Recognition: unknown
BhashaSutra: A Task-Centric Unified Survey of Indian NLP Datasets, Corpora, and Resources
Pith reviewed 2026-05-10 04:18 UTC · model grok-4.3
The pith
The first unified survey catalogs over 200 Indian NLP datasets, 50 benchmarks, and 100 models across languages and tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the first unified survey of Indian NLP resources, covering 200+ datasets, 50+ benchmarks, and 100+ models, tools, and systems across text, speech, multimodal, and culturally grounded tasks. We organize resources by linguistic phenomena, domains, and modalities; analyze trends in annotation, evaluation, and model design; and identify persistent challenges such as data sparsity, uneven language coverage, script diversity, and limited cultural and domain generalization.
What carries the argument
The task-centric unified survey framework that groups resources by linguistic phenomena, domains, and modalities while tracking annotation trends and evaluation practices.
Load-bearing premise
The authors have identified and accurately categorized nearly all relevant Indian NLP resources without major omissions, selection bias, or outdated entries.
What would settle it
A systematic search that locates a large number of Indian-language NLP datasets, benchmarks, or models absent from the survey's 200+ and 50+ counts would show the coverage claim is incomplete.
Figures














read the original abstract
India's linguistic landscape, spanning 22 scheduled languages and hundreds of marginalized dialects, has driven rapid growth in NLP datasets, benchmarks, and pretrained models. However, no dedicated survey consolidates resources developed specifically for Indian languages. Existing reviews either focus on a few high-resource languages or subsume Indian languages within broader multilingual settings, limiting coverage of low-resource and culturally diverse varieties. To address this gap, we present the first unified survey of Indian NLP resources, covering 200+ datasets, 50+ benchmarks, and 100+ models, tools, and systems across text, speech, multimodal, and culturally grounded tasks. We organize resources by linguistic phenomena, domains, and modalities; analyze trends in annotation, evaluation, and model design; and identify persistent challenges such as data sparsity, uneven language coverage, script diversity, and limited cultural and domain generalization. This survey offers a consolidated foundation for equitable, culturally grounded, and scalable NLP research in the Indian linguistic ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BhashaSutra as the first unified survey of Indian NLP resources. It claims to cover 200+ datasets, 50+ benchmarks, and 100+ models, tools, and systems across text, speech, multimodal, and culturally grounded tasks for India's 22 scheduled languages and dialects. The resources are organized by linguistic phenomena, domains, and modalities, with analysis of trends in annotation, evaluation, and model design, and discussion of challenges including data sparsity, uneven language coverage, script diversity, and limited cultural and domain generalization.
Significance. If the enumeration proves accurate and exhaustive, this survey would provide a valuable consolidated reference for NLP research on low-resource Indian languages, which are frequently subsumed or overlooked in broader multilingual reviews. The task-centric organization and explicit identification of challenges such as script diversity and cultural generalization represent clear strengths that could guide future equitable and scalable work in the field.
major comments (1)
- Abstract: The abstract states the scope and coverage numbers (200+ datasets, 50+ benchmarks, 100+ models) but provides no details on literature search methodology, inclusion criteria, verification process, or handling of duplicates and updates. This omission is load-bearing for the central claim of comprehensive, unbiased coverage and prevents assessment of completeness or selection bias.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive assessment of the survey's value for Indian NLP research. We address the single major comment point by point below.
read point-by-point responses
-
Referee: Abstract: The abstract states the scope and coverage numbers (200+ datasets, 50+ benchmarks, 100+ models) but provides no details on literature search methodology, inclusion criteria, verification process, or handling of duplicates and updates. This omission is load-bearing for the central claim of comprehensive, unbiased coverage and prevents assessment of completeness or selection bias.
Authors: We agree that the abstract would be strengthened by briefly indicating the literature search methodology to support claims of comprehensive coverage. The full manuscript (Section 3) details our systematic review process: search queries across ACL Anthology, arXiv, Google Scholar, and Indian NLP repositories; inclusion criteria limited to resources explicitly targeting India's 22 scheduled languages or dialects (2010–2024); duplicate handling via automated deduplication followed by manual verification; and cross-referencing against prior surveys for completeness. We will revise the abstract to add one concise sentence summarizing this approach, e.g., 'Through a systematic literature search with explicit inclusion criteria and duplicate verification, we compile...'. This addresses the concern without altering the abstract's length or focus. revision: yes
Circularity Check
No significant circularity: descriptive survey without derivations
full rationale
This is a literature survey paper whose central claim is the compilation and organization of existing Indian NLP resources into a unified taxonomy. No mathematical derivations, equations, fitted parameters, predictions, or first-principles results are present in the abstract or described structure. The contribution reduces to enumeration and categorization under stated inclusion criteria, with no self-referential steps that equate outputs to inputs by construction. Self-citations, if any, serve only as source references and do not bear load for any uniqueness theorem or ansatz that would create circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In2023 1st Interna- tional Conference on Circuits, Power and Intelligent Systems (CCPIS), pages 1–7
Generative chatbot adaptation for odia lan- guage: A critical evaluation. In2023 1st Interna- tional Conference on Circuits, Power and Intelligent Systems (CCPIS), pages 1–7. IEEE. Divyanshu Aggarwal, Vivek Gupta, and Anoop Kunchukuttan. 2022. Indicxnli: Evaluating multi- lingual inference for indian languages. InProceed- ings of the 2022 Conference on Em...
