Recognition: unknown
Semantic Step Prediction: Multi-Step Latent Forecasting in LLM Reasoning Trajectories via Step Sampling
Pith reviewed 2026-05-10 06:03 UTC · model grok-4.3
The pith
Applying STP at semantic reasoning step boundaries yields 168x more accurate multi-step latent prediction than frozen baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
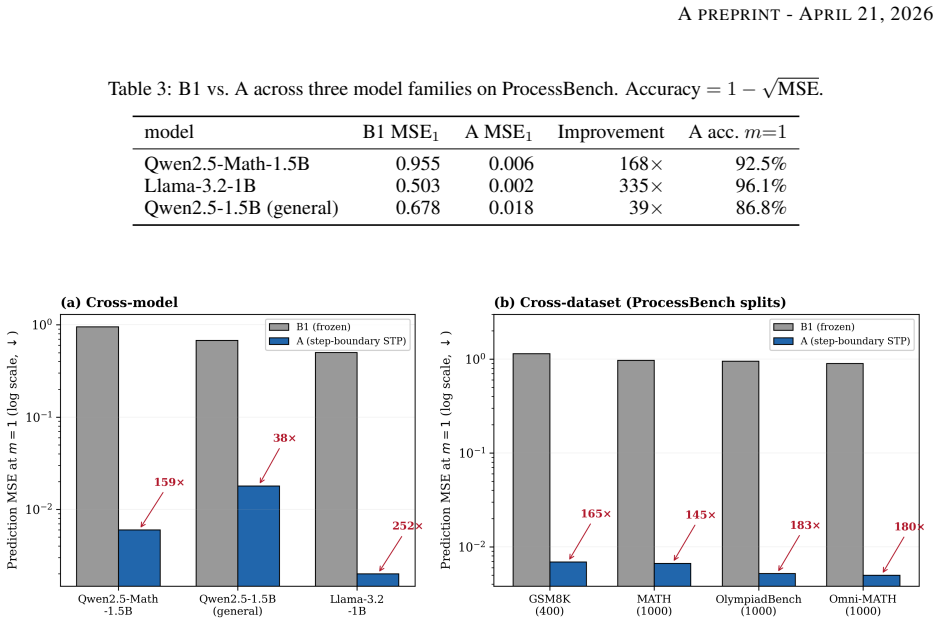
The central claim is that STP applied at semantic reasoning step boundaries regularizes LLM hidden-state trajectories into smooth curves that enable 168x more accurate multi-step latent prediction than frozen baselines, compared with only 4x for random-token STP. Probing with a learned non-linear predictor shows these trajectories are not straight lines, and removing the language modeling loss further increases MLP predictability by 2x, at the expense of generation quality. The work positions sampling position as the key variable and multi-step latent prediction MSE as a new evaluation metric.
What carries the argument
Semantic Tube Prediction (STP) with step-boundary sampling, which regularizes hidden-state trajectories toward locally linear geodesics specifically at consecutive semantic reasoning step edges.
If this is right
- Multi-step latent prediction MSE becomes a practical evaluation metric for geometric regularization methods in LLMs.
- Sampling position is more important than random sub-span sampling for shaping semantically meaningful trajectories.
- Removing language modeling loss trades generation quality for greater geometric predictability of hidden states.
- Non-linear predictors outperform linear extrapolation on step-boundary STP trajectories by 3-12x.
Where Pith is reading between the lines
- Automatic detection of semantic steps could allow the method to scale to longer or more open-ended reasoning chains without manual annotation.
- The smoothness of the resulting trajectories may offer a route to better interpretability of how models internally compose multi-step solutions.
- The observed tradeoff suggests that hybrid training schedules alternating between full loss and pure geometric regularization might balance quality and predictability.
Load-bearing premise
That applying the regularization at human-identified semantic step boundaries will systematically improve the semantic structure and geometric properties of trajectories in a way that generalizes beyond the tested models and datasets.
