Recognition: unknown
Fast and Forgettable: A Controlled Study of Novices' Performance, Learning, Workload, and Emotion in AI-Assisted and Human Pair Programming Paradigms
Pith reviewed 2026-05-10 03:36 UTC · model grok-4.3
The pith
Novices performed significantly better and with lower workload using AI than with a human programming partner, but experienced more positive emotions and better retention with the human.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Participants in the study wrote Python code under time pressure for 20 minutes each with a human teammate and individually with an AI code generation tool. They achieved significantly higher performance with the AI tool and reported lower workload across several dimensions, yet the human teammate produced significantly more positive and arousing emotional effects. Retest performance after one week showed a larger decrement in the AI condition, suggesting differences in how the two paradigms support learning.
What carries the argument
The experimental setup where each participant completed coding tasks with both a human partner and an AI tool, comparing performance, workload, emotion, and one-week retest results.
If this is right
- AI assistance enables higher coding performance for novices in short sessions.
- Several aspects of perceived workload decrease when using AI for coding tasks.
- Human partners elicit stronger positive emotional responses than AI tools.
- Retention of programming knowledge may suffer more after using AI compared to human collaboration.
- Pair programming should be reconsidered as a tool alongside AI in educational settings.
Where Pith is reading between the lines
- The emotional advantage of human partners might lead to greater long-term engagement in programming courses.
- Combining AI and human pair programming could potentially maximize both performance and retention benefits.
- The observed effects might vary with different types of programming tasks or student experience levels.
Load-bearing premise
That differences observed in a single 20-minute session with only 22 participants after a one-week retention interval reflect meaningful and generalizable effects on learning in novice programming education.
What would settle it
Finding no significant difference in one-week retest performance between the AI and human conditions in a replication with more participants and sessions would undermine the claim of differential learning impacts.
Figures
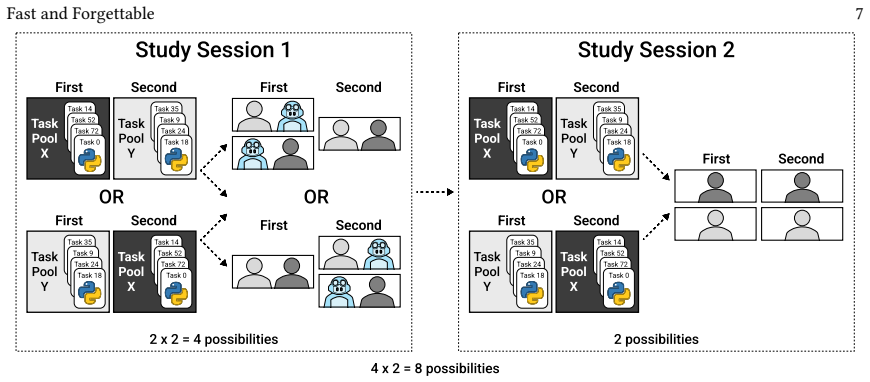

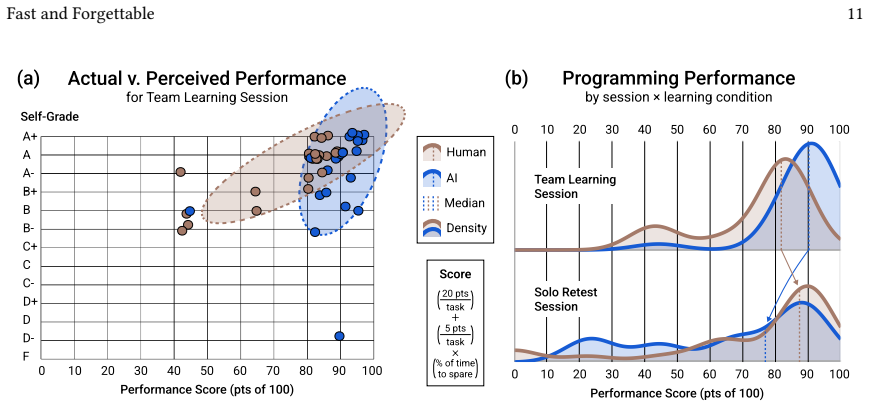
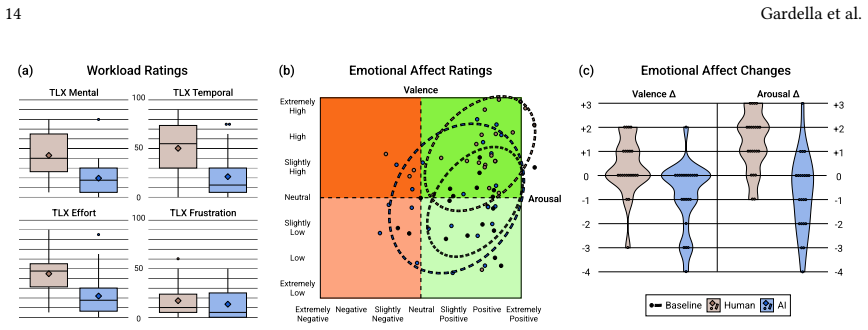
read the original abstract
Code-generating Artificial Intelligence has gained popularity within both professional and educational programming settings over the past several years. While research and pedagogy are beginning to cope with this change, computing students are left to bear the unforeseen consequences of AI amidst a dearth of empirical evidence about its effects. Though pair programming between students is well studied and known to be beneficial to self-efficacy and academic achievement, it remains underutilized and further threatened by the proposition that AI can replace a human programming partner. In this paper, we present a controlled pair programming study with 22 participants who wrote Python code under time pressure in teams of two and individually with GitHub Copilot for 20 minutes each. They were incentivized by bonus compensation to balance performance with understanding and were retested individually on the programming tasks after a retention interval of one week. Subjective measures of workload and emotion as well as