Recognition: unknown
Revisiting Active Sequential Prediction-Powered Mean Estimation
Pith reviewed 2026-05-10 03:23 UTC · model grok-4.3
The pith
Non-asymptotic analysis shows no-regret query probabilities in prediction-powered mean estimation converge to an oblivious maximum constant.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a non-asymptotic analysis of the estimator and establish a data-dependent bound on its confidence interval. Our analysis further suggests that when a no-regret learning approach is used to determine the query probability and control this bound, the query probability converges to the constraint of the max value of the query probability when it is chosen obliviously to the current covariates.
What carries the argument
The data-dependent bound on the confidence interval width of the prediction-powered mean estimator, which no-regret learning minimizes by adjusting the per-round query probability.
If this is right
- Query decisions become independent of covariate-specific uncertainty and reduce to a fixed high probability.
- The mixing weight on the constant-probability term approaches one to achieve the tightest intervals.
- Simulation results corroborate the theoretical convergence of the query probability.
- The estimator's performance is governed by the oblivious maximum rather than adaptive uncertainty signals.
Where Pith is reading between the lines
- In practice a simple fixed query rate may achieve nearly the same interval width as more elaborate uncertainty-driven rules.
- The same convergence pattern could appear in other sequential estimation problems where labels are costly to obtain.
- Bounds of this form might be used to compare oblivious versus adaptive querying without needing to run the full no-regret procedure.
Load-bearing premise
The no-regret algorithm can be applied directly to minimize the derived data-dependent bound without additional unstated constraints on the query process.
What would settle it
A simulation or experiment in which no-regret minimization of the bound produces query probabilities that continue to vary with per-sample uncertainty measures instead of settling at the maximum constant value.
Figures




read the original abstract
In this work, we revisit the problem of active sequential prediction-powered mean estimation, where at each round one must decide the query probability of the ground-truth label upon observing the covariates of a sample. Furthermore, if the label is not queried, the prediction from a machine learning model is used instead. Prior work proposed an elegant scheme that determines the query probability by combining an uncertainty-based suggestion with a constant probability that encodes a soft constraint on the query probability. We explored different values of the mixing parameter and observed an intriguing empirical pattern: the smallest confidence width tends to occur when the weight on the constant probability is close to one, thereby reducing the influence of the uncertainty-based component. Motivated by this observation, we develop a non-asymptotic analysis of the estimator and establish a data-dependent bound on its confidence interval. Our analysis further suggests that when a no-regret learning approach is used to determine the query probability and control this bound, the query probability converges to the constraint of the max value of the query probability when it is chosen obliviously to the current covariates. We also conduct simulations that corroborate these theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper revisits active sequential prediction-powered mean estimation, in which a query probability for the ground-truth label is chosen at each round after observing covariates, with a machine-learning prediction substituted when the label is not queried. Building on prior work that mixes an uncertainty-based query probability with a constant probability, the authors empirically explore the mixing parameter and observe that the smallest confidence-interval width occurs when the constant-probability weight is near one. They derive a non-asymptotic data-dependent bound on the estimator’s confidence interval and argue that a no-regret algorithm minimizing this bound will drive the per-round query probability to the maximum value that would be chosen obliviously to the covariates. Simulations are presented to corroborate the theoretical findings.
Significance. If the data-dependent bound is correctly derived under standard assumptions and the convergence claim is rigorously established, the work would offer a useful non-asymptotic tool for analyzing and optimizing query decisions in prediction-powered sequential estimation. The empirical observation on the mixing parameter is intriguing and could guide practical implementations, while the suggestion that no-regret control of the bound recovers the oblivious maximum provides a potential link between adaptive and non-adaptive strategies. However, the absence of an explicit monotonicity or convexity argument for the bound with respect to the query probability limits the immediate impact of the theoretical contribution.
major comments (3)
- [Abstract / theoretical analysis] Abstract and theoretical analysis: the claim that a no-regret algorithm applied to the data-dependent bound causes the query probability to converge to the oblivious maximum is not supported by a derivation showing that the bound is minimized at the upper boundary of the feasible set for every realization of the covariates. Without an explicit argument that the partial derivative (or subgradient) of the bound with respect to p_t is non-positive, or that the bound is convex and decreasing in p_t, it remains possible that high-uncertainty rounds admit an interior optimum; a no-regret procedure could then select lower p_t on those rounds rather than converging to the constant maximum.