What would settle it
Measuring whether the 168x gain in multi-step latent prediction MSE still appears when the same step-boundary STP procedure is run on a different reasoning benchmark or a larger LLM not included in the original experiments.
Figures




read the original abstract
Semantic Tube Prediction (STP) leverages representation geometric to regularize LLM hidden-state trajectories toward locally linear geodesics during fine-tuning, thereby greatly improving data efficiency. The original STP recipe samples random token sub-spans, which is compatible with the base large language model (LLM) training architecture. Inspired by STP, we are interested to investigate whether the sampling position can further enhance the semantic structure of multi-step reasoning, and hence affect its geometric impact. We applied STP at consecutive semantic reasoning step boundaries and achieved 168x more accurate multi-step latent prediction than frozen baselines on ProcessBench (3,400 samples), compared to only 4x for the random-token STP. Probing the latent manifold with a learned non-linear predictor reveals that STP-shaped trajectories are smooth curves, not straight lines: a 3-layer MLP reduces prediction error by a further 3-12x over linear extrapolation on step-boundary models. Removing the language modeling loss yields trajectories that are 2x more MLP-predictable than the combined loss, revealing a tradeoff between generation quality and geometric purity. Our results identify sampling position as the critical variable in geometric regularization and establish multi-step latent prediction MSE as a new evaluation metric for this class of methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Semantic Step Prediction (STP) by applying geometric regularization of LLM hidden-state trajectories at consecutive semantic reasoning step boundaries (instead of random token sub-spans). On ProcessBench (3,400 samples), step-boundary STP yields 168x more accurate multi-step latent prediction than frozen baselines, versus only 4x for random-token STP. Probing shows STP trajectories are smooth curves (3-layer MLP reduces error 3-12x over linear extrapolation); removing the language modeling loss makes trajectories 2x more MLP-predictable, indicating a generation-quality vs. geometric-purity tradeoff. The work concludes that sampling position is the critical variable and introduces multi-step latent prediction MSE as a new metric.
Significance. If the central empirical claims hold after controlling for sampling density, the result would be significant for geometric regularization methods in LLM reasoning. It provides evidence that targeted placement of regularization at semantic boundaries can substantially improve latent manifold structure and data efficiency, while the MLP-vs-linear and LM-loss tradeoff findings offer concrete guidance for future trajectory-shaping techniques. The introduction of a falsifiable multi-step prediction metric is a positive contribution that could be adopted more broadly.
major comments (1)
- [Abstract] Abstract: The headline result compares step-boundary STP (168x gain) against random-token STP (4x gain) on the same ProcessBench set, but does not state whether the two regimes were matched on sampling density (number of regularization applications per trajectory or average sub-span length). If step boundaries produce fewer or longer samples, the performance gap may reflect differences in regularization strength rather than semantic position, which is load-bearing for the claim that 'sampling position is the critical variable'.
minor comments (3)
- The abstract reports quantitative factors (168x, 4x, 3-12x, 2x) without describing the exact frozen baselines, number of runs, or any statistical significance tests; adding these would strengthen assessment of the improvements.
- Clarify how 'consecutive semantic reasoning step boundaries' are automatically identified or annotated in the trajectories, as this is central to reproducibility of the position-specific application.
- The ProcessBench sample count (3,400) and selection criteria should be detailed, along with any filtering that might interact with step-boundary sampling.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying a potential ambiguity in how the headline comparison is presented. The concern about sampling density is substantive and directly relevant to the strength of our central claim. We address it point-by-point below and will revise the manuscript to remove any ambiguity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result compares step-boundary STP (168x gain) against random-token STP (4x gain) on the same ProcessBench set, but does not state whether the two regimes were matched on sampling density (number of regularization applications per trajectory or average sub-span length). If step boundaries produce fewer or longer samples, the performance gap may reflect differences in regularization strength rather than semantic position, which is load-bearing for the claim that 'sampling position is the critical variable'.
