Recognition: unknown
OpenGame: Open Agentic Coding for Games
Pith reviewed 2026-05-10 04:08 UTC · model grok-4.3
The pith
OpenGame uses reusable template and debug skills plus a specialized code model to generate fully playable web games from text prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
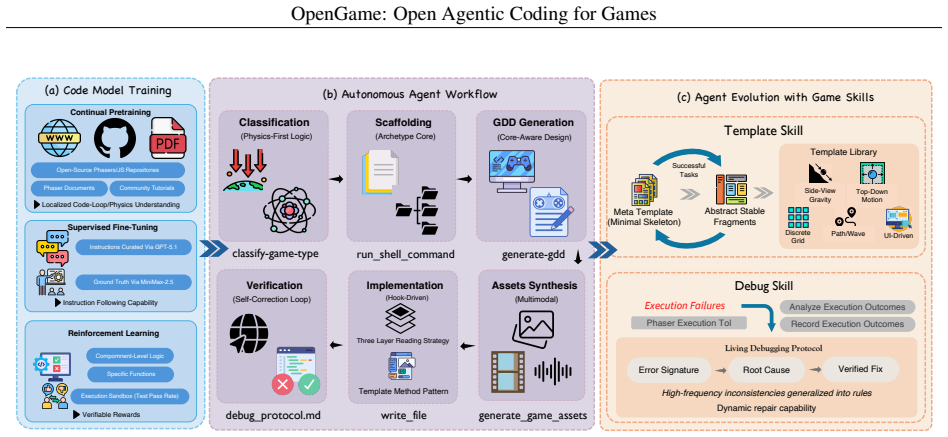
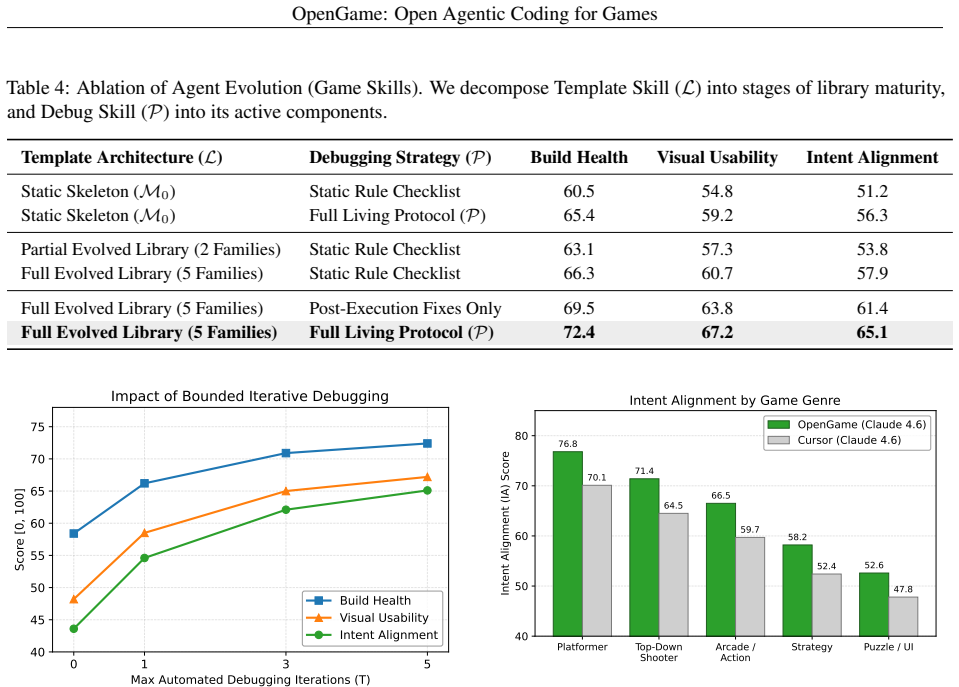
OpenGame is the first open-source agentic framework for end-to-end web game creation. Its core is Game Skill, a reusable capability built from a Template Skill that grows a library of project skeletons from experience and a Debug Skill that maintains a living protocol of verified fixes, together enabling stable architectures and systematic repair of integration errors. This is powered by GameCoder-27B, a 27B code LLM trained in three stages of continual pre-training, supervised fine-tuning, and execution-grounded reinforcement learning. The framework is evaluated with OpenGame-Bench, which measures Build Health, Visual Usability, and Intent Alignment via headless browser runs and VLM judging
What carries the argument
Game Skill, composed of Template Skill for evolving project skeletons and Debug Skill for maintaining protocols of verified fixes, powered by GameCoder-27B through continual pre-training, supervised fine-tuning, and execution-grounded reinforcement learning.