objective measures of performance and learning (retest performance) were collected. Results showed that participants performed significantly better with GitHub Copilot than their human teammate, and several dimensions of their workload were significantly reduced. However, the emotional effect of the human teammate was significantly more positive and arousing as compared to working with Copilot. Furthermore, there was a nonsignificant absolute retest performance reduction in the AI condition and a larger retest performance decrement in the AI condition. We recommend that educators strongly consider revisiting pair programming as an educational tool in addition to embracing modern AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a within-subjects controlled study with 22 novice participants comparing GitHub Copilot-assisted programming to human pair programming in 20-minute Python coding sessions under time pressure. Participants were retested after one week. The study finds significantly higher performance and lower workload with Copilot, but more positive and arousing emotions with human partners. Retest performance showed a nonsignificant reduction that was larger in the AI condition. The authors suggest educators should reconsider pair programming in light of AI tools.
Significance. If the findings are robust, this work offers valuable insights into the performance benefits and emotional costs of AI assistance versus human collaboration in programming education. The combination of objective performance data and subjective measures (NASA-TLX and SAM) is a strength, as is the focus on retention to address learning. However, the limited sample and task duration constrain the strength of conclusions about long-term learning effects.
major comments (2)
- [Results] Results section (and abstract): The claim of a 'larger retest performance decrement in the AI condition' is presented despite being nonsignificant; without effect sizes, confidence intervals, or a power analysis for the retention scores, this interpretation risks overstating evidence for differential learning impacts.
- [Methods] Methods section: The design uses only 22 participants for within-subjects comparisons across two 20-minute sessions with a one-week retention interval; given that learning/retention is central to the educational recommendations, the manuscript should include a power calculation or sensitivity analysis to justify that the sample can reliably detect the reported effects.
minor comments (2)
- [Abstract] Abstract: Significant results (e.g., performance and workload differences) are described without accompanying statistics such as t-values, p-values, or effect sizes; adding these would allow quicker assessment of the strength of the evidence.
- [Discussion] Discussion: The final recommendation to 'strongly consider revisiting pair programming' could be tempered to better reflect the mixed findings, specifically the performance advantage of Copilot alongside the emotional advantages of human partners.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We have carefully considered the concerns regarding the interpretation of the nonsignificant retention results and the justification for the sample size. Below we respond point by point and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results] Results section (and abstract): The claim of a 'larger retest performance decrement in the AI condition' is presented despite being nonsignificant; without effect sizes, confidence intervals, or a power analysis for the retention scores, this interpretation risks overstating evidence for differential learning impacts.
