Recognition: 2 theorem links
· Lean TheoremLLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals
Pith reviewed 2026-05-10 19:48 UTC · model grok-4.3
The pith
LLM chain-of-thought reasoning follows step-specific trajectories in representation space that diverge by correctness at late layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
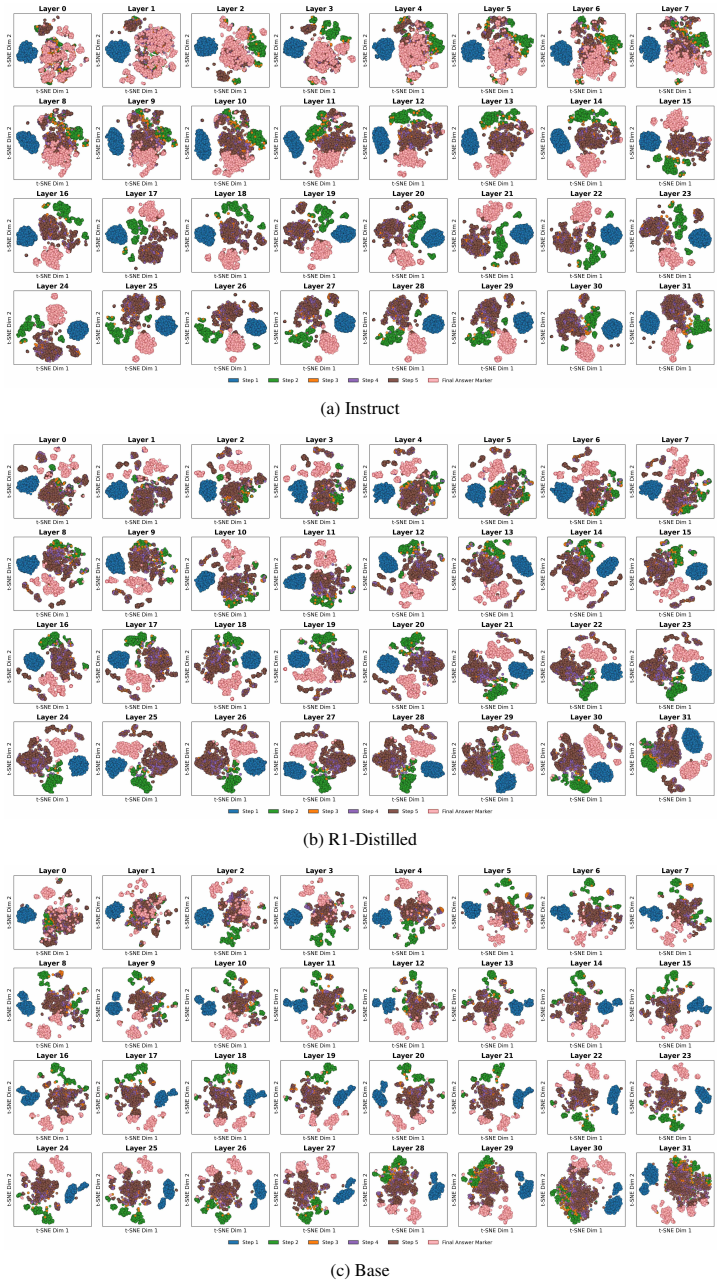
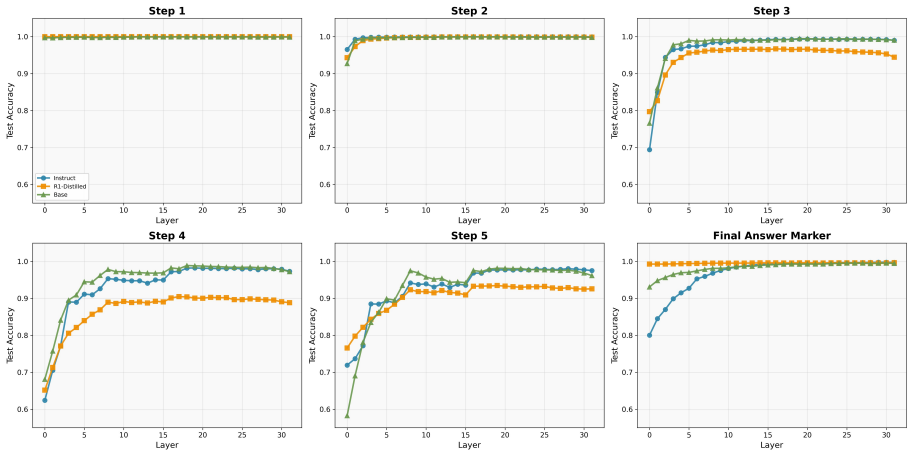
The paper establishes that mathematical reasoning in LLMs traverses functionally ordered, step-specific subspaces in representation space that become increasingly separable with layer depth. This geometric structure is present even in base models, with training mainly accelerating convergence to termination subspaces. Early reasoning steps follow similar trajectories across correct and incorrect solutions, but the paths diverge systematically in later stages. This late divergence permits prediction of final-answer correctness from mid-reasoning states with ROC-AUC up to 0.87. The work introduces trajectory-based steering as an inference-time method to correct reasoning or control output leng
What carries the argument
Step-specific subspaces and trajectories of hidden representations across layers and generation steps, which organize the reasoning process and reveal divergence between correct and incorrect paths.