If this is right
- Agentic code systems can now produce complete, playable multi-file projects instead of breaking on cross-file inconsistencies.
- Evaluating interactive applications requires running them in headless browsers and judging output with vision-language models rather than static code checks.
- Specialized three-stage training with execution feedback improves reliability on tightly coupled real-time systems like games.
- Reusable skill libraries that grow from experience can help maintain architectural consistency across successive generations of code.
Where Pith is reading between the lines
- The same template-plus-debug pattern could apply to other domains that demand consistent state across many files, such as web apps or simulations.
- If the debug skill generalizes beyond games, it may lower the amount of human debugging needed for large agent-generated codebases.
- Open-sourcing the framework and benchmark invites community extensions to new game engines or additional interactive application types.
Load-bearing premise
That the combination of Template Skill, Debug Skill, and execution-grounded reinforcement learning on GameCoder-27B can systematically resolve integration errors and logical incoherence in multi-file game projects rather than merely patching syntax.
What would settle it
Running the 150 generated games in a real browser and checking whether they execute without crashes, maintain consistent visuals and logic, and match the prompt intent according to the Build Health, Visual Usability, and Intent Alignment scores.
Figures

read the original abstract
Game development sits at the intersection of creative design and intricate software engineering, demanding the joint orchestration of game engines, real-time loops, and tightly coupled state across many files. While Large Language Models (LLMs) and code agents now solve isolated programming tasks with ease, they consistently stumble when asked to produce a fully playable game from a high-level design, collapsing under cross-file inconsistencies, broken scene wiring, and logical incoherence. We bridge this gap with OpenGame, the first open-source agentic framework explicitly designed for end-to-end web game creation. At its core lies Game Skill, a reusable, evolving capability composed of a Template Skill that grows a library of project skeletons from experience and a Debug Skill that maintains a living protocol of verified fixes - together enabling the agent to scaffold stable architectures and systematically repair integration errors rather than patch isolated syntax bugs. Powering this framework is GameCoder-27B, a code LLM specialized for game engine mastery through a three-stage pipeline of continual pre-training, supervised fine-tuning, and execution-grounded reinforcement learning. Since verifying interactive playability is fundamentally harder than checking static code, we further introduce OpenGame-Bench, an evaluation pipeline that scores agentic game generation along Build Health, Visual Usability, and Intent Alignment via headless browser execution and VLM judging. Across 150 diverse game prompts, OpenGame establishes a new state-of-the-art. We hope OpenGame pushes code agents beyond discrete software engineering problems and toward building complex, interactive real-world applications. Our framework will be fully open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OpenGame, an open-source agentic framework for generating fully playable web games from high-level natural language prompts. Its core contribution is the Game Skill, which combines a Template Skill (for evolving project skeletons) and a Debug Skill (for maintaining verified fix protocols) to scaffold architectures and repair cross-file integration errors. This is powered by GameCoder-27B, a 27B-parameter code LLM trained via continual pre-training, supervised fine-tuning, and execution-grounded reinforcement learning. The authors also present OpenGame-Bench, an evaluation pipeline that assesses Build Health through headless browser execution alongside Visual Usability and Intent Alignment via VLM judging. They report state-of-the-art results across 150 diverse game prompts, claiming that prior LLMs collapse on multi-file inconsistencies while OpenGame produces end-to-end playable games.
Significance. If the central claims hold, the work would be a meaningful step forward in agentic coding for complex, interactive systems. Demonstrating reliable handling of cross-file state, scene wiring, and logical coherence in game engines goes beyond isolated code tasks and could influence broader efforts in building real-world applications with LLMs. The open release of the framework, specialized model, and benchmark would provide concrete resources for the community, particularly if the execution-grounded RL and evolving skills prove reproducible.
major comments (3)
- [OpenGame-Bench] OpenGame-Bench section: the evaluation delegates Visual Usability and Intent Alignment to VLM judging while using headless execution only for Build Health. This setup risks missing persistent cross-file logical incoherence (e.g., mismatched state desynchronization or scene wiring errors) that manifest only during interactive play rather than static or visual inspection, directly weakening the claim that the Template + Debug Skill pipeline systematically resolves integration errors instead of patching surface issues.