Authors: We agree that the phrasing in the abstract and results could be interpreted as suggesting a meaningful differential effect on learning despite the nonsignificant result. In the revised version we will explicitly state that the retest performance reduction was nonsignificant in both conditions, with only a numerically larger (but nonsignificant) decrement observed in the AI condition. We will add Cohen's d effect sizes and 95% confidence intervals for the retention performance scores to allow readers to assess the magnitude and precision of the observed differences. We will also remove any language implying differential learning impacts and instead frame the retention data as exploratory and preliminary, consistent with the small sample and short retention interval. revision: yes
-
Referee: [Methods] Methods section: The design uses only 22 participants for within-subjects comparisons across two 20-minute sessions with a one-week retention interval; given that learning/retention is central to the educational recommendations, the manuscript should include a power calculation or sensitivity analysis to justify that the sample can reliably detect the reported effects.
Authors: We acknowledge that n=22 limits statistical power for detecting small effects on retention, even with the efficiency of the within-subjects design. We will add a sensitivity analysis to the Methods section that reports the minimum detectable effect size (with 80% power and alpha=0.05) for the paired retention comparison given our sample size and observed variance. This will provide transparent context for the retention findings. We note that the primary hypotheses concerned immediate performance, workload, and emotion, for which the within-subjects design yielded significant effects; the retention measure was included as an initial exploration of longer-term implications rather than the central outcome. revision: yes
Circularity Check
No significant circularity: purely empirical measurements
full rationale
The paper reports results from a controlled user study with 22 participants performing timed programming tasks under two conditions (human pair programming vs. GitHub Copilot), followed by subjective workload/emotion scales and a one-week retest. All claims derive from direct statistical comparisons of collected performance metrics, NASA-TLX scores, SAM emotion ratings, and retest deltas. No equations, derivations, fitted parameters, predictions, or first-principles arguments appear; the design contains no self-referential reductions or load-bearing self-citations that collapse claims to inputs by construction. This is a standard empirical HCI study whose validity rests on external data collection rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical assumptions for significance testing (normality, independence of observations) in behavioral experiments
Reference graph
Works this paper leans on
-
[1]
Kazunori Akizuki and Yukari Ohashi. 2015. Measurement of functional task difficulty during motor learning: What level of difficulty corresponds to the optimal challenge point?Human Movement Science43 (Oct. 2015), 107–117. doi:10.1016/j.humov.2015.07.007
-
[2]
Matin Amoozadeh, Daye Nam, Daniel Prol, Ali Alfageeh, James Prather, Michael Hilton, Sruti Srinivasa Ragavan, and Amin Alipour. 2024. Student-AI Interaction: A Case Study of CS1 students. InProceedings of the 24th Koli Calling International Conference on Computing Education Research (Koli Calling ’24). Association for Computing Machinery, New York, NY, US...
-
[3]
Lisanne Bainbridge. 1983. Ironies of automation. InAnalysis, design and evaluation of man–machine systems. Elsevier, 129–135
1983
-
[4]
André Barcaui. 2025. ChatGPT as a cognitive crutch: Evidence from a randomized controlled trial on knowledge retention.Social Sciences & Humanities Open12 (2025), 102287. doi:10.1016/j.ssaho.2025.102287
-
[5]
James, and Nadia Polikarpova
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages7, OOPSLA1 (2023), 85–111. Number: OOPSLA1
2023
-
[6]
Basawapatna, Alexander Repenning, Kyu Han Koh, and Hilarie Nickerson
Ashok R. Basawapatna, Alexander Repenning, Kyu Han Koh, and Hilarie Nickerson. 2013. The zones of proximal flow: guiding students through a space of computational thinking skills and challenges. InProceedings of the ninth annual international ACM conference on International computing education research. ACM, San Diego San California USA, 67–74. doi:10.114...
-
[7]
2004.Extreme Programming Explained: Embrace Change
Kent Beck, Cynthia Andres, and O’Reilly Online Learning: Academic/Public Library Edition. 2004.Extreme Programming Explained: Embrace Change. Addison Wesley Professional, Boston. http://RE5QY4SB7X.search.serialssolutions.com/?V=1.0&L=RE5QY4SB7X&S=JCs&C=TC0000074886&T=marc
2004
-
[8]
Brett A. Becker, Paul Denny, James Finnie-Ansley, Andrew Luxton-Reilly, James Prather, and Eddie Antonio Santos. 2023. Programming Is Hard - Or at Least It Used to Be: Educational Opportunities and Challenges of AI Code Generation. InProceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1 (SIGCSE 2023). Association for Computing...