Load-bearing premise
The patterns seen in the representation space directly reflect functional steps in reasoning and can be causally used to steer behavior without creating new mistakes.
What would settle it
An experiment showing that steering generations along the proposed ideal trajectories does not increase the rate of correct answers compared to unsteered generation, or that mid-reasoning state-based predictions fail to correlate with actual final correctness on new problems.
Figures



read the original abstract
This work characterizes large language models' chain-of-thought generation as a structured trajectory through representation space. We show that mathematical reasoning traverses functionally ordered, step-specific subspaces that become increasingly separable with layer depth. This structure already exists in base models, while reasoning training primarily accelerates convergence toward termination-related subspaces rather than introducing new representational organization. While early reasoning steps follow similar trajectories, correct and incorrect solutions diverge systematically at late stages. This late-stage divergence enables mid-reasoning prediction of final-answer correctness with ROC-AUC up to 0.87. Furthermore, we introduce trajectory-based steering, an inference-time intervention framework that enables reasoning correction and length control based on derived ideal trajectories. Together, these results establish reasoning trajectories as a geometric lens for interpreting, predicting, and controlling LLM reasoning behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models LLM chain-of-thought reasoning as trajectories through hidden-state representation space. It reports that mathematical reasoning follows step-specific subspaces whose separability increases with layer depth; this organization pre-exists in base models and is accelerated by reasoning training. Correct and incorrect trajectories remain similar early but diverge systematically at late stages, enabling mid-reasoning prediction of final-answer correctness (ROC-AUC up to 0.87). The authors further introduce an inference-time trajectory-based steering framework that uses derived “ideal” trajectories to correct reasoning errors and control output length.
Significance. If the geometric structures are shown to be causally tied to reasoning correctness rather than sequence artifacts, the work supplies a concrete geometric account of how LLMs perform step-by-step reasoning, together with practical tools for early correctness prediction and controllable generation. The pre-existing structure in base models and the steering results are potentially high-impact contributions to interpretability and inference-time intervention research.
major comments (2)
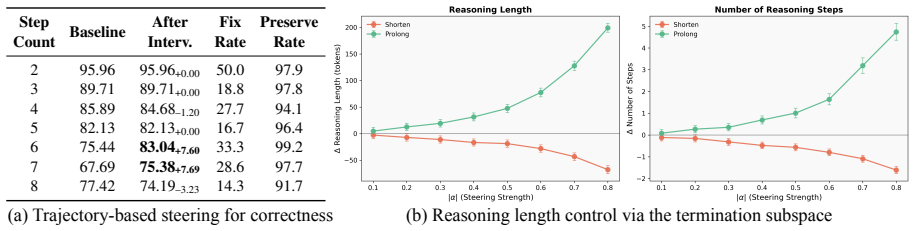
- [Results on late-stage divergence] §4 (or equivalent results section on divergence and prediction): the manuscript must include explicit controls that match correct and incorrect CoT chains on partial length, token distribution, and termination signals before attributing late-stage geometric separation to functional correctness. Without such controls, the reported ROC-AUC of 0.87 could be an artifact of next-token prediction on divergent sequences rather than a causally meaningful reasoning geometry.