- [Results] Results and experimental setup: the SOTA claim on 150 prompts lacks reported baselines (including whether prior models received equivalent skills or RL stages), error bars, data splits, or handling of post-hoc fixes. Without these, it is unclear whether the reported gains reflect genuine advances in repair capability or differences in evaluation protocol.
- [GameCoder-27B] GameCoder-27B training pipeline: the three-stage process (continual pre-training, SFT, execution-grounded RL) is described at a high level, but no ablation results or quantitative metrics per stage are provided to show that the RL component specifically improves resolution of multi-file inconsistencies over the base model.
minor comments (2)
- [Introduction] The abstract and introduction use the term 'Game Skill' without an early formal definition or diagram showing how Template Skill and Debug Skill interact during agent execution.
- [Game Skill] Notation for the evolving library of project skeletons and the 'living protocol' of fixes is introduced informally; a small table or pseudocode example would clarify the data structures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating revisions where the manuscript will be updated to improve clarity and rigor.
read point-by-point responses
-
Referee: [OpenGame-Bench] OpenGame-Bench section: the evaluation delegates Visual Usability and Intent Alignment to VLM judging while using headless execution only for Build Health. This setup risks missing persistent cross-file logical incoherence (e.g., mismatched state desynchronization or scene wiring errors) that manifest only during interactive play rather than static or visual inspection, directly weakening the claim that the Template + Debug Skill pipeline systematically resolves integration errors instead of patching surface issues.
Authors: We acknowledge that headless browser execution primarily surfaces runtime errors and crashes, while VLM-based judging evaluates static and dynamic visual frames; neither fully substitutes for extended interactive playtesting that could reveal subtle state desynchronization. The Debug Skill protocol is grounded in repeated execution feedback to target integration errors, but we agree the current pipeline does not exhaustively rule out all latent logical issues. In revision we will add an explicit limitations paragraph in the OpenGame-Bench section discussing this gap and outlining planned extensions to interactive testing harnesses. revision: partial
-
Referee: [Results] Results and experimental setup: the SOTA claim on 150 prompts lacks reported baselines (including whether prior models received equivalent skills or RL stages), error bars, data splits, or handling of post-hoc fixes. Without these, it is unclear whether the reported gains reflect genuine advances in repair capability or differences in evaluation protocol.
Authors: The 150-prompt evaluation applies the identical OpenGame-Bench protocol to both our system and prior LLMs/code agents; the baselines therefore do not receive the Game Skill framework or GameCoder-27B, which constitute the core contributions. We will revise the experimental section to (i) explicitly tabulate baseline configurations, (ii) report standard deviations across repeated runs, (iii) describe the prompt selection and split procedure, and (iv) confirm that all reported outcomes derive from fully autonomous agent trajectories without manual post-processing. revision: yes
-
Referee: [GameCoder-27B] GameCoder-27B training pipeline: the three-stage process (continual pre-training, SFT, execution-grounded RL) is described at a high level, but no ablation results or quantitative metrics per stage are provided to show that the RL component specifically improves resolution of multi-file inconsistencies over the base model.