-
[9]
Ben-Shachar, Daniel Lüdecke, and Dominique Makowski
Mattan S. Ben-Shachar, Daniel Lüdecke, and Dominique Makowski. 2020. effectsize: Estimation of Effect Size Indices and Standardized Parameters. Journal of Open Source Software5, 56 (2020), 2815. doi:10.21105/joss.02815
-
[10]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological)57, 1 (1995), 289–300. Number: 1
1995
-
[11]
Simon Berger and Julian Voigt. 2025. My Way or the AI Way? How Autonomy Frustration Undermines Creative Performance Through Editing AI Advice.How Autonomy Frustration Undermines Creative Performance Through Editing AI Advice (April 28, 2025)(2025)
2025
-
[12]
Christian Bird, Denae Ford, Thomas Zimmermann, Nicole Forsgren, Eirini Kalliamvakou, Travis Lowdermilk, and Idan Gazit. 2023. Taking flight with copilot.Commun. ACM66, 6 (2023), 56–62
2023
-
[13]
Robert A. Bjork. 1994. Memory and Metamemory Considerations in the Training of Human Beings. InMetacognition: Knowing About Knowing, Janet Metcalfe and Arthur P. Shimamura (Eds.). MIT Press, Cambridge, MA, 185–205
1994
-
[14]
Colin Cameron, Jonah B
A. Colin Cameron, Jonah B. Gelbach, and Douglas L. Miller. 2008. Bootstrap-based improvements for inference with clustered errors.The review of economics and statistics90, 3 (2008), 414–427. https://direct.mit.edu/rest/article-abstract/90/3/414/57731
2008
-
[15]
Colin Cameron and Douglas L
A. Colin Cameron and Douglas L. Miller. 2015. A practitioner’s guide to cluster-robust inference.Journal of human resources50, 2 (2015), 317–372. https://jhr.uwpress.org/content/50/2/317.short
2015
-
[16]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, and Greg Brockman. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Myra Cheng, Cinoo Lee, Pranav Khadpe, Sunny Yu, Dyllan Han, and Dan Jurafsky. 2025. Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence. doi:10.48550/arXiv.2510.01395 arXiv:2510.01395 [cs]
-
[18]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen. 2013.Statistical power analysis for the behavioral sciences. Academic press
2013
-
[19]
Ben Colagiuri, Evan J. Livesey, and Justin A. Harris. 2011. Can expectancies produce placebo effects for implicit learning?Psychonomic Bulletin & Review18, 2 (April 2011), 399–405. doi:10.3758/s13423-010-0041-1
-
[20]
2013.Understanding the new statistics: Effect sizes, confidence intervals, and meta-analysis
Geoff Cumming. 2013.Understanding the new statistics: Effect sizes, confidence intervals, and meta-analysis. Routledge. https://api.taylorfrancis.com/ content/books/mono/download?identifierName=doi&identifierValue=10.4324/9780203807002&type=googlepdf Manuscript submitted to ACM 20 Gardella et al
-
[21]
Elise Deitrick, R Benjamin Shapiro, and Brian Gravel. 2016. How do we assess equity in programming pairs? Singapore: International Society of the Learning Sciences
2016
-
[22]
Paul Denny, Juho Leinonen, James Prather, Andrew Luxton-Reilly, Thezyrie Amarouche, Brett A. Becker, and Brent N. Reeves. 2024. Prompt Problems: A New Programming Exercise for the Generative AI Era. InProceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1 (SIGCSE 2024). Association for Computing Machinery, New York, NY, USA, 29...
-
[23]
Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N
Paul Denny, James Prather, Brett A. Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N. Reeves, Eddie Antonio Santos, and Sami Sarsa. 2024. Computing Education in the Era of Generative AI.Commun. ACM67, 2 (Jan. 2024), 56–67. doi:10.1145/3624720
-
[24]
Maria TM Dijkstra and Astrid C. Homan. 2016. Engaging in rather than disengaging from stress: Effective coping and perceived control.Frontiers in psychology7 (2016), 1415. https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2016.01415/full
-
[25]
Guangrui Fan, Dandan Liu, Rui Zhang, and Lihu Pan. 2025. The impact of AI-assisted pair programming on student motivation, programming anxiety, collaborative learning, and programming performance: a comparative study with traditional pair programming and individual approaches. International Journal of STEM Education12, 1 (March 2025), 16. doi:10.1186/s405...