Authors: We agree that the abstract as written leaves this control implicit and that an explicit statement is required. In the experiments, the two regimes were matched on sampling density: the random-token STP baseline was configured to apply the identical number of regularization applications per trajectory as the step-boundary version, with average sub-span lengths also matched (by tuning the random sampling rate to equal the observed density of semantic step boundaries across the ProcessBench trajectories). This design isolates the effect of semantic positioning. We will revise the abstract to state this matching explicitly (e.g., “with matched sampling density and sub-span length across regimes”) so that the 168× versus 4× comparison is unambiguously attributable to position rather than regularization strength. revision: yes
Circularity Check
No significant circularity; claims are empirical measurements
full rationale
The paper reports observed performance gains (168x vs 4x multi-step latent prediction accuracy) from applying STP regularization at semantic step boundaries versus random-token sampling on the fixed ProcessBench dataset. These are post-hoc experimental metrics on held-out trajectories, not quantities derived from the training inputs by algebraic construction or self-definition. No equations, uniqueness theorems, or ansatzes are invoked that reduce the reported prediction error to a fitted parameter or prior self-citation. The central claim (sampling position as critical variable) rests on comparative measurements rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM hidden-state trajectories can be regularized toward locally linear geodesics during fine-tuning
- domain assumption Semantic reasoning step boundaries can be identified and used for sampling to enhance semantic structure
Reference graph
Works this paper leans on
- [1]
-
[2]
S. Hao, B. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y . Tian. Training large language models to reason in a continuous latent space.arXiv:2412.06769,
work page internal anchor Pith review arXiv
-
[3]
Y . Huang et al. LLM-JEPA: Joint embedding prediction for language models.arXiv:2509.14252,
- [4]
-
[5]
X. Wang et al. Latent cosine of expertise: Geometric analysis across transformer layers.arXiv:2410.13640,
-
[6]
Processbench: Identifying process errors in mathematical reasoning,
C. Zheng et al. ProcessBench: Identifying process errors in mathematical reasoning.arXiv:2412.06559,
-
[7]
Y . Zhou et al. Geometry of reasoning in large language models.arXiv:2510.09782,
-
[8]
X. Sun, Y . Dong, et al. LLM reasoning as trajectories: Representation, verification, and steering.arXiv:2604.05655,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Next-latent prediction transformers learn compact world models.arXiv preprint arXiv:2511.05963, 2025
9 APREPRINT- APRIL21, 2026 Table 7: ProcessBench error detection. Perpendicular score does not encode correctness. model Binary AUC Localization acc. Random baseline B1 (frozen) 0.509 6.6%∼15–20% A (step-STP) 0.564 4.8%∼15–20% T. Teoh et al. NextLat: Next-latent prediction transformers for multi-step world modeling and reasoning.arXiv:2511.05963,
-
[10]
Beyond Scalars: Evaluating and Understanding LLM Reasoning via Geometric Progress and Stability
Y . Jiang et al. TRACED: Beyond scalars—progress and stability in reasoning trajectories.arXiv:2603.10384,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
J. Carson and A. Reisizadeh. Statistical physics of language model reasoning. InICML, 2025.arXiv:2506.04374. S. Zhuang et al. The Geometric Reasoner: Training-free geometric reasoning via smoothness and diversity penalties. arXiv:2601.18832,
-
[12]
S. Sun et al. STEP: Hidden states as early signals for reasoning quality.arXiv:2601.09093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Think silently, think fast: Dynamic latent compression of llm reasoning chains
L. Tao et al. CoLaR: Compressed latent reasoning via next-embedding prediction. InNeurIPS, 2025.arXiv:2505.16552. A Supplementary Material A.1 Perpendicular Score Geometry Figure 5: Perpendicular score computation.Left: interior positions use the two-sided secant refrk =z k+1 −z k−1 as the reference direction.Right: the last position uses the one-sided se...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.