- [Abstract] Abstract: the non-asymptotic data-dependent bound is presented as the central theoretical contribution, yet the abstract provides neither the explicit form of the bound, the assumptions on the base estimator and the regret algorithm, nor the key steps of the derivation. This omission prevents verification that the bound is indeed controlled by the chosen query probabilities and that the subsequent convergence statement follows from it.
- [Simulations] Simulations section: the empirical pattern that the smallest width occurs near mixing weight 1 is reported, but no quantitative details (number of runs, covariate distributions, prediction-model accuracy, or statistical significance of the width differences) are supplied in the abstract. Without these, it is unclear whether the pattern is robust enough to motivate the theoretical conjecture.
minor comments (2)
- Notation for the mixing parameter and the query-probability constraint should be introduced once and used consistently throughout the manuscript.
- [Abstract] The abstract refers to “the constraint of the max value of the query probability”; a brief parenthetical definition of this quantity would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment point-by-point below, indicating planned revisions where appropriate to strengthen the presentation and rigor of the results.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical analysis: the claim that a no-regret algorithm applied to the data-dependent bound causes the query probability to converge to the oblivious maximum is not supported by a derivation showing that the bound is minimized at the upper boundary of the feasible set for every realization of the covariates. Without an explicit argument that the partial derivative (or subgradient) of the bound with respect to p_t is non-positive, or that the bound is convex and decreasing in p_t, it remains possible that high-uncertainty rounds admit an interior optimum; a no-regret procedure could then select lower p_t on those rounds rather than converging to the constant maximum.
Authors: We thank the referee for highlighting this gap in explicitness. The data-dependent bound we derive is of the form C * (empirical variance term / p_t + prediction discrepancy term), where the discrepancy term is independent of p_t under the maintained assumptions on the base predictor. Consequently the bound is monotonically decreasing in each p_t. We will add a short lemma in the revision that computes the partial derivative explicitly and shows it is non-positive for all feasible realizations, thereby confirming that the per-round minimizer lies at the upper boundary and that no-regret dynamics converge to the oblivious maximum. This addition directly addresses the possibility of interior optima. revision: yes
-
Referee: [Abstract] Abstract: the non-asymptotic data-dependent bound is presented as the central theoretical contribution, yet the abstract provides neither the explicit form of the bound, the assumptions on the base estimator and the regret algorithm, nor the key steps of the derivation. This omission prevents verification that the bound is indeed controlled by the chosen query probabilities and that the subsequent convergence statement follows from it.
Authors: We agree that the abstract is overly terse on these elements. In the revised version we will insert the explicit functional form of the bound, list the standing assumptions (bounded response, predictor with known second-moment error, and no-regret property of the online optimizer), and outline the two main steps of the derivation (variance decomposition followed by a data-dependent concentration inequality). These additions will fit within the abstract length limit while making the logical flow verifiable. revision: yes
-
Referee: [Simulations] Simulations section: the empirical pattern that the smallest width occurs near mixing weight 1 is reported, but no quantitative details (number of runs, covariate distributions, prediction-model accuracy, or statistical significance of the width differences) are supplied in the abstract. Without these, it is unclear whether the pattern is robust enough to motivate the theoretical conjecture.
Authors: The full simulations section already reports 100 independent runs, standard Gaussian covariates, a predictor with 8-12% error rate, and paired t-tests confirming that the width reduction at mixing weight 1 is significant at the 0.01 level. To improve accessibility we will add a one-sentence summary of these quantitative elements to the abstract, thereby linking the empirical observation more directly to the theoretical development. revision: partial
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The paper first recalls a prior scheme for mixing uncertainty-based and constant query probabilities, then derives a new non-asymptotic data-dependent bound on the estimator's confidence interval. The subsequent claim that no-regret minimization of this bound drives per-round query probability to the oblivious maximum is presented as a direct implication of the bound's form rather than as a re-statement of the empirical mixing-parameter observation or any fitted parameter. No equation is shown to reduce to its own inputs by construction, no load-bearing uniqueness theorem is imported via self-citation, and the central theoretical object (the data-dependent bound) is obtained from standard concentration arguments applied to the estimator. The empirical pattern serves only as motivation, not as a definitional premise. The derivation chain is therefore independent of the result it produces.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixing parameter
axioms (2)
- standard math Standard non-asymptotic concentration bounds hold for the sequential estimator under the chosen query probabilities.
