Recognition: unknown
Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes
Pith reviewed 2026-05-10 04:51 UTC · model grok-4.3
The pith
Small language models gain up to 5x sample efficiency in low-data RLVR when trained on mixed-complexity procedural data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
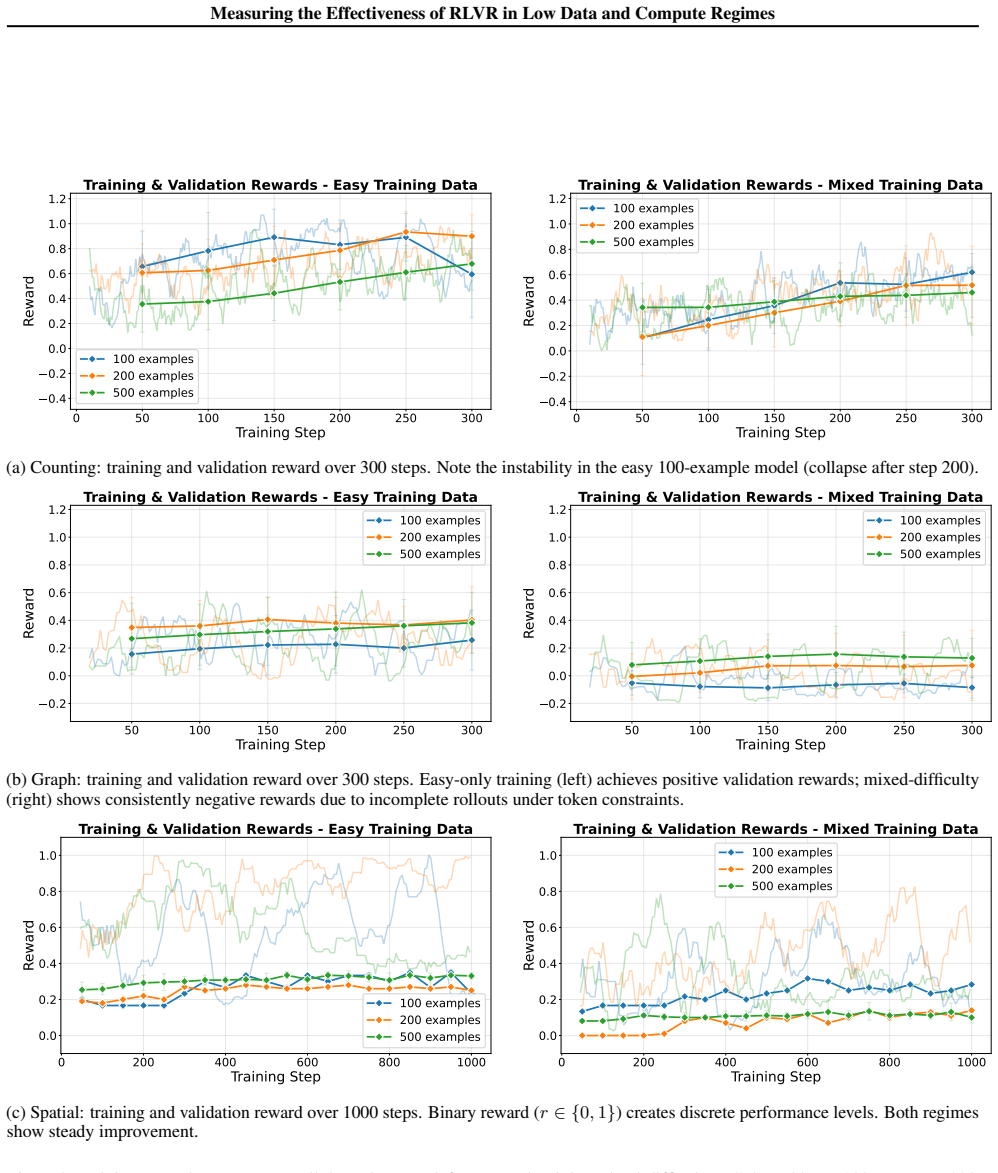
Using three new procedural datasets for number counting, graph reasoning, and spatial reasoning, the work shows that small language models trained via RLVR on mixed-complexity data achieve superior performance in low-data regimes compared to uniform complexity training. Specifically, low-complexity training generalizes to high-complexity evaluation, and mixed datasets provide up to 5x the sample efficiency of easy-only datasets. The use of procedurally generated data enables detailed control and analysis of how dataset size, diversity, and complexity influence fine-tuning outcomes across these tasks.