-
[26]
James Finnie-Ansley, Paul Denny, Andrew Luxton-Reilly, Eddie Antonio Santos, James Prather, and Brett A. Becker. 2023. My AI Wants to Know if This Will Be on the Exam: Testing OpenAI’s Codex on CS2 Programming Exercises. InProceedings of the 25th Australasian Computing Education Conference (ACE ’23). Association for Computing Machinery, New York, NY, USA,...
-
[27]
2004.The Midnight Disease: The Drive to Write, Writer’s Block, and the Creative Brain
Alice Weaver Flaherty. 2004.The Midnight Disease: The Drive to Write, Writer’s Block, and the Creative Brain. Houghton Mifflin, Boston
2004
-
[28]
Nat Friedman. 2021. Introducing GitHub Copilot: your AI pair programmer. https://github.blog/2021-06-29-introducing-github-copilot-ai-pair- programmer/
2021
-
[29]
Nicholas Gardella, Raymond Pettit, and Sara L. Riggs. 2024. Performance, Workload, Emotion, and Self-Efficacy of Novice Programmers Using AI Code Generation. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1. ACM, Milan Italy, 290–296. doi:10.1145/3649217.3653615
-
[30]
Nicholas Gardella, Joseph Shelton, Isabella Graßl, and Sara Riggs. 2025. HBCU Student Perspectives on Identity, Persistence, and Code-Generating AI in CS Education: A Case Study. InProceedings of the 25th Koli Calling International Conference on Computing Education Research. ACM, Koli Finland, 1–12. doi:10.1145/3769994.3770015
-
[31]
Gian Luca Scoccia. 2023. Exploring Early Adopters’ Perceptions of ChatGPT as a Code Generation Tool. (Sept. 2023). doi:10.1109/asew60602.2023.00016 MAG ID: 4388214696
-
[32]
Brian Hanks, Sue Fitzgerald, Renée McCauley, Laurie Murphy, and Carol Zander. 2011. Pair programming in education: A literature review.Computer Science Education21, 2 (2011), 135–173
2011
-
[33]
Hannay, Tore Dybå, Erik Arisholm, and Dag I
Jo E. Hannay, Tore Dybå, Erik Arisholm, and Dag I. K. Sjøberg. 2009. The effectiveness of pair programming: A meta-analysis.Information and Software Technology51, 7 (July 2009), 1110–1122. doi:10.1016/j.infsof.2009.02.001
-
[34]
Hart and Lowell E
Sandra G. Hart and Lowell E. Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Advances in psychology. Vol. 52. Elsevier, 139–183
1988
-
[35]
Anja Hawlitschek, Sarah Berndt, and Sandra Schulz. 2023. Empirical research on pair programming in higher education: a literature review. Computer Science Education33, 3 (July 2023), 400–428. doi:10.1080/08993408.2022.2039504
-
[36]
Toni Honicke and Jaclyn Broadbent. 2016. The influence of academic self-efficacy on academic performance: A systematic review.Educational research review17 (2016), 63–84. https://www.sciencedirect.com/science/article/pii/S1747938X15000639
2016
-
[37]
Irene Hou, Owen Man, Kate Hamilton, Srishty Muthusekaran, Jeffin Johnykutty, Leili Zadeh, and Stephen MacNeil. 2025. ’All Roads Lead to ChatGPT’: How Generative AI is Eroding Social Interactions and Student Learning Communities. InProceedings of the 30th ACM Conference on Innovation and Technology in Computer Science Education V. 1 (ITiCSE 2025). Associat...