2022
-
[2]
InProceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), pages 19–25
Efficient multilingual text classification for indian languages. InProceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), pages 19–25. Afroz Ahamad, Ankit Anand, and Pranesh Bhargava
2021
-
[3]
InProceed- ings of the Twelfth Language Resources and Evalua- tion Conference, pages 5351–5358
Accentdb: A database of non-native english ac- cents to assist neural speech recognition. InProceed- ings of the Twelfth Language Resources and Evalua- tion Conference, pages 5351–5358. Zishan Ahmad, Raghav Jindal, Asif Ekbal, and Push- pak Bhattachharyya. 2020. Borrow from rich cousin: transfer learning for emotion detection using cross lingual embedding...
2020
-
[4]
Samiul Alam, Tahsin Reasat, Asif Shahriyar Sushmit, Sadi Mohammad Siddique, Fuad Rahman, Mahady Hasan, and Ahmed Imtiaz Humayun
Dataset and ground truth for handwritten text in four different scripts.International Jour- nal of Pattern Recognition and Artificial Intelligence, 26(04):1253001. Samiul Alam, Tahsin Reasat, Asif Shahriyar Sushmit, Sadi Mohammad Siddique, Fuad Rahman, Mahady Hasan, and Ahmed Imtiaz Humayun. 2021. A large multi-target dataset of common bengali handwritten...
2021
-
[5]
InCOMPASS, page 462
mtransdial: Multilingual dataset for transport domain dialog systems (poster). InCOMPASS, page 462. Dhiraj Amin, Sharvari Govilkar, and Sagar Kulkarni
-
[6]
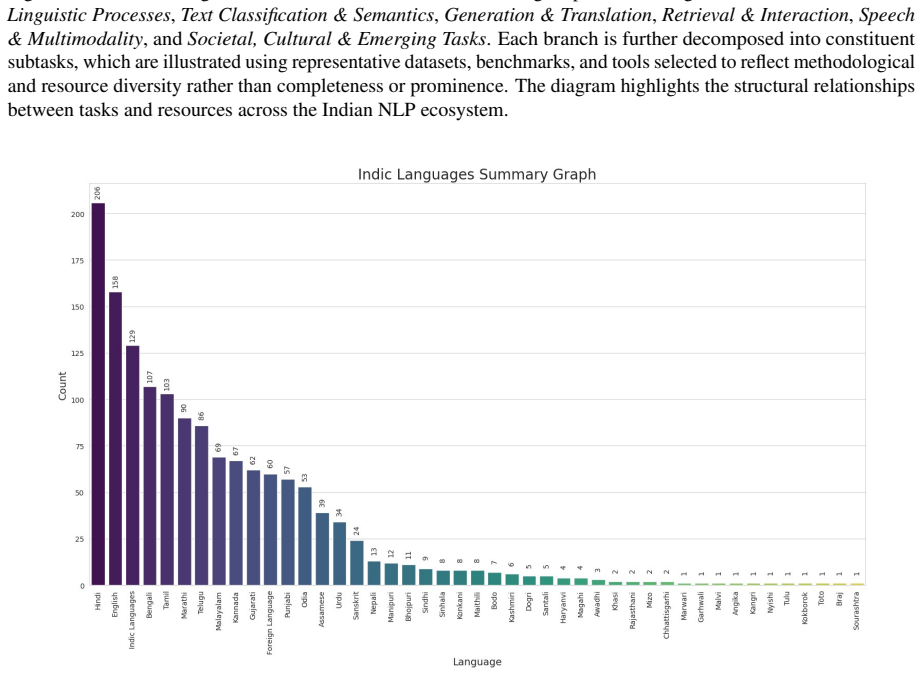
Question answering using deep learning in low resource indian language marathi.arXiv preprint arXiv:2309.15779. Maaz Amjad, Grigori Sidorov, Alisa Zhila, Helena Gómez-Adorno, Ilia V oronkov, and Alexander Gel- bukh. 2020. “bend the truth”: Benchmark dataset for fake news detection in urdu language and its evaluation.Journal of Intelligent & Fuzzy Systems,...
