Recognition: unknown
Advancing Vision Transformer with Enhanced Spatial Priors
Pith reviewed 2026-05-10 05:16 UTC · model grok-4.3
The pith
The Euclidean-enhanced Vision Transformer achieves 86.6% top-1 accuracy on ImageNet-1k by incorporating more accurate spatial priors through distance decay and flexible grouping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
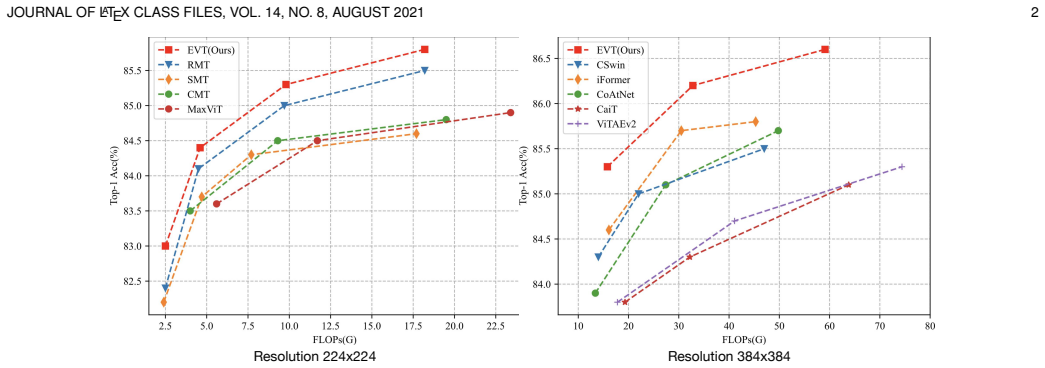
The central discovery is that an enhanced vision transformer using Euclidean distance decay to model spatial information and a spatially-independent grouping approach instead of horizontal-vertical decomposition can achieve superior performance on image classification, object detection, instance segmentation, and semantic segmentation tasks. Specifically, this design allows for a more reasonable representation of spatial relationships and greater flexibility in token grouping, leading to 86.6% top-1 accuracy on ImageNet-1k without additional data.
What carries the argument
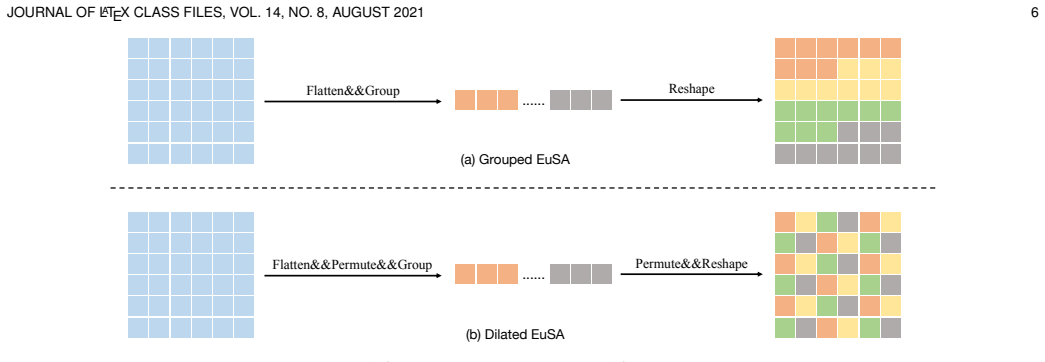
The key mechanism is the combination of Euclidean distance decay in attention weights and spatially-independent grouping of tokens, which together embed explicit spatial priors into the self-attention process while simplifying the computation compared to prior decomposed methods.
If this is right
- The model delivers high accuracy on ImageNet classification without needing extra training data.
- It supports effective object detection and both instance and semantic segmentation.
- The design offers more flexibility in setting the number of tokens in each attention group.
- It addresses quadratic complexity and lack of spatial structure in original vision transformers through these targeted modifications.
Where Pith is reading between the lines
- The approach could be tested on video or 3D data where spatial relations extend over time or depth.