-
[38]
Irene Hou, Sophia Mettille, Owen Man, Zhuo Li, Cynthia Zastudil, and Stephen MacNeil. 2024. The Effects of Generative AI on Computing Students’ Help-Seeking Preferences. InProceedings of the 26th Australasian Computing Education Conference (ACE ’24). Association for Computing Machinery, New York, NY, USA, 39–48. doi:10.1145/3636243.3636248
-
[39]
Ross Ihaka and Robert Gentleman. 1996. R: A Language for Data Analysis and Graphics.Journal of Computational and Graphical Statistics5, 3 (Sept. 1996), 299–314. doi:10.1080/10618600.1996.10474713
-
[40]
Sumeet Jeswani, Akshay Mittal, and Soni Sewlani. 2025. Premature Trust: How Student Overreliance on GenAI is Seeding Tomorrow’s Security Gaps. InProceedings of the 26th ACM Annual Conference on Cybersecurity & Information Technology Education (SIGCITE ’25). Association for Computing Machinery, New York, NY, USA, 107–112. doi:10.1145/3769694.3771124
-
[41]
Martin Jonsson and Jakob Tholander. 2022. Cracking the code: Co-coding with AI in creative programming education. InProceedings of the 14th Conference on Creativity and Cognition (C&C ’22). Association for Computing Machinery, New York, NY, USA, 5–14. doi:10.1145/3527927.3532801
-
[42]
Gregor Jošt, Viktor Taneski, and Sašo Karakatič. 2024. The Impact of Large Language Models on Programming Education and Student Learning Outcomes.Applied Sciences14, 10 (Jan. 2024), 4115. doi:10.3390/app14104115 Number: 10
-
[43]
Maria Kallia. 2025. To Be, or to Be Otherwise? Silicon Souls in Search of Dasein and Authentic Human Engagement in the Age of Generative AI. In Proceedings of the 2025 ACM Conference on International Computing Education Research V.1 (ICER ’25). Association for Computing Machinery, New York, NY, USA, 240–255. doi:10.1145/3702652.3744223 Manuscript submitte...
-
[44]
Ericson, David Weintrop, and Tovi Grossman
Majeed Kazemitabaar, Justin Chow, Carl Ka To Ma, Barbara J. Ericson, David Weintrop, and Tovi Grossman. 2023. Studying the effect of AI Code Generators on Supporting Novice Learners in Introductory Programming. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, ...
-
[45]
Majeed Kazemitabaar, Xinying Hou, Austin Henley, Barbara Jane Ericson, David Weintrop, and Tovi Grossman. 2024. How Novices Use LLM-based Code Generators to Solve CS1 Coding Tasks in a Self-Paced Learning Environment. InProceedings of the 23rd Koli Calling International Conference on Computing Education Research (Koli Calling ’23). Association for Computi...
-
[46]
Majeed Kazemitabaar, Runlong Ye, Xiaoning Wang, Austin Zachary Henley, Paul Denny, Michelle Craig, and Tovi Grossman. 2024. CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Comp...
-
[47]
András Komócsi, Gergely Csaba, Eszter Veronika Csöngei, Krisztina Fischer, Kristóf Filipánits, László Czopf, and Andrea Tamás. 2026. Academic performance and progression among near-peer tutors: A comparative analysis in undergraduate medical education.Medical Teacher48, 3 (March 2026), 394–404. doi:10.1080/0142159X.2025.2553658 _eprint: https://doi.org/10...
-
[48]
Sandeep Kaur Kuttal, Bali Ong, Kate Kwasny, and Peter Robe. 2021. Trade-offs for Substituting a Human with an Agent in a Pair Programming Context: The Good, the Bad, and the Ugly. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, New York, NY, USA, 1–20. doi:10.1145/3411764.3445659
-
[49]
Liang, Chenyang Yang, and Brad A
Jenny T. Liang, Chenyang Yang, and Brad A. Myers. 2024. A Large-Scale Survey on the Usability of AI Programming Assistants: Successes and Challenges. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3597503.3608128
-
[50]
Mark Liffiton, Brad E Sheese, Jaromir Savelka, and Paul Denny. 2023. CodeHelp: Using Large Language Models with Guardrails for Scalable Support in Programming Classes. InProceedings of the 23rd Koli Calling International Conference on Computing Education Research. ACM, Koli Finland, 1–11. doi:10.1145/3631802.3631830
-
[51]
Wenhan Lyu, Yimeng Wang, Yifan Sun, and Yixuan Zhang. 2025. Will Your Next Pair Programming Partner Be Human? An Empirical Evaluation of Generative AI as a Collaborative Teammate in a Semester-Long Classroom Setting. InProceedings of the Twelfth ACM Conference on Learning @ Scale. ACM, Palermo Italy, 83–94. doi:10.1145/3698205.3729544
-
[52]
MacKinnon, Morten Ørregaard Nielsen, and Matthew D
James G. MacKinnon, Morten Ørregaard Nielsen, and Matthew D. Webb. 2023. Fast and reliable jackknife and bootstrap methods for cluster-robust inference.Journal of Applied Econometrics38, 5 (Aug. 2023), 671–694. doi:10.1002/jae.2969
-
[53]
Margulieux, James Prather, Brent N
Lauren E. Margulieux, James Prather, Brent N. Reeves, Brett A. Becker, Gozde Cetin Uzun, Dastyni Loksa, Juho Leinonen, and Paul Denny. 2024. Self-Regulation, Self-Efficacy, and Fear of Failure Interactions with How Novices Use LLMs to Solve Programming Problems. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1. ACM...
