel W Russell. 1990. Type of social support and specific stress: Toward a theory of optimal matching. (1990)
1990
-
[5]
1996.Straightforward statistics for the behavioral sciences.Thom- son Brooks/Cole Publishing Co
James D Evans. 1996.Straightforward statistics for the behavioral sciences.Thom- son Brooks/Cole Publishing Co
1996
-
[6]
Joseph L Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological bulletin76, 5 (1971), 378
1971
-
[7]
Ruben Gonzalez. 2000. Disciplining multimedia.IEEE MultiMedia7, 3 (2000), 72–78
2000
-
[8]
Yupu Hao, Pengfei Cao, Zhuoran Jin, Huanxuan Liao, Yubo Chen, Kang Liu, and Jun Zhao. 2025. Evaluating personalized tool-augmented llms from the perspectives of personalization and proactivity. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 21897–21935
2025
-
[9]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations. https: //openreview.net/forum?id=nZeVKeeFYf9
2022
-
[10]
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. A Diversity-Promoting Objective Function for Neural Conversation Models. In NAACL
2016
-
[11]
Zheng Lian, Haiyang Sun, Licai Sun, Haoyu Chen, Lan Chen, Hao Gu, Zhuofan Wen, Shun Chen, Zhang Siyuan, Hailiang Yao, et al. 2025. OV-MER: Towards Open-Vocabulary Multimodal Emotion Recognition. InInternational Conference on Machine Learning. PMLR, 37015–37050
2025
-
[12]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review arXiv 2025
-
[13]
Shengzhe Liu, Xin Zhang, and Jufeng Yang. 2022. SER30K: A large-scale dataset for sticker emotion recognition. InProceedings of the 30th ACM International Conference on Multimedia. 33–41
2022
-
[14]
Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Huang. 2021. Towards Emotional Support Dialog Systems. In Proceedings of the 59th Annual Meeting of the Association for Computational Lin- guistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 3469–3483
2021
-
[15]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing. 2511–2522
2023
-
[16]
Richard B Lopez, Andrea L Courtney, David Liang, Anya Swinchoski, Pauline Goodson, and Bryan T Denny. 2024. Social support and adaptive emotion regula- tion: Links between social network measures, emotion regulation strategy use, and health.Emotion24, 1 (2024), 130
2024
-
[17]
Robert R McCrae and Oliver P John. 1992. An introduction to the five-factor model and its applications.Journal of personality60, 2 (1992), 175–215
1992
-
[18]
Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica22, 3 (2012), 276–282
2012
-
[19]
Shuyi Pan and Maartje MA De Graaf. 2025. Developing a social support frame- work: Understanding the reciprocity in human-chatbot relationship. InProceed- ings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–13
2025
- [20]
-
[21]
Yushan Qian, Weinan Zhang, and Ting Liu. 2023. Harnessing the power of large language models for empathetic response generation: Empirical investigations and improvements. InFindings of the Association for Computational Linguistics: EMNLP 2023. 6516–6528
2023
-
[22]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[23]
Hannah Rashkin, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. 2019. Towards empathetic open-domain conversation models: A new benchmark and dataset. InProceedings of the 57th annual meeting of the association for computa- tional linguistics. 5370–5381
2019
-
[24]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
2019
-
[25]
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2020. Mpnet: Masked and permuted pre-training for language understanding.Advances in neural information processing systems33 (2020), 16857–16867
2020
-
[26]
Xingyu Sui, Yanyan Zhao, Yulin Hu, Jiahe Guo, Weixiang Zhao, and Bing Qin
-
[27]
TEA-Bench: A Systematic Benchmarking of Tool-enhanced Emotional Support Dialogue Agent.arXiv preprint arXiv:2601.18700(2026)
work page internal anchor Pith review arXiv 2026
-
[28]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al . 2026. Kimi K2. 5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276(2026)
work page internal anchor Pith review arXiv 2026
-
[29]
Peggy A Thoits. 2011. Mechanisms linking social ties and support to physical and mental health.Journal of health and social behavior52, 2 (2011), 145–161
2011
-
[30]
Quan Tu, Yanran Li, Jianwei Cui, Bin Wang, Ji-Rong Wen, and Rui Yan. 2022. MISC: A mixed strategy-aware model integrating COMET for emotional support conversation. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: Long papers). 308–319
2022
-
[31]
United Nations, Department of Economic and Social Affairs, Population Division
-
[32]
https://population.un
World Population Prospects 2022, Online Edition. https://population.un. org/wpp/. Accessed: 2026-03-21
2022
-
[33]
Lanrui Wang, Jiangnan Li, Chenxu Yang, Zheng Lin, Hongyin Tang, Huan Liu, Yanan Cao, Jingang Wang, and Weiping Wang. 2025. Sibyl: Empowering empa- thetic dialogue generation in large language models via sensible and visionary commonsense inference. InProceedings of the 31st International Conference on Computational Linguistics. 123–140
2025
-
[34]
Qiancheng Xu, Yongqi Li, Heming Xia, Fan Liu, Min Yang, and Wenjie Li. 2025. Petoolllm: Towards personalized tool learning in large language models. In Findings of the Association for Computational Linguistics: ACL 2025. 21488–21503
2025
-
[35]
Yangyang Xu, Jinpeng Hu, Zhuoer Zhao, Zhangling Duan, Xiao Sun, and Xun Yang. 2025. Multiagentesc: A llm-based multi-agent collaboration framework for emotional support conversation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 4665–4681
2025
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [37]
-
[38]
Jiahao Yuan, Zixiang Di, Zhiqing Cui, Guisong Yang, and Usman Naseem. 2025. Reflectdiffu: Reflect between emotion-intent contagion and mimicry for empa- thetic response generation via a rl-diffusion framework. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 25435–25449
2025
-
[39]
Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muennighoff, et al. 2025. A survey on test-time scaling in large language models: What, how, where, and how well? arXiv preprint arXiv:2503.24235(2025)
work page internal anchor Pith review arXiv 2025
-
[40]
Tenggan Zhang, Xinjie Zhang, Jinming Zhao, Li Zhou, and Qin Jin. 2024. Escot: Towards interpretable emotional support dialogue systems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13395–13412
2024
-
[41]
Sticker Response
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623. ComPASS: Towards Personalized Agentic Social Support via Tool-Augmented Companionship ...
2023
-
[42]
(b) Overall average subjective score for each tool, obtained by averaging the model-wise mean scores shown in (a)
“N/A” indicates that the corresponding model does not use that tool. (b) Overall average subjective score for each tool, obtained by averaging the model-wise mean scores shown in (a). Figure 8: Tool-wise Performance Differences
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.