What carries the argument
Procedural data generators that produce reasoning tasks at adjustable complexity levels, allowing controlled measurement of how data composition affects RLVR outcomes in scarce-data conditions.
If this is right
- Models trained only on lower-complexity tasks can solve higher-complexity versions of the same problem types.
- Mixing task complexities during training maximizes performance per example more effectively than using only easy or only hard tasks.
- Procedural generation supplies a scalable route to diverse training data with known properties, reducing dependence on large human-annotated sets.
- These efficiency patterns appear consistently across counting, graph, and spatial reasoning, suggesting broader applicability to other controllable reasoning domains.
Where Pith is reading between the lines
- The same mixed-complexity strategy could be tested in supervised fine-tuning or other reward methods to stretch limited data budgets.
- Data curation pipelines for reasoning models might shift toward generating balanced difficulty distributions rather than maximizing average hardness.
- Validating the results on existing non-procedural benchmarks would clarify how much the controllable generation itself contributes to the observed gains.
- Extending the approach to larger models or additional diversity axes such as problem format could uncover further efficiency improvements.
Load-bearing premise
The three procedural datasets are representative enough of broader reasoning capabilities that the efficiency gains and easy-to-hard generalization will appear in other tasks or real data.
What would settle it
Run the same RLVR low-data protocol on a new domain such as arithmetic word problems and find neither the 5x efficiency advantage for mixed complexity nor generalization from low- to high-complexity test sets.
Figures





read the original abstract
Fine-tuning Large Language Models (LLMs) typically relies on large quantities of high-quality annotated data, or questions with well-defined ground truth answers in the case of Reinforcement Learning with Verifiable Rewards (RLVR). While previous work has explored the benefits to model reasoning capabilities by scaling both data and compute used for RLVR, these results lack applicability in many real-world settings where annotated data and accessible compute may be scarce. In this work, we present a comprehensive empirical study of open-source Small Language Model (SLM) performance after RLVR in low data regimes. Across three novel datasets covering number counting problems, graph reasoning, and spatial reasoning, we characterize how model performance scales with dataset size, diversity, and complexity. We demonstrate that (1) procedural datasets allow for fine-grained evaluation and training dataset development with controllable properties (size, diversity, and complexity), (2) under RLVR, models trained on lower complexity tasks can generalize to higher complexity tasks, and (3) training on mixed complexity datasets is associated with the greatest benefits in low data regimes, providing up to 5x sample efficiency versus training on easy tasks. These findings inspire future work on the development of data scaling laws for RLVR and the use of procedural data generators to further understand effective data development for efficient LLM fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a controlled empirical study of RLVR fine-tuning for small language models in low-data regimes. Using three novel procedural datasets (number counting, graph reasoning, spatial reasoning) with controllable size, diversity, and complexity, the authors characterize scaling behavior and report that (1) lower-complexity training generalizes to higher-complexity tasks and (2) mixed-complexity training yields the largest gains, including up to 5x sample efficiency relative to easy-only training.
Significance. If the empirical patterns hold beyond the specific generators, the work would supply practical guidance for data curation under compute and annotation constraints and support the development of data scaling laws for RLVR. The procedural generators are a clear methodological strength, enabling fine-grained ablation of size/diversity/complexity that is difficult with static benchmarks.
major comments (3)
- [Abstract and §4 (Results)] Abstract and §4 (Results): the central claims—mixed-complexity training providing up to 5x sample efficiency and low-to-high complexity generalization—are demonstrated exclusively on the three author-introduced procedural distributions. No transfer experiments or scaling curves are shown on established reasoning corpora (GSM8K, MATH, or code-generation suites), so it remains possible that the observed efficiency ordering is an artifact of how complexity is parameterized within each generator family.