-
[7]
InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 2784–2795
Beyond semantics: Examining gender bias in llms deployed within low-resource contexts in in- dia. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 2784–2795. Abhishek Anilkumar, G Jyothish Lal, B Premjith, and Bharathi Raja Chakravarthi. 2024. Dravlangguard: A multimodal approach for hate speech detection in dr...
2025
-
[8]
In0th International Conference on Compu- tational Linguistics and Intelligent Text
Hindirc: a dataset for reading comprehension in hindi. In0th International Conference on Compu- tational Linguistics and Intelligent Text. Ramakrishna Appicharla, Asif Ekbal, and Pushpak Bhat- tacharyya. 2021. Edumt: Developing machine trans- lation system for educational content in indian lan- guages. InProceedings of the 18th International Conference on...
2021
-
[9]
Calmqa: Exploring culturally specific long- form question answering across 23 languages. In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 11772–11817. Jathin Badam, Akash Bonagiri, Kvln Raju, and Dipan- jan Chakraborty. 2022. Aletheia: A fake news de- tection system for hindi. InPr...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Vistaar: Diverse benchmarks and training sets for indian language asr. InProc. Interspeech 2023, pages 4384–4388. Darshana S Bhole and Sandip S Patil. 2018. Detection of paraphrases for devanagari languages using sup- port vector machine. In2018 International Confer- ence on Communication information and Computing Technology (ICCICT), pages 1–5. IEEE. Sha...
2023
-
[11]
In2021 IEEE international conference on big data (Big Data), pages 2470–2475
Hate or non-hate: Translation based hate speech identification in code-mixed hinglish data set. In2021 IEEE international conference on big data (Big Data), pages 2470–2475. IEEE. Akhilesh Bisht and Deepa Gupta. 2024. Neural machine translation for low resource indian language: Hindi- kangri.Journal of Intelligent & Fuzzy Systems, pages JIFS–219384. Su Li...
-
[12]
Bharathi Raja Chakravarthi, Ruba Priyadharshini, Bernardo Stearns, Arun Kumar Jayapal, Mihael Ar- can, Manel Zarrouk, John P Mccrae, and 1 others
Dravidiancodemix: Sentiment analysis and of- fensive language identification dataset for dravidian languages in code-mixed text.Language Resources and Evaluation, 56(3):765–806. Bharathi Raja Chakravarthi, Ruba Priyadharshini, Bernardo Stearns, Arun Kumar Jayapal, Mihael Ar- can, Manel Zarrouk, John P Mccrae, and 1 others
-
[13]
InProceedings of the 2nd Workshop on Tech- nologies for MT of Low Resource Languages, pages 56–63
Multilingual multimodal machine translation for dravidian languages utilizing phonetic transcrip- tion. InProceedings of the 2nd Workshop on Tech- nologies for MT of Low Resource Languages, pages 56–63. Bharathi Raja Chakravarthi, KP Soman, Rahul Pon- nusamy, Prasanna Kumar Kumaresan, Kingston Pal Thamburaj, John P McCrae, and 1 others. 2021. Dra- vidianm...
-
[14]
In2022 IEEE International Conference on Signal Processing and Communications (SPCOM), pages 1–5
Indic visual question answering. In2022 IEEE International Conference on Signal Processing and Communications (SPCOM), pages 1–5. IEEE. Dhivya Chandrasekaran and Vijay Mago. 2021. Evolu- tion of semantic similarity—a survey.Acm Comput- ing Surveys (Csur), 54(2):1–37. Ankush Chandrashekar, Mohammed Rushad, Akshat Nambiar, V Rashmi, and Shashidhar G Koolagudi
2021
-
[15]
InInternational Confer- ence on Sustainable Computing and Intelligent Sys- tems, pages 53–64
fasttext-based siamese network for hindi se- mantic textual similarity. InInternational Confer- ence on Sustainable Computing and Intelligent Sys- tems, pages 53–64. Springer. Pulkit Chatwal, Amit Agarwal, and Ankush Mittal
-
[16]
InWorking Notes of FIRE 2024-Forum for Information Retrieval Evaluation, Gandhinagar, In- dia
Overcoming code-mixing and script-mixing in indian language summarization with transformer models. InWorking Notes of FIRE 2024-Forum for Information Retrieval Evaluation, Gandhinagar, In- dia. December 12-15. CEUR-WS. org. Prasad Chaudhari, Pankaj Nandeshwar, Shubhi Bansal, and Nagendra Kumar. 2023. Mahaemosen: Towards emotion-aware multimodal marathi se...