Authors: We will expand the GameCoder-27B section with available per-stage quantitative metrics (perplexity reduction after continual pre-training, pass@1 improvements after SFT, and reward curves from the execution-grounded RL phase). Comprehensive ablations that isolate the RL stage’s contribution specifically to multi-file inconsistency resolution are not present in the current manuscript; we will note this limitation and flag it as future work. revision: partial
Circularity Check
No significant circularity; new framework, model, and benchmark are independent contributions
full rationale
The paper's central claims rest on the introduction of OpenGame (with its Template Skill and Debug Skill), the GameCoder-27B three-stage training pipeline, and the new OpenGame-Bench evaluation pipeline, followed by empirical results on 150 diverse prompts. No load-bearing self-citations appear in the provided text, no predictions or results reduce by construction to fitted inputs or prior self-referential definitions, and the evaluation metrics (headless execution plus VLM judging) are presented as newly defined rather than tautological. The derivation chain is self-contained empirical work on novel artifacts.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be specialized for game engines via continual pre-training, SFT, and execution-grounded RL
- domain assumption Headless browser execution plus VLM judging can reliably score interactive playability
invented entities (2)
-
Game Skill
no independent evidence
-
GameCoder-27B
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, 2024
Carlos E Jimenez, John Murphy, Arian Kowalczyk, Prem Mudigonda, et al. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, 2024
2024
-
[2]
Devin: The first ai software engineer
Cognition AI. Devin: The first ai software engineer. https://www.cognition-labs.com/introducing-devin, 2024
2024
-
[3]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024
2024
-
[4]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Luan, et al. Swe-agent: Agent-computer interfaces enable automated software engineering.arXiv preprint arXiv:2405.15793, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M ˛ adry. Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025
2025
-
[6]
Merrill, Alexander G
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
2026
-
[7]
Jimenez, Ofir Press, Ludwig Schmidt, and Diyi Yang
John Yang, Kilian Lieret, Joyce Yang, Carlos E. Jimenez, Ofir Press, Ludwig Schmidt, and Diyi Yang. Codeclash: Benchmarking goal-oriented software engineering, 2025
2025
-
[8]
Hongda Zhu, Yiwen Zhang, Bing Zhao, Jingzhe Ding, Siyao Liu, Tong Liu, Dandan Wang, Yanan Liu, and Zhaojian Li. Frontendbench: A benchmark for evaluating llms on front-end development via automatic evaluation.ArXiv, abs/2506.13832, 2025
-
[9]
arXiv:2403.03163 [cs.CL] https://arxiv.org/abs/2403
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: How far are we from automating front-end engineering?ArXiv, abs/2403.03163, 2024
-
[10]
Jimenez, Alex L
John Yang, Carlos E. Jimenez, Alex L. Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R. Narasimhan, Diyi Yang, Sida I. Wang, and Ofir Press. Swe-bench multimodal: Do ai systems generalize to visual software domains?, 2024
2024
-
[11]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
2024
-
[12]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024
2024
-
[13]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks, 2024
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks, 2024
2024
-
[14]
Gamedevbench: Evaluating agentic capabilities through game development, 2026
Wayne Chi, Yixiong Fang, Arnav Yayavaram, Siddharth Yayavaram, Seth Karten, Qiuhong Anna Wei, Runkun Chen, Alexander Wang, Valerie Chen, Ameet Talwalkar, and Chris Donahue. Gamedevbench: Evaluating agentic capabilities through game development, 2026. 11 OpenGame: Open Agentic Coding for Games
2026
-
[15]
Large language models and games: A survey and roadmap.IEEE Transactions on Games, 2024
Roberto Gallotta, Graham Todd, Marvin Zammit, Sam Earle, Antonios Liapis, Julian Togelius, and Georgios N Yannakakis. Large language models and games: A survey and roadmap.IEEE Transactions on Games, 2024
2024
-
[16]
Deep blue.Artificial intelligence, 134(1-2):57–83, 2002
Murray Campbell, A Joseph Hoane Jr, and Feng-hsiung Hsu. Deep blue.Artificial intelligence, 134(1-2):57–83, 2002
2002
-
[17]
Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
2016
-
[18]
Human-level play in the game of diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022
Meta Fundamental AI Research Diplomacy Team (FAIR)†, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, et al. Human-level play in the game of diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022