-
[54]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to Help With Code Understanding. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. ACM, Lisbon Portugal, 1–13. doi:10.1145/3597503.3639187
-
[55]
Akilan, P
Palanichamy Naveen, T. Akilan, P. Manikandan, C. Swedheetha, and M. Saravanan. 2025. Comparative Review of Large Language Models. In2025 5th International Conference on Soft Computing for Security Applications (ICSCSA). IEEE, 2120–2124. https://ieeexplore.ieee.org/abstract/document/ 11170906/?casa_token=8DcrOMItU_cAAAAA:3qj-JPYir4hqrlJDkCm4GQL6QwDEiDgQh0v...
2025
-
[56]
2021.The Extended Mind: The Power of Thinking Outside the Brain
Annie Murphy Paul. 2021.The Extended Mind: The Power of Thinking Outside the Brain. Houghton Mifflin Harcourt, Boston, MA
2021
-
[57]
Reinhard Pekrun. 2006. The Control-Value Theory of Achievement Emotions: Assumptions, Corollaries, and Implications for Educational Research and Practice.Educational Psychology Review18, 4 (Nov. 2006), 315–341. doi:10.1007/s10648-006-9029-9
-
[58]
Reinhard Pekrun. 2024. Control-Value Theory: From Achievement Emotion to a General Theory of Human Emotions.Educational Psychology Review36, 3 (Sept. 2024), 83. doi:10.1007/s10648-024-09909-7
-
[59]
Jacob Penney, Pawan Acharya, Peter Hilbert, Priyanka Parekh, Anita Sarma, Igor Steinmacher, and Marco Gerosa. 2025. Understanding Programming Students’ Help-Seeking Preferences in the Era of Generative AI. InProceedings of the ACM Global Computing Education Conference 2025 - Volume 1. ACM, Gaborone Botswana, 15–21. doi:10.1145/3736181.3747165
-
[60]
Reeves, Jaromir Savelka, IV Smith, David H., Sven Strickroth, and Daniel Zingaro
James Prather, Juho Leinonen, Natalie Kiesler, Jamie Gorson Benario, Sam Lau, Stephen MacNeil, Narges Norouzi, Simone Opel, Vee Pettit, Leo Porter, Brent N. Reeves, Jaromir Savelka, IV Smith, David H., Sven Strickroth, and Daniel Zingaro. 2025. Beyond the Hype: A Comprehensive Review of Current Trends in Generative AI Research, Teaching Practices, and Too...
-
[61]
It’s Weird That it Knows What I Want
James Prather, Brent N. Reeves, Paul Denny, Brett A. Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2024. “It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers.ACM Transactions on Computer-Human Interaction31, 1 (Feb. 2024), 1–31. doi:10.1145/3617367
-
[62]
and Kimmel, Bailey and Wright, Jared and Briggs, Ben , title =
James Prather, Brent N Reeves, Juho Leinonen, Stephen MacNeil, Arisoa S Randrianasolo, Brett A. Becker, Bailey Kimmel, Jared Wright, and Ben Briggs. 2024. The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers. InProceedings of the 2024 ACM Conference on International Computing Education Research - Volume 1. ACM, Melbourne VIC Au...