- Similar distance-based priors might help reduce data requirements in other low-resource vision settings.
- The grouping strategy may simplify scaling the model to higher-resolution inputs.
Load-bearing premise
That the performance improvements come specifically from the Euclidean decay and grouping changes rather than from other implementation details or hyperparameter choices in the experiments.
What would settle it
Training an identical model but with Manhattan distance decay and measuring if it still reaches or exceeds 86.6% top-1 accuracy on ImageNet-1k would test whether the Euclidean choice is essential.
Figures






read the original abstract
In recent years, the Vision Transformer (ViT) has garnered significant attention within the computer vision community. However, the core component of ViT, Self-Attention, lacks explicit spatial priors and suffers from quadratic computational complexity, limiting its applicability. To address these issues, we have proposed RMT, a robust vision backbone with explicit spatial priors for general purposes. RMT utilizes Manhattan distance decay to introduce spatial information and employs a horizontal and vertical decomposition attention method to model global information. Building on the strengths of RMT, Euclidean enhanced Vision Transformer (EVT) is an expanded version that incorporates several key improvements. Firstly, EVT uses a more reasonable Euclidean distance decay to enhance the modeling of spatial information, allowing for a more accurate representation of spatial relationships compared to the Manhattan distance used in RMT. Secondly, EVT abandons the decomposed attention mechanism featured in RMT and instead adopts a simpler spatially-independent grouping approach, providing the model with greater flexibility in controlling the number of tokens within each group. By addressing these modifications, EVT offers a more sophisticated and adaptable approach to incorporating spatial priors into the Self-Attention mechanism, thus overcoming some of the limitations associated with RMT and further enhancing its applicability in various computer vision tasks. Extensive experiments on Image Classification, Object Detection, Instance Segmentation, and Semantic Segmentation demonstrate that EVT exhibits exceptional performance. Without additional training data, EVT achieves 86.6% top1-acc on ImageNet-1k.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Euclidean enhanced Vision Transformer (EVT) as an extension of the prior RMT model. EVT replaces Manhattan distance decay with Euclidean distance decay to better capture spatial relationships in self-attention and substitutes the horizontal-vertical decomposed attention with a spatially-independent grouping mechanism that offers more flexible token grouping. The central empirical claim is that EVT achieves 86.6% top-1 accuracy on ImageNet-1k without extra training data and shows strong results on object detection, instance segmentation, and semantic segmentation.
Significance. If the accuracy gains can be shown to arise specifically from the Euclidean decay and grouping changes under controlled comparisons (matching parameter count, FLOPs, and training recipe to baselines), the work would provide a concrete, practical refinement for injecting spatial priors into ViT-style attention. This could be useful for practitioners seeking modest accuracy lifts without quadratic complexity or heavy architectural overhauls.
major comments (2)
- [Abstract] Abstract and Experimental Results section: The headline result of 86.6% top-1 accuracy on ImageNet-1k is stated without any accompanying table of baselines (including RMT), parameter counts, FLOPs, training schedule, data augmentation, or optimizer settings for the reported run. This prevents verification that the gain is attributable to the Euclidean distance decay and spatially-independent grouping rather than differences in model capacity or optimization.
- [Experimental Results] Experimental Results section (ImageNet-1k subsection): No ablation studies isolate the contribution of Euclidean versus Manhattan decay or the effect of the grouping change versus the prior decomposed attention; without these controls the attribution of the performance improvement to the stated spatial-prior modifications remains unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to strengthen the experimental support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experimental Results section: The headline result of 86.6% top-1 accuracy on ImageNet-1k is stated without any accompanying table of baselines (including RMT), parameter counts, FLOPs, training schedule, data augmentation, or optimizer settings for the reported run. This prevents verification that the gain is attributable to the Euclidean distance decay and spatially-independent grouping rather than differences in model capacity or optimization.