2024
-
[17]
Chhikara, G.; Kumar, A.; and Chakraborty, A
A literature survey on multimodal and multi- lingual automatic hate speech identification.Multi- media Systems, 29(3):1203–1230. Garima Chhikara, Abhishek Kumar, and Abhijnan Chakraborty. 2025. Through the prism of culture: Evaluating llms’ understanding of indian subcultures and traditions.arXiv preprint arXiv:2501.16748. Alebachew Chiche and Betselot Yi...
-
[18]
JK Dahanayaka and AR Weerasinghe
A survey of multilingual neural machine trans- lation.ACM Computing Surveys (CSUR), 53(5):1– 38. JK Dahanayaka and AR Weerasinghe. 2014. Named entity recognition for sinhala language. In2014 14th International Conference on Advances in ICT for Emerging Regions (ICTer), pages 215–220. IEEE. Tusarkanta Dalai, Tapas Kumar Mishra, and Pankaj K Sa. 2023. Part-...
-
[19]
Vandana Dhingra and Mihir M Joshi
Fakenewsindia: A benchmark dataset of fake news incidents in india, collection methodology and impact assessment in social media.Computer Com- munications, 185:130–141. Vandana Dhingra and Mihir M Joshi. 2022. Rule based approach for compound segmentation and paraphrase generation in sanskrit.International Journal of Infor- mation Technology, 14(6):3183–3...
2022
-
[20]
arXiv preprint arXiv:2305.11355
Md3: The multi-dialect dataset of dialogues. arXiv preprint arXiv:2305.11355. Asif Ekbal and Sivaji Bandyopadhyay. 2008. Web- based bengali news corpus for lexicon development and pos tagging.Polibits, (37):21–30. Asif Ekbal, Pushpak Bhattacharyya, Tista Saha, Alka Kumar, Shikha Srivastava, and 1 others. 2022. Hindimd: A multi-domain corpora for low-resou...
-
[21]
arXiv preprint arXiv:2305.16307 , year=
Tamilfacts: A comprehensive multimodal dataset of fact-checked social media content in tamil language. InInternational Conference on Speech and Language Technologies for Low-resource Languages, pages 167–182. Springer. Baban Gain, Ramakrishna Appicharla, Soumya Chennabasavaraj, Nikesh Garera, Asif Ekbal, and Muthusamy Chelliah. 2022. Low resource chat tra...
-
[22]
Sanjana Gunna, Rohit Saluja, and CV Jawahar
A deep learning-based bilingual hindi and punjabi named entity recognition system using en- hanced word embeddings.Knowledge-Based Sys- tems, 234:107601. Sanjana Gunna, Rohit Saluja, and CV Jawahar. 2021. Transfer learning for scene text recognition in indian languages. InInternational Conference on Document Analysis and Recognition, pages 182–197. Spring...
-
[23]
Vedika Gupta, Nikita Jain, Shubham Shubham, Agam Madan, Ankit Chaudhary, and Qin Xin
IEEE. Vedika Gupta, Nikita Jain, Shubham Shubham, Agam Madan, Ankit Chaudhary, and Qin Xin. 2021b. To- ward integrated cnn-based sentiment analysis of tweets for scarce-resource language—hindi.Trans- actions on Asian and Low-Resource Language Infor- mation Processing, 20(5):1–23. Vikram Gupta, Sumegh Roychowdhury, Mithun Das, Somnath Banerjee, Punyajoy Sa...
-
[24]
Mahaparaphrase: A marathi paraphrase detec- tion corpus and bert-based models.arXiv preprint arXiv:2508.17444. Swapnil Ashok Jadhav. 2020. Marathi to english neu- ral machine translation with near perfect corpus and transformers.arXiv preprint arXiv:2002.11643. Farhan Ahmad Jafri, Kritesh Rauniyar, Surendrabikram Thapa, Mohammad Aman Siddiqui, Matloob Khu...
-
[25]
arXiv preprint arXiv:2409.13484 , year=
’since lawyers are males..’: Examining implicit gender bias in hindi language generation by llms. arXiv preprint arXiv:2409.13484. Neha Joshi, Pamir Gogoi, Aasim Mirza, Aayush Jansari, Aditya Yadavalli, Ayushi Pandey, Arunima Shukla, Deepthi Sudharsan, Kalika Bali, and Vivek Seshadri
-
[26]
Elr-1000: A community-generated dataset for endangered indic indigenous languages.arXiv preprint arXiv:2512.01077. Sindhya K. Nambiar, David Peter S, and Sumam Mary Idicula. 2023. Abstractive summarization of text document in malayalam language: Enhancing attention model using pos tagging feature.ACM Transactions on Asian and Low-Resource Language Informa...
-
[27]
Telugu language hate speech detection using deep learning transformer models: Corpus genera- tion and evaluation.Systems and Soft Computing, 6:200112. Simran Khanuja, Diksha Bansal, Sarvesh Mehtani, Savya Khosla, Atreyee Dey, Balaji Gopalan, Dilip Kumar Margam, Pooja Aggarwal, Rajiv Teja Nagipogu, Shachi Dave, and 1 others. 2021. Muril: Multilingual repre...