-
[63]
Ira J. Roseman. 1996. Appraisal Determinants of Emotions: Constructing a More Accurate and Comprehensive Theory.Cognition & Emotion10, 3 (May 1996), 241–278. doi:10.1080/026999396380240 Manuscript submitted to ACM 22 Gardella et al
-
[64]
Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D
Steven I. Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D. Weisz. 2023. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. InProceedings of the 28th International Conference on Intelligent User Interfaces. ACM, Sydney NSW Australia, 491–514. doi:10.1145/3581641.3584037
-
[65]
James A. Russell. 1980. A circumplex model of affect.Journal of personality and social psychology39, 6 (1980), 1161. https://psycnet.apa.org/journals/ psp/39/6/1161/
1980
-
[66]
Norsaremah Salleh, Emilia Mendes, and John Grundy. 2011. Empirical Studies of Pair Programming for CS/SE Teaching in Higher Education: A Systematic Literature Review.IEEE Transactions on Software Engineering37, 4 (July 2011), 509–525. doi:10.1109/TSE.2010.59
-
[67]
Benjamin T. Sharpe and Ian Tyndall. 2025. The Sustained Attention Paradox: A Critical Commentary on the Theoretical Impossibility of Perfect Vigilance.Cognitive Science49, 4 (2025), e70061. doi:10.1111/cogs.70061 _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/cogs.70061
-
[68]
Abdulhadi Shoufan. 2023. Can Students without Prior Knowledge Use ChatGPT to Answer Test Questions? An Empirical Study.ACM Trans. Comput. Educ.23, 4 (Dec. 2023), 45:1–45:29. doi:10.1145/3628162
-
[69]
Nancy Sommers. 1980. Revision Strategies of Student Writers and Experienced Adult Writers.College Composition & Communication31, 4 (1980), 378–388. doi:10.58680/ccc198015930 Type: Journal Article
-
[70]
Nancy Sommers. 1982. Responding to Student Writing.College Composition & Communication33, 2 (1982), 148–156. doi:10.58680/ccc198215854 Type: Journal Article
-
[71]
Son and Rajiv Sethi
Lisa K. Son and Rajiv Sethi. 2006. Metacognitive Control and Optimal Learning.Cognitive Science30, 4 (July 2006), 759–774. doi:10.1207/ s15516709cog0000_74
2006
-
[72]
Phil Steinhorst, Andrew Petersen, and Jan Vahrenhold. 2020. Revisiting Self-Efficacy in Introductory Programming. InProceedings of the 2020 ACM Conference on International Computing Education Research. ACM, Virtual Event New Zealand, 158–169. doi:10.1145/3372782.3406281
-
[73]
John Sweller. 2011. Cognitive load theory. InPsychology of learning and motivation. Vol. 55. Elsevier, 37–76. https://www.sciencedirect.com/science/ article/pii/B9780123876911000028
2011
-
[74]
Ritzhaupt
Karthikeyan Umapathy and Albert D. Ritzhaupt. 2017. A meta-analysis of pair-programming in computer programming courses: Implications for educational practice.ACM Transactions on Computing Education (TOCE)17, 4 (2017), 1–13
2017
-
[75]
Smith IV, Mounika Padala, Christine Alvarado, Jamie Gorson Benario, and Leo Porter
Annapurna Vadaparty, Daniel Zingaro, David H. Smith IV, Mounika Padala, Christine Alvarado, Jamie Gorson Benario, and Leo Porter. 2024. CS1-LLM: Integrating LLMs into CS1 Instruction. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1 (ITiCSE 2024). Association for Computing Machinery, New York, NY, USA, 297–303. doi...
-
[76]
Marcel Valový and Alena Buchalcevova. 2023. The Psychological Effects of AI-Assisted Programming on Students and Professionals. In2023 IEEE International Conference on Software Maintenance and Evolution (ICSME). 385–390. doi:10.1109/ICSME58846.2023.00050 ISSN: 2576-3148
-
[77]
Vygotsky
Lev S. Vygotsky. 1978.Mind in Society: The Development of Higher Psychological Processes. Harvard University Press, Cambridge, MA
1978
-
[78]
Matthew D. Webb. 2023. Reworking wild bootstrap-based inference for clustered errors.Canadian Journal of Economics/Revue canadienne d’économique56, 3 (Aug. 2023), 839–858. doi:10.1111/caje.12661
-
[79]
Weisz, Michael Muller, Michael Muller, Michael Muller, Stephanie Houde, John T
Justin D. Weisz, Michael Muller, Michael Muller, Michael Muller, Stephanie Houde, John T. Richards, Steven I. Ross, Fernando Martinez, Mayank Agarwal, and Kartik Talamadupula. 2021. Perfection Not Required? Human-AI Partnerships in Code Translation. 402–412. doi:10.1145/3397481. 3450656 MAG ID: 3154248444
-
[80]
Bai, Robert Tairas, and Yu Huang
Yuankai Xue, Hanlin Chen, Gina R. Bai, Robert Tairas, and Yu Huang. 2024. Does ChatGPT Help With Introductory Programming?An Experiment of Students Using ChatGPT in CS1. InProceedings of the 46th International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET ’24). Association for Computing Machinery, New York, NY,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.