Authors: We agree that the abstract, owing to its length limit, cannot accommodate a full comparison table. The current manuscript does not provide the requested side-by-side details for the 86.6% result. In the revision we will insert a dedicated table in the Experimental Results section that reports EVT (86.6%) together with RMT and other baselines, explicitly listing parameter counts, FLOPs, training schedule, data augmentation, and optimizer settings so that readers can verify the source of the improvement. revision: yes
-
Referee: [Experimental Results] Experimental Results section (ImageNet-1k subsection): No ablation studies isolate the contribution of Euclidean versus Manhattan decay or the effect of the grouping change versus the prior decomposed attention; without these controls the attribution of the performance improvement to the stated spatial-prior modifications remains unsupported.
Authors: We acknowledge that the manuscript currently contains no ablation experiments that isolate Euclidean distance decay from Manhattan decay or the spatially-independent grouping from the earlier horizontal-vertical decomposition while holding parameter count and FLOPs fixed. In the revised version we will add controlled ablation studies on ImageNet-1k that quantify the incremental contribution of each change, thereby providing direct evidence that the reported gains arise from the proposed spatial-prior modifications. revision: yes
Circularity Check
No circularity: empirical accuracy claim with no derivation chain
full rationale
The paper proposes EVT as an architectural variant of Vision Transformers, describing two design changes relative to the authors' prior RMT work: switching from Manhattan to Euclidean distance decay and replacing decomposed attention with spatially-independent grouping. The headline result (86.6% ImageNet-1k top-1 accuracy) is presented as a direct experimental measurement, not as a prediction derived from any equation or fitted parameter. No equations, uniqueness theorems, or ansatzes appear in the provided text; the modifications are motivated descriptively rather than derived. Self-reference to RMT supplies context for the improvements but is not invoked to justify the performance number or to forbid alternatives. The result therefore stands as an independent empirical observation rather than a self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikovet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021
2021
-
[2]
Uniformer: Unified transformer for efficient spatiotemporal rep- resentation learning,
K. Li, Y. Wang, P . Gao, G. Song, Y. Liu, H. Li, and Y. Qiao, “Uniformer: Unified transformer for efficient spatiotemporal rep- resentation learning,” 2022
2022
-
[3]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inICCV, 2021
2021
-
[4]
Going deeper with image transformers,
H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. J ´egou, “Going deeper with image transformers,” inICCV, 2021
2021
-
[5]
Rethinking lo- cal perception in lightweight vision transformer,
Q. Fan, H. Huang, J. Guan, and R. He, “Rethinking lo- cal perception in lightweight vision transformer,”ArXiv, vol. abs/2303.17803, 2023
-
[6]
Cvt: Introducing convolutions to vision transformers,
H. Wu, B. Xiao, N. Codella, M. Liu, X. Dai, L. Yuan, and L. Zhang, “Cvt: Introducing convolutions to vision transformers,”arXiv preprint arXiv:2103.15808, 2021
-
[7]
Cmt: Convolutional neural networks meet vision transformers,
J. Guo, K. Han, H. Wu, C. Xu, Y. Tang, C. Xu, and Y. Wang, “Cmt: Convolutional neural networks meet vision transformers,” inCVPR, 2022
2022
-
[8]
Lite vision transformer with enhanced self-attention,
C. Yang, Y. Wang, J. Zhanget al., “Lite vision transformer with enhanced self-attention,” inCVPR, 2022
2022
-
[9]
Neighborhood attention transformer,
A. Hassani, S. Walton, J. Li, S. Li, and H. Shi, “Neighborhood attention transformer,” inCVPR, 2023
2023
-
[10]
Rmt: Retentive networks meet vision transformers,
Q. Fan, H. Huang, M. Chen, H. Liu, and R. He, “Rmt: Retentive networks meet vision transformers,” inCVPR, 2024
2024
-
[11]
Retentive Network: A Successor to Transformer for Large Language Models
Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, and F. Wei, “Retentive network: A successor to Transformer for large language models,”ArXiv, vol. abs/2307.08621, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Train short, test long: At- JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 17 tention with linear biases enables input length extrapolation,
O. Press, N. Smith, and M. Lewis, “Train short, test long: At- JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 17 tention with linear biases enables input length extrapolation,” in ICLR, 2022
2021
-
[13]
Peripheral vision transformer,
J. Min, Y. Zhao, C. Luoet al., “Peripheral vision transformer,” in NeurIPS, 2022
2022
-
[14]
Cswin transformer: A general vision transformer backbone with cross-shaped windows,
X. Dong, J. Bao, D. Chenet al., “Cswin transformer: A general vision transformer backbone with cross-shaped windows,” in CVPR, 2022
2022
-
[15]
Vision trans- former with deformable attention,
Z. Xia, X. Pan, S. Song, L. E. Li, and G. Huang, “Vision trans- former with deformable attention,” inCVPR, 2022
2022
-
[16]
Davit: Dual attention vision transformers,
M. Ding, B. Xiao, N. Codellaet al., “Davit: Dual attention vision transformers,” inECCV, 2022
2022
-
[17]
Biformer: Vision transformer with bi-level routing attention,
L. Zhu, X. Wang, Z. Ke, W. Zhang, and R. Lau, “Biformer: Vision transformer with bi-level routing attention,” inCVPR, 2023
2023
-
[18]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y. Wuet al., “A convnet for the 2020s,” in CVPR, 2022
2022
-
[19]
Semantic equitable clustering: A simple, fast and effective strategy for vision trans- former,
Q. Fan, H. Huang, M. Chen, and R. He, “Semantic equitable clustering: A simple, fast and effective strategy for vision trans- former,” inICCV, 2025
2025
-
[20]
Vision transformer with sparse scan prior,
——, “Vision transformer with sparse scan prior,” 2024
2024
-
[21]
Twins: Revisiting the design of spatial attention in vision transformers,
X. Chu, Z. Tian, Y. Wang, B. Zhang, H. Ren, X. Wei, H. Xia, and C. Shen, “Twins: Revisiting the design of spatial attention in vision transformers,” inNeurIPS, 2021
2021
-
[22]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,
W. Wang, E. Xie, X. Li, D.-P . Fan, K. Song, D. Liang, T. Lu, P . Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” inICCV, 2021
2021
-
[23]
Pvtv2: Improved baselines with pyramid vision trans- former,
——, “Pvtv2: Improved baselines with pyramid vision trans- former,”Computational Visual Media, vol. 8, no. 3, pp. 1–10, 2022
2022
-
[24]
Lightweight vision transformer with bidirectional interaction,
Q. Fan, H. Huang, X. Zhou, and R. He, “Lightweight vision transformer with bidirectional interaction,” inNeurIPS, 2023
2023
-
[25]
Multi-scale vision longformer: A new vision transformer for high-resolution image encoding,
P . Zhang, X. Dai, J. Yang, B. Xiao, L. Yuan, L. Zhang, and J. Gao, “Multi-scale vision longformer: A new vision transformer for high-resolution image encoding,” inICCV, 2021
2021
-
[26]
RegionViT: Regional-to- Local Attention for Vision Transformers,
C.-F. R. Chen, R. Panda, and Q. Fan, “RegionViT: Regional-to- Local Attention for Vision Transformers,” inICLR, 2022
2022
-
[27]
Visual parser: Represent- ing part-whole hierarchies with transformers,
S. Sun, X. Yue, S. Bai, and P . Torr, “Visual parser: Represent- ing part-whole hierarchies with transformers,”arXiv preprint arXiv:2107.05790, 2021
-
[28]
Perceiver: General perception with iterative atten- tion,
A. Jaegle, F. Gimeno, A. Brock, A. Zisserman, O. Vinyals, and J. Carreira, “Perceiver: General perception with iterative atten- tion,” inICML, 2021
2021
-
[29]
Msg- transformer: Exchanging local spatial information by manipulat- ing messenger tokens,
J. Fang, L. Xie, X. Wang, X. Zhang, W. Liu, and Q. Tian, “Msg- transformer: Exchanging local spatial information by manipulat- ing messenger tokens,” inCVPR, 2022
2022
-
[30]
Hrformer: High-resolution transformer for dense prediction,
Y. Yuan, R. Fu, L. Huang, W. Lin, C. Zhang, X. Chen, and J. Wang, “Hrformer: High-resolution transformer for dense prediction,” in NeurIPS, 2021
2021
-
[31]
Multi-scale high-resolution vision transformer for semantic segmentation,
J. Gu, H. Kwon, D. Wang, W. Ye, M. Li, Y.-H. Chen, L. Lai, V . Chandra, and D. Z. Pan, “Multi-scale high-resolution vision transformer for semantic segmentation,” inCVPR, 2022
2022
-
[32]
When do we not need larger vision models?