2022
-
[19]
Sawyer, Daniel Slater, David Reichert, Davide Vercelli, Demis Hassabis, Drew A
Adrian Bolton, Alexander Lerchner, Alexandra Cordell, Alexandre Moufarek, Andrew Bolt, Andrew Lampinen, Anna Mitenkova, Arne Olav Hallingstad, Bojan Vujatovic, Bonnie Li, et al. Sima 2: A generalist embodied agent for virtual worlds. arXiv preprint arXiv:2512.04797, 2025
-
[20]
The pokeagent challenge: Competitive and long-context learning at scale.NeurIPS Competition Track, 2025
Seth Karten, Jake Grigsby, Stephanie Milani, Kiran V odrahalli, Amy Zhang, Fei Fang, Yuke Zhu, and Chi Jin. The pokeagent challenge: Competitive and long-context learning at scale.NeurIPS Competition Track, 2025
2025
- [21]
-
[22]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Beating the world record in pokémon emerald: An AI agent case study
Nunu AI. Beating the world record in pokémon emerald: An AI agent case study. https://nunu.ai/case-studies/ pokemon-emerald, 2024
2024
-
[24]
Hoover, Aaron Isaksen, Andy Nealen, and Julian Togelius
Adam Summerville, Sam Snodgrass, Matthew Guzdial, Christoffer Holmgård, Amy K. Hoover, Aaron Isaksen, Andy Nealen, and Julian Togelius. Procedural content generation via machine learning (pcgml), 2018
2018
-
[25]
Procedural content generation in games
Noor Shaker, Julian Togelius, and Mark J Nelson. Procedural content generation in games. 2016
2016
-
[26]
Mariogpt: Open-ended text2level generation through large language models, 2023
Shyam Sudhakaran, Miguel González-Duque, Claire Glanois, Matthias Freiberger, Elias Najarro, and Sebastian Risi. Mariogpt: Open-ended text2level generation through large language models, 2023
2023
-
[27]
Agapiou, Avia Aharon, Ron Ziv, Jayd Matyas, Edgar A
Alexander Sasha Vezhnevets, John P Agapiou, Avia Aharon, Ron Ziv, Jayd Matyas, Edgar A Duéñez-Guzmán, William A Cunningham, Simon Osindero, Danny Karmon, and Joel Z Leibo. Generative agent-based modeling with actions grounded in physical, social, or digital space using concordia.arXiv preprint arXiv:2312.03664, 2023
-
[28]
Alexander Sasha Vezhnevets, Jayd Matyas, Logan Cross, Davide Paglieri, Minsuk Chang, William A Cunningham, Simon Osindero, William S Isaac, and Joel Z Leibo. Multi-actor generative artificial intelligence as a game engine.arXiv preprint arXiv:2507.08892, 2025
-
[29]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[30]
Unreal engine.https://www.unrealengine.com, 1998
Epic Games. Unreal engine.https://www.unrealengine.com, 1998
1998
-
[31]
Unity game engine.https://unity.com, 2005
Unity Technologies. Unity game engine.https://unity.com, 2005
2005
-
[32]
Phaser - a fast, fun and free open source html5 game framework
Richard Davey and Photon Storm. Phaser - a fast, fun and free open source html5 game framework. https://phaser.io, 2013
2013
-
[33]
Qwen3.5-Max: Scaling open foundation models
Qwen Team. Qwen3.5-Max: Scaling open foundation models. https://qwenlm.github.io/blog/qwen3-max/,
-
[34]
Accessed: 2026-04-20
2026
-
[35]
MiniMax-M2.5 technical report.https://www.minimaxi.com/, 2025
MiniMax. MiniMax-M2.5 technical report.https://www.minimaxi.com/, 2025. Accessed: 2026-04-20
2025
-
[36]
GLM-4.5: Advancing open bilingual foundation models
Zhipu AI. GLM-4.5: Advancing open bilingual foundation models. https://z.ai/blog/glm-4.5, 2025. Accessed: 2026-04-20
2025
-
[37]
Kimi K2.5 technical report
Moonshot AI. Kimi K2.5 technical report. https://moonshotai.github.io/Kimi-K2/, 2025. Accessed: 2026-04- 20
2025
-
[38]
DeepSeek-V3.2: Advancing open-source language models
DeepSeek-AI. DeepSeek-V3.2: Advancing open-source language models. https://www.deepseek.com/, 2025. Accessed: 2026-04-20
2025
-
[39]
Claude Sonnet 4.6.https://www.anthropic.com/claude, 2025
Anthropic. Claude Sonnet 4.6.https://www.anthropic.com/claude, 2025. Accessed: 2026-04-20
2025
-
[40]
GPT-5.1.https://openai.com/index/gpt-5-1/, 2025
OpenAI. GPT-5.1.https://openai.com/index/gpt-5-1/, 2025. Accessed: 2026-04-20
2025
-
[41]
Gemini 3.1 Pro
Google DeepMind. Gemini 3.1 Pro. https://deepmind.google/technologies/gemini/, 2025. Accessed: 2026-04-20
2025
-
[42]
Qwen Code: A command-line ai workflow tool for agentic coding
Qwen Team. Qwen Code: A command-line ai workflow tool for agentic coding. https://github.com/QwenLM/ qwen-code, 2025. Accessed: 2026-04-20
2025
-
[43]
Cursor: The ai code editor.https://www.cursor.com, 2024
Anysphere. Cursor: The ai code editor.https://www.cursor.com, 2024. Accessed: 2026-04-20. 12 OpenGame: Open Agentic Coding for Games A System Prompt Specifications This appendix presents the prompt specifications used in the OpenGame agent framework, reproduced from the source files used during evaluation. A.1 Main System Prompt The main system prompt is ...