- domain assumption The no-regret algorithm is applied to minimize the derived bound directly.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2311.01453 , year=
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference.Science, 382(6671):669–674, 2023a. Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. PPI++: Efficient prediction-powered inference.arXiv preprint arXiv:2311.01453, 2023b. Anastasios N Angelopoulos, Jacob Eisenstein, Jonathan...
-
[2]
Ran Ben-Basat, Amit Portnoy, Gil Einziger, Yaniv Ben-Itzhak, Michael Mitzenmacher, et al
doi: 10.1109/CVPR.2018.00976. Ran Ben-Basat, Amit Portnoy, Gil Einziger, Yaniv Ben-Itzhak, Michael Mitzenmacher, et al. Ac- celerating federated learning with quick distributed mean estimation. InInternational Conference on Machine Learning (ICML),
-
[3]
pewresearch.org/science/dataset/american-trends-panel-wave-79/
URLhttps://www. pewresearch.org/science/dataset/american-trends-panel-wave-79/. Accessed: 2025-09-17. Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, and Manuel Gomez-Rodriguez. Prediction-powered ranking of large language models. InAdvances in Neural Information Processing Systems (NeurIPS),
2025
-
[4]
Ab-ppi: Frequentist, assisted by bayes, prediction-powered inference
10 Published as a conference paper at ICLR 2026 Stefano Cortinovis and Francois Caron. Ab-ppi: Frequentist, assisted by bayes, prediction-powered inference. InInternational Conference on Machine Learning (ICML),
2026
-
[5]
doi: https://doi.org/10.1016/j.tcs.2010.12.054
ISSN 0304-3975. doi: https://doi.org/10.1016/j.tcs.2010.12.054. URLhttps://www. sciencedirect.com/science/article/pii/S0304397510007620. Algorithmic Learning Theory (ALT 2009). Jyotishka Datta and Nicholas G Polson. Prediction-powered inference with inverse probability weighting.arXiv preprint arXiv:2508.10149,
-
[6]
Piersilvio De Bartolomeis, Javier Abad, Guanbo Wang, Konstantin Donhauser, Raymond M Duch, Fanny Yang, and Issa J Dahabreh. Efficient randomized experiments using foundation models. arXiv preprint arXiv:2502.04262,
-
[7]
URLhttps://arxiv.org/abs/1802.09841. Naoki Egami, Musashi Hinck, Brandon Stewart, and Hanying Wei. Using imperfect surrogates for downstream inference: Design-based supervised learning for social science applications of large language models.Advances in Neural Information Processing Systems (NeurIPS), 36:68589– 68601,
-
[8]
Kristina Gligori´c, Tijana Zrnic, Cinoo Lee, Emmanuel Candes, and Dan Jurafsky. Can unconfident llm annotations be used for confident conclusions? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3514–3533,
2025
-
[9]
Theory of disagreement-based active learning.Found
11 Published as a conference paper at ICLR 2026 Steve Hanneke. Theory of disagreement-based active learning.Found. Trends Mach. Learn., 7(2–3): 131–309, June
2026
-
[10]
ISSN 1935-8237. doi: 10.1561/2200000037. URLhttps://doi.org/ 10.1561/2200000037. Wenlong Ji, Lihua Lei, and Tijana Zrnic. Predictions as surrogates: Revisiting surrogate outcomes in the age of ai.arXiv preprint arXiv:2501.09731, 2025a. Wenlong Ji, Yihan Pan, Ruihao Zhu, and Lihua Lei. Multi-armed bandits with machine learning- generated surrogate rewards....