B. Shi, Z. Wu, M. Mao, X. Wang, and T. Darrell, “When do we not need larger vision models?”arXiv preprint arXiv:2403.13043, 2024
-
[33]
Hiri-vit: Scaling vision trans- former with high resolution inputs,
T. Yao, Y. Li, Y. Pan, and T. Mei, “Hiri-vit: Scaling vision trans- former with high resolution inputs,”TP AMI, 2024
2024
-
[34]
Swin transformer v2: Scaling up capacity and resolution,
Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong, F. Wei, and B. Guo, “Swin transformer v2: Scaling up capacity and resolution,” inCVPR, 2022
2022
-
[35]
Internimage: Exploring large-scale vision foundation models with deformable convolutions,
W. Wang, J. Dai, Z. Chen, Z. Huang, Z. Li, X. Zhu, X. Hu, T. Lu, L. Lu, H. Liet al., “Internimage: Exploring large-scale vision foundation models with deformable convolutions,” inCVPR, 2023
2023
-
[36]
Not all patches are what you need: Expediting vision transformers via token reorganizations,
Y. Liang, C. Ge, Z. Tong, Y. Song, J. Wang, and P . Xie, “Not all patches are what you need: Expediting vision transformers via token reorganizations,” inICLR, 2022
2022
-
[37]
Dynam- icvit: Efficient vision transformers with dynamic token sparsifi- cation,
Y. Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “Dynam- icvit: Efficient vision transformers with dynamic token sparsifi- cation,” inNeurIPS, 2021
2021
-
[38]
Token merging: Your ViT but faster,
D. Bolya, C.-Y. Fu, X. Dai, P . Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your ViT but faster,” inICLR, 2023
2023
-
[39]
Vision transformer with super token sampling,
H. Huang, X. Zhou, J. Cao, R. He, and T. Tan, “Vision transformer with super token sampling,” inCVPR, 2023
2023
-
[40]
Conformer: Local features coupling global representations for visual recognition,
Z. Peng, W. Huang, S. Gu, L. Xie, Y. Wang, J. Jiao, and Q. Ye, “Conformer: Local features coupling global representations for visual recognition,” inICCV, 2021
2021
-
[41]
Mixformer: Mixing features across windows and dimensions,
Q. Chen, Q. Wu, J. Wang, Q. Hu, T. Hu, E. Ding, J. Cheng, and J. Wang, “Mixformer: Mixing features across windows and dimensions,” inCVPR, 2022
2022
-
[42]
Inception transformer,
C. Si, W. Yu, P . Zhou, Y. Zhou, X. Wang, and S. YAN, “Inception transformer,” inNeurIPS, 2022
2022
-
[43]
Fast vision transformers with hilo attention,
Z. Pan, J. Cai, and B. Zhuang, “Fast vision transformers with hilo attention,” inNeurIPS, 2022
2022
-
[44]
Coatnet: Marrying convolution and attention for all data sizes,
Z. Dai, H. Liu, Q. V . Le, and M. Tan, “Coatnet: Marrying convolution and attention for all data sizes,”arXiv preprint arXiv:2106.04803, 2021
-
[45]
Orthogonal transformer: An effi- cient vision transformer backbone with token orthogonalization,
H. Huang, X. Zhou, and R. He, “Orthogonal transformer: An effi- cient vision transformer backbone with token orthogonalization,” inNeurIPS, 2022
2022
-
[46]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmaret al., “Attention is all you need,” inNeurIPS, 2017
2017
-
[47]
Conditional positional encodings for vision transformers,
X. Chu, Z. Tian, B. Zhang, X. Wang, and C. Shen, “Conditional positional encodings for vision transformers,” inICLR, 2023
2023
-
[48]
Eva-02: A visual representation for neon genesis