-
[28]
InFindings of the Association for Computational Linguistics: ACL 2022, pages 472–480
Symcom-syntactic measure of code mixing a study of english-hindi code-mixing. InFindings of the Association for Computational Linguistics: ACL 2022, pages 472–480. Adithya S Kolavi, Vyoman Jain, and 1 others. 2025. Nayana: A foundation for document-centric vision- language models via multi-task, multimodal, and multilingual data synthesis. InProceedings o...
2022
-
[29]
Normalized dataset for sanskrit word seg- mentation and morphological parsing.Language Resources and Evaluation, 59(2):1279–1330. Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, and Orhan Firat. 2023. Madlad-400: A multilingual and document-level large audited dataset.Advances in Neural In...
-
[30]
Onkar Litake, Maithili Ravindra Sabane, Parth Sachin Patil, Aparna Abhijeet Ranade, and Raviraj Joshi
A survey on deep learning for named entity recognition.IEEE transactions on knowledge and data engineering, 34(1):50–70. Onkar Litake, Maithili Ravindra Sabane, Parth Sachin Patil, Aparna Abhijeet Ranade, and Raviraj Joshi
-
[31]
L3cube-mahaner: A marathi named entity recognition dataset and bert models. InProceedings of the WILDRE-6 Workshop within the 13th Lan- guage Resources and Evaluation Conference, pages 29–34. Chen Cecilia Liu, Iryna Gurevych, and Anna Korho- nen. 2025a. Culturally aware and adapted nlp: A taxonomy and a survey of the state of the art.Trans- actions of the...
-
[32]
Chhattisgarhi speech corpus for research and development in automatic speech recognition.Inter- national Journal of Speech Technology, 21(2):193– 210. Adam Lopez. 2008. Statistical machine translation. ACM Computing Surveys (CSUR), 40(3):1–49. Harsh Lunia, Ajoy Mondal, and CV Jawahar. 2023. Indicstr12: a dataset for indic scene text recognition. InInterna...
-
[33]
In2016 12th IAPR workshop on document analysis systems (DAS), pages 186–191
Multilingual ocr for indic scripts. In2016 12th IAPR workshop on document analysis systems (DAS), pages 186–191. IEEE. Laiba Mehnaz, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle Lee, Anish Acharya, and Rajiv Ratn Shah. 2021. Gupshup: An anno- tated corpus for abstractive summarization of open- do...
-
[34]
Between words and characters: A brief history of open-vocabulary modeling and tokenization in NLP,
Automatic text summarization in gujarati lan- guage. In2022 IEEE 2nd international symposium on sustainable energy, signal processing and cyber security (iSSSC), pages 1–6. IEEE. Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar. 2020. Plotqa: Reasoning over sci- entific plots. InProceedings of the ieee/cvf winter conference on applicati...
-
[35]
Aishwarya Mirashi, Srushti Sonavane, Purva Lingayat, Tejas Padhiyar, and Raviraj Joshi
L3cube-mahasts: A marathi sentence similarity dataset and models.arXiv preprint arXiv:2508.21569. Aishwarya Mirashi, Srushti Sonavane, Purva Lingayat, Tejas Padhiyar, and Raviraj Joshi. 2023. L3cube- indicnews: News-based short text and long document classification datasets in indic languages. InProceed- ings of the 20th International Conference on Natura...
-
[36]
Ritwik Mishra, Rajiv Ratn Shah, and Ponnurangam Kumaraguru
Springer. Ritwik Mishra, Rajiv Ratn Shah, and Ponnurangam Kumaraguru. 2025. Long-context non-factoid ques- tion answering in indic languages.arXiv preprint arXiv:2504.13615. Sudhakar Mishra, Narayanan Srinivasan, Mohammad Asif, and Uma Shanker Tiwary. 2023. Affective film dataset from india (afdi): creation and validation with an indian sample.Journal of ...
-
[37]
Mubashir Munaf, Hammad Afzal, Khawir Mahmood, and Naima Iltaf
An information-extraction system for urdu—a resource-poor language.ACM Transactions on Asian Language Information Processing (TALIP), 9(4):1– 43. Mubashir Munaf, Hammad Afzal, Khawir Mahmood, and Naima Iltaf. 2024. Low resource summarization using pre-trained language models.ACM Transac- tions on Asian and Low-Resource Language Informa- tion Processing, 2...