2024
-
[44]
Classification & Scaffolding— invoke classify-game-type and copy the corresponding template family into the workspace
-
[45]
Game Design— generate a technical GDD via generate-gdd, then expand per-file todos from GDD Section 5
-
[46]
Asset Synthesis— call generate-game-assets and generate-tilemap based on the GDD asset registry and ASCII maps
-
[47]
Config & Registration— merge gameConfig.json and register all scenes in main.ts / LevelManager.ts
-
[48]
Code Implementation— three-layer reading strategy (API summary → targeted source → implementation guide), followed by hook-based coding against template files
-
[49]
Verification— static self-review checklist from debug_protocol.md, then npm run build , npm run test, andnpm run dev. A.2 Game Classification Tool Prompt This tool classifies a user’s game idea into one of five archetypes usingPhysics-First Logic(gravity, perspective, and movement type) rather than genre names. It calls an external LLM (DeepSeek-v3.2 by d...
-
[50]
Tool Description— the one-line capability summary and parameter list exposed to the agent as a tool manifest entry
-
[51]
System Prompt— classification rules for five archetypes (platformer,top_down,grid_logic,tower_defense, ui_heavy), each with a key discriminating question, physics profile, and common-mistake warnings
-
[52]
A.3 GDD Generation Tool Prompt This tool generates a technical game Design Document (GDD) tailored to a specific archetype
User Prompt— the runtime template that wraps the user’s game description and requests a JSON-only response. A.3 GDD Generation Tool Prompt This tool generates a technical game Design Document (GDD) tailored to a specific archetype. The system prompt is dynamically assembled from a fixed header plus three documents loaded from disk: docs/gdd/core.md (unive...
-
[53]
Tool Description— function signature and required parameters ( raw_user_requirement, archetype)
-
[54]
System Prompt – Fixed Header— instructs the model to act as a game design engineer and enforces four core rules: user-faithful, config-first, zero custom code, and hook integrity
-
[55]
User Prompt— runtime template requesting a 6-section Technical GDD with archetype-specific guidance injected at call time
-
[56]
Section 1 Asset Guidance – Platformer— side-view animation frames, tileset grid format, and audio SFX list
-
[57]
Section 1 Asset Guidance – UI Heavy— front-view bust shots, per-expression image naming, and UI audio conventions
-
[58]
Section 1 Asset Guidance – Top-Down— directional animation triplets and tilemap-vs-arena sub-mode rules
-
[59]
13 OpenGame: Open Agentic Coding for Games
Section 1 Asset Guidance – Grid Logic— strict type:"image" parameter constraints and background overlay model. 13 OpenGame: Open Agentic Coding for Games
-
[60]
A.4 Todo List Tool Prompt This tool creates and manages a structured task list for the agent’s coding session, enabling real-time progress tracking across multi-phase workflows
Section 1 Asset Guidance – Tower Defense— tower, enemy, projectile, and icon asset conventions with correct JSON examples. A.4 Todo List Tool Prompt This tool creates and manages a structured task list for the agent’s coding session, enabling real-time progress tracking across multi-phase workflows. Parameters: todos array of items with id, content, and s...
-
[61]
A.5 Asset Generation Tool Prompts This tool generates game assets (images, animations, audio, tilesets, backgrounds) using AI vision and audio models (Tongyi / Doubao backends)
Full Tool Prompt— comprehensive guidance on when to use the todo list (3+ step tasks, multi-file refactors, game development pipelines), worked examples of both correct and incorrect usage, and task state management rules (one in-progress at a time; mark complete immediately upon finishing). A.5 Asset Generation Tool Prompts This tool generates game asset...