Y. Fang, Q. Sun, X. Wang, T. Huang, X. Wang, and Y. Cao, “Eva-02: A visual representation for neon genesis,”arXiv preprint arXiv:2303.11331, 2023
-
[49]
Flatten trans- former: Vision transformer using focused linear attention,
D. Han, X. Pan, Y. Han, S. Song, and G. Huang, “Flatten trans- former: Vision transformer using focused linear attention,” in ICCV, 2023
2023
-
[50]
Agent attention: On the integration of softmax and linear attention,
D. Han, T. Ye, Y. Han, Z. Xia, S. Song, and G. Huang, “Agent attention: On the integration of softmax and linear attention,” in ECCV, 2024
2024
-
[51]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, Y. Lu, S. Pan, B. Wen, and Y. Liu, “Roformer: Enhanced transformer with rotary position embedding,” 2021
2021
-
[52]
Maxvit: Multi-axis vision transformer,
Z. Tu, H. Talebi, H. Zhang, F. Yang, P . Milanfar, A. Bovik, and Y. Li, “Maxvit: Multi-axis vision transformer,” inECCV, 2022
2022
-
[53]
Multi-scale vmamba: Hierarchy in hierarchy visual state space model,
Y. Shi, M. Dong, and C. Xu, “Multi-scale vmamba: Hierarchy in hierarchy visual state space model,” inNeurIPS, 2024
2024
-
[54]
Moat: Alternating mobile convolu- tion and attention brings strong vision models,
C. Yang, S. Qiao, Q. Yuet al., “Moat: Alternating mobile convolu- tion and attention brings strong vision models,” inICLR, 2023
2023
-
[55]
M.-H. Guo, C.-Z. Lu, Z.-N. Liu, M.-M. Cheng, and S.-M. Hu, “Visual attention network,”arXiv preprint arXiv:2202.09741, 2022
-
[56]
Conv2former: A simple transformer-style convnet for visual recognition,
Q. Hou, C.-Z. Lu, M.-M. Cheng, and J. Feng, “Conv2former: A simple transformer-style convnet for visual recognition,”arXiv preprint arXiv:2211.11943, 2022
-
[57]
Scaling up your kernels: Large kernel design in convnets towards universal representations,
Y. Zhang, X. Ding, and X. Yue, “Scaling up your kernels: Large kernel design in convnets towards universal representations,” TP AMI, 2025
2025
-
[58]
Learned queries for efficient local attention,
M. Arar, A. Shamir, and A. H. Bermano, “Learned queries for efficient local attention,” inCVPR, 2022
2022
-
[59]
Global context vision transformers,
A. Hatamizadeh, H. Yin, G. Heinrich, J. Kautz, and P . Molchanov, “Global context vision transformers,” inICML, 2023
2023
-
[60]
Scale-aware modulation meet transformer,
W. Lin, Z. Wu, J. Chen, J. Huang, and L. Jin, “Scale-aware modulation meet transformer,” inICCV, 2023
2023
-
[61]
Transnext: Robust foveal visual perception for vision transformers,
D. Shi, “Transnext: Robust foveal visual perception for vision transformers,” inCVPR, 2024
2024
-
[62]
Overlock: An overview-first-look-closely-next convnet with context-mixing dynamic kernels,
M. Lou and Y. Yu, “Overlock: An overview-first-look-closely-next convnet with context-mixing dynamic kernels,” inCVPR, 2025
2025
-
[63]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douzeet al., “Training data-efficient image transformers & distillation through attention,” inICML, 2021
2021
-
[64]
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification,
C.-F. R. Chen, Q. Fan, and R. Panda, “CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification,” in ICCV, 2021
2021
-
[65]
Focal self-attention for local-global interactions in vision transformers,