2024
-
[38]
Reddy Naidu, Santosh Kumar Bharti, Korra Sathya Babu, and Ramesh Kumar Mohapatra
Kannada to english machine translation using deep neural network.Ingénierie des Systèmes d Inf., 26(1):123–127. Reddy Naidu, Santosh Kumar Bharti, Korra Sathya Babu, and Ramesh Kumar Mohapatra. 2017. Sen- timent analysis using telugu sentiwordnet. In2017 International Conference on Wireless Communica- tions, Signal Processing and Networking (WiSPNET), pag...
-
[39]
Bolanle Ojokoh and Emmanuel Adebisi
Study of tokenization strategies for the santhali language.SN Computer Science, 5(7):807. Bolanle Ojokoh and Emmanuel Adebisi. 2018. A re- view of question answering systems.Journal of Web Engineering, 17(8):717–758. Eric Onyame, Akash Ghosh, Subhadip Baidya, Sri- parna Saha, Xiuying Chen, and Chirag Agarwal
2018
-
[40]
CURE-Med: Curriculum-Informed Reinforcement Learning for Multilingual Medical Reasoning
Cure-med: Curriculum-informed reinforce- ment learning for multilingual medical reasoning. arXiv preprint arXiv:2601.13262. Aditya Pal and Bhaskar Karn. 2020. Anubhuti–an anno- tated dataset for emotional analysis of bengali short stories.arXiv preprint arXiv:2010.03065. Aniket Pal, Ajoy Mondal, and CV Jawahar. 2025. Hw- mlvqa: a novel handwritten multili...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[41]
InInformatics, volume 6, page 19
Improving semantic similarity with cross- lingual resources: a study in bangla—a low resourced language. InInformatics, volume 6, page 19. MDPI. Jyoti Pareek, Dimple Singhania, Rashmi Rekha Ku- mari, and Suchit Purohit. 2020. Gujarati handwritten character recognition from text images.Procedia Computer Science, 171:514–523. Shantipriya Parida, Ond ˇrej Bo...
2020
-
[42]
Braja Gopal Patra, Dipankar Das, Amitava Das, and Ra- jendra Prasath
Sentiment analysis of code-mixed indian lan- guages: An overview of sail_code-mixed shared task@ icon-2017.arXiv preprint arXiv:1803.06745. Braja Gopal Patra, Dipankar Das, Amitava Das, and Ra- jendra Prasath. 2015. Shared task on sentiment anal- ysis in indian languages (sail) tweets-an overview. In International Conference on Mining Intelligence and Kno...
-
[43]
In2025 IEEE International Conference on Electro Information Technology (eIT), pages 456–462
Tokenization matters: Improving zero-shot ner for indic languages. In2025 IEEE International Conference on Electro Information Technology (eIT), pages 456–462. IEEE. Siddhesh Pawar, Junyeong Park, Jiho Jin, Arnav Arora, Junho Myung, Srishti Yadav, Faiz Ghifari Haznitrama, Inhwa Song, Alice Oh, and Isabelle Au- genstein. 2025. Survey of cultural awareness ...
2025
-
[44]
InProceedings of the 6th Workshop on South and Southeast Asian Natural Language Pro- cessing (WSSANLP2016), pages 93–102
Sentiment analysis of tweets in three indian languages. InProceedings of the 6th Workshop on South and Southeast Asian Natural Language Pro- cessing (WSSANLP2016), pages 93–102. Siginamsetty Phani, Ashu Abdul, M Krishna Siva Prasad, and Hiren Kumar Deva Sarma. 2024. Mmsft: Multilingual multimodal summarization by fine- tuning transformers.IEEE Access. Rit...
2024
-
[45]
In2022 IEEE 19th India Council International Conference (INDICON), pages 1–6
Telugu dialect speech dataset creation and recognition using deep learning techniques. In2022 IEEE 19th India Council International Conference (INDICON), pages 1–6. IEEE. SS Poorna, K Anuraj, and GJ Nair. 2018. A weight based approach for emotion recognition from speech: An analysis using south indian languages. InInterna- tional Conference on Soft Comput...
-
[46]
InPro- ceedings of the First Workshop in South East Asian Language Processing, pages 79–84
Sentmix-3l: A novel code-mixed test dataset in bangla-english-hindi for sentiment analysis. InPro- ceedings of the First Workshop in South East Asian Language Processing, pages 79–84. Eduri Raja, Badal Soni, and Samir Kumar Borgo- hain. 2023. Fake news detection in dravidian lan- guages using transfer learning with adaptive finetun- ing.Engineering Applic...
-
[47]
Transactions of the Association for Computational Linguistics, 10:145–162
Samanantar: The largest publicly available parallel corpora collection for 11 indic languages. Transactions of the Association for Computational Linguistics, 10:145–162. S Ramraj, R Arthi, Solai Murugan, and MS Julie. 2020. Topic categorization of tamil news articles using pre- trained word2vec embeddings with convolutional neural network. In2020 Internat...