- [§3 (Experimental Setup)] §3 (Experimental Setup): the manuscript does not report the number of random seeds, statistical significance tests, or confidence intervals for the 5x efficiency figure or the generalization results. Without these, it is impossible to determine whether the reported advantages are robust or sensitive to post-hoc dataset splits or hyperparameter choices.
- [§2 (Datasets)] §2 (Datasets): while the generators permit controllable complexity, the paper provides no external validation that the chosen complexity metrics (step count, graph statistics, spatial relations) align with LLM reasoning difficulty on out-of-distribution tasks. This weakens the claim that the observed transfer and efficiency patterns constitute a general principle for RLVR data design.
minor comments (2)
- [Abstract] Abstract: 'low data regimes' should be quantified (e.g., exact sample counts or token budgets) to allow direct comparison with prior RLVR scaling studies.
- [Figures] Figures: scaling plots should include error bars and explicit legends distinguishing mixed-, easy-, and hard-only conditions.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on our manuscript. We provide point-by-point responses to the major comments below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] Abstract and §4 (Results): the central claims—mixed-complexity training providing up to 5x sample efficiency and low-to-high complexity generalization—are demonstrated exclusively on the three author-introduced procedural distributions. No transfer experiments or scaling curves are shown on established reasoning corpora (GSM8K, MATH, or code-generation suites), so it remains possible that the observed efficiency ordering is an artifact of how complexity is parameterized within each generator family.
Authors: We appreciate the referee's concern regarding the generalizability of our findings. The procedural datasets were specifically designed to allow fine-grained control over complexity, diversity, and size, enabling us to rigorously test hypotheses about RLVR data curation that would be challenging with fixed benchmarks like GSM8K or MATH. Our results demonstrate consistent patterns across three distinct domains (counting, graphs, spatial), supporting the robustness of low-to-high complexity generalization and mixed-complexity benefits. While transfer to standard corpora is desirable, it is beyond the scope of this controlled study focused on low-data regimes. In the revised version, we will add a Limitations section explicitly discussing this scope and suggesting future work on transfer experiments. revision: partial
-
Referee: [§3 (Experimental Setup)] §3 (Experimental Setup): the manuscript does not report the number of random seeds, statistical significance tests, or confidence intervals for the 5x efficiency figure or the generalization results. Without these, it is impossible to determine whether the reported advantages are robust or sensitive to post-hoc dataset splits or hyperparameter choices.
Authors: We agree that reporting statistical details is essential for assessing robustness. We will update §3 (Experimental Setup) and the results in §4 to specify the number of random seeds (we used 3 seeds for all experiments), include error bars or confidence intervals in figures, and perform statistical significance tests (paired t-tests) for the key efficiency comparisons. This will be incorporated in the revised manuscript. revision: yes
-
Referee: [§2 (Datasets)] §2 (Datasets): while the generators permit controllable complexity, the paper provides no external validation that the chosen complexity metrics (step count, graph statistics, spatial relations) align with LLM reasoning difficulty on out-of-distribution tasks. This weakens the claim that the observed transfer and efficiency patterns constitute a general principle for RLVR data design.