-
[62]
Background Generation— full-scene, edge-to-edge illustration prompt; explicitly forbids characters, UI elements, and transparency
-
[63]
Image (Sprite) Generation— single isolated object on a pure white background with centered composition
-
[64]
Animation Base Image— side-view chibi character in neutral idle pose; used as the seed frame for the I2V pipeline
-
[65]
Animation Frame – I2V (Image-to-Video)— motion description for the image-to-video model; enforces consistent side-view framing and identical character size across frames
-
[66]
Animation Frame – I2I (Image-to-Image)— per-frame prompt with frame index and total count for the image-to-image pipeline
-
[67]
Tileset Generation— 3 ×3 seamless tileset with strict row/column layout, zero gaps, full 1024×1024 canvas coverage, and forbidden elements list. A.6 Audio Generation Prompts (ABC Notation) The audio generation pipeline uses a two-step process: (1) generate ABC music notation via LLM, then (2) convert the ABC notation to W A V using symusic/Python. The com...
-
[68]
ABC System Prompt— mandatory header fields ( X:, T:, M:, L:, Q:, K:), note-length and rest syntax reference, and a valid two-part example; instructs the model to produce loop-friendly game music with actual note sequences (not placeholders)
-
[69]
#"]), mode (
ABC Generation Prompt (User Message)— runtime template specifying duration, audio type (BGM/SFX), genre, tempo, and description; requests a JSON response withnotation and comments fields and provides good/bad notation examples. A.7 Tilemap Generation Tool This is apurely algorithmictool with no LLM prompts. It converts ASCII map layouts into Phaser Tilema...
-
[70]
15 OpenGame: Open Agentic Coding for Games B Prompt Appendix Pages You are a game coding agent specializing in 2D game development tasks
Platformer Rules (Built-in)— physics settings (Y-axis gravity, side view), available behaviors (PlatformerMovement, MeleeAttack, RangedAttack, PatrolAI, ChaseAI), nine ultimate skill types, ASCII level design legend with placement constraints, and the canonical gameConfig.json schema using the{ "value": X }wrapper format. 15 OpenGame: Open Agentic Coding ...
-
[71]
**Classify**: Call `classify-game-type` tool with user 's game idea. Uses **Physics-First Logic** (not genre names): | Module | Physics | Key Question | Examples | |--------|---------|--------------|----------| | `platformer` | Side + Gravity | Does character FALL? | Mario, Terraria, Street Fighter | | `top_down` | Top-Down + Free | Can move UP without ju...
-
[72]
Do NOT read any source files yet** -- template code is only read in Phase 5
**Scaffold**: Use `run_shell_command` to copy templates and docs (FOUR steps, in order): ```bash # Step 1: Copy core template (creates src/, public/, config files) cp -r {TEMPLATES_DIR}/core/* ./ # Step 2: Copy module-specific code INTO src/ (ADDITIVE merge) cp -r {TEMPLATES_DIR}/modules/{archetype}/src/* ./src/ # Step 3: Copy core documentation mkdir -p ...
-
[73]
**Call `generate-gdd`** with: - `raw_user_requirement`: User 's game idea - `archetype`: From Phase 1 classification (REQUIRED) The tool auto-loads three documents: - `{DOCS_DIR}/gdd/core.md` -- universal GDD format - `{DOCS_DIR}/modules/{archetype}/design_rules.md` -- game design guide (gameplay, flow, feel) - `{DOCS_DIR}/modules/{archetype}/template_api...
-
[74]
**Save GDD** to `GAME_DESIGN.md` using `write_file` tool
-
[75]
archetype
**Expand todos NOW**: GDD exists -- replace the IMPLEMENT placeholder with **specific per-file todos** from GDD Section 5 (each todo = `COPY`/`UPDATE`/`CREATE`/`MERGE` + GDD section reference). Ensure READ and VERIFY phases are still present. ↪→ ↪→ The GDD has 6 sections. Each section feeds a specific downstream step: - **Section 0** (Architecture) -> Pha...
-
[76]
Do not invent unasked features
**User-Faithful**: Fulfill stated requirements. Do not invent unasked features
-
[77]
**Config-First**: Numeric values go in `gameConfig.json` using `{ "value": X } ` wrapper
-
[78]
**Zero Custom Code**: Use existing behaviors/hooks from template_api.md only
-
[79]
animation
**Hook Integrity**: Every hook name MUST exist in template_api.md. Non-existent hooks cause compilation failure.↪→ **User's Game Idea**: {raw_user_requirement} **Archetype**: {archetype} Generate a Technical GDD with **6 sections** (Section 0-5) following the structure defined in the GDD Core Rules above. Be specific -- the coding agent should never need ...
-
[80]
Complex multi-step tasks - When a task requires 3 or more distinct steps or actions
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.