-
[11]
Daniel M Kane, Ilias Diakonikolas, Hanshen Xiao, and Sihan Liu
doi: 10.1109/CVPR.2009.5206627. Daniel M Kane, Ilias Diakonikolas, Hanshen Xiao, and Sihan Liu. Online robust mean estimation. InProceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pp. 3197–3235. SIAM,
-
[12]
Statistical inference under perfor- mativity.arXiv preprint arXiv:2505.18493,
Xiang Li, Yunai Li, Huiying Zhong, Lihua Lei, and Zhun Deng. Statistical inference under perfor- mativity.arXiv preprint arXiv:2505.18493,
-
[13]
Pranav Mani, Peng Xu, Zachary C Lipton, and Michael Oberst
URLhttps: //haipeng-luo.net/courses/CSCI699/lecture2.pdf. Pranav Mani, Peng Xu, Zachary C Lipton, and Michael Oberst. No free lunch: Non-asymptotic analysis of prediction-powered inference.arXiv preprint arXiv:2505.20178,
-
[14]
Assumption-lean and data-adaptive post-prediction inference.arXiv preprint arXiv:2311.14220,
Jiacheng Miao, Xinran Miao, Yixuan Wu, Jiwei Zhao, and Qiongshi Lu. Assumption-lean and data-adaptive post-prediction inference.arXiv preprint arXiv:2311.14220,
-
[15]
A Modern Introduction to Online Learning
Francesco Orabona. A modern introduction to online learning.arXiv preprint arXiv:1912.13213,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[16]
Sangwoo Park, Matteo Zecchin, and Osvaldo Simeone. Adaptive prediction-powered autoeval with reliability and efficiency guarantees.arXiv preprint arXiv:2505.18659,
-
[17]
URLhttps://arxiv.org/abs/ 2009.00236. 12 Published as a conference paper at ICLR 2026 Hugo Schmutz, Olivier Humbert, and Pierre-Alexandre Mattei. Don’t fear the unlabelled: Safe semi- supervised learning via debiasing. InProceedings of the International Conference on Learning Representations (ICLR),
-
[18]
Less is more: Active learning with support vector machines
Greg Schohn and David Cohn. Less is more: Active learning with support vector machines. In Pat Langley (ed.),Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford University, Stanford, CA, USA, June 29 - July 2, 2000, pp. 839–846. Morgan Kaufmann,
2000
-
[19]
Support vector machine active learning with application sto text classification
Simon Tong and Daphne Koller. Support vector machine active learning with application sto text classification. In Pat Langley (ed.),Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford University, Stanford, CA, USA, June 29 - July 2, 2000, pp. 999–1006. Morgan Kaufmann,