J. Yang, C. Li, P . Zhang, X. Dai, B. Xiao, L. Yuan, and J. Gao, “Focal self-attention for local-global interactions in vision transformers,” inNeurIPS, 2021
2021
-
[66]
Sucheng ren, xingyi yang, songhua liu, xinchao wang,
S.-F. S. guided Transformer with Evolving Token Reallocation, “Sucheng ren, xingyi yang, songhua liu, xinchao wang,” inICCV, 2023
2023
-
[67]
Demystify mamba in vision: A linear attention perspective,
D. Han, Z. Wang, Z. Xia, Y. Han, Y. Pu, C. Ge, J. Song, S. Song, B. Zheng, and G. Huang, “Demystify mamba in vision: A linear attention perspective,” inNeurIPS, 2024
2024
-
[68]
Vssd: Vision mamba with non-causal state space duality,
Y. Shi, M. Dong, M. Li, and C. Xu, “Vssd: Vision mamba with non-causal state space duality,” inICCV, 2025
2025
-
[69]
Quadtree attention for vision transformers,
S. Tang, J. Zhang, S. Zhuet al., “Quadtree attention for vision transformers,” inICLR, 2022
2022
-
[70]
Scalablevit: Rethinking the context-oriented generalization of vision transformer,
R. Yang, H. Ma, J. Wu, Y. Tang, X. Xiao, M. Zheng, and X. Li, “Scalablevit: Rethinking the context-oriented generalization of vision transformer,” inECCV, 2022
2022
-
[71]
Crossformer++: A versatile vision transformer hinging on cross-scale attention,
W. Wang, W. Chen, Q. Qiu, L. Chen, B. Wu, B. Lin, X. He, and W. Liu, “Crossformer++: A versatile vision transformer hinging on cross-scale attention,”TP AMI, 2023
2023
-
[72]
Contextual transformer net- works for visual recognition,
Y. Li, T. Yao, Y. Pan, and T. Mei, “Contextual transformer net- works for visual recognition,”TP AMI, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18
2022
-
[73]
Q. Zhang, Y. Xu, J. Zhang, and D. Tao, “Vitaev2: Vision trans- former advanced by exploring inductive bias for image recogni- tion and beyond,”arXiv preprint arXiv:2202.10108, 2022
-
[74]
Mvitv2: Improved multiscale vision trans- formers for classification and detection,
Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision trans- formers for classification and detection,” inCVPR, 2022
2022
-
[75]
Crossformer: A versatile vision transformer hinging on cross- scale attention,
W. Wang, L. Yao, L. Chen, B. Lin, D. Cai, X. He, and W. Liu, “Crossformer: A versatile vision transformer hinging on cross- scale attention,” inICLR, 2022
2022
-
[76]
Mpvit: Multi-path vision transformer for dense prediction,
Y. Lee, J. Kim, J. Willette, and S. J. Hwang, “Mpvit: Multi-path vision transformer for dense prediction,” inCVPR, 2022
2022
-
[77]
Vision transformer adapter for dense predictions,
Z. Chen, Y. Duan, W. Wang, J. He, T. Lu, J. Dai, and Y. Qiao, “Vision transformer adapter for dense predictions,” inICLR, 2023
2023
-
[78]
Do imagenet classifiers generalize to imagenet?
B. Recht, R. Roelofs, L. Schmidt, and V . Shankar, “Do imagenet classifiers generalize to imagenet?” 2019
2019
-
[79]
Natural adversarial examples,
D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song, “Natural adversarial examples,” inCVPR, 2021
2021
-
[80]
The many faces of robustness: A critical analysis of out-of-distribution generalization,
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo, R. Desai, T. Zhu, S. Parajuli, M. Guo, D. Song, J. Steinhardt, and J. Gilmer, “The many faces of robustness: A critical analysis of out-of-distribution generalization,” inICCV, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.