-
[48]
InProceedings of the 7th ACM IKDD CoDS and 25th COMAD, pages 234–238
Avadhan: System for open-domain telugu question answering. InProceedings of the 7th ACM IKDD CoDS and 25th COMAD, pages 234–238. Hassan Raza and Waseem Shahzad. 2024. End to end urdu abstractive text summarization with dataset and improvement in evaluation metric.IEEE Access, 12:40311–40324. Siva Reddy and Serge Sharoff. 2011. Cross language pos taggers (...
2024
-
[49]
Breaking language barriers: A question an- swering dataset for hindi and marathi.arXiv preprint arXiv:2308.09862. Sourav Saha, Zeshan Ahmed Nobin, Mufassir Ahmad Chowdhury, Md Shakirul Hasan Khan Mobin, Mo- hammad Ruhul Amin, and Sudipta Kar. 2024. Bnpc: A gold standard corpus for paraphrase detection in bangla, and its evaluation. InProceedings of the 17...
-
[50]
Indic-tedst: Datasets and baselines for low- resource speech to text translation. InProceedings of the 2024 Joint International Conference on Compu- tational Linguistics, Language Resources and Evalu- ation (LREC-COLING 2024), pages 9019–9024. Nivedita Sethiya, Saanvi Nair, Puneet Walia, and Chan- dresh Maurya. 2025. Indic-st: A large-scale multilin- gual...
-
[51]
Richa Sharma, Sudha Morwal, Basant Agarwal, Ramesh Chandra, and Mohammad S Khan
Named entity recognition using neural lan- guage model and crf for hindi language.Computer Speech & Language, 74:101356. Richa Sharma, Sudha Morwal, Basant Agarwal, Ramesh Chandra, and Mohammad S Khan. 2020. A deep neural network-based model for named entity recognition for hindi language.Neural Computing and Applications, 32(20):16191–16203. Usha Sharma,...
2020
-
[52]
Rajvee Sheth, Himanshu Beniwal, and Mayank Singh
Hindispeech-net: a deep learning based robust automatic speech recognition system for hindi language.Multimedia Tools and Applications, 82(11):16173–16193. Rajvee Sheth, Himanshu Beniwal, and Mayank Singh
-
[53]
Vishwas M Shetty and Srinivasan Umesh
Comi-lingua: Expert annotated large-scale dataset for multitask nlp in hindi-english code- mixing.arXiv preprint arXiv:2503.21670. Vishwas M Shetty and Srinivasan Umesh. 2021. Ex- ploring the use of common label set to improve speech recognition of low resource indian languages. InICASSP 2021-2021 IEEE International Confer- ence on Acoustics, Speech and S...
-
[54]
Punit Kumar Singh, Nishant Kumar, Hrushik Mehta, and Sriparna Saha
Benchmark databases of handwritten bangla- roman and devanagari-roman mixed-script docu- ment images.Multimedia Tools and Applications, 77(7):8441–8473. Punit Kumar Singh, Nishant Kumar, Hrushik Mehta, and Sriparna Saha. 2025b. From conversations to in- sights: A multimodal approach to discussion summa- rization. InInternational Conference on Document Ana...
-
[55]
Ian Smith and Uthayasanker Thayasivam
Springer. Ian Smith and Uthayasanker Thayasivam. 2019. Lan- guage detection in sinhala-english code-mixed data. In2019 International Conference on Asian Language Processing (IALP), pages 228–233. IEEE. Vimal Kumar Soni, Dinesh Gopalani, and MC Govil
2019
-
[56]
InIOP Conference Series: Materials Science and Engineering, volume 1131, page 012015
A dataset to evaluate hindi word embeddings. InIOP Conference Series: Materials Science and Engineering, volume 1131, page 012015. IOP Pub- lishing. Kumar Sourabh and Vibhakar Mansotra. 2012. Query optimization: a solution for low recall problem in hindi language information retrieval.International Journal of Computer Applications, 55(17). K Sreelakshmi, ...
-
[57]
Sarkar Sujoy, Amrith Krishna, and Pawan Goyal
Malfake: A multimodal fake news identifica- tion for malayalam using recurrent neural networks and vgg-16.arXiv preprint arXiv:2310.18263. Sarkar Sujoy, Amrith Krishna, and Pawan Goyal. 2023. Pre-annotation based approach for development of a sanskrit named entity recognition dataset. InPro- ceedings of the Computational Sanskrit & Digital Humanities: Sel...
-
[58]
InFindings of the Association for Computational Linguistics: ACL 2023, pages 307–318
On evaluating and mitigating gender biases in multilingual settings. InFindings of the Association for Computational Linguistics: ACL 2023, pages 307–318. Arpita Vats, Rahul Raja, Mrinal Mathur, Aman Chadha, and Vinija Jain. 2025. Multilingual state space mod- els for structured question answering in indic lan- guages. InProceedings of the Eighth Workshop...