- [Trajectory-based steering] Steering framework description (likely §5): the construction of “ideal trajectories” must be fully specified, including whether any fitted quantities from the same data are used; the paper should also report whether steering preserves or degrades performance on unrelated metrics and whether it introduces new error modes.
minor comments (2)
- [Methods] Clarify the precise layer indices and token positions used for the ROC-AUC measurements and steering interventions.
- [Discussion] Add a limitations paragraph discussing the scope (e.g., restriction to mathematical reasoning, dependence on specific model families).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify important gaps in controls and specification that we agree need to be addressed. Below we respond point by point and commit to a revised manuscript that incorporates the requested additions.
read point-by-point responses
-
Referee: [Results on late-stage divergence] §4 (or equivalent results section on divergence and prediction): the manuscript must include explicit controls that match correct and incorrect CoT chains on partial length, token distribution, and termination signals before attributing late-stage geometric separation to functional correctness. Without such controls, the reported ROC-AUC of 0.87 could be an artifact of next-token prediction on divergent sequences rather than a causally meaningful reasoning geometry.
Authors: We agree that the current attribution of late-stage divergence to functional correctness requires stronger controls against sequence-level confounds. In the revision we will add a controlled analysis that (i) matches correct and incorrect chains on prefix length up to the prediction timestep, (ii) balances token-type distributions via subsampling or propensity-score matching, and (iii) enforces identical termination signals. We will recompute the ROC-AUC under these matched conditions and report both the original and controlled results, together with statistical tests confirming that the separation persists after matching. revision: yes
-
Referee: [Trajectory-based steering] Steering framework description (likely §5): the construction of “ideal trajectories” must be fully specified, including whether any fitted quantities from the same data are used; the paper should also report whether steering preserves or degrades performance on unrelated metrics and whether it introduces new error modes.
Authors: We will expand §5 with a precise algorithmic description of ideal-trajectory construction, explicitly stating that the reference trajectories are computed solely from held-out correct examples and that no parameters are fitted on the evaluation set. In addition, we will report steering effects on unrelated metrics (perplexity on non-mathematical text, factual recall on unrelated QA, and output diversity measured by distinct-n) and will document any newly introduced error modes (e.g., increased repetition, hallucination of intermediate steps, or length-control failures). These results will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core claims rest on direct empirical measurements of hidden-state trajectories across layers and steps in both base and fine-tuned models, including quantitative comparisons of subspace separability, divergence points between correct/incorrect chains, and downstream ROC-AUC from linear classifiers trained on those activations. The ideal trajectories used for steering are computed as aggregates from observed correct reasoning paths in the data and then applied as an intervention; their effectiveness is reported as an empirical outcome rather than a definitional necessity. No self-citations, ansatzes, or uniqueness theorems are invoked to close the argument, and no fitted parameter is relabeled as an independent prediction. The derivation therefore remains self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden representations in LLMs capture functional aspects of reasoning steps in an ordered manner
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
mathematical reasoning traverses functionally ordered, step-specific subspaces that become increasingly separable with layer depth... late-stage divergence enables mid-reasoning prediction of final-answer correctness with ROC-AUC up to 0.87
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
trajectory-based steering, an inference-time intervention framework that enables reasoning correction and length control based on derived ideal trajectories
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Semantic Step Prediction: Multi-Step Latent Forecasting in LLM Reasoning Trajectories via Step Sampling
Applying STP at consecutive semantic reasoning steps achieves 168x more accurate multi-step latent prediction on ProcessBench than frozen baselines, with trajectories forming smooth curves best captured by non-linear ...
-
Hypothesis generation and updating in large language models
LLMs exhibit Bayesian-like hypothesis updating with strong-sampling bias and an evaluation-generation gap but generalize poorly outside observed data.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Deepseek. 2025. Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning. Preprint, arXiv:2501.12948. Subhabrata Dutta, Joykirat Singh, Soumen Chakrabarti, and Tanmoy Chakraborty. 2024. How to think step- by-step: A mechanistic understanding of ch...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2506.08343 , year =
Wait, we don’t need to "wait"! removing think- ing tokens improves reasoning efficiency.Preprint, arXiv:2506.08343. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-thought prompt- ing elicits reasoning in large language models. In Advances in Neural Information Processing Sys...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.