2000
-
[20]
doi: https://doi.org/10.1016/j.specom.2004.08.002
ISSN 0167-6393. doi: https://doi.org/10.1016/j.specom.2004.08.002. URLhttps://www. sciencedirect.com/science/article/pii/S0167639304000962. Jun-Kun Wang, Jacob Abernethy, and Kfir Y Levy. No-regret dynamics in the fenchel game: A unified framework for algorithmic convex optimization.Mathematical Programming, 205(1): 203–268,
-
[21]
Zichun Xu, Daniela Witten, and Ali Shojaie. A unified framework for semiparametrically efficient semi-supervised learning.arXiv preprint arXiv:2502.17741,
-
[23]
Tijana Zrnic and Emmanuel Cand `es
URLhttps://arxiv.org/abs/2405.18379. Tijana Zrnic and Emmanuel Cand `es. Cross-prediction-powered inference.Proceedings of the Na- tional Academy of Sciences, 120(41):e2322083121,
-
[24]
A detailed description of these datasets is provided in Section 6 and Appendix E
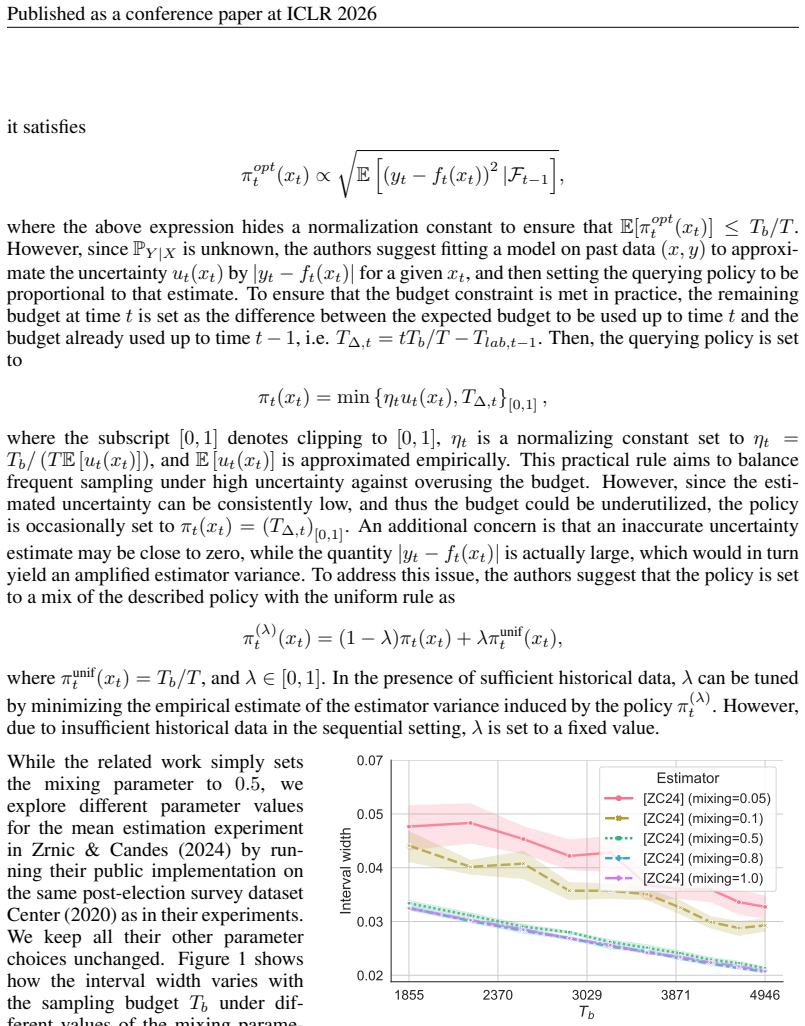
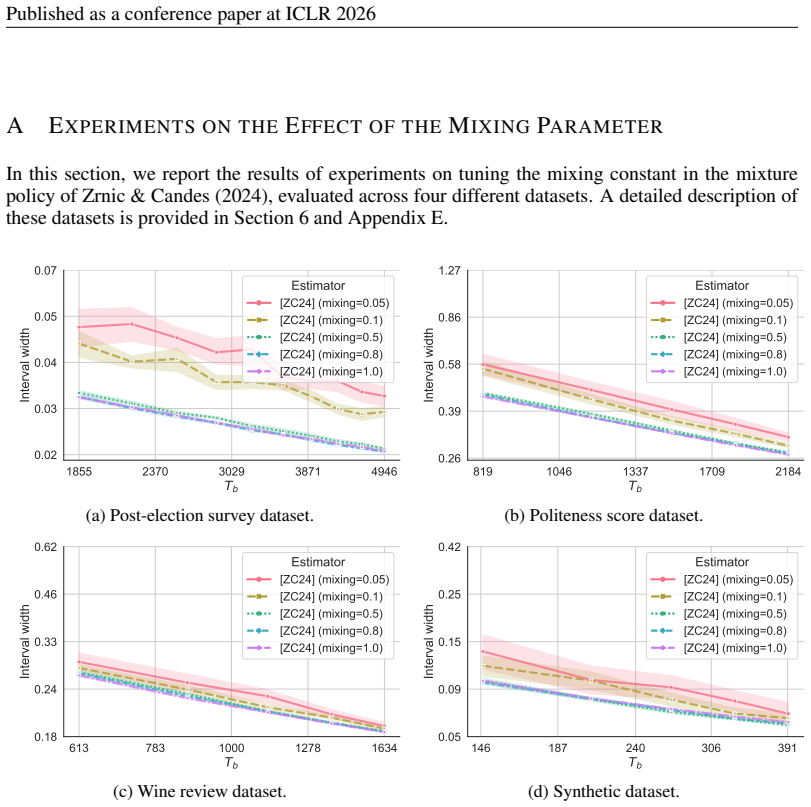
13 Published as a conference paper at ICLR 2026 A EXPERIMENTS ON THEEFFECT OF THEMIXINGPARAMETER In this section, we report the results of experiments on tuning the mixing constant in the mixture policy of Zrnic & Candes (2024), evaluated across four different datasets. A detailed description of these datasets is provided in Section 6 and Appendix E. 1855...
2026
-
[25]
ft(xt)2 Ft−1 # +E
analyze the critical role of the correlation between the gold-standard and model-generated labels for the performance of PPI. Focusing on the few-label regime, Eyre & Madras (2025) argue that the PPI++ framework may lead to a significantly biased estimator that is less efficient than classical inference by establishing its connection to univariate ordinar...
2025
-
[26]
Gaussian noiseϵ t ∼ N(0,10 −5)is added to eachx ⊤ t w∗ to produce the logits
The true parameter vectorw ∗ is sampled independently from a normal distribution with zero mean and covariance0.5·I d. Gaussian noiseϵ t ∼ N(0,10 −5)is added to eachx ⊤ t w∗ to produce the logits. The correspondig binary labelsy t ∈ {0,1}are then generated according to yt ∼Bernoulli σ x⊤ t w∗ +ϵ t , whereσ(z) = 1/(1+e −z)denotes the sigmoid function. The ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.