-
[59]
InProceedings of the 19th International Conference on Natural Language Processing (ICON), pages 300– 307
Tequad: Telugu question answering dataset. InProceedings of the 19th International Conference on Natural Language Processing (ICON), pages 300– 307. Devika Verma, Ramprasad S Joshi, Aiman A Shivani, and Rohan D Gupta. 2023a. K ¯araka-based answer retrieval for question answering in indic languages. InProceedings of the 14th International Conference on Rec...
-
[60]
Milu: A multi-task indic language understand- ing benchmark. InProceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 10076–10132. Yash Verma, Anubhav Jangra, Raghvendra Verma, and Sriparna Saha. 2023b. Large scale multi-lingua...
2025
-
[61]
InSLTU, pages 56–60
Iiith-ilsc speech database for indain language identification. InSLTU, pages 56–60. Mayur Wankhade, Annavarapu Chandra Sekhara Rao, and Chaitanya Kulkarni. 2022. A survey on senti- ment analysis methods, applications, and challenges. Artificial Intelligence Review, 55(7):5731–5780. Sunita Warjri, Partha Pakray, Saralin A Lyngdoh, and Arnab Kumar Maji. 202...
2022
-
[62]
What qualifies a resource to be included in this survey?We include datasets, bench- marks, and tools developed specifically for Indian languages, as well as multilingual re- sources that explicitly cover Indian languages (including English–Indic settings)
-
[63]
Indic Languages
Why are some languages grouped under the “Indic Languages” category in figures? Resources covering multiple Indian languages (often 15–200) are aggregated under theIndic Languagescategory, while resources focused exclusively on a single language are counted toward that language
-
[64]
Does the survey aim to be exhaustive or rep- resentative?The survey prioritizes breadth and diversity over completeness, selecting rep- resentative resources to reflect methodological trends, task coverage, and language diversity rather than listing every available work
-
[65]
Why is English included in some datasets discussed in the survey?English is included when it appears alongside Indian languages in multilingual or code-mixed resources, as such settings are common in real-world Indian NLP applications
-
[66]
How does this survey differ from existing Indic or multilingual NLP surveys?Unlike prior surveys that focus on specific tasks or embed Indian languages within broader multi- lingual contexts, this work provides a unified, task-centric view dedicated exclusively to In- dian NLP
-
[67]
Why are certain tasks (e.g., sentiment, hate speech) more resource-rich than others? These tasks often rely on easily available social-media data, whereas tasks such as mul- timodal reasoning, speech processing, and low-resource language modeling require more complex and costly data collection
-
[68]
Are pretrained LLMs and foundation mod- els fully solving Indian NLP challenges? While multilingual pretrained models have im- proved coverage, significant gaps remain in low-resource languages, cultural grounding, bias mitigation, and cross-modal generaliza- tion
-
[69]
How are annotation quality and consistency addressed in the survey?We highlight an- notation practices, agreement reporting, and documentation where available, and identify inconsistent labeling and sparse metadata as key cross-cutting challenges
-
[70]
Why is code-mixing treated as a recurring challenge across tasks?Code-mixing and romanization are pervasive in Indian language use and affect nearly all NLP pipelines, from tokenization to generation, making them foun- dational rather than task-specific issues
-
[71]
What are the main limitations of current evaluation practices?Evaluation protocols vary widely across languages and tasks, with inconsistent metrics, difficulty levels, and benchmarks, limiting reliable cross-language and cross-task comparison
-
[72]
How does the survey address societal and cultural dimensions of NLP?Dedicated sec- tions cover misinformation, cultural reason- ing, bias, and emerging tasks, emphasizing India-specific social, cultural, and ethical con- siderations often overlooked in generic NLP surveys
-
[73]
Where can readers find detailed tables and extended comparisons?Comprehensive task-wise tables, language-wise distributions, and unified gap analyses are provided in the appendix and referenced throughout the paper
-
[74]
Indic NLP
Who is this survey intended for?The sur- vey is intended for NLP researchers, dataset creators, model developers, practitioners, and policymakers interested in building inclusive, culturally grounded AI for Indian languages. D Future Directions Despite rapid progress across datasets, benchmarks, and models, Indian-language NLP continues to face distinctiv...
2020
-
[75]
look-back fix
are released for research and evaluation. Li- censing information, however, is inconsistently specified across resources. Dialogue Systems.Dialogue datasets including the code-mixed corpus (Banerjee et al., 2018), HDRS (Malviya et al., 2021), TamilATIS (Ra- maneswaran et al., 2022), and mTransDial (Am- bastha and Desarkar, 2021) are primarily available fo...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.