Authors: The complexity metrics were chosen based on established notions of reasoning difficulty in the literature (e.g., number of operations or structural complexity). To address this, we will revise §2 to provide more justification for these metrics, including references to prior work on reasoning complexity, and include an additional analysis showing correlation between our complexity levels and model performance on the procedural tasks themselves. We believe this supports the patterns as indicative of general principles, though we acknowledge broader validation would be beneficial. revision: partial
Circularity Check
No circularity: purely empirical measurements on synthetic datasets
full rationale
The paper reports direct experimental results from RLVR fine-tuning of SLMs on three author-generated procedural datasets (number counting, graph reasoning, spatial reasoning). All reported findings—scaling with data size/diversity/complexity, generalization from low- to high-complexity tasks, and up to 5x sample efficiency for mixed-complexity training—are measured performance numbers, not derived predictions or first-principles results. No equations, ansatzes, uniqueness theorems, or self-citations are invoked to define or force the central claims; the work contains no load-bearing derivations that reduce to their own inputs by construction. The study is self-contained against its own benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption RLVR with verifiable rewards produces measurable improvements in reasoning on the chosen tasks
- domain assumption Procedural generation yields datasets whose size, diversity, and complexity can be independently controlled without introducing unintended biases
Reference graph
Works this paper leans on
-
[1]
Avail- able at: https://assets.anthropic. com/m/12f214efcc2f457a/original/ Claude-Sonnet-4-5-System-Card.pdf. Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agen...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2503.16219
Dang, Q.-A. and Ngo, C. Reinforcement learning for reason- ing in small llms: What works and what doesn’t.arXiv preprint arXiv:2503.16219,
-
[3]
Automat- ing benchmark design.arXiv preprint arXiv:2510.25039,
Dsouza, A., Vishwakarma, H., Qi, Z., Bauer, J., Pham, D., Walshe, T., Parchami, A., Sala, F., and Varma, P. Automat- ing benchmark design.arXiv preprint arXiv:2510.25039,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2504.11456 , year=
He, Z., Liang, T., Xu, J., Liu, Q., Chen, X., Wang, Y ., Song, L., Yu, D., Liang, Z., Wang, W., et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456,
-
[6]
Training Compute-Optimal Large Language Models
Measuring the Effectiveness of RLVR in Low Data and Compute Regimes Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Rae, J. W., Vinyals, O., an...
work page internal anchor Pith review arXiv
-
[7]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[8]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
Khatri, D., Madaan, L., Tiwari, R., Bansal, R., Duvvuri, S. S., Zaheer, M., Dhillon, I. S., Brandfonbrener, D., and Agarwal, R. The art of scaling reinforcement learn- ing compute for llms.arXiv preprint arXiv:2510.13786,
-
[9]
Limr: Less is more for rl scaling.arXiv preprint arXiv:2502.11886, 2025
Li, X., Zou, H., and Liu, P. Limr: Less is more for rl scaling. arXiv preprint arXiv:2502.11886,
-
[10]
Liu, X., Liang, T., He, Z., Xu, J., Wang, W., He, P., Tu, Z., Mi, H., and Yu, D. Trust, but verify: A self-verification ap- proach to reinforcement learning with verifiable rewards. arXiv preprint arXiv:2505.13445,
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
doi: 10.64434/tml. 20250929. https://thinkingmachines.ai/blog/lora/. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseek- math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.64434/tml
-
[12]
Exploring data scaling trends and effects in reinforcement learning from human feedback
Shen, W., Liu, G., Wu, Z., Zhu, R., Yang, Q., Xin, C., Yue, Y ., and Yan, L. Exploring data scaling trends and effects in reinforcement learning from human feedback.arXiv preprint arXiv:2503.22230,
-
[13]
Tan, Z., Geng, H., Yu, X., Zhang, M., Wan, G., Zhou, Y ., He, Q., Xue, X., Zhou, H., Fan, Y ., Li, Z., Zhang, Z., Zhang, G., Zhang, C., Yin, Z., Torr, P., and Bai, L. Scaling behaviors of llm reinforcement learning post-training: An empirical study in mathematical reasoning.arXiv preprint arXiv:2509.25300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Tina: Tiny reasoning models via LoRA.arXiv preprint arXiv:2504.15777, 2025b
Wang, S., Asilis, J., Akg¨ul, ¨O. F., Bilgin, E. B., Liu, O., and Neiswanger, W. Tina: Tiny reasoning models via lora. arXiv preprint arXiv:2504.15777, 2025a. Wang, Y ., Yang, Q., Zeng, Z., Ren, L., Liu, L., Peng, B., Cheng, H., He, X., Wang, K., Gao, J., et al. Reinforce- ment learning for reasoning in large language models with one training example.arXi...
-
[15]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Zeng, A., Lv, X., Zheng, Q., Hou, Z., Chen, B., Xie, C., Wang, C., Yin, D., Zeng, H., Zhang, J., et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471,
work page internal anchor Pith review arXiv
-
[17]
Zhang, B., Liu, Z., Cherry, C., and Firat, O. When scaling meets LLM finetuning: The effect of data, model and finetuning method.arXiv preprint arXiv:2402.17193, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.